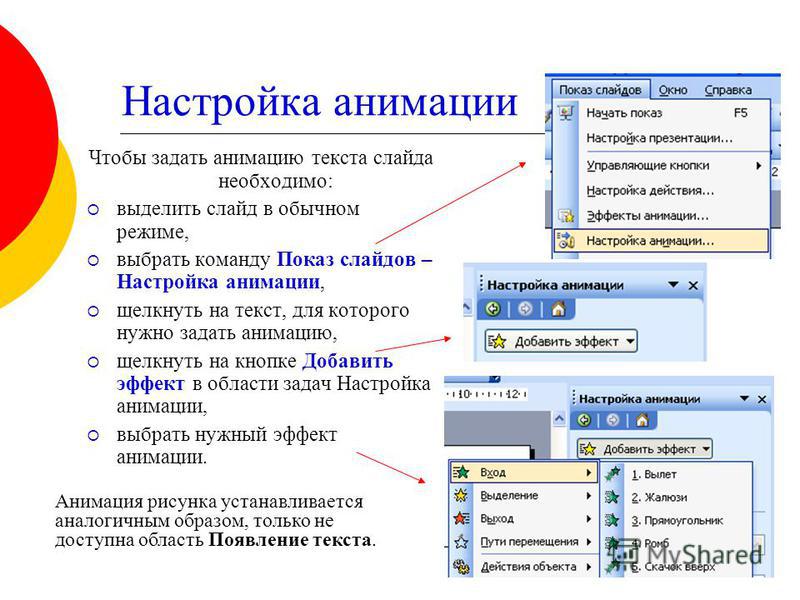
Содержимое резервных копий iCloud — Служба поддержки Apple
- Данные приложений
- Резервные копии данных Apple Watch1
- Настройки устройств
- Вид экрана «Домой» и расположение значков приложений
- Сообщения iMessage, текстовые сообщения (SMS-сообщения) и MMS-сообщения2
- Фото и видео с iPhone, iPad и iPod touch2
- Историю покупок в службах Apple, например информацию о покупке музыки, фильмов, телешоу, приложений и книг3
- Рингтоны
- Пароль визуального автоответчика (требуется SIM-карта, которая использовалась в момент резервного копирования)
Резервные копии iPhone, iPad и iPod touch содержат только данные и настройки, которые хранятся на вашем устройстве. Они не содержат данные, которые уже хранятся в iCloud, такие как контакты, календари, закладки, заметки, напоминания, голосовые записи4, сообщения в iCloud, фото iCloud и общие фото. Некоторые данные не входят в состав резервной копии iCloud, но их можно добавить в iCloud и использовать на нескольких устройствах. Это данные приложения «Почта», медицинские данные, история вызовов и файлы, которые вы храните на iCloud Drive.
1. Если часы Apple Watch используются с функцией Семейная настройка, ваши часы Apple Watch не включаются в резервную копию iPhone, iPad или iPod touch.
2. Если используется приложение Сообщения в iCloud или включена функция Фото iCloud, содержимое автоматически сохраняется в iCloud. Это означает, что такое содержимое не включаются в резервную копию iCloud.
3. Резервная копия iCloud включает информацию о приобретенном содержимом, но не само содержимое. При восстановлении данных из резервной копии iCloud выполняется автоматическая повторная загрузка содержимого, приобретенного в магазинах iTunes Store, App Store или Apple Books. Некоторые виды содержимого не загружаются автоматически в определенных странах или регионах. Ранее приобретенное содержимое может быть недоступно, если его стоимость была возмещена или оно отсутствует в магазине.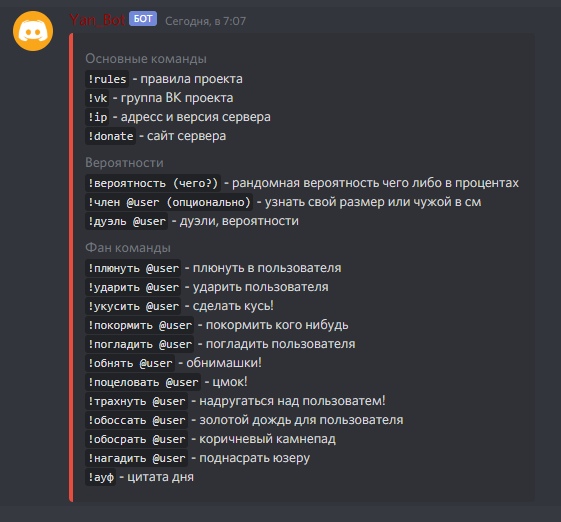
4. Если используется iOS 11 или более ранних версий, голосовые записи включаются в резервную копию iCloud.
Тег | htmlbook.ru
| Internet Explorer | Chrome | Opera | Safari | Firefox | Android | iOS |
| 3.0+ | 1.0+ | 4.0+ | 1.0+ | 1.0+ | 1.0+ | 1.0+ |
Спецификация
| HTML: | 3.2 | 4.01 | 5.0 | XHTML: | 1.0 | 1.1 |
Описание
Определяет структуру фреймов на веб-странице. Фреймы разделяют окно браузера на отдельные области, расположенные вплотную друг к другу. В каждую из таких областей загружается самостоятельная веб-страница определяемая с помощью тега <frame>. С помощью фреймов веб-страница делится на два или более документа, которые обычно содержат навигацию по сайту и его контент. Механизм фреймов позволяет открывать документ в одном фрейме, по ссылке, нажатой в совершенно другом фрейме. Тег <frameset> заменяет собой элемент <body> на веб-странице. Допустимо использовать вложенную структуру элементов, это позволяет разбить один фрейм на две и более области.
При использовании фреймов примите во внимание их следующие особенности.
- Поисковые системы плохо работают с фреймовой структурой, поскольку на страницах, которые содержат контент, обычно нет ссылок на другие документы.
- Фреймы скрывают адрес страницы на которой находится посетитель и устанавливаемый через тег <title>, и всегда показывают только адрес сайта. По этой причине понравившуюся страницу невозможно поместить в раздел «Избранное» браузера.
- Пользователь зачастую оказывается на сайте, совершенно не представляя, куда
он попал, потому что всего лишь нажал на ссылку, полученную в поисковой системе.
 Чтобы посетителю сайта было проще разобраться, где он находится, на каждую
страницу помещают название сайта, заголовок страницы и навигацию. Фреймы,
как правило, нарушают данный принцип, отделяя заголовок сайта от содержания,
а навигацию от контента. Представьте, что вы нашли подходящую ссылку в поисковой
системе, нажимаете на нее, а в итоге открывается документ без названия и навигации.
Чтобы понять, где мы находимся или посмотреть другие материалы, придется редактировать
путь в адресной строке, что в любом случае доставляет неудобство.
Чтобы посетителю сайта было проще разобраться, где он находится, на каждую
страницу помещают название сайта, заголовок страницы и навигацию. Фреймы,
как правило, нарушают данный принцип, отделяя заголовок сайта от содержания,
а навигацию от контента. Представьте, что вы нашли подходящую ссылку в поисковой
системе, нажимаете на нее, а в итоге открывается документ без названия и навигации.
Чтобы понять, где мы находимся или посмотреть другие материалы, придется редактировать
путь в адресной строке, что в любом случае доставляет неудобство. - Большое число фреймов требует для браузера выделения больше памяти, чем обычно.
Синтаксис
<frameset>
<frame>
</frameset>Атрибуты
- border
- Толщина границы между фреймами.
- bordercolor
- Цвет линии границы.
- cols
- Устанавливает ширину или пропорции фреймов в виде колонок.
- frameborder
- Определяет, отображать рамку вокруг фрейма или нет.
- framespacing
- Аналог атрибута border, задает ширину границы.
- rows
- Задает размер или пропорции фреймов в виде строк.
Закрывающий тег
Обязателен.
Пример
HTML 4.01IECrOpSaFx
<!DOCTYPE HTML PUBLIC "-//W3C//DTD HTML 4.01 Frameset//EN"
"http://www.w3.org/TR/html4/frameset.dtd">
<html>
<head>
<meta http-equiv="Content-Type" content="text/html; charset=utf-8">
<title>Тег FRAMESET</title>
</head>
<frameset rows="80,*" cols="*">
<frame src="top.html" name="topFrame" scrolling="no" noresize>
<frameset cols="80,*">
<frame src="left.html" name="leftFrame" scrolling="no" noresize>
<frame src="main.html" name="mainFrame">
</frameset>
</frameset>
</html>Некоторые примеры организации фреймов приведены ниже.
|
| |||||||||
| |
 html" name="Фрейм 1">
<frame src="r1c2.html" name="Фрейм 2">
<frame src="r2c1.html" name="Фрейм 3">
<frame src="r2c2.html" name="Фрейм 4">
<frame src="r3c1.html" name="Фрейм 5">
<frame src="r3c2.html" name="Фрейм 6">
</frameset>
html" name="Фрейм 1">
<frame src="r1c2.html" name="Фрейм 2">
<frame src="r2c1.html" name="Фрейм 3">
<frame src="r2c2.html" name="Фрейм 4">
<frame src="r3c1.html" name="Фрейм 5">
<frame src="r3c2.html" name="Фрейм 6">
</frameset>Работа в Средней Ахтубе, поиск персонала и публикация вакансий
Работа в Средней Ахтубе — это самый широкий спектр направлений в различных отраслях деятельности: от сотрудников сферы обслуживания до руководителей крупнейших компаний. Используя нашу обширную информационную базу, вы легко найдете подходящую работу в Средней Ахтубе, ведь hh.ru сотрудничает со множеством компаний-работодателей.
Искать работу с помощью сервисов hh.ru очень просто и удобно. Вам достаточно один раз заполнить форму резюме и разместить его. Потом остается только откликаться на вакансии интересных компаний и получать приглашения от работодателей. Обновления происходят регулярно, превращая поиск работы в увлекательное времяпровождение. Большая часть услуг для соискателей абсолютно бесплатна.
Показать полностью
По актуальным предложениям кадровых отделов предприятий в Средней Ахтубе соискатель может договориться о собеседовании уже в первый день поиска. Но, даже если интересующий вас рабочий профиль довольно редкий, не отчаивайтесь: вакансии по нему рано или поздно появятся. Не хотите ждать? Воспользуйтесь опцией «Хочу у вас работать». Нажмите на эту кнопку — и ваше резюме стопроцентно попадет в кабинет работодателя в специальную папку «Хотят у вас работать» и будет выделяться в результатах поиска.
Большой плюс заключается в том, что на hh.ru есть возможность осуществлять поиск не только по должности, но также и по компаниям. Если вы хотите присоединиться к штату сотрудников какой-либо конкретной фирмы — данный сервис будет особенно полезен.
Если вы хотите присоединиться к штату сотрудников какой-либо конкретной фирмы — данный сервис будет особенно полезен.
На что стоит обратить внимание при поиске новой работы? Работодатели предпочитают не просто соискателей с высокими профессиональными качествами, но и сотрудников, обладающих сильной адаптивностью. Такие работники легче переносят перемены в жизни, более адекватно ориентируются в любой ситуации, эмоционально устойчивы и способны меняться вместе с обстоятельствами.
Таким образом, рекрутеры советуют для успешного трудоустройства развивать следующие качества: успешную адаптацию к изменяющимся ситуациям; способность сохранять спокойствие перед лицом трудностей; умение быстро реагировать на внезапные изменения в обстоятельствах; принятие на себя новых задач в кратчайшие сроки.
Информатика: уроки, тесты, задания.
Информация вокруг нас
-
Как мы получаем информацию? Виды информации
-
Основные информационные процессы. Хранение, передача и обработка информации
Компьютер — универсальная машина для работы с информацией
-
Как устроен компьютер?
-
Техника безопасности, организация рабочего пространства
Ввод информации в память компьютера
-
Устройства ввода информации
-
Клавиатура и её использование
Управление компьютером
-
Программы и документы.
Главное меню. Запуск программ
Хранение информации
-
Оперативная и долговременная память
Передача информации
-
Схема передачи информации. Электронная почта
Кодирование информации
-
В мире кодов
-
Метод координат
Текстовая информация
-
Текстовые документы
Представление информации в форме таблиц
-
Структура таблицы
-
Табличный способ решения логических задач
Компьютерная графика
-
Графический редактор MS Paint
-
Устройства ввода графической информации
Информационный повод (инфоповод) | Unisender
Информационный повод (инфоповод) — это событие, служащее эффективным инструментом при создании определенного имиджа, формировании или коррекции взгляда сообщества на предмет инфоповода. Такая новость способна заинтересовать публику и средства массовой информации.
Такая новость способна заинтересовать публику и средства массовой информации.
Особенности и примеры информационного повода
Информационный повод может включать:
- новые или дополнительные сведения;
- общественное отношение;
- мнения экспертов и пр.
Инфоповод не только формирует имидж и продвигает предмет, но и укрепляет или корректирует уже имеющееся мнение целевой аудитории.
Основная цель информационного повода — материальная или нематериальная выгода. К примеру, анонсирование новостей должно привлечь СМИ и целевую аудиторию, что способствует популяризации и соответственно продвижению предмета инфоповода.
Предмет или объект информационного повода — это субъект, интересующий общество. Это может быть товар, услуга, бренд или компания.
Важно различать понятия «пресс-релиз» и «информационный повод». В первом случае подразумевается непосредственно официальный текст, содержащий новости о предмете или компании. Инфоповод — это главная тема данного сообщения, заставляющая обсуждать этот пресс-релиз. В идеале информационный повод представлен лаконично, включает важные факты, отражает суть и описывает выгоду для целевой аудитории, что является основной задачей паблик-рилейшнз.
Инфоповод выступает важной составляющей ивент-маркетинга. С его помощью осуществляется пиар продукции, услуг и брендов.
Информационный повод может подразумевать как большие, так и малые события. В результате формируются разные сообщества заинтересованных лиц. Хороший инфоповод привлекает больше СМИ и собирает численную целевую аудиторию.
Создание инфоповода
Информационные поводы могут освещаться СМИ самостоятельно и за счет собственника обсуждаемого объекта.
Способствует ли инфоповод маркетинговой выгоде, зависит от того, соответствует ли он следующим основным характеристикам:
- масштабность;
- значимость;
- однозначная интерпретация;
- позитивность;
- актуальность.
Обычно, чем масштабнее и значимее событие, тем больше оно интересует СМИ и привлекает огромную целевую аудиторию.
Также на количество заинтересованных лиц влияет интерпретация информационного повода. Суть должна быть понятной и однозначной: никто не захочет искать скрытый смысл сообщения. Текст, содержащий множество усложняющих восприятие элементов, негативно сказывается на способности целевой аудитории анализировать информацию.
Такое явления даже получило название — информационный шум. Этот феномен подразумевает переизбыток информации, в потоке которой человек не может определить главную мысль.
Хотя негативные новости привлекают большее внимание, позитивные инфоповоды более выгодные: они создают позитивный имидж и призывают к действию.
Информационный повод должен быть актуальным, чтобы он не выпал из текущей повестки дня и был интересен непосредственно сегодня. Новость может вызвать негативные реакции, если появится спустя какое-то время после произошедшего события.
Успешный инфоповод предусматривает гармоничное сочетание всех характеристик. Если какая-то составляющая отсутствует, требуется больше сосредоточиться на других пунктах.
Перед тем, как приступить к обработке инфоповода, нужно собрать как можно больше информации о продвигаемом объекте. Для изучения потребностей клиентов могут проводиться соцопросы. Беря во внимание аналитический отчет, можно сделать предложение более интересным для целевой аудитории.
При оптимизации информационного повода соблюдайте несложные правила:
- избегайте навязчивости;
- придерживайтесь уважительного стиля общения с целевой аудиторией;
- при необходимости упоминания катастроф, катаклизмов или эпидемий будьте очень осторожны;
- учитесь на ошибках конкурентов.
Создав грамотный и хорошо читаемый текст инфоповода, используйте всевозможные способы распространение: газеты, журналы, объявления, листовки, телевидение, радио, SMS- и email-рассылку. Рекламу можно распространять даже на упаковках товаров.
Рекламу можно распространять даже на упаковках товаров.
Прекрасный инструмент продвижения обсуждаемого предмета — розыгрыши, после проведения которых нужно обязательно предоставить информацию о результатах.
Примеры информационных поводов
Маркетологи разработали множество типов инфоповодов с учетом вида продвигаемого предмета, цели и масштаба мероприятия.
Основные примеры:
- презентация новых товаров и услуг;
- акции, распродажи, аукционы;
- общие новости: заседание руководства, новые программы, съезд партии;
- кадровые изменения: смена руководства, интервью официальных представителей;
- история: бренда, компании, товара;
- планируемые события: выборы президента, праздники, день открытых дверей, выставка, юбилей компании, фестиваль, ярмарка;
- местоположение: переезд, адрес главного офиса, складов или магазинов;
- награды, рекорды, победа в конкурсе;
- спортивные состязания (привлекают клиентов спортклубов и секций).
Наиболее эффективным информационным поводом в сфере продаж является презентация новых товаров и услуг. Основная задача — сообщить что-то новое: преимущества, качества, дизайн, технологии и т.д. Результатом успешного информационного повода в данном случае будет привлечение большего количества клиентов.
Существуют малые или локальные инфоповоды, нацеленные на конкретную категорию людей. Например, новость о завершении строительства завода в Киеве и приглашение на работу специалистов.
Длительность инфоповода
На продолжительность информационного повода влияют следующие факторы:
- заинтересованность сообщества;
- популярность обсуждаемого предмета;
- актуальность и польза новости.
Обычно новость в газете или объявлении привлекает недолговечный ажиотаж, поэтому маркетологи стараются максимально продлить интерес целевой аудитории или постоянно его обновляют. Одним действенным инструментом считается формирование сопричастности продвигаемого объекта и более значимого и масштабного инфоповода.
Компания «АСКОН» представляет САПР для домашнего использования КОМПАС-3D v19 Home
Российский разработчик систем автоматизированного проектирования «АСКОН» выпустил обновленный КОМПАС-3D Home для любительского 3D-моделирования и изучения. Мейкерам, 3D-печатникам, домашним мастерам и блогерам доступны все возможности профессиональной САПР.
В условия лицензионного соглашения о некоммерческом использовании системы внесены важные изменения.: теперь КОМПАС-3D Home можно применять в коммерческих целях в условиях чрезвычайной ситуации, например эпидемии, если это поможет ее предотвращению. Второе новшество — разрешается коммерческое использование для создания публичного аудио/видеоконтента в блогах и соцсетях.
По производительности новая версия превзошла предыдущие показатели и стала самой быстрой в истории. Всего КОМПАС-3D v19 Home содержит более семидесяти новинок в области интерфейса, трехмерного моделирования, построения чертежей, инженерных расчетов.
КОМПАС-3D Home — это возможности профессиональной САПР, доступные домашним пользователям. Моделируйте самолеты и грузовики, автобусы и танки, мотоциклы и вертолеты, собирайте планеры и коптеры, создавайте модели автомобилей вашей мечты.
КОМПАС-3D Home содержит все базовые средства трехмерного моделирования и двумерного черчения, а также разнообразные приложения, например «Валы и механические передачи», «Механика: Пружины», «Распознавание 3D-моделей», «Стандартные изделия», а также новое приложение «Оптимизация IOSO-K» для оптимизации геометрии деталей и сборок от компании «Сигма Технология».
Все ограничения КОМПАС-3D Home относятся исключительно к области лицензирования. Система предназначена для некоммерческого использования, что закреплено в лицензионном соглашении. Кроме того, формат файлов домашней версии не совместим с форматом профессиональной, а на полях чертежей автоматически выводятся надписи о создании документа в некоммерческой версии.
Скачать КОМПАС-3D v19 Home можно по этой ссылке.
О КОМПАС-3D
КОМПАС-3D — российская система автоматизированного проектирования, базирующаяся на собственном математическом ядре и параметрических технологиях, разработанных специалистами «АСКОН». КОМПАС-3D — стандарт для тысяч предприятий, простой в освоении инструмент с широким возможностям твердотельного, поверхностного и прямого моделирования. Подробная информация о компании «АСКОН» доступна на официальном сайте.
Пресс-релиз
А у вас есть интересные новости? Поделитесь с нами своими разработками, и мы расскажем о них всему миру! Ждем ваши идеи по адресу [email protected].
Изучите версии с помощью Jira Software
Учебное руководство по версиям Jira
Из этого учебного руководства вы узнаете, как можно работать с версиями в Jira Software.
Время:
10 минут на прочтение. Прохождение учебного курса занимает не менее 2 недель.
Аудитория:
Вы знакомы с принципами работы с досками Scrum и (или) Kanban в Jira Software
У вас есть права на администрирование всех проектов на вашей доске Scrum или Kanban. Дополнительную информацию см. на странице «Управление правами на уровне проекта».
Обязательное условие:
Получить бесплатно
Что представляет собой версия в Jira Software?Версии в Jira Software отражают состояние проекта на определенный момент времени. Они помогают организовать работу посредством создания контрольных точек, которых необходимо достичь. Вы можете связать задачи проекта с конкретной версией и организовать спринты для выполнения работы в рамках этой версии.
Шаг 1. Создание версии в Jira Software
- Перейдите в проект.
В меню проекта нажмите Releases (Релизы).
Выберите текстовое поле Version name (Имя версии), введите имя и нажмите Add (Добавить).
Имена версий обычно состоят из цифр, например 1.0 или 2.1.1. Можно также использовать внутреннее кодовое имя.

Вы можете создать ровно столько версий, сколько необходимо. Создание нескольких версий поможет спланировать работу заранее, однако для начала можно ограничиться лишь одной или двумя.
После создания версии для ваших задач станут доступны поля Affects version (Затрагиваемая версия) и Fix version (Версия фикса).
Шаг 2. Добавление задач к версии
Если у проекта есть бэклог
Перейдите в бэклог проекта.
Откройте панель Versions (Версии) слева.
Перетащите задачу в нужную версию для добавления.
Если у проекта нет бэклога
Откройте задачу, которую нужно добавить в версию.
Найдите поле Fix version/s (Версия исправления) и введите имя версии, в которую нужно добавить задачу.
Затрагиваемая версия — это версия, в которой были обнаружены баг или проблема. Информация о таких версиях может быть полезна при отслеживании проблем, однако они используются в Jira довольно редко.
Версия фикса — это версия для клиентов, в рамках которой планируется выпуск новой возможности или устранение багов. Это поле используется для планирования релизов, отслеживания работы и скорости ее выполнения, а также для составления отчетов. Скорее всего, вы будете пользоваться им чаще остальных в процессе работы.
Шаг 3. Отслеживание работы над версией
Jira Software содержит множество инструментов, с помощью которых вы можете следить за работой над версией. Далее мы поговорим о некоторых из них.
Центр управления релизами
В центре управления релизами вы можете управлять всеми релизами, а также просматривать сведения о состоянии релизов и количестве задач в каждой версии.
Переход в центр управления релизами.
- Перейдите в проект.
В меню проекта выберите Releases (Релизы).
Быстрые фильтры. Отобразите конкретные версии, исключив все остальные.
Список версий. Перетаскивайте версии, чтобы изменить их порядок.
Состояние. Версии могут находиться в одном из трех состояний: Unreleased (Не выпущена), Released (Выпущена) или Archived (В архиве).
Прогресс. Здесь показано количество задач, связанных с конкретной версией, а также состояние каждой задачи.
Burndown-диаграмма релиза (только для Scrum)
На диаграмме Burndown релиза показан объем выполненной и оставшейся работы. С помощью таких диаграмм можно спрогнозировать, выполнит ли команда работу в срок. Они также отлично подходят для того, чтобы сообщить команде о расширении области проекта.
Обратите внимание: прежде чем использовать диаграмму Burndown релиза, необходимо оценить сложность задач. Подробнее см. в нашем руководстве по диаграммам Burndown.
Чтобы просмотреть диаграмму Burndown релиза, выполните следующие действия.
- Перейдите в проект.
В меню проекта выберите Reports (Отчеты).
Выберите Release burndown (Диаграмма Burndown релиза).
Меню релизов. Выбор релиза, информацию по которому нужно просмотреть.
Добавленная работа. Сегменты темно-синего цвета отображают объем работы, добавленный в каждый спринт релиза. В этом примере объем работы измеряется в очках за пользовательские истории.
Оставшаяся работа. Сегменты светло-синего цвета отображают оставшийся объем работы в релизе.
Выполненная работа. Сегменты зеленого цвета отображают объем работы, выполненной в рамках каждого спринта в релизе.
Ожидаемое время завершения. В отчете показано, сколько спринтов потребуется для завершения работы над релизом с учетом скорости работы команды.
Подробнее см. в нашей документации по диаграммам Burndown для отслеживания релизов.
Шаг 4. Завершение работы над версией
Ваша команда усердно потрудилась — настало время выпустить релиз ПО. На этом этапе вы должны быть уверены, что версия готова к релизу. Убедитесь, что все задачи выполнены, код загружен и проверен, выполнено его слияние, сборки успешно протестированы и т. д.
Для развертывания релиза чаще всего необходимо выпустить версию в Jira Software, после чего выполнить сборку релиза и его развертывание в нужной среде.
Завершение работы над версией
Перейдите в проект.
В меню проекта выберите Releases (Релизы).
Кнопка «…»Выберите Actions () > Release (Действия > Выпустить) для версии, которую нужно выпустить.
На досках Kanban можно также выпустить все задачи из столбца Done (Выполнено) в качестве новой версии прямо со страницы доски.
Versions and Jira automationYou can use automation to supercharge how you use versions in Jira. See this automation rule and 100s more in the Jira Automation Template Library. Go to library
Хотите узнать больше?
Подробнее о работе с версиями в Jira Software см. в нашей документации по версиям.
Есть вопросы? Задайте вопрос в сообществе Atlassian.
Поделитесь этой статьей
Max Rehkopf
Я считал себя «хаотичным раздолбаем», но методики и принципы agile помогли навести порядок в моей повседневной жизни. Для меня истинная радость — делиться этими знаниями с другими людьми, публикуя многочисленные статьи, участвуя в беседах и распространяя видеоматериалы, которые я создаю для Atlassian.
kradecki / infa: Python API для Informatica PowerCenter (pmrep, pmcmd)
инфа — это недостающее звено между Informatica PowerCenter и Python. Он создает оболочку для инструментов командной строки PowerCenter (pmrep, pmcmd) и обрабатывает обмен данными с этими инструментами и их вывод.
Он создает оболочку для инструментов командной строки PowerCenter (pmrep, pmcmd) и обрабатывает обмен данными с этими инструментами и их вывод.
Зачем нужна инфа?
- Нет собственного Python API, предоставляемого самой компанией Informatica Corp. Встроенные инструменты командной строки PowerCenter для
- ориентированы на пользователя и обеспечивают вывод, который сложно проанализировать программным способом
- infa фокусируется на API: вывод осуществляется в машинно-понятном виде (например: списки)
- легко понять опытным разработчикам и администраторам Informatica
Требования
- Python 2.x (реализовано и протестировано на 2.7.5)
- Инструменты командной строки Informatica (pmrep, pmcmd), установленные на том же компьютере
- Реализовано и протестировано в Linux
Использование
Каждый инструмент командной строки Informatica реализован как класс Python, а специальные команды инструмента разработаны как методы класса. В следующем примере сравнивается использование встроенного инструмента командной строки pmrep и класса Pmrep infa.
Оболочка:
# Подключиться к репозиторию Informatica $ / opt / informatica / 9.6.1 / server / bin / pmrep Connect -r Имя_репозитория -h localhost -o 6005 -n admin -x пароль-секрета # Получить список всех преобразований агрегатора в папке "Demo" $ /opt/informatica/9.6.1/server/bin/pmrep ListObjects -o преобразование -t агрегатор -f Демо # Закрыть соединения и очистить $ /opt/informatica/9.6.1/server/bin/pmrep Очистка
Собственная команда вызывает результат со следующим выводом:
(...)
Informatica (r) PMREP, версия [9.6.1 HotFix3], сборка [990.0611], LINUX 64-бит
Авторские права (c) Informatica Corporation 1994-2015
Все права защищены.
Это программное обеспечение защищено патентами США № 5,794,246; 6014670; 6,016,501; 6,029,178; 6032158; 6 035 307; 6044374; 6 092 086; 6,208,990; 6,339,775; 6,640,226; 6,789,096; 6,823,373; 6,850,947; 6,895,471; 7,117,215; 7,162,643; 7 243 110; 7,254,590; 7 281 001; 7,421,458; 7,496,588; 7,523,121; 7,584,422; 7,676,516; 7,720,842; 7,721,270; 7,774,791; 8 065 266; 8,150,803; 8,166,048; 8,166,071; 8,200,622; 8,224,873; 8,271,477; 8 327 419; 8,386,435; 8,392,460; 8,453,159; 8,458,230; 8,707,336; 8,886,617; и RE44 478, Международные патенты и другие заявленные патенты. Вызвано в четверг, 10 декабря, 19:50:02 2015
SANDBOX_1
SANDBOX_2
SANDBOX_3
SANDBOX_4
SANDBOX_5
.listobjects успешно завершен.
Завершено в чт, 10 дек, 19:50:07 2015
Вызвано в четверг, 10 декабря, 19:50:02 2015
SANDBOX_1
SANDBOX_2
SANDBOX_3
SANDBOX_4
SANDBOX_5
.listobjects успешно завершен.
Завершено в чт, 10 дек, 19:50:07 2015
Python:
импортная инфа
# Создать экземпляр класса Pmrep и открыть соединение с репозиторием
p = infa.Pmrep (
'/opt/informatica/9.6.1/server/bin/pmrep',
r = 'Имя_репозитория',
h = 'локальный',
о = '6005',
n = 'админ',
x = 'secret_password'
)
# Получить список всех преобразований агрегатора в папке "Demo"
а = р.listobjects (o = 'преобразование', t = 'агрегатор', f = 'демонстрация')
печать (а)
# Закрыть соединения и очистить
p.cleanup () Приведенный выше код дает следующие результаты:
[['SANDBOX_1'], ['SANDBOX_2'], ['SANDBOX_3'], ['SANDBOX_4'], ['SANDBOX_5']]
Наиболее существенное различие заключается в том, как оба инструмента обрабатывают вывод. Собственный pmrep создает удобочитаемый, недружелюбный для машины результат с большим количеством дополнительного «шума», который размывает желаемую информацию. Данные часто доставляются непоследовательным образом (например: пробелы или запятые в качестве разделителей полей). инфа использует другой подход. Основное внимание уделяется доставке результатов удобным для API способом. Нерелевантные данные удаляются из вывода, а запрошенная информация предоставляется в удобном для анализа и согласованном формате.
Подробную документацию см. На вики-страницах.
Установка
Сделать.
Дорожная карта / Состояние игры
инфа в стадии разработки. Ниже приведен обзор реализованных в настоящее время функций и причины отказа от реализации других.
PMREP
| Команда pmrep | Метод класса PMREP | Реализовано? | Комментарий |
|---|---|---|---|
| AddToDeploymentGroup | addtodeploymentgroup | ✅ | |
| ApplyLabel | applylabel | ✅ | |
| AssignPermission | присвоить разрешение | ✅ | |
| BackUp | резервное копирование | ✅ | |
| Изменить владельца | сменщик | ✅ | |
| Прибытие | заезд | ✅ | |
| Очистка | очистка | ✅ | |
| ClearDeploymentGroup | cleardeploymentgroup | ✅ | |
| Подключить | __init__ | ✅ | Используется неявно при создании экземпляра класса |
| Создать | создать | ✅ | |
| CreateConnection | создать соединение | ✅ | |
| CreateDeploymentGroup | createdeploymentgroup | ✅ | |
| CreateFolder | создать папку | ✅ | |
| CreateLabel | createlabel | ✅ | |
| Удалить | ✘ | ||
| DeleteConnection | ✘ | ||
| DeleteDeploymentGroup | ✘ | ||
| DeleteFolder | удалить папку | ✅ | |
| DeleteLabel | deletelabel | ✅ | |
| DeleteObject | ✘ | ||
| ExecuteQuery | ✘ | ||
| Выход | ✘ | Интерактивный режим не планируется | |
| FindCheckout | ✘ | ||
| GetConnectionDetails | ✘ | ||
| GenerateAbapProgramToFile | ✘ | ||
| Справка | ✘ | Не поддерживается | |
| Установить AbapProgram | ✘ | ||
| KillUserConnection | ✘ | ||
| Список соединений | список соединений | ✅ | |
| ListObjectDependencies | ✘ | ||
| Список объектов | Листобъекты | ✅ | |
| ListTablesBySess | Таблицы✅ | ||
| ListUserConnections | ✘ | ||
| MassUpdate | ✘ | ||
| ModifyFolder | ✘ | ||
| Уведомить | ✘ | ||
| ObjectExport | ✘ | ||
| Импорт объекта | ✘ | ||
| Версия для продувки | ✘ | ||
| Регистр | ✘ | ||
| RegisterPlugin | ✘ | ||
| Восстановить | ✘ | ||
| Откат Развертывание | ✘ | ||
| Бег | ✘ | ||
| ShowConnectionInfo | ✘ | ||
| Переключатель подключения | ✘ | ||
| TruncateLog | ✘ | ||
| Отменить оформление заказа | ✘ | ||
| Отменить регистрацию | ✘ | ||
| Отменить регистрацию подключаемого модуля | ✘ | ||
| Обновление подключения | ✘ | ||
| Обновить адрес электронной почты | ✘ | ||
| ОбновитьSeqGenVals | ✘ | ||
| UpdateSrcPrefix | ✘ | ||
| Обновить статистику | статистика обновлений | ✅ | |
| UpdateTargPrefix | ✘ | ||
| Обновление | ✘ | ||
| Удалить AbapProgram | ✘ | ||
| Подтвердить | ✘ | ||
| Версия | ✘ |
Pmcmd
Приближается.
Авторы
инфа была создана и разрабатывается Кшиштофом Радецким (krzysztof.radecki / gmail / com). Мы приветствуем вклад других разработчиков, и он будет им зачислен.
Лицензия
Лицензия GPL
Учебное пособие поInformatica — Изучите инструмент Informatica ETL
В этом руководстве по Informatica мы покажем вам пошаговый процесс подключения к различным источникам данных. Затем извлеките данные из источника данных, преобразуйте данные с помощью преобразований.Последний раздел этого руководства по Informatica охватывает создание сеанса и рабочего процесса, а также загрузку данных в место назначения со снимками экрана.
Что такое инструмент Informatica ETL?
Informatica — лидер рынка ETL-инструментов, от которого зависят более 5800 предприятий. Informatica в основном используется для создания мощных бизнес-приложений для извлечения данных из источников, преобразования и загрузки данных в целевые объекты. На этой странице руководства Informatica мы объясняем все об этом инструменте ETL.
Клиент Informatica PowerCenter содержит различные приложения или инструменты, которые помогают разрабатывать сопоставления и маплеты. Используйте этот клиент PowerCenter для создания сеанса и рабочего процесса.
Informatica Введение
Это введение в данное руководство по Informatica, которое охватывает установку Informatica, настройку Power Center, рабочие процессы и т. Д.
ПриложениеInformatica PowerCenter позволяет загружать или извлекать данные из нескольких источников (Source Qualifier), преобразовывать данные в соответствии с бизнес-требованиями (преобразование) и загружать обработанные данные в целевую таблицу (Target Designer).
- Как загрузить Informtica
- Пошаговый подход к установке InformaticaSoftware
- Как настроить службу репозитория и службу интеграции
- PowerCenter Repository Manager
- Введение в PowerCenter Designer
- Анализатор источника PowerCenter
- Знакомство с Workflow Manager
- Введение в Workflow Monitor
Informatica Data Connections Tutorial
Informatica PowerCenter получает доступ к информации или данным из различных источников, таких как плоские файлы, XML, реляционные базы данных, SAP Hana, Teradata, мэйнфреймы, Excel и Access. Точно так же Informatica поддерживает одни и те же места назначения для загрузки данных. В этом разделе учебного пособия Informatica рассматриваются различные типы соединений данных и основные операции ETL.
Точно так же Informatica поддерживает одни и те же места назначения для загрузки данных. В этом разделе учебного пособия Informatica рассматриваются различные типы соединений данных и основные операции ETL.
- Соединение ODBC
- Импорт данных из реляционной базы данных
- Как импортировать данные из плоского файла
- Импорт данных из книги Excel
- Перемещение данных из одной базы данных SQL в другую базу данных
- Экспорт данных из SQL Server в плоский файл
- Загрузка данных из текстового файла в SQL Server
- Загрузка нескольких текстовых файлов в SQL Server
Informatica Tutorial on Transformations
Преобразование — это часть Informatica Mapping, которая преобразует или изменяет данные в соответствии с выбранным преобразованием.В этом разделе учебника Informatica представлен список доступных преобразований с практическими примерами.
- Список преобразований
- Преобразование агрегатора
- Преобразование выражения
- Преобразование фильтра
- Преобразование Java
- Преобразование объединителя
- Обычное соединение
- Мастер внешнего соединения
- Деталь Наружное соединение
- Полное внешнее соединение
- Преобразование поиска
- Преобразование поиска
- Преобразование несвязанного поиска
- Преобразование нормализатора
- Преобразование ранга
- Преобразование ранга с помощью Group By
- Преобразование маршрутизатора
- Преобразование генератора последовательности
- Преобразование сортировщика
- Преобразование сортировщика — удаление дубликатов
- Преобразование квалификатора источника
- Преобразование SQL
- Преобразование хранимой процедуры
- Преобразование управления транзакциями
- Преобразование объединения
- Преобразование стратегии обновления
- Стратегия обновления с использованием свойств сеанса
- Пример стратегии обновления
- Преобразование генератора XML
- Преобразование синтаксического анализатора XML
- Преобразование квалификатора источника XML
- Pre SQL и Post SQL
Информационные сеансы и сопоставления
В этом разделе учебника Informatica объясняется создание сеансов информатики, сопоставления и рабочего процесса. Этот раздел учебника Informatica является наиболее важным из-за возможности его повторного использования во всех преобразованиях.
Этот раздел учебника Informatica является наиболее важным из-за возможности его повторного использования во всех преобразованиях.
- Target Designer
- Создать целевую таблицу с использованием определения источника
- Создать новую целевую таблицу
- Как создать сопоставление
- Создать сеанс
- Как создать многоразовый сеанс
- Создать рабочий процесс
- Создание рабочего процесса с помощью мастера
- Командная задача
- Задача ожидания события
Использование Informatica PowerCenter с соединителем Greenplum
Следуйте этим инструкциям, чтобы использовать клиент Informatica PowerCenter Designer для создания целевого загрузчика базы данных Greenplum и сопоставления для загрузки данных в базу данных Greenplum.
Предварительные требования
Процесс
Шаг 1. Создание сопоставления между исходной и целевой таблицами
Выполните следующие действия, чтобы использовать PowerCenter Designer для сопоставления столбцов исходной таблицы со столбцами в целевой таблице базы данных Greenplum:
Запустите клиентское приложение Informatica PowerCenter Designer.
В списке Repositories щелкните правой кнопкой мыши имя репозитория, в котором вы установили компоненты сервера Connector, и выберите Connect .
Введите свои учетные данные для доступа к репозиторию и нажмите Connect .
Щелкните правой кнопкой мыши доступную базу данных в репозитории и выберите Открыть , чтобы открыть ее данные в представлении анализатора.
Разверните узел Sources , чтобы показать исходные таблицы, доступные для сопоставления. При необходимости используйте меню Sources , чтобы определить новую исходную таблицу для отображения в базу данных Greenplum.
 Перед продолжением убедитесь, что доступные исходные таблицы отображаются в папке Sources и в представлении Source Analyzer .Например:
Перед продолжением убедитесь, что доступные исходные таблицы отображаются в папке Sources и в представлении Source Analyzer .Например:Щелкните значок Target Designer , чтобы начать создание целевой таблицы базы данных Greenplum для загрузки данных.
Выберите Targets> Import from Greenplum5 , чтобы отобразить окно Establish Connection :
Введите следующую информацию в окне « Establish Connection », чтобы подключиться к кластеру базы данных Greenplum:
- Адрес хоста загрузчика , Порт хоста загрузчика : введите имя хоста и номер порта, на котором служба GPSS прослушивает соединения.Эти значения должны соответствовать свойствам адреса прослушивания
HostиPortв файле конфигурации JSON, используемом для запуска GPSS. См. Установка и настройка GPSS в базе данных Greenplum. - Главный адрес Greenplum , Главный порт Greenplum : Введите имя хоста и номер порта главного хоста базы данных Greenplum.
- Имя базы данных : Введите имя базы данных, которая содержит таблицы, в которые вы хотите загрузить данные из Informatica.
- Имя пользователя базы данных Greenplum , Пароль : введите имя пользователя и пароль базы данных Greenplum, которые будут использоваться для загрузки данных.
- Использовать SSL : Установите этот флажок, чтобы использовать, если вы настроили GPSS для использования связи
httpsмежду Informatica и службой GPSS. Не устанавливайте этот флажок, если вы настроили GPSS на использование незашифрованногоhttp. - Путь к файлу центра сертификации : Если вы выбрали использование SSL с сертификатами, введите путь к локальному файлу центра сертификации на клиентском компьютере Informatica.
 Этот файл должен содержать центр сертификации, подписавший сертификат для службы GPSS (см. Установка и настройка GPSS в базе данных Greenplum).
Этот файл должен содержать центр сертификации, подписавший сертификат для службы GPSS (см. Установка и настройка GPSS в базе данных Greenplum). - Схема : введите схему базы данных Greenplum, которая содержит таблицы, в которые вы хотите загрузить данные из Informatica.
- Адрес хоста загрузчика , Порт хоста загрузчика : введите имя хоста и номер порта, на котором служба GPSS прослушивает соединения.Эти значения должны соответствовать свойствам адреса прослушивания
Щелкните Connect , чтобы проверить параметры подключения, которые вы ввели. Если соединение установлено успешно, нажмите Next , чтобы отобразить экран View Record Metadata :
Щелкните имя таблицы, чтобы отобразить ее схему на панели предварительного просмотра.Используйте флажки, чтобы выбрать одну или несколько таблиц, которые будут использоваться в качестве цели для операций загрузки.
Щелкните Finish , чтобы добавить целевые таблицы в окно Target Designer. Например:
Щелкните значок Mapping Designer , чтобы начать создание сопоставления между исходной таблицей и целевой таблицей базы данных Greenplum.
Перетащите имя исходной таблицы из списка Repositories на панель Mapping Designer.Введите имя для нового сопоставления, если PowerCenter предложит вам назвать сопоставление.
Перетащите имя целевой таблицы из списка Repositories на панель Mapping Designer. На этом этапе панель Mapping Designer должна отображать окна Source Definition и Source Qualifier, а также окно Target Definition. Например:
Используя окно Source Qualifier, перетащите от имени доступного столбца в исходной таблице к столбцу, который вы хотите сопоставить в окне Target Definition.При необходимости повторите этот шаг, чтобы сопоставить несколько столбцов между исходной и целевой таблицами.
Шаг 2. Создание и настройка рабочего процесса загрузки данных
Выполните следующие действия, чтобы создать рабочий процесс для загрузки данных между исходной и целевой таблицами:
Находясь в PowerCenter Designer, нажмите кнопку Workflow Manager , чтобы запустить Informatica PowerCenter Workflow Manager.
Выберите Подключения> Приложение… , чтобы открыть браузер подключений приложения:
Выберите Greenplum5 из меню Select Type , затем щелкните New… , чтобы открыть окно редактора соединений:
Используйте поля Attributes для ввода параметров подключения GPSS для коннектора Greenplum Informatica.Эти атрибуты используют те же имена, что и поля, представленные в окне Установить соединение клиента PowerCenter:
- Адрес хоста загрузчика , Порт хоста загрузчика : введите имя хоста и номер порта, на котором служба GPSS прослушивает соединения. Эти значения должны соответствовать свойствам адреса прослушивания
HostиPortв файле конфигурации JSON, используемом для запуска GPSS. См. Установка и настройка GPSS в базе данных Greenplum. - Главный адрес Greenplum , Главный порт Greenplum : Введите имя хоста и номер порта главного хоста базы данных Greenplum.
- Имя базы данных : Введите имя базы данных, которая содержит таблицы, в которые вы хотите загрузить данные из Informatica.
- Имя пользователя базы данных Greenplum , Пароль : введите имя пользователя и пароль базы данных Greenplum, которые будут использоваться для загрузки данных.
- Использовать SSL : Установите этот флажок, чтобы использовать, если вы настроили GPSS для использования связи
httpsмежду Informatica и службой GPSS.Не устанавливайте этот флажок, если вы настроили GPSS на использование незашифрованногоhttp. - Путь к файлу центра сертификации : Если вы выбрали использование SSL с сертификатами, введите путь к локальному файлу центра сертификации на клиентском компьютере Informatica. Этот файл должен содержать центр сертификации, подписавший сертификат для службы GPSS (см. Установка и настройка GPSS в базе данных Greenplum).
- Схема : введите схему базы данных Greenplum, которая содержит таблицы, в которые вы хотите загрузить данные из Informatica.
- Адрес хоста загрузчика , Порт хоста загрузчика : введите имя хоста и номер порта, на котором служба GPSS прослушивает соединения. Эти значения должны соответствовать свойствам адреса прослушивания
Щелкните OK , а затем Закройте , чтобы создать соединение с GPSS.
Вернитесь в клиент PowerCenter Designer и найдите новое отображение, которое вы только что создали. Щелкните правой кнопкой мыши имя сопоставления и выберите Создать рабочий процесс… Появится мастер создания рабочего процесса:
Выберите вариант сеанса для рабочего процесса, затем щелкните Далее .
Убедитесь, что значение объекта соединения для целевых столбцов показывает «Greenplum5», а также наличие соединений для исходных таблиц.(При необходимости создайте соединения для исходных таблиц в Informatica PowerCenter Workflow Manager.) Нажмите Далее , чтобы продолжить. Например:
Щелкните Next , а затем щелкните Finish , чтобы создать новый рабочий процесс.
Вернитесь в Informatica PowerCenter Workflow Manager и найдите новый рабочий процесс, который вы только что создали.
Примечание: Вам может потребоваться Отключить , а затем Подключить к базе данных репозитория, прежде чем новый рабочий процесс появится в PowerCenter Workflow Manager.
Щелкните правой кнопкой мыши имя нового рабочего процесса и выберите Открыть , чтобы открыть его на панели конструктора рабочих процессов. Конструктор WorkFlow должен показать кнопку запуска и имя нового рабочего процесса, как показано ниже:
На панели конструктора рабочих процессов щелкните правой кнопкой мыши имя рабочего процесса и выберите Изменить .. , чтобы настроить необходимые параметры. Откроется окно Edit Tasks .
На левой панели выберите имя цели в вашем сопоставлении.Затем выберите вкладку Mapping .
В списке свойств найдите Тип операции и убедитесь, что он соответствует операции, которую вы хотите выполнить ( Вставьте для вставки данных из исходной таблицы в Greenplum.).
Убедитесь, что в списке свойств установлен флажок для типа операции. Например, если Operation Type показывает значение Insert , также прокрутите вниз и установите флажок рядом со свойством INSERT .Например:
Рассмотрите возможность изменения других свойств, таких как ErrorLimitRows , по мере необходимости для целевой таблицы. См. Настройка свойств целевого сеанса Greenplum для получения дополнительной информации.
Щелкните Применить , затем щелкните ОК , чтобы закрыть окно.
Щелкните правой кнопкой мыши в любом месте области конструктора рабочих процессов и выберите Запустить рабочий процесс для загрузки из исходной таблицы в целевую.Вы можете щелкнуть значок Workflow Monitor , чтобы просмотреть подробный журнал и статистику операций рабочего процесса.
Informatica Cloud Mapping Tutorial для начинающих, Создание первого сопоставления ~ Решения для интеграции данных
В прошлой паре статей мы обсудили основы Informatica Cloud и Informatica Cloud Designer. В этом руководстве мы описываем, как создать базовое сопоставление, сохранить и проверить сопоставление, а также создать задачу настройки сопоставления.Демонстрационное сопоставление считывает и записывает источники данных, а также включает метод параметризации.
Создаваемое здесь отображение считывает исходные данные, отфильтровывает нежелательные данные и записывает данные в цель. Сопоставление также включает параметры для исходного соединения и значение фильтра. В этом руководстве вы можете использовать образец исходного файла учетной записи, доступный в сообществе Informatica Cloud. Вы можете загрузить образец исходного файла по следующей ссылке Образец исходного файла для учебного пособия по сопоставлению.
Шаг 1. Создание сопоставления и конфигурация источника
В следующей процедуре описывается, как создать новое сопоставление и настроить образец плоского файла Account в качестве источника.
- Чтобы создать сопоставление, щелкните «Дизайн»> «Сопоставления»> «Новое сопоставление».
- В диалоговом окне «Новое сопоставление» введите имя сопоставления: Account_by_State. Вы можете использовать подчеркивание в именах сопоставлений и преобразований, но не используйте другие специальные символы.
- Чтобы добавить источник в сопоставление, на палитре преобразования щелкните «Источник».
- На панели «Свойства» на вкладке «Общие» введите имя источника: FF_Account.
- На вкладке Источник настройте следующие свойства:
- Подключение : — Подключение к источнику. Выберите подключение к плоскому файлу для образца исходного файла учетной записи. Или создайте новое подключение к плоскому файлу для образца исходного файла.
- Тип источника : — Тип источника. Выбрать объект.
- Объект : — Исходный объект.Выберите образец исходного файла учетной записи. Для предварительного просмотра исходных данных щелкните Предварительный просмотр данных.
Шаг 2. Создание фильтра и настройка правила поля
В следующей процедуре вы добавляете преобразование «Фильтр» в поток данных и определяете параметр для значения в условии фильтра. Когда вы используете параметр для значения условия фильтрации, вы можете определить значение фильтра, которое хотите использовать при настройке задачи.И вы можете создать отдельную задачу для данных для каждого состояния.
Образец исходного файла Account включает поле State. Когда вы используете поле State в условии фильтрации, вы можете записывать данные в цель по состоянию. Например, когда вы используете State = MD в качестве условия, вы включаете в поток данных учетные записи, зарегистрированные в Мэриленде.
- Чтобы добавить преобразование «Фильтр», на палитре «Преобразование» перетащите преобразование «Фильтр» на холст сопоставления.
- Чтобы связать преобразование «Фильтр» с потоком данных, нарисуйте ссылку от источника FF_Account к преобразованию «Фильтр».Когда вы связываете преобразования, последующее преобразование наследует поля из предыдущего преобразования.
- Чтобы настроить преобразование «Фильтр», выберите преобразование «Фильтр» на холсте сопоставления.
- Чтобы назвать преобразование «Фильтр», на панели «Свойства» щелкните «Общие» и введите имя: Filter_by_State.
- Чтобы настроить правила для полей, щелкните Входящие поля. Правила полей определяют поля, которые входят в преобразование, и их имена. По умолчанию в преобразование включаются все доступные поля.Поскольку мы хотим использовать все поля, не настраивайте дополнительные правила для полей.
- Чтобы настроить условие фильтрации, щелкните Фильтр.
- Чтобы создать простой фильтр с параметром для значения, в поле «Условие фильтра» выберите «Простой».
- Щелкните Добавить новое условие фильтра.
- В поле «Имя поля» выберите «Состояние» и используйте в качестве оператора «Равно».
- В поле «Значение» выберите «Новый параметр».
- В диалоговом окне «Новый параметр» настройте следующие параметры и нажмите «ОК».
- Имя: FConditionValue
- Отображаемая метка: значение фильтра для состояния
- Описание: введите двухсимвольное имя состояния для данных, которые вы хотите использовать.
- Значение по умолчанию: MD. Обратите внимание, что вы можете создать только строковый параметр в этом месте.
- Чтобы сохранить изменения, нажмите «Сохранить»> «Сохранить и продолжить».
Шаг 3. Настройка параметров цели и источника
В следующей процедуре вы настраиваете цель, а затем заменяете исходное соединение параметром.
Поскольку вы планируете параметризовать источник, вам также необходимо использовать параметр для сопоставления полей.
- Чтобы добавить целевое преобразование, на палитре «Преобразование» перетащите целевое преобразование на холст сопоставления.
- Чтобы связать преобразование Target с потоком данных, нарисуйте ссылку от преобразования Filter к преобразованию Target.
- Щелкните вкладку Target и настройте следующие свойства:
- Соединение: — Целевое соединение.Выберите соединение для цели. Или создайте новое соединение с целью. Тип цели: — Тип цели. Выбрать объект.
- Объект: — Целевой объект. Выберите подходящую цель.
- Операция: — Целевая операция. Выберите Вставить.
- Чтобы настроить сопоставление полей, щелкните Сопоставление полей.
- Чтобы отобразить некоторые поля и разрешить отображение остальных полей в задаче, настройте параметр карты полей для частично параметризованного.
- Создайте новый параметр и настройте следующие свойства.
- Имя: PartialFieldMapping.
- Отображаемая метка: частичное сопоставление полей.
- Выберите Разрешить частичное переопределение сопоставления. Это позволяет вам просматривать и редактировать сопоставленные поля в задаче. Если вы хотите запретить разработчику задачи изменять сопоставления полей, настроенные в сопоставлении, снимите этот флажок.
- Сопоставьте поля, которые вы хотите отображать, как сопоставленные в задаче.
- Щелкните Сохранить> Сохранить и продолжить.
- Чтобы отредактировать источник и добавить параметр для исходного соединения, щелкните преобразование FF_Account Source, а затем щелкните вкладку Source.
- Для подключения щелкните «Новый параметр».
- В диалоговом окне «Новый параметр» настройте следующие свойства параметра.
- Имя: SourceConnection.
- Отображаемая этикетка: образец плоского файла.
- Описание: Выберите подключение к файлу образца.
Шаг 4. Проверка сопоставления и создание задач
В следующей процедуре вы сохраняете и проверяете сопоставление.И вы создаете задачу настройки сопоставления на основе сопоставления.
- Чтобы проверить сопоставление, нажмите «Сохранить»> «Сохранить и продолжить».
- Когда вы сохраняете сопоставление, Mapping Designer проверяет сопоставление. Сопоставление допустимо, если Статус в области статуса показывает Действителен.
- Если статус — Недействительный, на панели инструментов щелкните значок Проверка. На панели «Проверка» нажмите «Проверить».
- На панели «Проверка» перечислены преобразования в сопоставлении и статус сопоставления.Отображение должно быть действительным. Если отображаются ошибки, исправьте ошибки. Щелкните Проверить, чтобы убедиться, что ошибки исправлены.
- Обратите внимание, страница Targets не отображается, поскольку целевое соединение и объект определены в сопоставлении.
- На странице «Другие параметры» отображаются остальные параметры для сопоставления.
- Обратите внимание, что, поскольку вы разрешили частичное переопределение сопоставления, в списке «Целевые поля» отображаются все поля. Вы можете сохранить или удалить существующие ссылки.
На следующем шаге вы можете запланировать отображение по заранее определенному расписанию. Надеюсь, вам понравилась эта статья. Нам любопытно узнать ваши отзывы.
Руководство для начинающих по Informatica Axon
Data Governance — это практика, в которой задействованы люди, процессы и технологии для эффективного управления различными рисками, связанными с жизненным циклом данных (например, безопасностью, конфиденциальностью, соблюдением нормативных требований, качеством, надежностью и т. Д.). Основная цель — установить организацию, принципы, стандарты и повторяемые процессы для коллективного управления данными компании. Знание о данных, которыми владеет организация, различных зависимостях и заинтересованных сторонах, участвующих в управлении данными, важно для эффективного управления данными.
Являясь четырехкратным лидером в Magic Quadrant компании Gartner, Informatica Axon представляет собой популярный инструмент управления данными, который упрощает совместную среду для сбора различных объектов данных (сбор метаданных), связывания их и управления доступом к метаданным. Этот «репозиторий знаний» очень помогает в управлении данными, поскольку он предоставляет информацию о том, чем нужно управлять, и как различные активы в организации связаны с интегрированным представлением.
Особенности Informatica Axon
- Совместная среда для партнерства между бизнесом и ИТ
- Собрать все активы данных в организации
- Возможность определять политики управления данными и связывать их с другими аспектами
- Правила, определение и информационная панель качества данных
- Интеграция с Informatica Enterprise Каталог данных и качество данных
- Эффективный поиск по активам данных
- Просмотр информационного потока и взаимосвязи (происхождение системы и происхождение данных)
- Иерархическое структурирование различных аспектов, обеспечивающих бизнес-контекст для данных
- Простое администрирование ролей / пользователей
- Удобная навигация по активам данных
- Распространение знаний между командами
- Функция массовой загрузки для создания активов данных [SV1]
- Получение уведомлений или электронных писем о любых действиях пользователя в рамках управления изменениями
Преимущества Informatica Axon
- Выравнивание ресурсов и четкое определение политик в соответствии с законодательными нормами
- Обеспечивает платформу для демократизации данных хорошего качества
- Снижает затраты, связанные с низким качеством данных, и позволяет бизнесу и ИТ сосредоточиться на монетизации данных
- Интеграция с другими продукты обеспечивают лучшее обнаружение данных и понимание данных
- Улучшенная способность управлять рисками данных
- Устранение переделок и оптимизация эффективности персонала
- Более глубокое знание бизнес-процессов
- Лучшее управление и глобальный обзор проектов в масштабе предприятия
Informatica Каталог Axon
Informatica Axon предоставляет возможность управлять инвентаризацией следующих типов объектов.
Фасеты по умолчанию, видимые в Axon без добавления в представление поиска: Система, Наборы данных, Атрибуты, Глоссарий, Качество данных и Люди:
- Система : используется для управления инвентаризацией приложений и систем, которые используются в организации (веб-приложения, приложения ERP, Excel и т. Д.).
- Наборы данных : Этот фасет содержит структуры данных, обнаруженные в системе. Набор данных — это организованный набор атрибутов, которые описывают конкретную предметную область / домен (примеры: продукт, заказ, элемент и т. Д.).
- Атрибуты : представляет характеристику объекта (примеры: ProductID, ProductName, Price и т. Д.).
- Глоссарий : Содержит определение бизнес-терминов, наборов данных, атрибутов и других объектов.
- Качество данных: Содержит метрики или правила качества данных.
- People : содержит информацию о пользователях, созданных в приложении Axon. Каждый пользователь связан с ролью, зависящей от функции пользователя, и пользователи могут выполнять действия в приложении на основе своих ролей.
Вот скриншот фасетов по умолчанию. Мы можем добавить дополнительные фасеты, нажав кнопку «+» рядом с фасетом «Люди». Дополнительный выбор фасетов нужно будет делать каждый раз, когда мы авторизуемся в приложении Axon.
Вот дополнительные фасеты, которые можно добавить в окно поиска Axon:
- Интерфейс : перечисляет все интерфейсы, которые определяют поток информации между системами.
- Запрос на изменение : Запрос на изменение предназначен для облегчения обсуждения и изменения процесса утверждения между заинтересованными сторонами объекта и пользователями Axon.
- Клиент : используется для классификации клиентов по различным сегментам и связывания ресурсов, определенных в Axon, с клиентскими сегментами. Например, мы могли бы определить различные клиентские сегменты или сегменты рынка (Север, Юг, Восток, Запад, Поколение Y, Поколение X и т. Д.) И связать их с различными наборами данных и системами.
- Политика : содержит подробную информацию о политиках, которые должны применяться в организации. Например, можно создать подробные политики, связанные с HIPAA, и связать эти политики с различными объектами процессов.
- Процесс : Позволяет нам составлять список процессов с такими деталями, как краткое описание, владелец, входы, выходы, родительский процесс и т. Д., И связывать эти процессы с другими объектами (Глоссарий, Система и т. Д.).
- Продукт : Предоставляет возможность инвентаризации производственной информации об организации и связывания ее с другими аспектами.
- Проект : упрощает сбор данных, связанных с проектами внутри организации, и связывает их с другими аспектами, такими как политика, глоссарий и система.
Чтобы создать объект, щелкните ссылку «Создать» в верхней части экрана и выберите соответствующий объект из меню, как показано на рисунке ниже. Здесь, на этом рисунке, создается новый интерфейсный объект. И вы можете заметить, что обязательным объектом для интерфейса является «Система».
Создание объектов в правильном порядке
Объекты в Axon необходимо создавать в последовательном порядке. Например, набор данных не может быть создан до тех пор, пока не будут созданы система и элемент глоссария, который описывает его.Итак, каждый объект зависит от других родительских объектов, которые должны быть созданы. Вот порядок объектов в последовательном порядке.
- Организационная единица
- Люди
- Глоссарий
- Система
- Набор данных
- Атрибуты
- Интерфейс
- Ссылка на атрибут данных
- Правило качества данных
- Политика
- Процесс
- Проект
Объекты в Axon могут быть создается вручную, используя ссылку «Создать» в верхней части окна Axon, а затем выбирая соответствующий объект из опций меню, как обсуждалось ранее.После создания и сохранения объекта становятся доступными дополнительные вкладки для установления связей между другими объектами с текущим объектом.
Существует еще один вариант создания объектов в Axon с помощью «массовой загрузки». Это упрощает массовую загрузку данных с использованием формата файла CSV с уже существующими шаблонами для каждого объекта или для создания отношений между объектами.
Массовую загрузку можно выполнить, выбрав ссылку «Создать» и щелкнув пункт меню «Создать из файла.При выборе «типа загрузки» это может быть один из вариантов «Объект», «Отношения» или «Роли». Затем укажите фактический объект / отношение / роль, определите параметры загрузки как «Новые / существующие» и нажмите «Столбцы следующей карты». На следующем экране сопоставления будут правильно сопоставлены, а затем нажмите «Загрузить». Строка состояния покажет статус завершения и успешную загрузку. Любые ошибки данных, связанные с загрузкой файла, могут быть исправлены, и файл может быть загружен снова.
Вы также можете загрузить шаблон, используя опцию «Загрузить шаблон».Вот скриншот шаблона для системных объектов.
Красные столбцы являются обязательными, остальные — необязательными. Файл не может быть загружен, если в обязательных столбцах отсутствуют данные.
Unison Search против быстрого поиска в Informatica Axon
Unison search объединяет поиск по различным аспектам — например, на снимке экрана ниже, поиск выполняется по CMD-ID в инвентаре глоссария. В результате информация, связанная с CMD-ID, фильтруется по всем аспектам.
Ниже приведен снимок экрана с отфильтрованными фасетами на основе Unison Search. Мы видим, что количество наборов данных уменьшено до 18 из 85. Когда вы нажмете на инвентарь наборов данных, вы увидите только 18 наборов данных, которые связаны с объектом глоссария CMD-ID. Мы можем выполнять поиск Unison по нескольким объектам одновременно. Выберите строку в сетке, которую необходимо добавить к существующему поиску в унисон, и нажмите кнопку поиска, чтобы добавить эту строку в поиск. Таким образом, мы можем искать несколько объектов одновременно.Мы также можем очистить поиск, нажав кнопку поиска, чтобы «Удалить объект» или «Очистить поиск», чтобы начать с нуля. Это очень полезный вариант поиска, когда нам нужно фильтровать по объекту для просмотра связанных объектов по разным аспектам.
С другой стороны, быстрый поиск предназначен для поиска определенного объекта, и результаты будут отображаться для этого объекта, и никакие фильтры не будут применяться на других вкладках инвентаря. Мы можем найти опцию быстрого поиска в правой части окна Axon со значком увеличительного стекла.
О чем следует помнить при использовании Axon
- Согласуйте внедрение Axon с видением, целями, задачами и планом развития вашей организации.
- Привлекайте весь бизнес к внедрению Axon и сбору знаний.
- Начните с POC, завоюйте доверие заинтересованных сторон и итеративно создавайте базу знаний.
- Используйте интеграцию с другими продуктами Informatica (например: EDC, IDQ).
- Axon не является инструментом каталогизации данных.Каталог корпоративных данных — это инструмент каталогизации, который может сканировать все физические (технические) активы данных в организации, тогда как Axon предоставляет возможность помещать данные в контекст.
Сводка
Сотрудничество между бизнесом и ИТ — ключевой аспект успеха программ Data Governance. Сбор знаний о различных активах предприятия и их взаимоотношениях дает бизнесу контекст, который помогает расставить приоритеты в отношении того, чем необходимо управлять. Инструмент Informatica Axon облегчает сбор данных, относящихся не только к наборам данных, но и к системам, процессам, проектам, правилам, клиентам и т. Д., которые жизненно важны для успешной программы управления данными.
Если у вас есть вопросы о Data Governance, Informatica Axon или вам нужна помощь по вашей программе Data Governance, свяжитесь с нами, оставив комментарии к этому сообщению в блоге или свяжитесь с нами здесь.
Databricks и Informatica ускоряют разработку и полное управление данными для интеллектуальных конвейеров данных
Ценность аналитики и машинного обучения для организаций хорошо известна. Наш недавний опрос ИТ-директоров показал, что 90% организаций инвестируют в аналитику, машинное обучение и искусственный интеллект.Но мы также отметили, что самым большим препятствием является получение нужных данных в нужном месте и в нужном формате. Поэтому мы стали партнерами Informatica, чтобы позволить организациям добиться большего успеха, открывая новые способы обнаружения, сбора и подготовки данных для аналитики.
Получение данных непосредственно в Delta Lake
Получить большие объемы данных из гибридных источников данных в озеро данных надежным и высокопроизводительным способом сложно. Наборы данных часто сбрасываются в неуправляемые озера данных без какой-либо цели.Данные сбрасываются в озера данных без согласованного формата, что делает невозможным смешивание операций чтения и добавления. Данные также могут быть повреждены в процессе записи в озеро данных, так как запись может завершиться ошибкой и оставить частичные наборы данных.
Informatica Cloud Data Ingestion (CDI) позволяет принимать данные из сотен источников данных. Благодаря интеграции CDI с Delta Lake, интеллектуальное потребление может происходить с преимуществами Delta Lake. Транзакции ACID гарантируют, что запись завершена, или откатываются в случае сбоя, не оставляя артефактов.Применение схемы Delta Lake гарантирует правильность типов данных и наличие необходимых столбцов, предотвращая повреждение данных из-за неправильных данных. Полная интеграция между Informatica CDI и Delta Lake позволяет инженерам по обработке данных быстро принимать большие объемы данных из нескольких гибридных источников в озеро данных с высокой надежностью и производительностью
Препарат
Каждая организация ограничена в ресурсах для форматирования данных для аналитики. Обеспечение возможности использования наборов данных в моделях машинного обучения требует сложных преобразований, на создание которых уходит много времени.Недостаточно высококвалифицированных инженеров по обработке данных, чтобы кодировать расширенные преобразования ETL для масштабируемых данных. Кроме того, код ETL может быть трудным для устранения или изменения.
Интеграция Informatica Big Data Management (BDM) и унифицированной аналитической платформы Databricks упрощает создание конвейеров больших объемов данных для масштабируемых данных. Интерфейс перетаскивания BDM снижает планку для команд при создании преобразований данных, устраняя необходимость писать код для создания конвейеров данных.А простые в обслуживании и модификации конвейеры BDM могут использовать масштабируемость большого объема Databricks, перемещая эту работу вниз для обработки. Результат — более быстрая и недорогая разработка конвейеров больших объемов данных для проектов машинного обучения. Создание и развертывание конвейеров увеличено в 5 раз, конвейеры легче обслуживать и устранять неполадки.
Открытие
Найти подходящие наборы данных для машинного обучения сложно. Специалисты по обработке данных тратят драгоценное время на поиск подходящих наборов данных для своих моделей, которые помогут решить критические проблемы.Они не могут определить, какие наборы данных полны и правильно отформатированы и были должным образом проверены на предмет использования в качестве правильных наборов данных.
Благодаря интеграции Informatica Enterprise Data Catalog (EDC) с унифицированной аналитической платформой Databricks, специалисты по данным теперь могут находить нужные данные для создания моделей и проведения аналитики. Система CLAIRE от Informatica использует искусственный интеллект и машинное обучение для автоматического обнаружения данных и предоставления разумных рекомендаций специалистам по данным.Специалисты по обработке данных могут быстро находить, проверять и предоставлять свои аналитические модели, что значительно сокращает время окупаемости. Databricks может запускать модели машинного обучения в неограниченном масштабе, чтобы получать ценные сведения. И EDC теперь может отслеживать данные и в Delta Lake, делая их частью каталога корпоративных данных.
Родословная
Отследить происхождение обработки данных для аналитики было практически невозможно. Инженеры и специалисты по обработке данных не могут предоставить никаких доказательств происхождения, чтобы показать, откуда пришли данные.И когда данные обрабатываются для создания моделей, определение того, какая версия набора данных, модели или даже какие аналитические платформы и библиотеки использовались, становится настолько сложным, что выходит за рамки наших возможностей для ручного отслеживания.
Благодаря интеграции Informatica EDC, а также Delta Lake и MLflow, работающих внутри Databricks, специалисты по данным могут проверять происхождение данных из источника, отслеживать точную версию данных в Delta Lake, а также отслеживать и воспроизводить модели, фреймворки и библиотеки. используется для обработки данных для аналитики.Эта возможность отслеживать решения Data Science вплоть до источника предоставляет организациям эффективный способ проверки и воспроизведения результатов по мере необходимости для демонстрации соответствия.
Мы очень довольны этими интеграциями и тем влиянием, которое они окажут на успех организаций, позволив им автоматизировать конвейеры данных и лучше понять эти конвейеры. Для получения дополнительной информации зарегистрируйтесь на этот веб-семинар https://dbricks.co/INFA19.
Преобразование XML в Informatica — Perficient Blogs
Введение
В этом документе мы увидим, как обрабатывать XML-данные в Informatica Mapping.Перед этим мы должны знать, что такое преобразование в Informatica.
Informatica Transformations — это объекты репозитория, которые могут читать, изменять или передавать данные в определенные целевые структуры, такие как таблицы, файлы или любые другие требуемые целевые объекты. Преобразование в основном используется для представления набора правил, которые определяют поток данных и способ загрузки данных в целевые объекты.
Что такое преобразования Informatica
В Informatica преобразования помогают преобразовать исходные данные в соответствии с требованиями целевой системы и обеспечивают качество данных, загружаемых в целевую систему.
Преобразования классифицируются как Активный или Пассивный , Подключен или Не подключен
Активное преобразование:
Активное преобразование может изменить количество строк, которые проходят через преобразование, изменить границу транзакции, может изменить тип строки.
Informatica Designer не позволяет нам подключать несколько активных преобразований или активное и пассивное преобразование к одной и той же входящей группе преобразований или преобразований в нисходящем направлении, потому что служба интеграции может быть не в состоянии объединить строки, переданные активными преобразованиями, за исключением преобразования генератора последовательности (SGT). .Потому что он генерирует уникальные числовые значения, поскольку служба интеграции не сталкивается с какими-либо проблемами при объединении строк.
Пассивное преобразование:
Пассивное преобразование не изменяет количество строк, которые проходят через него, поддерживает границу транзакции и поддерживает тип строки.
Informatica Designer позволяет подключать несколько преобразований к одной и той же входящей трансформации или группе входов преобразований, только если все преобразования в ветвях восходящего потока являются пассивными.
Подключено Преобразование:
Преобразования, которые связаны с другими преобразованиями или непосредственно с целевой таблицей в отображении, называются связанными преобразованиями.
Не подключен Преобразование:
Несвязанное преобразование не связано с другими преобразованиями в отображении. Он вызывается в другом преобразовании и возвращает значение этому преобразованию.
Преобразование XML:
Informatica Power Center имеет мощные встроенные функции для обработки XML-данных.Мы можем создать определение XML в Power Center из файла XML, файла DTD, схемы XML, определения плоского файла или определения реляционной таблицы.
У нас есть три типа преобразований XML, и они перечислены ниже:
Преобразование квалификатора источника XML:
Это активное преобразование, а также связанное преобразование. Используется только с определением источника XML. Он представляет собой элементы данных, которые сервер Informatica считывает при выполнении сеанса с источниками XML.Квалификатор источника XML имеет один порт ввода или вывода для каждого столбца в источнике. Если мы удаляем определение источника XML из сопоставления, конструктор также удаляет соответствующее преобразование квалификатора источника XML.
Пример:
Создание определения источника для квалификатора источника XML в Informatica
После подключения к конструктору Informatica с нашими учетными данными перейдите к Source Analyzer , чтобы определить наши XML-данные в качестве источника.Предположим, файл XML находится в нашей локальной файловой системе. Окно определения импорта XML будет вызвано, когда мы сделаем, как показано ниже
Окно определения импорта XML:
Выберите файл Xml Contract.xml в локальной файловой системе и нажмите кнопку «Открыть».
Откроется мастер XML (шаг 1). Нажмите кнопку Далее
Нажмите кнопку «Готово»
В этом примере мы используем XML-файл с отношением Entity, поэтому мы выбираем первый вариант.Если мы используем XML-файл Hierarchies, тогда выберем второй вариант.
В отношении Entity конструктор выбирает корень и создает отдельные представления для сложных типов и повторяющихся элементов. Он определяет отношения и наследование между сложными типами. Он определяет отношения между представлениями с ключами.
На скриншоте ниже мы можем видеть, что мы можем видеть наше недавно созданное определение источника XML в Informatica
.Мы можем использовать это определение источника в окне сопоставления, как обычно.Но на этот раз он будет отображаться как квалификатор источника XML вместо квалификатора источника. См. Диаграмму ниже.
Мы можем использовать обязательные поля из этого квалификатора источника и загружать его в наши целевые таблицы в зависимости от бизнес-требований. В нашем примере квалификатор источника XML имеет множество представлений для контракта XML. См. Снимок экрана ниже для представлений XML. Дважды щелкните определение источника.
Если нам потребуется отредактировать какое-либо из свойств XML или столбца, то это изменение будет выполнено в этом представлении и будет проверено.Пожалуйста, перейдите к XML Views-> Validate XML Definition, как показано ниже
В случае, если мы хотим отредактировать файловую структуру XSD, которая использовалась ранее, это будет взято следующим образом в самом представлении XML. Нажмите «Просмотр» -> «Метаданные XML
».Щелкните без пространства имен, чтобы получить файл XSD, он откроет файл в установленном редакторе XSD, таком как Microsoft Visual Studio
.Преобразование синтаксического анализатора XML:
Это активное преобразование, а также связанное преобразование.Он используется для извлечения XML внутри конвейера и последующей передачи его в цель. XML извлекается из исходных систем, таких как файлы или базы данных. Преобразование XML Parser считывает данные XML из одного входного порта и записывает данные в один или несколько выходных портов.
Пример:
Если определение источника представляет собой плоский файл или реляционную таблицу, которая содержит один столбец в виде данных XML (тип данных Clob), то для извлечения данных будет использоваться анализатор XML.
Перейдите в Источник-> Импорт из базы данных
Столбец XDATA содержит значение XML.Только один столбец данных XML может быть проанализирован с помощью преобразования синтаксического анализатора XML. Потому что для преобразования синтаксического анализатора XML разрешен только один входной порт. Но мы можем передать другие столбцы, такие как столбцы REQ_ID, TRANSMISSION_ID, в преобразование синтаксического анализатора XML.
Перенести определение источника в Mapping Designer
Теперь нам нужно создать преобразование синтаксического анализатора XML, используя файл XSD столбца XDATA из определения источника. Перейдите в Преобразование -> Создать в Mapping Designer
.Выберите XML Parser в раскрывающемся списке Тип преобразования и нажмите на создание
.Откроется окно определения импорта XML для импорта файла XSD.Нажмите «Открыть
«.После импорта файла XSD нажмите Далее
Нам нужно выбрать тип структуры XSD, как мы следовали в XML Source Qualifier. Нажмите Готово на шаге ниже.
Нажмите Готово, чтобы завершить создание преобразования XML-парсера.
Когда мы закончим создание преобразования XML-анализатора, нам нужно связать столбец XDATA из определения источника с вводом данных в преобразовании XML-анализатора.
В случае, если обычные поля из определения источника также необходимы для цели, тогда эти поля могут быть приняты как столбцы $ Pass Thru в преобразовании синтаксического анализатора XML.
В приведенном ниже примере REQ_ID и TRANSMISSION ID используются в качестве столбцов Pass Thru в преобразовании синтаксического анализатора XML.
