занимательная арифметика в картинках с ответами
Занимательные примеры на сложение и вычитание
Перед вами 7 заданий, которые можно использовать для короткого дополнительного занятия с первоклассником. Решать сейчас эти примеры в уме или на бумаге не обязательно.
Вы сможете выполнять интерактивные задания в персональном кабинете. А здесь мы просто показываем родителям и учителям примеры задач. Чтобы вы сразу поняли, что наконец-то нашли то, что искали 😉.
Определи недостающее число.

С ЛогикЛайк ребёнок не соскучится! И подружится с логикой и математикой.
Какие цифры спрятались за совой и попугаями?
Пример составления отчетности по форме ПОД-1
На территории объекта «Площадка №1» предприятия ООО «Пример» расположен столярный цех. В нем 8 деревообрабатывающих станков и газопылеулавливающая установка марки «Циклон Гипродревпром», для улавливания древесных отходов с диаметром входного патрубка 0,4 м и диаметром 0,45 м на выходе. Цех работает 8 часов в день. Составим отчет по форме ПОД-1 для этого цеха.
В нем 8 деревообрабатывающих станков и газопылеулавливающая установка марки «Циклон Гипродревпром», для улавливания древесных отходов с диаметром входного патрубка 0,4 м и диаметром 0,45 м на выходе. Цех работает 8 часов в день. Составим отчет по форме ПОД-1 для этого цеха.
Для того чтобы начать вводить данные в форму ПОД-1, необходимо сначала описать стационарный источник выбросов.
1. Откройте журнал документов «Источники выбросов» и добавьте новый документ. Это можно сделать с помощью пункта меню «Действия» или клавиши <Insert> или щелчком мышки по кнопке — «Добавить документ (Ins)». Откроется экранная форма «Источники выбросов (новый)». Начинается заполнение документа с поля «Объект НВОС», которое можно выбрать из документа «Объекты НВОС» с помощью кнопки — выбираем объект Площадка № 1. Далее следует ввести наименование цеха или участка, на котором расположены источники выбросов – вводим значение вручную «Столярный цех» (если цех или участок уже вводились ранее, значение можно выбрать по кнопке ). Затем введите наименование и номер источника в соответствующих полях.
2. Теперь переходим к описанию параметров источника выбросов. Эти параметры могут со временем изменяться, поэтому в окошке «Описание действует» укажите период действия данного описания. Введите дату начала периода в формате дд.мм.гггг. Дату можно ввести вручную или выбрать по календарю с помощью кнопки . Данное описание источника, которое мы вводим еще действует, поэтому дату окончания периода вводить не нужно. Щелчком мыши выберите тип источника: «Организованный». Далее укажите высоту источника в метрах и геометрические размеры на выходе, как на рисунке ниже.
3. В нашем примере есть газопылеулавливающая установка, поэтому в поле «Есть ГПУ» щелчком мыши установите галочку. При этом в поле «Кол-во ступеней очистки» автоматически будет установлено значение 1, а в таблице «Характеристика ступеней очистки» появится 1 строка, которую нельзя ни удалить, ни добавить.
4. Теперь можно приступить к вводу документа «Форма ПОД-1». Откройте журнал документов «Форма ПОД-1» и добавьте новый документ. Это можно сделать с помощью пункта меню «Действия» или клавиши <Insert> или щелчком мышки по кнопке — «Добавить документ (Ins)». Откроется экранная форма «Форма ПОД-1 (новый)». Начинается заполнение документа с поля «Год». Автоматически устанавливается текущий год. Можно изменить вручную. Далее следует заполнить поле «Цех (участок)». Выберите нужное значение из документа «Источники выбросов» с помощью кнопки . После ввода цеха поля «Объект НВОС» и «Наименование источника» заполнятся автоматически из документа «Источники выбросов». А в окошке, в левой части документа появится номер источника выбросов.
5. Введите дату измерения в левом окошке документа по выбранному номеру источника выброса. Для этого щелкните мышкой по номеру источника и нажмите кнопку (Добавить дату измерения). В появившемся окошке введите дату или выберите ее по календарю, нажав кнопку справа от поля даты.
Теперь нажмите кнопку (применить).
Дата попадет в окошко, а в таблице «Результаты измерения» появится две строки (зависит от описания источника). Данные строки нельзя ни добавлять ни удалять.
Введите время работы источника (группы источников) в часах за сутки.
6. Далее заполните все «белые» колонки в таблице «Результаты измерения» в каждой автоматически сформированной строке.
Колонка «Место и точка отбора проб» — если поле не заполнилось автоматически, введите текст вручную.
Колонка «t, °C» — укажите температуру газовоздушной смеси.
Колонка «Давление абс.» — введите абсолютное давление. Давление должно быть задано в кПа. Если вы измеряете в других единицах, нажмите кнопочку справа от вводимого поля, появится окошко «Перевод давления в кПа».
Колонка «Uср, м/с» — укажите среднюю скорость газа по сечению газохода в м/с.
Колонка «Q Нм3 в час» — объем сухой газовоздушной смеси при нормальных условиях, рассчитывается автоматически и вручную не корректируется.
7. Теперь для каждой строки таблицы «Результаты измерения» заполните таблицу «Концентрация загрязняющих веществ». Установите курсор на первую строку в таблице «Результаты измерения» и в таблице «Концентрация загрязняющих веществ» введите загрязняющее вещество, в нашем случае это «Пыль древесная». Это можно сделать, указав в первой колонке код загрязняющего вещества «2936» или во второй колонке выбрать пыль древесную из справочника «Вещества, загрязняющие воздух (СПб)» (справочник открывается с помощью кнопки ). В колонке «Концентрация ЗВ г/Нм3» укажите концентрацию выбранного загрязняющего вещества – 90 г/Нм3.
8. Перейдите ко второй строке в таблице «Результаты измерения» и щелкните мышкой по кнопке — «Добавить выбранные вещества». В таблице «Концентрация загрязняющих веществ» появится строка с загрязняющим веществом «Пыль древесная». В колонке «Концентрация ЗВ г/Нм3» укажите концентрацию вещества – 30 г/Нм3.
9. После того как Вы заполнили все вышеперечисленные поля и таблицы, щелкните по кнопке . Программа выполнит расчет и заполнит таблицу «Количество загрязняющих веществ на выходе из источника (группы источников)». Вручную ни добавлять, ни удалять вещества в данной таблице нельзя.
После расчета необходимо заполнить колонки «Макс. кол-во ЗВ» и «Методы определения». В первой из этих колонок укажите максимальное количество по каждому загрязняющему (вредному) веществу в выбросе. Максимальное количество указывается в граммах в секунду и берется из выданных разрешений на выброс (ПДВ, ВСВ). Методы определения введите вручную или выберите из списка ранее введенных значений.
На этом ввод формы ПОД-1 окончен, нажмите кнопку .
10. Для создания бумажной копии журнала учета по форме ПОД-1 необходимо распечатать титульный лист и отдельные листы на каждый источник выделения (группу источников) с результатами измерения.
Титульный лист распечатывается на один год по каждому цеху (участку) в отдельности. Для его распечатки необходимо открыть журнал документа «Форма ПОД-1», выбрать в журнале строку с нужным цехом (участком) и щелкнуть мышкой по кнопке — «Печать документа (Ctrl+P)». Откроется окно с перечнем печатных форм. Выберите отчет «Титульный лист ПОД-1» и нажмите кнопку . Откроется MS Word, со сформированным титульным листом для выбранного в журнале цеха (участка). Титульный лист следует печатать один раз в начале года.
Отдельные листы формы ПОД-1 распечатываются по мере проведения замеров параметров источников загрязнения и данных обработки результатов лабораторного анализа отобранных проб. Откройте журнал документа «Форма ПОД-1», выберите в журнале строку с нужным цехом (участком) и щелкнуть мышкой по кнопке — «Печать документа (Ctrl+P)». Откроется окно с перечнем печатных форм. Выберите отчет «Форма ПОД-1» и нажмите кнопку . Откроется окно для ввода параметров отчета. Выберите источник выбросов и период даты измерения, для которых нужно распечатать листы формы ПОД-1, и щелкните мышкой по кнопке . Откроется MS Excel с содержимым отчета.
По окончании года титульный лист и отдельные листы формы ПОД-1 прошиваются и заверяются подписью и печатью предприятия.
ОДВ-1 2020 за 2019 год — пример заполнения показателей
С пакетом, содержащим СЗВ-СТАЖ 2019, нужно подать и форму ОДВ-1 (до 02.03.2020, перенос с воскресенья 1 марта). Предлагаем разобраться с основными моментами заполнения ОДВ-1 за 2019 год:
- Раздел 1 «Реквизиты страхователя, передающего документы» — заполняется аналогично СЗВ-СТАЖ, с которой подается ОДВ-1.
- Раздел 2 «Отчетный период (код)» — ставим 0 за год.
- Тип сведений указываем тот же, что и в CЗВ-СТАЖ.
- Тип «Корректирующая» выбирается при необходимости корректировки данных раздела 5 формы ОДВ-1 с типом «Исходная», а тип «Отменяющая» представляется для отмены данных раздела 5 формы ОДВ-1 с типом «Исходная».
- Раздел 3 «Перечень входящих документов».
В графе «Количество застрахованных лиц» раздела 3 указывается число застрахованных лиц, сведения на которых содержат формы, представленные одновременно с ОДВ-1:
- по форме СЗВ-СТАЖ — количество застрахованных лиц, указанных в таблице 3 формы;
- по форме СЗВ-ИСХ — количество форм СЗВ-ИСХ, входящих в пакет;
- по форме СЗВ-КОРР — количество форм СЗВ-КОРР, входящих в пакет.
ОБРАТИТЕ ВНИМАНИЕ! В случае когда ОДВ-1 представляется одновременно с пакетом документов, содержащим формы СЗВ-КОРР (за исключением формы СЗВ-КОРР с типом «Особая»), заполняются только разделы 1–3 формы.
- Раздел 4 «Данные в целом по страхователю» — не заполняется.
- Раздел 5 «Основание для отражения данных о периодах работы застрахованного лица в условиях, дающих право на досрочное назначение пенсии в соответствии со статьей 30 закона “О страховых пенсиях” от 28.12.2013 № 400-ФЗ» — заполняется, если в формах СЗВ-СТАЖ (с типом сведений «ИСХ») и СЗВ-ИСХ, представленных одновременно с формой ОДВ-1, содержатся сведения о застрахованных лицах, занятых на видах работ, указанных в пп. 1–18 ч. 1 ст. 30 закона № 400-ФЗ, то есть если есть информация в графах 9, 10 и 12 раздела 3 CЗВ-СТАЖ.
Образец заполнения ОДВ-1 за 2019 год можно посмотреть здесь.
О сроках сдачи пакетов с СЗВ-СТАЖ и ОДВ-1 в 2020 году, читайте в этой статье.
Источники:
Постановление Правления ПФР от 06.12.2018 № 507п Более полную информацию по теме вы можете найти в КонсультантПлюс.Пробный бесплатный доступ к системе на 2 дня.
Несбалансированные планы и сумма квадратов типа I и II
Milliken и Johnson (1984, стр. 129) обсуждают некоторые детали несбалансированного межгруппового плана 2 x 3. Файл данных Twoway.sta показан ниже в электронной таблице.
129) обсуждают некоторые детали несбалансированного межгруппового плана 2 x 3. Файл данных Twoway.sta показан ниже в электронной таблице.
Этот план несбалансирован, так как ячейки T1, B2 и T2, B1 содержат по два наблюдения, так как оставшиеся ячейки содержат по три наблюдения. В главе 10 своей книги Милликен и Джонсон обсуждают вычисление и интерпретацию сумм квадратов типа I, II и III для факторов и их взаимодействий.
Для анализа, сначала нужно открыть файл данных Twoway.sta и задать переменные T и B как независимые переменные, а переменную DV — как зависимую. Также в стартовой панели нужно установить опцию Регрессионный подход.
Теперь, нужно нажать OK для начала анализа (STATISTICA автоматически выберет коды для независимых переменных). Для вычисления таблицы дисперсионного анализа типа I щелкните на кнопке Опции вывода и в получившемся диалоге выберите опцию SS типа I (последовательная).
Нажмите OK в этом диалоговом окне, а затем в диалоговом окне Результаты дисперсионного анализа щелкните на кнопку Все эффекты. Откроется диалоговое окно Порядок эффектов для суммы квадратов типа I. В этом диалоговом окне можно выбрать порядок межгрупповых факторов в плане. Для этого примера выберите Порядок по умолчанию.
Нажмите OK для вывода таблицы результатов дисперсионного анализа типа I для всех эффектов.
Сумма квадратов типа I и опция Специфический эффект/средние/графики. Когда используется опция Специфический эффект/средние/графики в диалоговом окне Результаты дисперсионного анализа, то после запроса анализа типа I изучаемый эффект будет введен в модель после всех эффектов, которые ниже его по порядку, но перед всеми эффектами, которые выше его по порядку. Следовательно, изучаемый эффект исследуется после проверки всех низших по порядку эффектов. Эффекты такого же или высшего порядка игнорируются.
Следовательно, изучаемый эффект исследуется после проверки всех низших по порядку эффектов. Эффекты такого же или высшего порядка игнорируются.
В начало
Содержание портала
Sony Alpha 1: Первые примеры фотографий
Sony вела себя довольно сдержанно и скрытно, когда затрагивался вопрос о публикации фотографий, отснятых с помощью недавно анонсированной Alpha 1. Официально примеры фотографий должны появиться не раньше конца этой — начала следующей недели, но в сеть уже утекли 5 рекламных снимков в полном разрешении.
Пример фотографии с Sony Alpha 1 Пример фотографии с Sony Alpha 1: 100% кропПоскольку a1 получила совершенно новый сенсор, в фотосообществе подогревается немалый интерес к тому, как же выглядят фотографии, которые он может снять.
Пример фотографии с Sony Alpha 1 Пример фотографии с Sony Alpha 1: 100% кропПортал Sony Alpha Rumors поделился пятью изображениями в полном разрешении, попавшими в Сеть, но не раскрыл источники их получения. Если вы уже видели видео с презентации новой топовой беззеркалки Sony, то некоторые из фото могут показаться вам знакомыми.
Пример фотографии с Sony Alpha 1 Пример фотографии с Sony Alpha 1: 100% кропЭти фотографии не дадут представления о возможностях камеры в экстремальных условиях, но они помогают пролить свет на то, на что способна камера в относительно идеальных, по мнению Sony, условиях. Хотя все пять фотографий имеют одинаковое разрешение, они довольно сильно различаются по размеру файла: самая маленькая “весит” 19,7 МБ, а самая большая — 48,2 МБ.
Пример фотографии с Sony Alpha 1 Пример фотографии с Sony Alpha 1: 100% кропК сожалению, данные EXIF были удалены из фотографий, поэтому мы не можем увидеть информацию об объективах, использованных при съёмке, или значение ISO, на которое был настроен сенсор Sony a1.
Пример фотографии с Sony Alpha 1 Пример фотографии с Sony Alpha 1: 100% кропЕсли вы хотите взглянуть на изображения в полном размере, вы можете скачать их с нашего Google-диска.
Что вы думаете об этих фото? Соответствуют ли они вашим ожиданиям о Sony a1? Напишите в комментариях ниже.
Больше полезной информации и новостей в нашем Telegram-канале «Уроки и секреты фотографии». Подписывайся!Поделиться новостью в соцсетях Об авторе: spp-photo.ru « Предыдущая запись Следующая запись »
«Электромобиль “КАМА-1” – яркий пример деятельности Университета 3.0», – глава Минобрнауки России Валерий Фальков
6 марта 2021 года в Университете Иннополис (Республика Татарстан) под председательством заместителя председателя Правительства РФ Дмитрия Чернышенко состоялось рабочее совещание с ректорами ведущих российских вузов, посвященное вопросам развития сферы высшего образования в части подготовки квалифицированных кадров для приоритетных отраслей цифровой экономики. Санкт-Петербургский политехнический университет Петра Великого (СПбПУ) представлял ректор академик РАН Андрей Рудской.
Программа мероприятия началась с круглых столов рабочих групп по приоритетным отраслям экономики и IT-отрасли, участниками которых стали представители опорных вузов, федеральных органов власти, федерального учебно-методического объединения и представители крупнейших IT-компаний и разработчиков программного обеспечения. Ректор СПбПУ Андрей Рудской принял участие в круглом столе «Цифровые технологии в обрабатывающей промышленности».
-
Участники круглого стола
Бочаров Олег Евгеньевич, заместитель министра Министерства промышленности и торговли РФ;
Каримов Альберт Анварович, заместитель премьер-министра Республики Татарстан – министр промышленности и торговли Республики Татарстан;
Соловьев Александр Александрович, заместитель руководителя Федеральной службы по аккредитации;
Рудской Андрей Иванович, ректор Санкт-Петербургского политехнического университета Петра Великого;
Кокшаров Виктор Анатольевич, ректор Уральского федерального университета имени первого Президента России Б.
 Н. Ельцина;
Н. Ельцина;Шавалиев Эльдар Рамильевич, директор Центра цифровой трансформации ПАО «КАМАЗ».
В рамках круглого стола участники обсудили требования к системе высшего образования для реализации модели цифровой промышленности. Заместитель министра Министерства промышленности и торговли РФ Олег Бочаров представил стратегию цифровой трансформации обрабатывающих отраслей промышленности в целях достижения их «цифровой зрелости» до 2024 года и на период до 2030 года.
Олег Евгеньевич отметил, что для повсеместного старта цифровой трансформации необходимы не только собственные цифровые платформы предприятий, но и соответствующие специалисты. «Деятельность промышленности и вузов последние 20 лет разорвана, в виду ряда причин университеты вынуждены замыкаться в себе и многие научные работы, исследования остаются в стенах вузов. Наша стратегия призвана эту ситуацию исправить. Среди наиболее актуальных и востребованных высокотехнологичной промышленностью новых направлений подготовки машиностроении отмечу:
- Цифровое проектирование и моделирование;
- Виртуальные испытания;
- Цифровая подготовка производства;
- Управление роботехническими комплексами»,
– прокомментировал Олег Бочаров.
В продолжение темы ректор СПбПУ академик РАН Андрей Рудской выступил с докладом и поделился, в частности, мнением относительно направлений подготовки, в рамках которых будут разработаны рекомендуемые к тиражированию образовательные программы. Он отметил, что разработчики материалов к совещанию пропустили направление подготовки бакалавров и магистров 15.03.03 / 15.03.04 «Прикладная механика», специально выделив магистерские программы:
- «Вычислительная механика и компьютерный инжиниринг»;
- «Компьютерный инжиниринг и цифровое производство».

Ректор СПбПУ подчеркнул, что именно это направление и магистерские программы, реализуемые в СПбПУ, отвечают на вопросы и предложения заместителя министра промышленности и торговли по трём указанным позициям: «Цифровое проектирование и моделирование»; «Виртуальные испытания»; «Цифровая подготовка производства».
Далее, Андрей Рудской подчеркнул, что гораздо больший интерес для научно–образовательного сообщества и высокотехнологичной промышленности представляют инновационные программы, способные обеспечить научно-технологический прорыв, интегрирующие фундаментальные физико-математические и инженерно-технические знания и, конечно, передовые цифровые технологии.
Примером такого научно-технологического прорыва является проект по созданию электромобиля «КАМА-1», реализованный инженерами Инжинирингового центра «Центр компьютерного инжиниринга» (CompMechLab®) СПбПУ – ключевого подразделения Центра компетенций НТИ СПбПУ «Новые производственные технологии». Индустриальным партнером в этом проекте выступал КАМАЗ.
Как рассказал Андрей Иванович, разработанное высокотехнологичное изделие – предсерийный опытный промышленный образец электромобиля, было создано в кратчайшие сроки с помощью передовых цифровых технологий и уникальных цифровых платформ, разработанных в Центре НТИ СПбПУ.
«Высокотехнологичное изделие, в котором чрезвычайно много электрики и электроники, конечно – специализированного программного обеспечения, я уже не говорю, что это машиностроительное изделие, а потому используются разные материалы, включая композиты.
Используются математическое моделирование, компьютерный и суперкомпьютерный инжиниринг, системный и цифровой инжиниринг, сквозные цифровые технологии (новые производственные технологии, большие данные, искусственный интеллект и так далее).Наконец, разрабатываются цифровые двойники, обеспечивающие значительное снижение себестоимости и времени разработки, используются виртуальные испытания, виртуальные стенды и виртуальные полигоны, что, в свою очередь, значительно снижает объемы “лишних (избыточных)” натурных испытаний.
Если все это сделать за два года, с помощью инженеров – наших выпускников, большинство из которых выпускники направления ”Прикладная механика», обладающих компетенциями мирового уровня в области цифровых технологий и цифровой промышленности, то это и будет научно-технологический прорыв, признанный как Министерством науки и высшего образования РФ, так и Правительством Российской Федерации, признанный высокотехнологичной промышленностью России».
Академик РАН ректор СПбПУ
Андрей Рудской

ВУЗПРОМЭКСПО-2020. Презентация первого российского электрического смарт-кроссовера «КАМА-1».
Обращаясь к участникам сессии и руководителям вузов Андрей Иванович, отметил:
«Коллеги, нам нужно четко понимать единые требования к программам подготовки и те компетенции, которыми должны обладать наши выпускники. Одна из наших ключевых задач – подготовка высококвалифицированных кадров, в которых нуждается наша экономика, наша промышленность. Это люди широкого круга компетенций, которые могут использовать цифровые технологии как инструмент для достижения реальных прорывных результатов».
Андрей Иванович также подчеркнул, что для решения обозначенных задач необходимо поднять вопрос о том, чтобы ряд направлений, таких как «Прикладная механика» (магистерские программы «Вычислительная механика и компьютерный инжиниринг», «Компьютерный инжиниринг и цифровое производство»), были бы определены для политехнических университетов в качестве базовых.
Что касается системы повышения квалификации, то ректор отметил системную работу в Петербургском Политехе по подготовке кадров в области цифровой трансформации.
«Необходимо создать новую систему дополнительного профессионального образования, когда команда инженеров-конструкторов / расчётчиков / технологов от промышленного предприятия совместно с представителями Центров компетенций, например, нашего Центра компетенций НТИ «Новые производственные технологии» решает амбициозные актуальные промышленные задачи в кратчайшие сроки с помощью передовых цифровых технологий и платформенных решений», – сказал Андрей Рудской.
Ректор СПбПУ отметил, что сегодня в Центре НТИ СПбПУ «Новые производственные технологии» реализуются проекты с представителями компании «ТВЭЛ» (управляющая компания Топливного дивизиона Госкорпорации «Росатом»), создана универсальная пассажирская платформа автобусов, электробусов и троллейбусов, выполняются актуальные проекты в интересах Объединённой двигателестроительной корпорации (в первую очередь, ОДК-КЛИМОВ, ОДК-САТУРН, ОКБ им. А.М. Люльки и других предприятий).
«Нужна конкретнаят комплексная научно-образовательная программа по типу Дорожных карт (планов мероприятий), реализуемых в Центре НТИ СПбПУ в интересах ОДК и ТВЭЛ. Мы должны гармонизировать взаимодействие органов власти и высокотехнологичных предприятий промышленности для того, чтобы создавать компетентные кадры для будущего», – подвёл итог своего выступления ректор.
В завершение мероприятия заместитель премьер-министра Республики Татарстан – министр промышленности и торговли Республики Татарстан Альберт Каримов отметил:
«Подготовка специалистов для промышленности Республики Татарстан является важнейшим направлением. Мы видим, что подготовка высококвалифицированных кадров позволяет максимально увеличить производительность труда, добавочную стоимость продукта, способствует развитию региона и объединению предприятий в кооперационные цепочки. Я бы хотел предложить рабочей группе предусмотреть возможность внесения изменений во все программы».
Олег Бочаров выразил благодарность участникам сессии и обозначил дальнейшие шаги деятельности рабочей группы по данному вопросу.
Обсуждение кадрового вопроса продолжилось на стратегической сессии министра науки и высшего образования РФ Валерия Фалькова. Мероприятие было посвящено презентации и обсуждению инициатив, подготовленных совместно с ректорским и экспертным сообществом для будущей стратегии социально-экономического развития России до 2030 года. «По поручению Председателя Правительства РФ Михаила Мишустина уже более полутора месяцев, привлекая множество экспертов, мы работаем над идеями для фронтальной Стратегии социально-экономического развития России. Сегодняшняя стратегическая сессия даст старт их широкому профессиональному обсуждению», – пояснил Валерий Фальков.
«По поручению Председателя Правительства РФ Михаила Мишустина уже более полутора месяцев, привлекая множество экспертов, мы работаем над идеями для фронтальной Стратегии социально-экономического развития России. Сегодняшняя стратегическая сессия даст старт их широкому профессиональному обсуждению», – пояснил Валерий Фальков.
Говоря о подготовке кадров, Валерий Николаевич представил одну из возможных классификаций университетов: Университет 1.0, Университет 2.0, Университет 3.0, основанную на работе Йохана Виссема «Университет третьего поколения» (2009).
«Из 710 вузов, я экспертно считаю, как минимум, 300 или 400 даже не ставят себе задачу выходить на рынок и думают, что их основная цель – это подготовка кадров под существующие индустрии. Я, конечно, обобщаю, поскольку не каждый отраслевой университет должен ставить себе подобную задачу, но мы с вами размышляем в масштабах системы в целом. И я прекрасно понимаю, какой большой шаг сделали те университеты, которые участвовали последние 15 лет в разных программах (федеральных, национально-исследовательских, опорных и, конечно, в проекте 5-100)», – пояснил Валерий Фальков. Министр отметил, что подобные программы, реализованные c 2016 года, охватили лишь 19% отечественных вузов.
«Так или иначе мы стремимся стать в классической или канонической интерпретации Университетом 3.0. – Университетом, который подразумевает выход в рынок, а также трансфер технологий и знаний.
Вот один из таких примеров. Яркий проект Питерского Политеха. Андрей Иванович Рудской вместе с Алексеем Ивановичем Боровковым представили очень хороший проект, который, на мой взгляд, демонстрирует, чем должен заниматься университет третьего поколения. Это выход уже, ну, не в готовый серийный продукт, но, тем не менее, для меня это важный показатель того, что университет либо приблизился к этой модели Университета 3.
0, либо уже являет собой таковую. И здесь даже не столь важно, пойдет этот продукт в серию или нет. Сразу хочу сказать, это – не задача университета. Для нас с вами, для того дискурса, который есть, и для университетского развития важно, что он вообще есть и важно, чтобы такие автомобили появлялись.
И я знаю, что в ряде других университетов есть наработки. Продуктовая линейка может быть самой разной. Речь идет о том, чтобы отчитываться не только статьями. Нужно что-то готовое для рынка, для гражданина, для нашей экономики».
Министр науки и высшего образования РФ
Валерий Фальков
Проект «КАМА-1», действительно, стал научно-технологическим прорывом и признан и на самом высоком правительственном уровне, и высокотехнологичной промышленностью России. Напомним, презентация первого российского электрического смарт-кроссовера «КАМА-1» состоялась в рамках ВУЗПРОМЭКСПО-2020 при участии представителей федеральных и региональных органов власти, институтов развития и руководителей университетов, госкорпораций и компаний.
На стратегической сессии были представлены экспертные доклады по семи инициативам:
- Программа «Приоритет 2030».
- Проект «Делаем науку в России».
- Проект «Платформа университетского технопредпринимательства».
- Проект «Повод для гордости: массовая основа инновационной системы».
- Проект «Экспансия российского образования».
- Проект «Сетевые программы научно-технологического прорыва».
- Проект «Новое инженерное образование».
С ректорами также обсуждались вопросы повышения уровня знаний самих преподавателей вузов. Ректоры и представители индустрии обсудили, как масштабирование дополнительного образования сократит разрыв между индустрией и образовательными программами в организациях высшего и среднего профессионального образования с учетом меняющихся требований к компетенциям выпускников по всем направлениям обучения.
Итоговая сводная позиция проведенной стратегической сессии была представлена на совещании «Кадры для будущего», которое прошло под председательством вице-премьера Дмитрия Чернышенко. В совещании приняли участие президент Республики Татарстан Рустам Минниханов, министр науки и высшего образования России Валерий Фальков, министр просвещения России Сергей Кравцов, заместитель министра цифрового развития России Евгений Кисляков, заместитель министра экономического развития России Оксана Тарасенко. В очном и заочном форматах к совещанию присоединились более 500 ректоров ведущих университетов страны (в том числе МГУ, МГТУ, МФТИ, МИФИ, СПбГУ, СПбПУ, ИТМО, МИСиС, МЭИ, УрФУ, КФУ и др.), а также представители Яндекса, Mail.ru, Сбера, X5 Retail Group, РЖД, Аэрофлота и Росатома – всего около 1000 участников.
На встрече обсуждались задачи обновления образовательных программ высшего и среднего профессионального образования в целях подготовки кадров для отраслей экономики, а также механизмы устранения дефицита IT-кадров с помощью государственных программ, в том числе федерального проекта «Кадры для цифровой экономики».
«Сегодня был очень важный день. Мы провели масштабную встречу, в которой участвовало онлайн и лично около 500 ректоров, представителей бизнеса и руководителей федеральных органов власти. Обсуждались очень важные вопросы, в том числе и подготовка Стратегии социально-экономического развития, которой занимается сейчас Правительство.
И основа ее – это, конечно, кадры. И очень важные решения были приняты. Основные изменения, касающиеся стандартов образования, создания цифровых образовательных модулей по всем направлениям, должны быть сделаны до следующего цикла обучения. Это сложная, амбициозная задача, мы отдаём себе отчет в том, что это будет непросто сделать, но именно такой темп нам задают текущие задачи, которые поставил Президент перед Правительством.
И времени на раскачку нет».
Заместитель председателя Правительства РФ
Дмитрий Чернышенко
По словам Дмитрия Чернышенко, задача ректоров: обеспечить качественную подготовку кадров, актуализацию образовательных программ, вести инновационную деятельность и формировать полноценную стратегию развития университета.
«Я очень благодарен коллегам за то, что они активно включились в работу, сегодня показали результаты деятельности рабочих групп, которые вселяют уверенность, что мы действительно сможем преодолеть имеющийся дефицит кадров», – отметил вице-премьер.
Президент Республики Татарстан Рустам Минниханов поблагодарил всех за участие в продуктивном диалоге и за выбор площадки.
«Совещание прошло в Иннополисе – самом молодом и высокотехнологичном городе страны. Уверен, что опыт Университета Иннополис позволит качественно готовить кадры для цифровой экономики, объединить методические ресурсы ведущих вузов страны, лучшие мировые практики. Бурный рост цифровых технологий оказывает существенное влияние на все сферы деятельности. Перед нами стоит важная задача – устранить разрыв, имеющийся между формируемыми у студентов компетенциями и реальными потребностями работодателей. Необходимо эффективное взаимодействие образовательных организаций и индустриальных компаний. Задачи по проекту заявлены, действительно, амбициозные», – заявил Рустам Нургалиевич.
Стоит отметить, что в Институте передовых производственных технологий (ИППТ) СПбПУ осуществляется образовательная модель «Университет 4.0» – Университет, который формирует федеральную повестку, в данном, a случае в области передовых цифровых и производственных технологий, решает сложные наукоемкие мультидисциплинарные «нерешаемые» задачи, которые по разным причинам не могут решить промышленные предприятия, и, конечно, выпускники которого полностью интегрированы в Индустрию 4. 0.
0.
«Университет 4.0» – это модель образовательного учреждения или его подразделения нового типа. Оно берется за решение важных задач, которые промышленность на нынешнем этапе считает ”нерешаемыми”. Такой университет готовит специалистов, которые в состоянии преодолеть глобальные технологические проблемы и вывести технологии на новую, пока не взятую высоту. Продукт мирового уровня можно создать, только применяя передовые технологии мирового уровня. Если хотя бы одна технология окажется на уровень ниже, то и характеристики всего продукта, скорее всего, упадут на этот уровень.
Выпускник Университета 4.0 – это компетентный эксперт, который работает по принципу «знание в действии». В нашей области у такого специалиста должно быть очень хорошее фундаментальное физико-математическое и инженерно-техническое образование. Дальнейшее обучение происходит в рамках выполнения проектов разного уровня сложности, как правило, в команде.
Важно, что оно проходит интенсивно и быстро. Использование передовых цифровых технологий и цифровых платформ, например, суперкомпьютерных технологий и технологий современного цифрового инжиниринга, приводит к тому, что сложна научно-технологическая задача, на решение которой раньше уходили годы, может быть решена за несколько месяцев.Именно так работает предлагаемый нами акселератор инжиниринговых центров в рамках создаваемой нами сети зеркальных инжиниринговых центров (на базе университетов, корпораций или региональных инжиниринговых це6тров). Выбирается пилотный проект и формируется смешанная команда для его решения, состоящая из инженеров нашего индустриального партнера и инженеров Центра компетенций НТИ СПбПУ. Это должен быть коллектив единомышленников, готовых использовать самые современные методы и инструменты. Ведь любая новая промышленная революция – это прежде всего изменение технологии мышления человека».
Проректор по перспективным проектам СПбПУ, руководитель Научного центра мирового уровня «Передовые цифровые технологии» и Центра компетенций НТИ СПбПУ «Новые производственные технологии», руководитель Инжинирингового центра CompMechLab® СПбПУ
Алексей Боровков
Сегодня Центр НТИ СПбПУ, действующий на базе ИППТ СПбПУ, реализует масштабный проект «Разработка и апробация модели современной подготовки инженеров – «ADVANCED ENGINEERING SCHOOL». Первый этап этого мероприятия прошел в феврале 2020 года – в ходе визита в Центр НТИ СПбПУ Петр Щедровицкий выступил с лекцией «Опережающая подготовка инженерных кадров как приводной ремень догоняющих индустриализаций России». Вторым этапом стала ВКС-конференция «СОВРЕМЕННАЯ ПОДГОТОВКА ИНЖЕНЕРОВ», которая состоялась в июне 2020 года. Мероприятие привлекло внимание большого количества специалистов – участниками конференции стали 202 человека – представителя более 30 университетов из 21 города России. Одним из ключевых спикеров мероприятия стал министр науки и высшего образования РФ Валерий Фальков.
Первый этап этого мероприятия прошел в феврале 2020 года – в ходе визита в Центр НТИ СПбПУ Петр Щедровицкий выступил с лекцией «Опережающая подготовка инженерных кадров как приводной ремень догоняющих индустриализаций России». Вторым этапом стала ВКС-конференция «СОВРЕМЕННАЯ ПОДГОТОВКА ИНЖЕНЕРОВ», которая состоялась в июне 2020 года. Мероприятие привлекло внимание большого количества специалистов – участниками конференции стали 202 человека – представителя более 30 университетов из 21 города России. Одним из ключевых спикеров мероприятия стал министр науки и высшего образования РФ Валерий Фальков.
Поделиться записью
Клуб детского скалолазания O’Skal
Территория O`Skal — 2021
Фестиваль и Открытое Первенство пройдут 23-25 апреля! Регистрация открыта
ЗарегистрироватьсяС 1 ноября мы объявляем набор в группы по акробатике
Тренировки с мастером спорта по спортивной акробатике
Записаться Мы в Telegram
Будьте в курсе наших новостей!
Подписывайтесь на наш канал в Telegram!
Мы всегда на связи в чате канала. Вы можете задавать вопросы напрямую тренерскому составу и администрации.
Вы можете задавать вопросы напрямую тренерскому составу и администрации.
Еще вас ждут online тренировки, полезные видео и информация о предстоящих и прошедших мероприятиях клуба О-скал.
ПОДПИСАТЬСЯНабор в группы!
Клуб детского скалолазания O’Skal проводит набор в группы!
Присоединяйтесь к нам!
Определение примера Merriam-Webster
пример | \ ig-ˈzam-pəl \1 : тот, который служит образцом, который можно имитировать или не подражать. хороший пример
2 : наказание, наложенное на кого-то в качестве предупреждения другим. также : человек, наказанный таким образом
также : человек, наказанный таким образом
3 : один, который представляет всю группу или тип
4 : параллельный или очень похожий случай, особенно если он служит прецедентом или моделью
5 : пример (например, проблема, которую необходимо решить), служащий для иллюстрации правила или предписания или для действия в качестве упражнения в применении правила.
Например \ fər- ig- ˈzam- pəl , фриг- \: в качестве примера есть много источников загрязнения воздуха; выхлопные газы, например
exampled; экзамен \ ig- ˈzam- p (ə-) liŋ \переходный глагол
1 : , чтобы служить примером
2 архаичный : быть или показать пример
Образец эссе 1 Богард | Набор оценок SAT
Пол Богард, уважаемый и увлеченный писатель, предлагает убедительный аргумент в пользу того, чтобы позволить большему количеству тьмы заполнить землю по определенным причинам, связанным со здоровьем и окружающей средой. Поскольку свет является таким огромным фактором в повседневной жизни, мы иногда забываем, что тьма может иметь больше исцеляющих способностей и позволяет природе вернуться в неискусственное, примитивное состояние. Богард использует личные наблюдения для достоверности, пробуждая чувства и поразительные факты, чтобы привести веские аргументы.
Поскольку свет является таким огромным фактором в повседневной жизни, мы иногда забываем, что тьма может иметь больше исцеляющих способностей и позволяет природе вернуться в неискусственное, примитивное состояние. Богард использует личные наблюдения для достоверности, пробуждая чувства и поразительные факты, чтобы привести веские аргументы.
На протяжении всего отрывка Богард ностальгирует о своем детстве: «В семейной хижине на озере Миннесота я знал лес настолько темный, что мои руки исчезли у меня на глазах.Я знал ночное небо, в котором метеоры оставляли дымные следы на сладких полосах звезд … В это зимнее солнцестояние, когда мы приветствуем постепенное движение дней назад к свету, давайте также вспомним о незаменимой ценности тьмы ». Описание природы и потрясающе красивые изображения вызывают чувство глубокого уважения к тьме. Мы разделяем точку зрения Богарда, и в результате Богард пользуется неоспоримым авторитетом. Богард знает силу тьмы, и благодаря его детским воспоминаниям мы наклоняем уши, чтобы слушать его.
Несмотря на то, что в этом отрывке много раз появляется достоверность, оно не имело бы реального значения, если бы не вызывало эмоции. Богард поражает людей, которые с ним не согласны, когда он говорит: «Нашему телу нужна темнота для выработки гормона мелатонина, который не дает развиваться некоторым видам рака, а нашим телам нужна темнота для сна. Нарушения сна связаны с диабетом, ожирением, сердечно-сосудистыми заболеваниями и депрессией, и недавние исследования показывают, что одной из основных причин «короткого сна» является «долгий свет».Заявление Богарда развеивает любые сомнения, но порождает новые чувства. Наконец-то мы видим истинную важность того, чтобы позволить нашему миру временно поддаться тьме. Из-за эмоций, которые вызывает Богард, мы внезапно начинаем защищаться, пытаясь сохранить тьму ради нашего психического и физического здоровья. Богард даже заставляет задуматься о будущих поколениях: «В мире, наполненном электрическим светом . .. как Ван Гог подарил бы миру свою« звездную ночь »? Кто знает, что это видение ночного неба должно вдохновить каждого из нас, наших детей или внуков? »
.. как Ван Гог подарил бы миру свою« звездную ночь »? Кто знает, что это видение ночного неба должно вдохновить каждого из нас, наших детей или внуков? »
Чтобы добиться должного доверия и вызвать эмоции, в отрывке должны находиться неопровержимые факты.Богард завершил свое исследование и использует его в своих рассуждениях: «Остальной мир также зависит от темноты, включая ночные и сумеречные виды птиц, насекомых, млекопитающих, рыб и рептилий. Некоторые примеры хорошо известны — 400 видов птиц, мигрирующих по ночам в Северной Америке, морские черепахи, которые приходят отложить яйца, — а некоторые нет, например летучие мыши, которые спасают миллиарды американских фермеров в борьбе с вредителями, и мотыльки, которые опыляют 80% мировой флоры ». Используя факты о животных, Богард расширяет аргумент за пределы людей, позволяя нам увидеть, что тьма влияет не только на нас, но и на всю природу.Затем Богард говорит: «В Соединенных Штатах и Западной Европе количество света в небе увеличивается в среднем примерно на 6% каждый год … Большая часть этого света — это потраченная впустую энергия, что означает потраченные впустую доллары. Те из нас, кто старше 35 лет, возможно, относятся к последнему поколению, знавшему поистине темные ночи ». Тем не менее, Богард расширяет факты, предлагая различные решения для бесполезного и чрезмерного освещения, такие как замена светодиодных уличных фонарей и сокращение использования света в общественных зданиях и домах в ночное время.Богард создает наш мир, а затем ломает его в наших умах, написав: «Проще говоря, без темноты экология Земли рухнет …»
Согласно Богарду, мы все еще можем спасти наш мир. Мы должны видеть силу и красоту в темноте и помнить, как наш мир выжил без огней. Свет может быть приемлемым, но его слишком много может оказаться хуже постоянной темноты.
Этот ответ получил 4/3/4.
Чтение — 4: Этот ответ демонстрирует полное понимание текста Богарда. Автор улавливает центральную идею отрывка из источника ( важность того, чтобы больше тьмы заполняло землю по определенным причинам для здоровья и экологии, ) и точно цитирует и перефразирует многие важные детали отрывка. Более того, писатель демонстрирует понимание того, как эти идеи и детали взаимосвязаны. В третьем абзаце, например, автор показывает движение аргумента Богарда от людей к животным и от проблем к решениям () Используя факты о животных, Богард расширяет аргумент за пределы людей… Богард расширяет факты, предлагая различные решения (). Ответ не содержит ошибок фактов и интерпретаций. В целом, этот ответ демонстрирует развитое понимание прочитанного.
Автор улавливает центральную идею отрывка из источника ( важность того, чтобы больше тьмы заполняло землю по определенным причинам для здоровья и экологии, ) и точно цитирует и перефразирует многие важные детали отрывка. Более того, писатель демонстрирует понимание того, как эти идеи и детали взаимосвязаны. В третьем абзаце, например, автор показывает движение аргумента Богарда от людей к животным и от проблем к решениям () Используя факты о животных, Богард расширяет аргумент за пределы людей… Богард расширяет факты, предлагая различные решения (). Ответ не содержит ошибок фактов и интерпретаций. В целом, этот ответ демонстрирует развитое понимание прочитанного.
Анализ — 3: Писатель демонстрирует понимание аналитической задачи, анализируя три способа, которыми Богард строит свои аргументы ( личных наблюдений за достоверностью, пробуждающими чувствами и поразительными фактами для подачи убедительного аргумента ). На протяжении всего ответа автор обсуждает использование Богардом этих трех элементов и может пройти мимо, утверждая их значение, чтобы провести эффективный анализ воздействия этих методов на аудиторию Богарда.Эффективный анализ очевиден в первом абзаце основного текста, в котором автор обсуждает возможную реакцию аудитории на чтение об опыте Богарда с темнотой в детстве ( Богард знает силу тьмы, и через его детские воспоминания мы наклоняем уши, чтобы слушать его. ). Во втором основном абзаце автор утверждает, что заявление Bogard развеивает любые сомнения, но порождает новое чувство. Наконец-то мы видим истинную важность того, чтобы позволить нашему миру временно поддаться тьме.Из-за эмоций, которые вызывает Богард, мы внезапно начинаем защищаться, пытаясь сохранить тьму ради нашего психического и физического здоровья . Эти точки анализа были бы сильнее, если бы автор подробно остановился на том, как они работают, чтобы построить аргумент Богарда. Однако автор компетентно оценивает использование Богардом личных наблюдений, эмоций и фактов и обеспечивает релевантную и достаточную поддержку каждого утверждения, демонстрируя эффективный анализ.
Письмо — 4: Писатель демонстрирует очень эффективное использование и владение языком в этом связном ответе.Ответ включает точное центральное утверждение ( Богард использует личные наблюдения для достоверности, пробуждая чувства и поразительные факты, чтобы представить мощный аргумент ), и каждый из последующих абзацев по-прежнему сосредоточен на одной из тем, изложенных в этом центральном утверждении. Есть намеренное развитие идей как внутри абзацев, так и на протяжении всего ответа. Более того, ответ демонстрирует точный выбор слов и изощренные обороты ( временно впадают в темноту , испытывает ностальгию по своему детству , развеивает любые сомнения ).Заключительный абзац развивает эссе, а не просто повторяет сказанное, а также удачен благодаря точному выбору слов и сложной структуре предложений ( Мы должны видеть силу и красоту в темноте и помнить, как наш мир выжил без света. Свет может быть приемлемым, но слишком много может оказаться хуже, чем постоянная темнота ). Хотя иногда случаются ошибки, когда писатель перегибает палку с речью ( Чтобы добиться должного доверия и вызвать эмоции, неопровержимые факты должны содержаться в отрывке ), в целом этот ответ демонстрирует продвинутые навыки письма.
Учебное пособие поPyplot — документация Matplotlib 3.4.1
Введение в интерфейс pyplot.
Введение в pyplot
matplotlib.pyplot — это набор функций
которые заставляют matplotlib работать как MATLAB.
Каждая функция pyplot делает
некоторые изменения в фигуре: например, создает фигуру, создает область построения
на рисунке рисует несколько линий в области рисования, украшает сюжет
с этикетками и пр.
В matplotlib.pyplot различные состояния сохраняются
между вызовами функций, чтобы отслеживать такие вещи, как
текущий рисунок и область построения, а также график
функции направлены на текущие оси (обратите внимание, что здесь «оси»
и в большинстве мест в документации упоминается ось часть фигуры
а не строгий математический термин для более чем одной оси).
Примечание
API pyplot обычно менее гибок, чем объектно-ориентированный API.
Большинство вызовов функций, которые вы видите здесь, также можно вызывать как методы.
из объекта Axes .Мы рекомендуем просмотреть учебные пособия и
примеры, чтобы увидеть, как это работает.
Создание визуализаций с помощью pyplot выполняется очень быстро:
Вам может быть интересно, почему по оси X находятся значения от 0 до 3, а по оси Y
с 1-4. Если вы предоставите один список или массив для участок , matplotlib предполагает, что это
последовательность значений y, и автоматически генерирует значения x для
ты. Поскольку диапазоны Python начинаются с 0, вектор x по умолчанию имеет
той же длины, что и y, но начинается с 0. Следовательно, данные x [0, 1, 2, 3] .
plot — это универсальная функция, которая принимает произвольное количество
аргументы. Например, чтобы построить график зависимости x от y, вы можете написать:
Вышел:
[<объект matplotlib.lines.Line2D в 0x7f5effdf1760>]
Форматирование стиля вашего сюжета
Для каждой пары аргументов x, y существует необязательный третий аргумент. это строка формата, указывающая цвет и тип линии сценарий. Буквы и символы строки формата взяты из MATLAB, и вы объединяете строку цвета со строкой стиля линии.Строка формата по умолчанию — «b-», которая представляет собой сплошную синюю линию. Для Например, чтобы отобразить вышеупомянутое с красными кружками, вы должны ввести
plt.plot ([1, 2, 3, 4], [1, 4, 9, 16], 'ro') plt.axis ([0, 6, 0, 20]) plt.show ()
Полную информацию см. В документации по plot .
список стилей линий и форматных строк. В
Ось Функция в приведенном выше примере принимает
список [xmin, xmax, ymin, ymax] и определяет область просмотра
топоры.
Если бы matplotlib был ограничен работой со списками, было бы справедливо
бесполезен для обработки чисел. ‘)
plt.show ()
‘)
plt.show ()
Построение со строками ключевых слов
В некоторых случаях у вас есть данные в формате, который позволяет вам
доступ к определенным переменным с помощью строк. Например, с numpy.recarray или панд.DataFrame .
Matplotlib позволяет предоставить такой объект с помощью
аргумент ключевого слова data . Если предоставлено, вы можете создавать графики с помощью
строки, соответствующие этим переменным.
График с категориальными переменными
Также возможно построить график с использованием категориальных переменных.Matplotlib позволяет передавать категориальные переменные напрямую в множество функций построения графиков. Например:
Свойства управляющей линии
Линии имеют множество атрибутов, которые вы можете установить: ширину линии, стиль штриха,
сглаживание и т. д .; см. matplotlib.lines.Line2D . Есть
несколько способов установить свойства линии
Использовать аргументы ключевого слова:
Используйте методы установки экземпляра
Line2D.сюжетвозвращает списокобъектов Line2D; е.г.,строка1, строка2 = график (x1, y1, x2, y2). В коде ниже мы предположим, что у нас есть только одна строка, чтобы возвращаемый список имел длину 1. Мы используем распаковку кортежей сстрока,, чтобы получить первый элемент этого списка:Используйте
setp. Пример ниже использует функцию в стиле MATLAB для установки нескольких свойств в списке строк.setpпрозрачно работает со списком объектов или отдельный объект. Вы можете использовать аргументы ключевого слова python или Пары строка / значение в стиле MATLAB:строк = plt.сюжет (x1, y1, x2, y2) # используйте ключевые слова args plt.setp (линии, цвет = 'r', ширина линии = 2,0) # или пары строковых значений стиля MATLAB plt.
 setp (линии, 'цвет', 'r', 'ширина линии', 2.0)
setp (линии, 'цвет', 'r', 'ширина линии', 2.0)
Вот доступные свойства Line2D .
| Свойство | Тип значения |
|---|---|
| альфа | поплавок |
| анимированные | [Верно | Ложь] |
| сглаживание или | [Верно | Ложь] |
| clip_box | матплотлиб.transform.Bbox экземпляр |
| клипса_он | [Верно | Ложь] |
| clip_path | экземпляр Path и экземпляр Transform, патч |
| цвет или c | любой цвет matplotlib |
| содержит | функция проверки попадания |
| dash_capstyle | [ «стык» | «круглый» | «выступающий» ] |
| dash_joinstyle | [ 'митра' | «круглый» | «скос» ] |
| тире | последовательность включения / выключения чернил в точках |
| данные | (нп.массив xdata, np.array ydata) |
| фигура | экземпляр matplotlib.figure.Figure |
| этикетка | любая строка |
| linestyle или ls | [ '-' | '-' | '-.' | ':' | «ступеньки» | …] |
| ширина линии или lw | значение с плавающей запятой в пунктах |
| маркер | [ '+' | ',' | '.' | '1' | '2' | '3' | '4' ] |
| markeredgecolor или mec | любой цвет matplotlib |
| markeredgewidth или mew | значение с плавающей запятой в пунктах |
| markerfacecolor или mfc | любой цвет matplotlib |
| размер маркера или мс | поплавок |
| markevery | [Нет | целое | (начало, шаг)] |
| подборщик | используется в интерактивном выборе строки |
| радиус обзора | радиус выбора линии выбора |
| solid_capstyle | [ «стык» | «круглый» | «выступающий» ] |
| solid_joinstyle | [ 'митра' | «круглый» | «скос» ] |
| преобразование | матплотлиб. transforms.Transform instance transforms.Transform instance |
| видимый | [Верно | Ложь] |
| xdata | np.array |
| ярдов | np.array |
| zorder | любой номер |
Чтобы получить список настраиваемых свойств линии, вызовите setp функция со строкой или строками в качестве аргумента
В [69]: lines = plt.plot ([1, 2, 3]) В [70]: plt.setp (строки) альфа: плавать анимированные: [True | Ложь] сглаживание или aa: [True | Ложь] ...щипнуть
Работа с несколькими фигурами и осями
MATLAB и pyplot имеют концепцию текущего рисунка
и текущие оси. Все функции построения графика применяются к текущему
топоры. Функция gca возвращает текущие оси (a matplotlib.axes.Axes instance), а gcf возвращает текущий
figure (экземпляр matplotlib.figure.Figure ). Обычно вам не нужно
беспокоиться об этом, потому что все это делается за кулисами.Ниже
сценарий для создания двух подзаговоров.
def f (t):
вернуть np.exp (-t) * np.cos (2 * np.pi * t)
t1 = np.arange (0,0; 5,0; 0,1)
t2 = np.arange (0,0; 5,0; 0,02)
plt.figure ()
plt.subplot (211)
plt.plot (t1, f (t1), 'bo', t2, f (t2), 'k')
plt.subplot (212)
plt.plot (t2, np.cos (2 * np.pi * t2), 'r--')
plt.show ()
Фигурка Вызов здесь не является обязательным, потому что цифра будет создана
если ничего не существует, так же будут созданы оси (эквивалентно явному subplot () call), если таковой не существует.Вызов подзаголовка указывает чисел,
numcols, plot_number , где plot_number варьируется от 1 до числа * число . Запятые в подзаголовке называют
необязательно, если numrows * numcols <10 . Итак, подзаголовок (211) идентичен
к подзаговору (2, 1, 1) .
Вы можете создать произвольное количество подзаговоров
и топоры. Если вы хотите разместить оси вручную, т.е. не на
прямоугольная сетка, использовать оси ,
что позволяет указать местоположение как осей ([слева, снизу,
ширина, высота]) , где все значения в дробном (от 0 до 1)
координаты.См. Демонстрацию Axes для примера
размещение осей вручную и демонстрация базового подсюжета для
пример с большим количеством сюжетов.
Вы можете создать несколько фигур, используя несколько цифра звонков с возрастающей цифрой
номер. Конечно, каждая фигура может содержать столько осей и подзаголовков.
как душе угодно:
Вы можете очистить текущую цифру с помощью clf и текущие оси с cla . Если ты найдешь
раздражает то, что состояния (в частности, текущее изображение, фигура и оси)
поддерживаются за кулисами, не отчаивайтесь: это всего лишь тонкая
оболочка с отслеживанием состояния вокруг объектно-ориентированного API, которую вы можете использовать
вместо этого (см. руководство художника)
Если вы делаете много фигур, вам нужно знать об одной
еще: память, необходимая для фигуры, не полностью
выпущен до тех пор, пока фигура не будет явно закрыта с помощью закрыть .Удаление всех ссылок на
рисунок и / или с помощью оконного менеджера, чтобы убить окно, в котором
фигура появляется на экране, этого недостаточно, потому что pyplot
поддерживает внутренние ссылки до закрыть называется.
Работа с текстом
текст можно использовать для добавления текста в произвольном месте и xlabel , ylabel и title используются для добавления
текст в указанных местах (см. Текст в графиках Matplotlib для
более подробный пример)
мю, сигма = 100, 15 х = му + сигма * нп.random.randn (10000) # гистограмма данных n, ячейки, участки = plt.hist (x, 50, плотность = 1, цвет лица = 'g', альфа = 0,75) plt.xlabel ("Умные") plt.ylabel ('Вероятность') plt.title ('Гистограмма IQ') plt.text (60, 0,025, r '$ \ mu = 100, \ \ sigma = 15 $') plt.axis ([40, 160, 0, 0,03]) plt.grid (Истина) plt.show ()
Все функции text возвращают matplotlib.text.Text пример. Как и в случае со строками выше, вы можете настроить свойства,
передача аргументов ключевого слова в текстовые функции или использование setp :
Эти свойства более подробно описаны в разделе «Свойства текста и макет».
Использование математических выражений в тексте
matplotlib принимает выражения уравнений TeX в любом текстовом выражении. Например, чтобы написать выражение \ (\ sigma_i = 15 \) в заголовке, вы можете написать выражение TeX, окруженное знаками доллара:
Значение r перед строкой заголовка важно - оно означает
что строка является необработанной строкой и не обрабатывает обратную косую черту как
питон ускользает. matplotlib имеет встроенный анализатор выражений TeX и
механизм компоновки и поставляет собственные математические шрифты - подробности см.
Написание математических выражений.Таким образом, вы можете использовать математический текст на разных платформах.
без установки TeX. Для тех, у кого есть LaTeX и
dvipng, вы также можете использовать LaTeX для форматирования текста и
включить вывод непосредственно в отображаемые цифры или сохранить
постскриптум - см. Рендеринг текста с помощью LaTeX.
Аннотирующий текст
Использование основной функции text выше
разместить текст в произвольной позиции на осях. Обычное использование для
текст должен аннотировать некоторые особенности сюжета, а аннотировать метод предоставляет помощника
функциональность для упрощения аннотаций.В аннотации есть
два момента, которые следует учитывать: аннотируемое местоположение, представленное
аргумент xy и расположение текста xytext . Оба
эти аргументы -
Оба
эти аргументы - (x, y) кортежей.
ax = plt.subplot ()
t = np.arange (0,0; 5,0; 0,01)
s = np.cos (2 * np.pi * t)
линия, = plt.plot (t, s, lw = 2)
plt.annotate ('локальный максимум', xy = (2, 1), xytext = (3, 1.5),
arrowprops = dict (цвет лица = 'черный', усадка = 0,05),
)
plt.ylim (-2, 2)
plt.показывать()
В этом базовом примере и xy (кончик стрелки), и xytext местоположения (расположение текста) находятся в координатах данных. Есть
множество других систем координат, которые можно выбрать - см.
Основные аннотации и расширенные аннотации для
подробности. Больше примеров можно найти в
Аннотирование сюжетов.
Логарифмические и прочие нелинейные оси
matplotlib.pyplot поддерживает не только шкалы линейных осей, но и
логарифмическая и логитовая шкалы.Это обычно используется, если данные охватывают много заказов.
величины. Изменить масштаб оси очень просто:
plt.xscale ('журнал')
Пример четырех графиков с одинаковыми данными и разными масштабами для оси y показано ниже.
# Исправление случайного состояния для воспроизводимости
np.random.seed (19680801)
# составляем данные в открытом интервале (0, 1)
y = np.random.normal (loc = 0,5, масштаб = 0,4, размер = 1000)
y = y [(y> 0) & (y <1)]
y.sort ()
x = np.arange (len (y))
# график с различными масштабами осей
plt.фигура()
# linear
plt.subplot (221)
plt.plot (x, y)
plt.yscale ('линейный')
plt.title ('линейный')
plt.grid (Истина)
# бревно
plt.subplot (222)
plt.plot (x, y)
plt.yscale ('журнал')
plt.title ('журнал')
plt.grid (Истина)
# симметричный бревно
plt.subplot (223)
plt.plot (x, y - y.mean ())
plt.yscale ('символический журнал', linthresh = 0,01)
plt.title ('символический журнал')
plt.grid (Истина)
# логит
plt.subplot (224)
plt.plot (x, y)
plt.yscale ('логит')
plt.title ('логит')
plt.grid (Истина)
# Отрегулируйте макет подзаголовка, потому что логит может занять больше места
# чем обычно, из-за меток y-галочки, таких как "1 - 10 ^ {- 3}"
plt. subplots_adjust (вверху = 0,92, внизу = 0,08, слева = 0,10, справа = 0,95, hspace = 0,25,
wspace = 0,35)
plt.show ()
subplots_adjust (вверху = 0,92, внизу = 0,08, слева = 0,10, справа = 0,95, hspace = 0,25,
wspace = 0,35)
plt.show ()
Также можно добавить свой собственный масштаб, см. Руководство разработчика по созданию масштабов и преобразований для подробности.
Общее время работы скрипта: (0 минут 3,431 секунды)
Ключевые слова: пример кода matplotlib, кодекс, график python, pyplot Галерея создана Sphinx-Gallery
основных запятых использует
основных запятых2005, 2002, 1987 Маргарет Л.Беннер Все права защищены.
ЗАПЯТАЯ ПРАВИЛО № 1 ЗАПЯТАЯ В РЯДЕ : Используйте запятые для разделения элементов в серии.
Что такое серия?
Серия - это список из 3 или более элементов, последние два из которых являются присоединились и , или , или или .
_____________ , ______________ , и _____________
ПРИМЕРЫ:
Любое из них может быть заключено в приговор форма.
Важные вещи, о которых нужно помнить с использованием запятых в ряд это:
1. Серия включает 3 или более элементов одного типа (слова или группы слова).
2. Последовательность связана с и , или , или или перед последним элементом.
3. Запятая разделяет элементы в серии, включая последний элемент перед ним. по и , или , или или .
Теперь щелкните ссылку ниже, чтобы выполнить упражнение. 1.
Ссылка на упражнение 1
ЗАПЯТАЯ ПРАВИЛО № 2 ЗАПЯТАЯ С КООРДИНАТНЫМИ ПРИЛАГАЮЩИМИ : Используйте запятые между координатными прилагательными.
Что такое согласовывать прилагательные?
Координатные прилагательные - это прилагательные, помещенные рядом
друг другу равные по важности.
Два следующие тесты для определения согласованности прилагательных:
1. Посмотрите, можно ли и можно ли плавно разместить между ними.
2. Посмотрите, можно ли поменять порядок прилагательных на обратный.
Взгляните на этот пример.
В этом примере запятая находится между счастливый и живой потому что они координируют прилагательные.
Проверка для подтверждения:
Сначала , попробуй и протестируй.
и помещается между 2 прилагательные звучат гладко.
Второй , попробуйте поменять местами прилагательные.
Когда прилагательные меняются местами, предложение по-прежнему имеет смысл.
Таким образом, , счастливый и lively - это координатные прилагательные в примере, которые должны быть через запятую.
ВНИМАНИЕ! Не все пары прилагательных координировать прилагательные. Таким образом, не все прилагательные отделяются друг от друга запятой.
Посмотрите на этот пример.
В этом примере запятая не принадлежит между двумя прилагательными молодой и золотой потому что это , а не координатных прилагательных.
Как мы можем узнать?
Сначала , попробуй и протестируй.
и помещены между двумя прилагательные не соответствуют .
Второй , попробуйте поменять местами прилагательные.
Когда два прилагательных меняются местами, они имеют смысл , а не .
Таким образом, , молодой и золотой являются , а не координатными прилагательными и не должны разделяться запятой.
Теперь щелкните ссылку ниже, чтобы выполнить упражнение. 2.
2.
Ссылка на упражнение 2
ЗАПЯТАЯ ПРАВИЛО № 3 ЗАПЯТАЯ В A СЛОЖНОЕ ПРЕДЛОЖЕНИЕ : используйте запятую перед и, но, или, ни, для, так, или , но , чтобы соединить два независимые предложения, образующие составное предложение.
Что такое сложное предложение?
Соединение Предложение - это предложение, которое имеет 2 независимых предложения .
независимый пункт - это группа слов с подлежащим и глаголом, которые выражают полный мысль. Он также известен как простое предложение . Независимое предложение может стоять отдельно как предложение.
Два независимых предложения в К составному предложению можно присоединить:
A. Точка с запятой
ИЛИ
B. Запятая и одно из семи соединяющихся слов: для, и, ни, но, или, тем не менее, и так . (Взятые вместе первые буквы составляют FANBOYS. )
Последний тип составного предложения тот, на котором мы сконцентрируемся при использовании запятых.
В составном предложении должно быть два независимые предложения, а не просто два глагола, два существительных или две группы слов это , а не независимых статей.
Посмотрите на этот пример.
В приведенном выше примере две группы глаголов присоединяются и . Вторая группа глаголов делает НЕ есть тема; таким образом, это НЕ независимый пункт.
Следовательно, НЕТ запятая стоит перед и .
Это пример простой предложение с соединением глагол , а не сложное предложение.
Однако мы можем преобразовать это предложение в
составное предложение, просто превратив последнюю часть глагола в независимую
пункт.
Теперь у нас есть добросовестный состав приговор. Два независимых предложения разделяются запятой и словом и .
Вот еще несколько примеров, проиллюстрировать разницу между составными элементами в простых предложениях (нет запятая) и истинные составные предложения (запятая).
Теперь вы готовы попробовать упражнение.
Убедитесь, что вы:
1. Знайте семь присоединяющихся слова ( f или, a nd, n или, b ut, o r, y et, с или ).
2. Банка различать простые предложения с составными элементами (без запятой) и составные предложения (запятая).
Теперь щелкните ссылку ниже, чтобы выполнить упражнение. 3.
ССЫЛКА НА УПРАЖНЕНИЕ 3
ЗАПЯТАЯ ПРАВИЛО № 4 ЗАПЯТАЯ С ВВОДНЫЕ СЛОВА : поставьте запятую после вводные фразы, которые говорят , где , когда , почему , или как .
В частности . . . используйте запятую:
1. После длинной вступительной фразы.
Пример:
Обычно НЕ обязательно использовать запятая после коротких вводных предложных фраз.
Пример:
2. После вступительной фразы, состоящей из до плюс, глагол и любой модификаторы (инфинитив), которые говорят , почему .
Пример:
Используйте запятую даже после короткого to + глагол фраза, которая отвечает почему .
Пример:
Вы можете сказать, что у вас есть такой вводная фраза + глагол, когда вы можете расположить слова по порядку в перед фразой.
Пример:
Будьте осторожны! Не все вводные фразы говорят , почему .
3. После вступительного предложения, которое отвечает
После вступительного предложения, которое отвечает
когда? где? Зачем? как? в какой степени?
(Предложение - это группа слов с подлежащее и глагол.)
Примеры:
ПРИМЕЧАНИЕ. Когда такой пункт находится в конце предложения, НЕ используйте запятую.
Примеры:
Теперь щелкните ссылку ниже, чтобы выполнить упражнение. 4.
Ссылка на упражнение 4
ЗАПЯТАЯ ПРАВИЛО № 5 ЗАПЯТАЯ С НЕЕССЕНЦИАЛЬНЫЕ СЛОВА, ФРАЗЫ И ПОЛОЖЕНИЯ: Отдельный через запятую любые несущественные слова или группы слов из остальной части приговор.
1. Отдельные слова прерывания, такие как , но , тем не менее , да , нет , конечно , из остальных приговор.
Примеры:
2. Отделить переименователь ( аппозитив) от остальной части предложения с запятой.
Пример:
3. Отделяйте прилагательные от основных частей предложения.
(Прилагательное описывает или ограничивает существительное.)
Примеры:
В каждом из приведенных выше случаев Мэри Робертс пробежал по улице существенная часть предложения .Прилагательные словосочетания несущественные и должны быть отделены от остальной части предложения запятыми.
4. Отделите несущественные прилагательных от остальной части предложения.
Есть два видов прилагательных:
- тот, который нужен для того, чтобы приговор был полный (ESSENTIAL)
- тот, который НЕ нужен для того, чтобы предложение было полное (НЕОБХОДИМО)
Модель Essential Прилагательное предложение НЕ должно отделяться от предложения запятыми.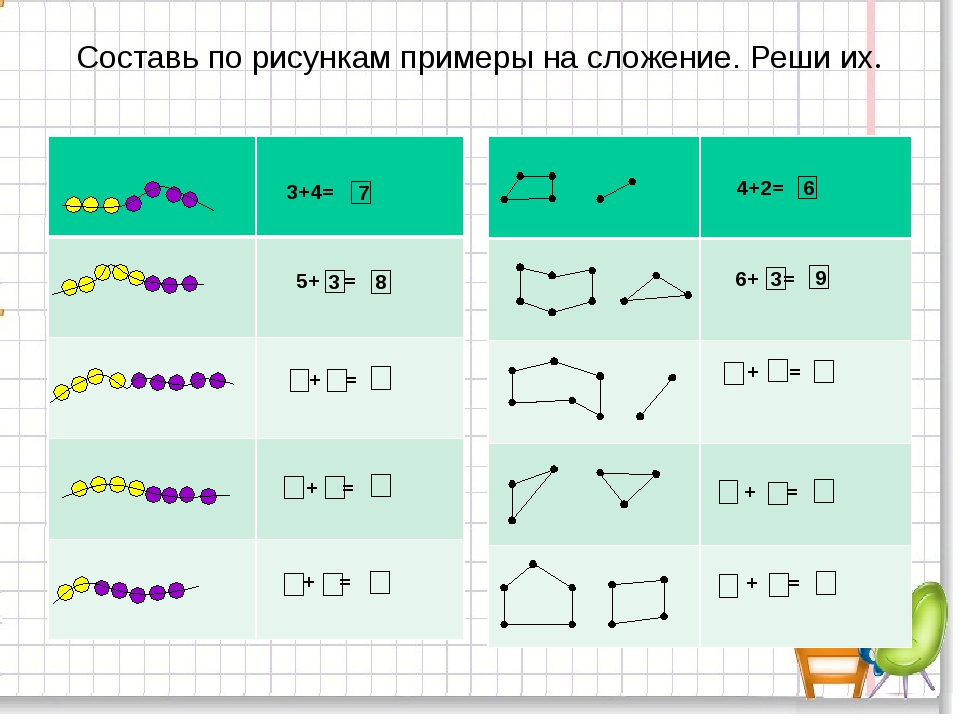
несущественное Прилагательное предложение (как и другие несущественные элементы) СЛЕДУЕТ разделять запятые.
Два примера иллюстрируют разницу:
А.
Б.
Посмотрите на пример A. Если мы удалим прилагательное, ограбившее банк, предложение читает, Мужчина был пойман сегодня.Без прилагательное предложение (кто ограбил банк), мы не знаем , который человек был пойман. Таким образом, прилагательное Предложение необходимо для завершения смысла предложений. Другими словами, это прилагательное существенное . Как отмечается в правилах, , а не , используйте запятые вокруг важных прилагательные.
Теперь посмотрим на пример B. Если мы удалим прилагательное, ограбившее банк, предложение Читает, Сэм Паук был пойман сегодня.Без Прилагательное предложение (кто ограбил банк), мы делаем знать, какой человек был пойман (Сэм Паук). Таким образом, Прилагательное предложение НЕ требуется для завершения смысла предложения. Другими словами, этот пункт несущественный . Следуя правилу, вы должны отделить это прилагательное от остальная часть предложения.
ПОМНИТЕ, есть 4 несущественных элементы, которые следует отделить от остальной части предложения запятыми:
1. такие слова прерывателя, как из конечно , однако
2. переименователи (аппозитивы)
3. несущественные прилагательные
4. несущественные придаточные прилагательныеТеперь щелкните ссылку ниже, чтобы выполнить упражнение. 5.
Ссылка на упражнение 5
Теперь щелкните ссылку ниже, чтобы выполнить пост-тест.
Ссылка на пост-тест
One Sample T Test: как его запустить, шаг за шагом
Тест t для одной выборки сравнивает среднее значение ваших выборочных данных с известным значением. Например, вы можете захотеть узнать, как среднее значение вашей выборки сравнивается со средним значением генеральной совокупности. Если вам неизвестно стандартное отклонение генеральной совокупности или если у вас небольшой размер выборки, вам следует выполнить t-тест для одной выборки. Полное изложение того, какой тест использовать, см .: T-score vs.Z-оценка.
Например, вы можете захотеть узнать, как среднее значение вашей выборки сравнивается со средним значением генеральной совокупности. Если вам неизвестно стандартное отклонение генеральной совокупности или если у вас небольшой размер выборки, вам следует выполнить t-тест для одной выборки. Полное изложение того, какой тест использовать, см .: T-score vs.Z-оценка.
Допущения теста (ваши данные должны соответствовать этим требованиям, чтобы тест был действительным):
Пример одного образца Т-теста
Пример вопроса : ваша компания хочет улучшить продажи. Прошлые данные о продажах показывают, что средняя цена за транзакцию составляла 100 долларов. После обучения вашего торгового персонала последние данные о продажах (взятые из выборки из 25 продавцов) показывают, что средняя сумма продажи составляет 130 долларов США со стандартным отклонением 15 долларов США. Тренинг сработал? Проверьте свою гипотезу на уровне альфа 5%.
Шаг 1. Напишите заявление о нулевой гипотезе (как сформулировать нулевую гипотезу). Принятая гипотеза состоит в том, что разницы в продажах нет, поэтому:
H 0 : μ = 100 долларов.
Шаг 2: Напишите альтернативную гипотезу. Это тот, который вы тестируете. Вы думаете, что - это разница (средний объем продаж увеличился), поэтому:
H 1 : μ> 100 долларов.
Шаг 3. Определите следующие фрагменты информации, которые вам понадобятся для расчета статистики теста.Вопрос должен дать вам следующие предметы:
- Выборочное среднее (x). Это указано в вопросе как 130 долларов.
- Среднее значение населения (μ). Вычислено как 100 долларов (по прошлым данным).
- Стандартное отклонение выборки (s) = 15 долларов США.
- Количество наблюдений (n) = 25.
Шаг 4: Вставьте элементы сверху в формулу t-оценки.
t = (130 - 100) / ((15 / √ (25))
t = (30/3) = 10
Это ваше вычисленное значение t .
Шаг 5: Найдите значение t-таблицы. Чтобы найти это, вам нужно два значения:
- Альфа-уровень: в вопросе задано как 5%.
- Степени свободы, то есть количество элементов в выборке (n) минус 1:25 - 1 = 24.
Найдите 24 степени свободы в левом столбце и 0,05 в верхнем ряду. Пересечение равно 1,711 - это ваше одностороннее критическое значение t.
Это критическое значение означает, что мы ожидаем, что большинство значений будет ниже 1.711. Если наше вычисленное значение t (из шага 4) попадает в этот диапазон, нулевая гипотеза, вероятно, верна.
Шаг 5: Сравните шаг 4 с шагом 5. Значение из шага 4 не попадает в диапазон, рассчитанный на шаге 5, поэтому мы можем отклонить нулевую гипотезу. Значение 10 попадает в область отклонения (левый хвост).
Другими словами, очень вероятно, что средняя продажа больше. Тренинг по продажам, вероятно, прошел успешно.
Хотите проверить свою работу? Взгляните на калькулятор Дэниела Сопера.Просто подключите свои данные, чтобы получить t-статистику и критические значения.
Список литературы
Бейер, В. Х. Стандартные математические таблицы CRC, 31-е изд. Бока Ратон, Флорида: CRC Press, стр. 536 и 571, 2002.
Агрести А. (1990) Анализ категориальных данных. Джон Вили и сыновья, Нью-Йорк.
Фридман (2015). Основы клинических исследований 5-е изд. Спрингер ».
Залкинд, Н. (2016). Статистика для людей, которые (думают, что они) ненавидят Статистика: Использование Microsoft Excel 4-го издания.
Нужна помощь с домашним заданием или контрольным вопросом? С Chegg Study вы можете получить пошаговые ответы на свои вопросы от эксперта в данной области.Ваши первые 30 минут с репетитором Chegg бесплатны!
Комментарии? Нужно опубликовать исправление? Пожалуйста, оставьте комментарий на нашей странице в Facebook .
Изучение PyTorch с примерами - Руководства по PyTorch 1.8.1 + документация cu102
Автор : Джастин Джонсон
Примечание
Это одно из наших старых руководств по PyTorch. Вы можете просмотреть наши последние контент для начинающих в Изучите основы.
В этом руководстве представлены основные концепции PyTorch через автономный Примеры.
По своей сути PyTorch предоставляет две основные функции:
- n-мерный тензор, похожий на numpy, но может работать на графических процессорах
- Автоматическое дифференцирование для построения и обучения нейронных сетей
Мы будем использовать задачу аппроксимации \ (y = \ sin (x) \) полиномом третьего порядка в качестве нашего рабочего примера. Сеть будет иметь четыре параметра и будет обучаться с градиентный спуск для соответствия случайным данным за счет минимизации евклидова расстояния между выходом сети и истинным выходом.
Разминка: numpy
Перед тем, как представить PyTorch, мы сначала реализуем сеть, используя тупой.
Numpy предоставляет объект n-мерного массива и множество функций для манипулирование этими массивами. Numpy - это общая структура для научных вычисления; он ничего не знает о графах вычислений или глубоких обучение или градиенты. Однако мы можем легко использовать numpy для соответствия полином третьего порядка в синусоидальную функцию путем ручной реализации прямого и обратный проход через сеть с использованием numpy-операций:
# - * - кодировка: utf-8 - * -
импортировать numpy как np
импортная математика
# Создание случайных входных и выходных данных
х = нп.3
y_pred = a + b * x + c * x ** 2 + d * x ** 3
# Потеря вычислений и печати
потеря = np.square (y_pred - y) .sum ()
если t% 100 == 99:
print (t, убыток)
# Backprop для вычисления градиентов a, b, c, d с учетом потерь
grad_y_pred = 2,0 * (y_pred - y)
grad_a = grad_y_pred.sum ()
grad_b = (grad_y_pred * x) . 3 ')
3 ')
PyTorch: Тензоры
Numpy - отличный фреймворк, но он не может использовать графические процессоры для ускорения своего численные расчеты.Для современных глубоких нейронных сетей графические процессоры часто обеспечить ускорение в 50 раз или больше, так что к сожалению, numpy недостаточно для современного глубокого обучения.
Здесь мы представляем самую фундаментальную концепцию PyTorch: Tensor . PyTorch Tensor концептуально идентичен массиву numpy: тензор n-мерный массив, а PyTorch предоставляет множество функций для на этих тензорах. За кулисами тензорные системы могут отслеживать вычислительный график и градиенты, но они также полезны как универсальный инструмент для научных вычислений.
Также в отличие от numpy, PyTorch Tensors может использовать графические процессоры для ускорения их числовые вычисления. Чтобы запустить PyTorch Tensor на GPU, вы просто необходимо указать правильное устройство.
Здесь мы используем тензоры PyTorch, чтобы подогнать полином третьего порядка к синусоидальной функции. Как и в приведенном выше примере numpy, нам нужно вручную реализовать переадресацию и обратно проходит по сети:
# - * - кодировка: utf-8 - * -
импортный фонарик
импортная математика
dtype = torch.float
устройство = torch.device ("процессор")
# устройство = фонарик.device ("cuda: 0") # Раскомментируйте это, чтобы запустить на GPU
# Создание случайных входных и выходных данных
x = torch.linspace (-math.pi, math.pi, 2000, устройство = устройство, dtype = dtype)
y = torch.sin (x)
# Произвольно инициализировать веса
a = torch.randn ((), устройство = устройство, dtype = dtype)
b = torch.randn ((), device = device, dtype = dtype)
c = torch.randn ((), устройство = устройство, dtype = dtype)
d = torch.randn ((), устройство = устройство, dtype = dtype)
learning_rate = 1e-6
для t в диапазоне (2000):
# Прямой проход: вычислить прогнозируемое y
y_pred = a + b * x + c * x ** 2 + d * x ** 3
# Потеря вычислений и печати
потеря = (y_pred - y). pow (2) .sum (). элемент ()
если t% 100 == 99:
print (t, убыток)
# Backprop для вычисления градиентов a, b, c, d с учетом потерь
grad_y_pred = 2,0 * (y_pred - y)
grad_a = grad_y_pred.sum ()
grad_b = (grad_y_pred * x) .sum ()
grad_c = (grad_y_pred * x ** 2) .sum ()
grad_d = (grad_y_pred * x ** 3) .sum ()
# Обновить веса с помощью градиентного спуска
a - = скорость_обучения * град_а
b - = скорость_обучения * grad_b
c - = скорость_обучения * град_с
d - = скорость_обучения * град_д
print (f'Result: y = {a.3 ')
pow (2) .sum (). элемент ()
если t% 100 == 99:
print (t, убыток)
# Backprop для вычисления градиентов a, b, c, d с учетом потерь
grad_y_pred = 2,0 * (y_pred - y)
grad_a = grad_y_pred.sum ()
grad_b = (grad_y_pred * x) .sum ()
grad_c = (grad_y_pred * x ** 2) .sum ()
grad_d = (grad_y_pred * x ** 3) .sum ()
# Обновить веса с помощью градиентного спуска
a - = скорость_обучения * град_а
b - = скорость_обучения * grad_b
c - = скорость_обучения * град_с
d - = скорость_обучения * град_д
print (f'Result: y = {a.3 ')
PyTorch: Тензоры и автоград
В приведенных выше примерах нам пришлось вручную реализовать как форвард, так и обратные проходы нашей нейронной сети. Ручная реализация обратный проход не имеет большого значения для небольшой двухуровневой сети, но может быстро становится очень проблематичным для больших сложных сетей.
К счастью, мы можем использовать автоматический дифференциация для автоматизации вычисления обратных проходов в нейронных сетях. В autograd Пакет в PyTorch обеспечивает именно эту функциональность.При использовании автограда прямой проход вашей сети будет определять вычислительный граф ; узлы в графе будут тензорами, а ребра будут функциями, которые производят выходные тензоры из входных тензоров. Обратное распространение через этот график затем позволяет легко вычислить градиенты.
Звучит сложно, но на практике довольно просто. Каждый тензор
представляет узел в вычислительном графе. Если x - это тензор, имеющий x.requires_grad = Истина , затем x.grad - еще один тензор,
градиент x относительно некоторого скалярного значения.
Здесь мы используем PyTorch Tensors и autograd для реализации нашей подходящей синусоидальной волны. с примером полинома третьего порядка; теперь нам больше не нужно вручную реализовать обратный проход по сети:
# - * - кодировка: utf-8 - * - импортный фонарик импортная математика dtype = torch.float устройство = torch.device ("процессор") # device = torch.device ("cuda: 0") # Раскомментируйте это, чтобы запустить на GPU # Создать тензоры для хранения ввода и вывода.3 # Настройка requires_grad = True указывает, что мы хотим вычислять градиенты с # уважение к этим тензорам во время обратного прохода. a = torch.randn ((), устройство = устройство, dtype = dtype, requires_grad = True) b = torch.randn ((), устройство = устройство, dtype = dtype, requires_grad = True) c = torch.randn ((), устройство = устройство, dtype = dtype, requires_grad = True) d = torch.randn ((), устройство = устройство, dtype = dtype, requires_grad = True) learning_rate = 1e-6 для t в диапазоне (2000): # Прямой проход: вычисление прогнозируемого y с использованием операций над тензорами.y_pred = a + b * x + c * x ** 2 + d * x ** 3 # Вычислить и распечатать потерю с помощью операций с тензорами. # Теперь потеря - это тензор формы (1,) # loss.item () получает скалярное значение убытка. потеря = (y_pred - y) .pow (2) .sum () если t% 100 == 99: print (t, loss.item ()) # Используйте autograd для вычисления обратного прохода. Этот вызов вычислит # градиент потерь по всем тензорам с requires_grad = True. # После этого вызовите a.grad, b.grad. c.grad и d.град будет холдинг тензор # градиент потерь относительно a, b, c, d соответственно. loss.backward () # Обновление веса вручную с помощью градиентного спуска. Завернуть в torch.no_grad () # потому что у весов requires_grad = True, но нам не нужно это отслеживать # в автограде. с torch.no_grad (): a - = скорость_обучения * a.grad b - = скорость_обучения * b.grad c - = скорость_обучения * c.grad d - = скорость_обучения * d.grad # Обнуляем градиенты вручную после обновления весов а.3 ')
PyTorch: определение новых функций автограда
Под капотом у каждого примитивного оператора автограда действительно две функции
которые работают с тензорами.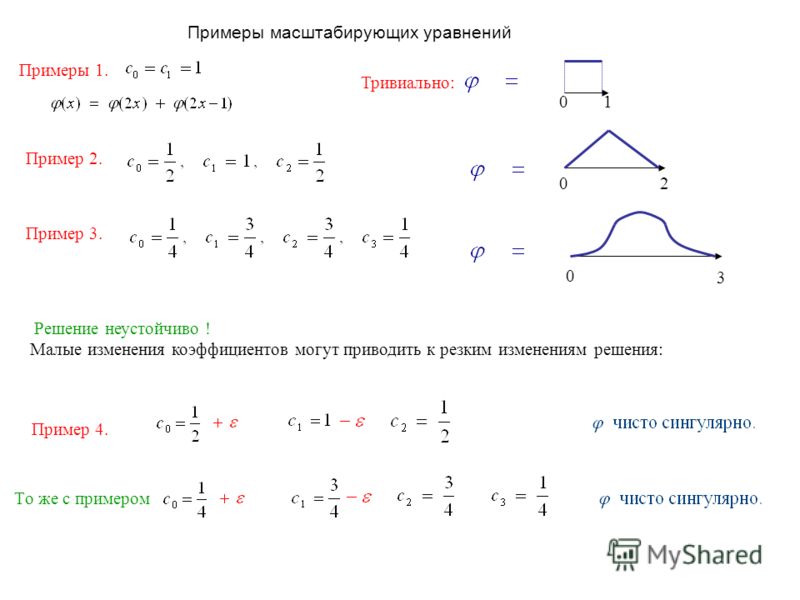 Функция вперед вычисляет вывод
Тензоры из входных Tensors. Функция назад получает
градиент выходных тензоров относительно некоторого скалярного значения, и
вычисляет градиент входных тензоров относительно того же
скалярное значение.
Функция вперед вычисляет вывод
Тензоры из входных Tensors. Функция назад получает
градиент выходных тензоров относительно некоторого скалярного значения, и
вычисляет градиент входных тензоров относительно того же
скалярное значение.
В PyTorch мы можем легко определить наш собственный оператор автограда, определив
подкласс горелки .3-3x \ вправо) \)
- полином Лежандра третьей степени. Пишем свой кастомный автоград
функция для вычисления вперед и назад \ (P_3 \), и использовать ее для реализации
наша модель:
# - * - кодировка: utf-8 - * -
импортный фонарик
импортная математика
класс LegendrePolynomial3 (torch.autograd.Function):
"" "
Мы можем реализовать наши собственные пользовательские функции автограда, создав подклассы
torch.autograd.Function и реализация прямого и обратного проходов
которые работают с тензорами.
"" "
@staticmethod
def вперед (ctx, ввод):
"" "
В прямом проходе мы получаем тензор, содержащий ввод и возврат
Тензор, содержащий вывод.ctx - это объект контекста, который можно использовать
хранить информацию для обратных вычислений. Вы можете кешировать произвольные
объекты для использования в обратном проходе с помощью метода ctx.save_for_backward.
"" "
ctx.save_for_backward (ввод)
возврат 0,5 * (5 * ввод ** 3 - 3 * ввод)
@staticmethod
def назад (ctx, grad_output):
"" "
При обратном проходе мы получаем тензор, содержащий градиент потери
относительно выхода, и нам нужно вычислить градиент потерь
относительно входа."" "
input, = ctx.saved_tensors
вернуть grad_output * 1.5 * (5 * input ** 2-1)
dtype = torch.float
устройство = torch.device ("процессор")
# device = torch.device ("cuda: 0") # Раскомментируйте это, чтобы запустить на GPU
# Создать тензоры для хранения ввода и вывода.
# По умолчанию requires_grad = False, что означает, что нам не нужно
# вычислить градиенты относительно этих тензоров во время обратного прохода. x = torch.linspace (-math.pi, math.pi, 2000, устройство = устройство, dtype = dtype)
y = torch.sin (x)
# Создать случайные тензоры для весов.Для этого примера нам понадобится
# 4 веса: y = a + b * P3 (c + d * x), эти веса необходимо инициализировать
# не слишком далеко от правильного результата, чтобы гарантировать сходимость.
# Настройка requires_grad = True указывает, что мы хотим вычислять градиенты с
# уважение к этим тензорам во время обратного прохода.
a = torch.full ((), 0.0, устройство = устройство, dtype = dtype, requires_grad = True)
b = torch.full ((), -1,0, устройство = устройство, dtype = dtype, requires_grad = True)
c = torch.full ((), 0.0, устройство = устройство, dtype = dtype, requires_grad = True)
d = факел.полный ((), 0.3, устройство = устройство, dtype = dtype, requires_grad = True)
learning_rate = 5e-6
для t в диапазоне (2000):
# Чтобы применить нашу функцию, мы используем метод Function.apply. Мы называем это «P3».
P3 = LegendrePolynomial3.apply
# Прямой проход: вычисление предсказанного y с помощью операций; мы вычисляем
# P3 с использованием нашей пользовательской операции автограда.
y_pred = a + b * P3 (c + d * x)
# Потеря вычислений и печати
потеря = (y_pred - y) .pow (2) .sum ()
если t% 100 == 99:
print (t, loss.item ())
# Используйте autograd для вычисления обратного прохода.loss.backward ()
# Обновить веса с помощью градиентного спуска
с torch.no_grad ():
a - = скорость_обучения * a.grad
b - = скорость_обучения * b.grad
c - = скорость_обучения * c.grad
d - = скорость_обучения * d.grad
# Обнуляем градиенты вручную после обновления весов
a.grad = Нет
b.grad = Нет
c.grad = Нет
d.grad = Нет
print (f'Result: y = {a.item ()} + {b.item ()} * P3 ({c.item ()} + {d.item ()} x) ')
x = torch.linspace (-math.pi, math.pi, 2000, устройство = устройство, dtype = dtype)
y = torch.sin (x)
# Создать случайные тензоры для весов.Для этого примера нам понадобится
# 4 веса: y = a + b * P3 (c + d * x), эти веса необходимо инициализировать
# не слишком далеко от правильного результата, чтобы гарантировать сходимость.
# Настройка requires_grad = True указывает, что мы хотим вычислять градиенты с
# уважение к этим тензорам во время обратного прохода.
a = torch.full ((), 0.0, устройство = устройство, dtype = dtype, requires_grad = True)
b = torch.full ((), -1,0, устройство = устройство, dtype = dtype, requires_grad = True)
c = torch.full ((), 0.0, устройство = устройство, dtype = dtype, requires_grad = True)
d = факел.полный ((), 0.3, устройство = устройство, dtype = dtype, requires_grad = True)
learning_rate = 5e-6
для t в диапазоне (2000):
# Чтобы применить нашу функцию, мы используем метод Function.apply. Мы называем это «P3».
P3 = LegendrePolynomial3.apply
# Прямой проход: вычисление предсказанного y с помощью операций; мы вычисляем
# P3 с использованием нашей пользовательской операции автограда.
y_pred = a + b * P3 (c + d * x)
# Потеря вычислений и печати
потеря = (y_pred - y) .pow (2) .sum ()
если t% 100 == 99:
print (t, loss.item ())
# Используйте autograd для вычисления обратного прохода.loss.backward ()
# Обновить веса с помощью градиентного спуска
с torch.no_grad ():
a - = скорость_обучения * a.grad
b - = скорость_обучения * b.grad
c - = скорость_обучения * c.grad
d - = скорость_обучения * d.grad
# Обнуляем градиенты вручную после обновления весов
a.grad = Нет
b.grad = Нет
c.grad = Нет
d.grad = Нет
print (f'Result: y = {a.item ()} + {b.item ()} * P3 ({c.item ()} + {d.item ()} x) ')
PyTorch: nn
Вычислительные графы и автоград - очень мощная парадигма для
определение сложных операторов и автоматическое получение производных; тем не мение
для больших нейронных сетей raw autograd может быть слишком низкоуровневым.
При построении нейронных сетей мы часто думаем об организации вычисление в слоев , некоторые из которых имеют обучаемых параметров которые будут оптимизированы во время обучения.
В TensorFlow такие пакеты, как Керас, TensorFlow-Slim, и TFLearn предоставляют абстракции более высокого уровня над необработанными вычислительными графами, которые полезны для построения нейронных сети.
В PyTorch пакет nn служит той же цели. Модель nn пакет определяет набор из модулей , которые примерно эквивалентны
слои нейронной сети.Модуль получает входные тензоры и вычисляет
выходные тензоры, но также могут содержать внутреннее состояние, такое как тензоры
содержащие обучаемые параметры. Пакет nn также определяет набор
полезных функций потерь, которые обычно используются при обучении нейронной
сети.
В этом примере мы используем пакет nn для реализации нашей полиномиальной модели.
сеть:
# - * - кодировка: utf-8 - * -
импортный фонарик
импортная математика
# Создать тензоры для хранения ввода и вывода.
x = torch.linspace (-мат.3).
p = torch.tensor ([1, 2, 3])
xx = x.unsqueeze (-1) .pow (p)
# В приведенном выше коде x.unsqueeze (-1) имеет форму (2000, 1), а p имеет форму
# (3,), в этом случае будет применяться семантика широковещательной передачи для получения тензора
# формы (2000, 3)
# Используйте пакет nn, чтобы определить нашу модель как последовательность слоев. nn. последовательный
# - это модуль, который содержит другие модули и последовательно применяет их к
# произвести свой вывод. Линейный модуль вычисляет вывод из ввода, используя
# линейная функция и содержит внутренние тензоры для ее веса и смещения.# Слой Flatten сглаживает вывод линейного слоя до одномерного тензора,
# для соответствия форме `y`.
model = torch.nn.Sequential (
torch.nn.Linear (3, 1),
torch.nn.Flatten (0, 1)
)
# Пакет nn также содержит определения популярных функций потерь; в этом
# case мы будем использовать среднеквадратичную ошибку (MSE) в качестве функции потерь. loss_fn = torch.nn.MSELoss (сокращение = 'сумма')
learning_rate = 1e-6
для t в диапазоне (2000):
# Прямой проход: вычислить предсказанный y, передав x модели. Объекты модуля
# переопределить оператор __call__, чтобы вы могли вызывать их как функции.Когда
# при этом вы передаете модулю тензор входных данных, и он производит
# Тензор выходных данных.
y_pred = модель (xx)
# Потеря вычислений и печати. Мы передаем тензоры, содержащие предсказанное и истинное
# значений y, а функция потерь возвращает тензор, содержащий
# потеря.
loss = loss_fn (y_pred, y)
если t% 100 == 99:
print (t, loss.item ())
# Обнулите градиенты перед выполнением обратного прохода.
model.zero_grad ()
# Обратный проход: вычислить градиент потерь относительно всего обучаемого
# параметры модели.Внутри сохраняются параметры каждого модуля.
# в тензорах с require_grad = True, поэтому этот вызов будет вычислять градиенты для
# все обучаемые параметры в модели.
loss.backward ()
# Обновить веса с помощью градиентного спуска. Каждый параметр является тензором, поэтому
# мы можем получить доступ к его градиентам, как и раньше.
с torch.no_grad ():
для параметра в model.parameters ():
param - = скорость_обучения * param.grad
# Вы можете получить доступ к первому уровню `модели` как доступ к первому элементу списка
linear_layer = модель [0]
# Для линейного слоя его параметры сохраняются как `weight` и` bias`.3 ')
loss_fn = torch.nn.MSELoss (сокращение = 'сумма')
learning_rate = 1e-6
для t в диапазоне (2000):
# Прямой проход: вычислить предсказанный y, передав x модели. Объекты модуля
# переопределить оператор __call__, чтобы вы могли вызывать их как функции.Когда
# при этом вы передаете модулю тензор входных данных, и он производит
# Тензор выходных данных.
y_pred = модель (xx)
# Потеря вычислений и печати. Мы передаем тензоры, содержащие предсказанное и истинное
# значений y, а функция потерь возвращает тензор, содержащий
# потеря.
loss = loss_fn (y_pred, y)
если t% 100 == 99:
print (t, loss.item ())
# Обнулите градиенты перед выполнением обратного прохода.
model.zero_grad ()
# Обратный проход: вычислить градиент потерь относительно всего обучаемого
# параметры модели.Внутри сохраняются параметры каждого модуля.
# в тензорах с require_grad = True, поэтому этот вызов будет вычислять градиенты для
# все обучаемые параметры в модели.
loss.backward ()
# Обновить веса с помощью градиентного спуска. Каждый параметр является тензором, поэтому
# мы можем получить доступ к его градиентам, как и раньше.
с torch.no_grad ():
для параметра в model.parameters ():
param - = скорость_обучения * param.grad
# Вы можете получить доступ к первому уровню `модели` как доступ к первому элементу списка
linear_layer = модель [0]
# Для линейного слоя его параметры сохраняются как `weight` и` bias`.3 ')
PyTorch: optim
До этого момента мы обновляли вес наших моделей вручную.
изменение тензоров, содержащих обучаемые параметры, с помощью torch.no_grad () .
Это не большая проблема для простых алгоритмов оптимизации, таких как стохастический.
градиентный спуск, но на практике мы часто обучаем нейронные сети, используя больше
сложные оптимизаторы, такие как AdaGrad, RMSProp, Adam и т. д.
Пакет optim в PyTorch абстрагирует идею оптимизации
алгоритм и предоставляет реализации часто используемой оптимизации
алгоритмы.3).
p = torch.tensor ([1, 2, 3])
xx = x.unsqueeze (-1) .pow (p) # Используйте пакет nn, чтобы определить нашу модель и функцию потерь.
model = torch.nn.Sequential (
torch.nn.Linear (3, 1),
torch.nn.Flatten (0, 1)
)
loss_fn = torch.nn.MSELoss (сокращение = 'сумма') # Используйте пакет optim, чтобы определить оптимизатор, который будет обновлять веса
# модель для нас. Здесь мы будем использовать RMSprop; пакет optim содержит много других
# алгоритмы оптимизации. Первый аргумент конструктора RMSprop сообщает
# оптимизатор, тензоры каких он должен обновлять.learning_rate = 1e-3
optimizer = torch.optim.RMSprop (model.parameters (), lr = скорость_обучения)
для t в диапазоне (2000):
# Прямой проход: вычислить предсказанный y, передав x модели.
y_pred = модель (xx) # Потеря вычислений и печати.
loss = loss_fn (y_pred, y)
если t% 100 == 99:
print (t, loss.item ()) # Перед обратным проходом используйте объект оптимизатора для обнуления всех
# градиентов для переменных, которые он будет обновлять (которые можно изучить
# веса модели). Это потому, что по умолчанию градиенты
# накапливается в буферах (т.е.e, не перезаписывается) всякий раз, когда .backward ()
# называется. Обратитесь к документации torch.autograd.backward для получения более подробной информации.
optimizer.zero_grad () # Обратный проход: вычислить градиент потерь относительно модели
# параметры
loss.backward () # Вызов пошаговой функции в оптимизаторе обновляет его
# параметры
optimizer.step () linear_layer = модель [0]
print (f'Result: y = {linear_layer.bias.item ()} + {linear_layer.weight [:, 0] .item ()} x + {linear_layer.weight [:, 1].3 ')
PyTorch: пользовательские модули nn
Иногда может потребоваться указать модели более сложные, чем
последовательность существующих модулей; для этих случаев вы можете определить свой собственный
Модули путем создания подкласса nn.Module и определения forward , который
получает входные тензоры и производит выходные тензоры, используя другие
модули или другие операции автограда над тензорами.
В этом примере мы реализуем наш полином третьего порядка как настраиваемый модуль. подкласс:
# - * - кодировка: utf-8 - * -
импортный фонарик
импортная математика
класс Polynomial3 (torch.nn.Module):
def __init __ (сам):
"" "
В конструкторе мы создаем четыре параметра и назначаем их как
параметры члена.
"" "
супер () .__ init __ ()
self.a = torch.nn.Parameter (torch.randn (()))
self.b = torch.nn.Parameter (torch.randn (()))
self.c = torch.nn.Parameter (torch.randn (()))
self.d = torch.nn.Parameter (torch.randn (()))
def вперед (self, x):
"" "
В функции forward мы принимаем тензор входных данных и должны возвращать
Тензор выходных данных.3 '
# Создать тензоры для хранения ввода и вывода.
x = torch.linspace (-math.pi, math.pi, 2000)
y = torch.sin (x)
# Создайте нашу модель, создав экземпляр класса, определенного выше
model = Polynomial3 ()
# Создайте нашу функцию потерь и оптимизатор. Вызов model.parameters ()
# в конструкторе SGD будет содержать обучаемые параметры (определенные
# с torch.nn.Parameter), которые являются членами модели.
критерий = torch.nn.MSELoss (сокращение = 'сумма')
optimizer = torch.optim.SGD (model.parameters (), lr = 1e-6)
для t в диапазоне (2000):
# Прямой проход: вычислить предсказанный y, передав x модели
y_pred = модель (x)
# Потеря вычислений и печати
потеря = критерий (y_pred, y)
если t% 100 == 99:
print (t, потеря.пункт())
# Обнулить градиенты, выполнить обратный проход и обновить веса.
optimizer.zero_grad ()
loss.backward ()
optimizer.step ()
print (f'Result: {model.string ()} ')
PyTorch: поток управления + распределение веса
В качестве примера динамических графиков и распределения веса мы реализуем очень странная модель: полином третьего-пятого порядка, который при каждом прямом проходе выбирает случайное число от 3 до 5 и использует это количество заказов, повторно используя одни и те же веса несколько раз для вычисления четвертого и пятого порядка.
Для этой модели мы можем использовать обычное управление потоком Python для реализации цикла, и мы можем реализовать распределение веса, просто повторно используя один и тот же параметр, несколько раз при определении прямого паса.
Мы можем легко реализовать эту модель как подкласс модуля:
# - * - кодировка: utf-8 - * -
случайный импорт
импортный фонарик
импортная математика
класс DynamicNet (torch.nn.Module):
def __init __ (сам):
"" "
В конструкторе мы создаем пять параметров и назначаем их как члены."" "
супер () .__ init __ ()
self.a = torch.nn.Parameter (torch.randn (()))
self.b = torch.nn.Parameter (torch.randn (()))
self.c = torch.nn.Parameter (torch.randn (()))
self.d = torch.nn.Parameter (torch.randn (()))
self.e = torch.nn.Parameter (torch.randn (()))
def вперед (self, x):
"" "
Для прямого прохода модели мы случайным образом выбираем 4, 5
и повторно используйте параметр e, чтобы вычислить вклад этих заказов.
Поскольку каждый прямой проход создает динамический граф вычислений, мы можем использовать обычные
Операторы потока управления Python, такие как циклы или условные операторы, когда
определение прямого прохода модели.Здесь мы также видим, что совершенно безопасно повторно использовать один и тот же параметр во многих
раз при определении вычислительного графа.
"" "
y = self.a + self.b * x + self.c * x ** 2 + self.d * x ** 3
для exp в диапазоне (4, random.randint (4, 6)):
y = y + self.e * x ** ехр
вернуть y
def строка (self):
"" "
Как и любой класс в Python, вы также можете определить собственный метод в модулях PyTorch.
"" "
return f'y = {self.a.item ()} + {self.5? '
# Создать тензоры для хранения ввода и вывода.
x = torch.linspace (-math.pi, math.pi, 2000)
y = torch.sin (x)
# Создайте нашу модель, создав экземпляр класса, определенного выше
модель = DynamicNet ()
# Создайте нашу функцию потерь и оптимизатор. Обучение этой странной модели с
# ванильный стохастический градиентный спуск сложен, поэтому мы используем импульс
критерий = torch.nn.MSELoss (сокращение = 'сумма')
optimizer = torch.optim.SGD (model.parameters (), lr = 1e-8, импульс = 0,9)
для t в диапазоне (30000):
# Прямой проход: вычислить предсказанный y, передав x модели
y_pred = модель (x)
# Потеря вычислений и печати
потеря = критерий (y_pred, y)
если t% 2000 == 1999:
print (t, потеря.пункт())
# Обнулить градиенты, выполнить обратный проход и обновить веса.
optimizer.zero_grad ()
loss.backward ()
optimizer.step ()
print (f'Result: {model.string ()} ')
Вы можете просмотреть приведенные выше примеры здесь.
Примечания и стиль библиографии
Перейти к дате автора: образцы цитат
Следующие примеры иллюстрируют систему примечаний и библиографии. Образцы примечаний показывают полные цитаты, за которыми следуют сокращенные цитаты тех же источников.Образцы библиографических записей следуют за примечаниями. Для получения дополнительных сведений и многих других примеров см. Главу 14 книги Чикагское руководство по стилю . Чтобы увидеть примеры тех же цитат с использованием системы "автор-дата", перейдите по ссылке "Автор-дата" выше.
Книга
Банкноты
Сокращенные банкноты
Библиографические записи (в алфавитном порядке)
Для многих других примеров, охватывающих практически все типы книг, см. 14.100–163 в The Chicago Manual of Style .
Глава или другая часть отредактированной книги
В примечании укажите конкретные страницы. В библиографии укажите диапазон страниц для главы или части.
Примечание
Сокращенная записка
Библиографическая запись
В некоторых случаях вы можете вместо этого процитировать сборник целиком.
Примечание
Сокращенная записка
Библиографическая запись
Для получения дополнительных примеров см. 14.103–5 и 14.106–12 в The Chicago Manual of Style .
Переведенная книга
Примечание
Сокращенная записка
Библиографическая запись
Электронная книга
Для книг, которые можно найти в Интернете, укажите URL-адрес или имя базы данных. Для других типов электронных книг назовите формат. Если фиксированных номеров страниц нет, укажите название раздела, главу или другой номер в примечаниях, если таковые имеются (или просто опустите).
Банкноты
Сокращенные банкноты
Библиографические записи (в алфавитном порядке)
Дополнительные примеры см. В 14.159–63 в Чикагское руководство по стилю .
Журнальная статья
В примечании укажите конкретные номера страниц. В библиографию укажите диапазон страниц для всей статьи. Для статей, к которым можно обратиться в Интернете, укажите URL-адрес или имя базы данных. Многие журнальные статьи содержат DOI (цифровой идентификатор объекта). DOI формирует постоянный URL-адрес, который начинается с https://doi.org/. Этот URL-адрес предпочтительнее, чем URL-адрес, который отображается в адресной строке вашего браузера.
Банкноты
Сокращенные банкноты
Библиографические записи (в алфавитном порядке)
В статьях журнала часто упоминается много авторов, особенно в области естественных наук.Если авторов четыре или более, укажите в библиографии до десяти; в примечании перечислите только первый, за ним следует и др. . ("и другие"). Для более чем десяти авторов (здесь не показаны) укажите первые семь в библиографии, за которыми следует и др. .
Примечание
Сокращенная записка
Библиографическая запись
Дополнительные примеры см. В 14.168–87 в The Chicago Manual of Style .
Новостная или журнальная статья
Статьи из газет или новостных сайтов, журналов, блогов и т.п. цитируются аналогично.Номера страниц, если таковые имеются, могут быть указаны в примечании, но не включены в библиографический список. Если вы просматривали статью в Интернете, укажите URL-адрес или имя базы данных.
Банкноты
Сокращенные банкноты
Библиографические записи (в алфавитном порядке)
Комментарии читателей цитируются в тексте или в примечании, но опускаются в библиографии.
Примечание
Дополнительные примеры см. В 14.188–90 (журналы), 14.191–200 (газеты) и 14.208 (блоги) в Чикагское руководство по стилю .
Рецензия на книгу
Примечание
Сокращенная записка
Библиографическая запись
Интервью
Примечание
Сокращенная записка
Библиографическая запись
Диссертация или диссертация
Примечание
Сокращенная записка
Библиографическая запись
Содержание веб-сайта
Часто бывает достаточно просто описать веб-страницы и другое содержимое веб-сайта в тексте («По состоянию на 1 мая 2017 г. указана домашняя страница Йельского университета.. . »). Если требуется более формальная цитата, ее можно оформить, как в приведенных ниже примерах. Для источника, в котором не указана дата публикации или редакции, укажите дату доступа (как в примечании 2 к примеру).
Банкноты
Сокращенные банкноты
Библиографические записи (в алфавитном порядке)
Дополнительные примеры см. В 14.205–10 в Чикагское руководство по стилю . Для мультимедиа, включая живые выступления, см. 14.261–68.
Контент в социальных сетях
Цитирование контента, распространяемого через социальные сети, обычно может быть ограничено текстом (как в первом примере ниже).Примечание может быть добавлено, если требуется более формальная ссылка. В редких случаях также может быть уместна библиографическая запись.
