Копирование текста из рисунков и распечаток файлов с помощью OCR в OneNote
OneNote для Microsoft 365 OneNote 2021 OneNote 2016 OneNote 2013 Еще…Меньше
Программа OneNote поддерживает распознавание текста (OCR) — инструмент, позволяющий скопировать текст из изображения или распечатки файла и вставить в заметки, чтобы можно было его редактировать. Это очень удобно, например, если нужно скопировать данные с визитной карточки, сохраненной в OneNote в виде отсканированного изображения. После извлечения текст можно вставить в другом месте в OneNote или в другой программе, например Outlook или Word.
Извлечение текста из одного рисунка
-
Щелкните изображение правой кнопкой мыши и выберите команду Копировать текст из рисунка.
Примечание: В зависимости от сложности, удобочитаемости и объема текста, отображаемого на вставленном рисунке, эта команда может быть не сразу доступна в меню, которое отображается при щелчке правой кнопкой мыши рисунка.

-
Поместите курсор в то место, куда нужно вставить скопированный текст, и нажмите клавиши CTRL+V.

Извлечение текста из изображений распечатки многостраничного файла
-
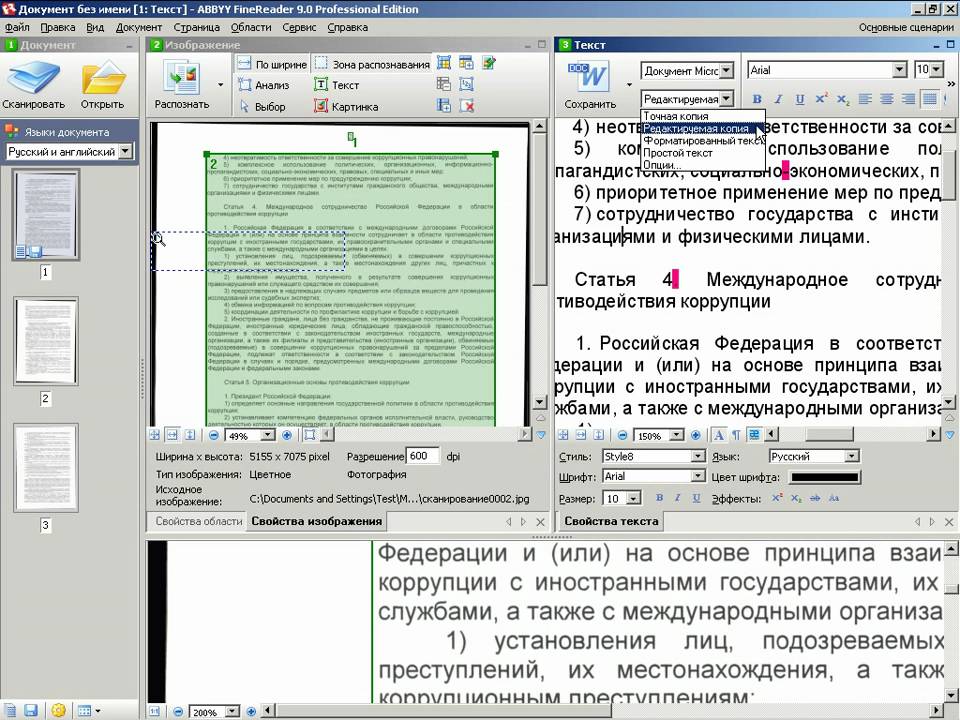
Щелкните правой кнопкой мыши любое изображение и выполните одно из следующих действий:
-
Чтобы скопировать текст только из выделенного изображения (страницы), выберите команду Копировать текст с этой страницы распечатки.
-
Чтобы скопировать текст из всех изображений (страниц), выберите команду Копировать текст со всех страниц распечатки
-
-
Поместите курсор в то место, куда нужно вставить скопированный текст, и нажмите клавиши CTRL+V.
Примечание: Эффективность распознавания текста зависит от качества изображения, с которым вы работаете. Вставив текст из изображения или распечатки файла, проверьте, правильно ли он распознан.
Глоссарий
Глоссарий| А | Б | З | И | К | Л | М | Н | О | П | Р | С | Т | Ф | Ш | Э | Я |
ABBYY Hot Folder & Scheduling -
приложение-планировщик, с помощью которого можно назначить время
обработки документов из выбранной папки.
ABBYY Screenshot Reader — приложение, позволяющее сделать снимок выбранной области экрана и распознать текст, содержащийся на нем.
ADF (Automatic Document Feeder) — устройство автоматической подачи бумаги, позволяющее отсканировать большое количество документов без ручного вмешательства. ABBYY FineReader поддерживает сканирование многостраничных документов.
dpi (Dots per Inch) — количество точек на дюйм; единица измерения разрешения.
Scan&Read — главная кнопка программы, по нажатию на которую система сканирует изображение и распознает (анализирует макет страницы и распознает документ).
TWAIN, TWAIN-диалог — диалог сканера.
Unicode — стандарт, разработанный концерном Unicode. Управляет процессом кодирования символов и предоставляет
шестнадцатибитную международную расширяемую систему кодировки
символов для обработки информации на большинстве языков народов
мира. Стандарт Unicode определяет кодировку символа, а также
свойства и алгоритмы, используемые при реализации этого
процесса.
Управляет процессом кодирования символов и предоставляет
шестнадцатибитную международную расширяемую систему кодировки
символов для обработки информации на большинстве языков народов
мира. Стандарт Unicode определяет кодировку символа, а также
свойства и алгоритмы, используемые при реализации этого
процесса.
А
Аббревиатура — сокращение, образованное из начальных букв слов. Например, МГУ, MS-DOS и т.д.
Активация — процесс получения пользователем в компании ABBYY специального кода, необходимого для обеспечения работы программы в полнофункциональном режиме на конкретном компьютере.
Активационный код — код, который выдается пользователю после прохождения процедуры активации (для версии Professional Edition). Предназначен для активации продукта на той машине, на которой был получен Installation ID.
 В нем содержится информация, необходимая для активации
сервера или компьютера (в случае установки на отдельное рабочее
место). Рабочие станции активируются сервером.
В нем содержится информация, необходимая для активации
сервера или компьютера (в случае установки на отдельное рабочее
место). Рабочие станции активируются сервером.
Автоподбор яркости - автоматический подбор яркости, производится сканером или системой ABBYY FineReader. Автоподбор позволяет подбирать яркость для каждого участка изображения в отдельности.
Анализ макета страницы (выделение блоков) — процесс выделения блоков на изображении. Блоки могут быть разных типов. Анализ макета может проводиться автоматически одновременно с распознаванием при нажатии кнопки 2-Распознать или вручную до распознавания.
Б
Блок — участок изображения, выделенный в рамку.
Д
Драйвер — программа, управляющая устройством.
К началу
З
Запрещенные символы — в качестве запрещенных символов для текущего языка указываются те, которые заведомо не могут встречаться в текстах, распознаваемых с подключением данного языка. Указание таких символов может существенно увеличить скорость и надежность распознавания. Например, при распознавании текстов, в которых встречаются только заглавные буквы, в качестве запрещенных следует указать все строчные буквы.
Зона распознавания — блок используется для распознавания и автоматического анализа части изображения. После нажатия на кнопку
И
К началу
Игнорируемые символы — в качестве
игнорируемых символов указываются те, которые могут встречаться
внутри слова, например, знаки слогоделения или ударения в словарях. При проверке по словарю программа не учитывает эти знаки. В
распознанном тексте эти символы сохраняются, но при проверке
орфографии не учитываются.
При проверке по словарю программа не учитывает эти знаки. В
распознанном тексте эти символы сохраняются, но при проверке
орфографии не учитываются.
Инвертированное изображение
К
К началу
Картинка — блок, используемый для выделения картинок. Он может содержать картинку или любую другую часть текста, которую вы хотите передать в распознанный текст в качестве картинки.
Кодовая страница — таблица, в которой задано отношение между кодами символов и их начертаниями. В системе ABBYY FineReader кодовая страница представлена как набор символов, из которого можно выбрать нужные символы.
Л
К началу
Лигатура
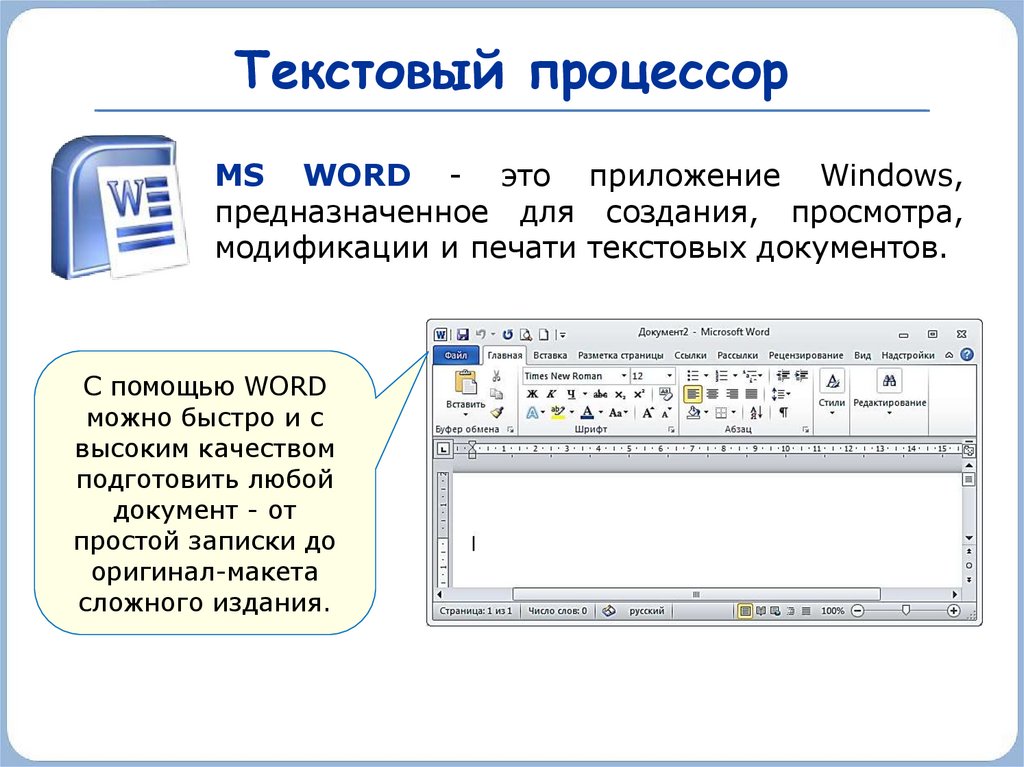 Например, ге, го,
fe, ffi, tt и т.п.
Например, ге, го,
fe, ffi, tt и т.п.
М
Мастер Scan&Read — специальный режим сканирования и распознавания, в котором система контролирует действия пользователя и подсказывает ему, что делать, чтобы получить тот или иной результат.
Макет страницы — расположение текста, таблиц и картинок в документе, разбиение на абзацы, гарнитура и размер шрифта, колонки, направление текста, цвет букв и фон текста.
Менеджер лицензий — приложение, в котором осуществляется управление лицензиями и активация ABBYY FineReader 8.0 Corporate Edition.
Менеждер сценариев — встроенный менеджер, позволяющий запускать выполнение сценариев, создавать сценарии и настраивать их, а также удалять неиспользуемые пользовательские сценарии.
Моноширинный шрифт — любой шрифт, буквы которого имеют
одинаковую ширину (моно). Например, шрифт Courier New. Для
улучшения качества распознавания моноширинных шрифтов на закладке
Распознать в
пункте Тип печати установите переключатель в положение
Пишущая машинка.
Например, шрифт Courier New. Для
улучшения качества распознавания моноширинных шрифтов на закладке
Распознать в
пункте Тип печати установите переключатель в положение
Пишущая машинка.
Мягкий перенос — перенос (¬) показывает, в каком именно месте должно быть разорвано слово или словосочетание (например, «Автоформат»), если оно попадает на конец строки (например, «Авто-формат»). Все переносы в словарных словах ABBYY FineReader заменяет на мягкий перенос.
Н
Набор опций — совокупность значений опций, расположенных
на закладках Сканировать/Открыть, Распознать,
Проверить и Сохранить диалога Опции, а также в
диалогах Форматы и Дополнительные опции. В набор
опций также входят пользовательские языки и эталоны. Набор опций
можно сохранить и затем использовать (загружать) в другие пакеты
ABBYY FineReader.
Начертание шрифта — способ выделения в тексте (полужирный, наклонный, с подчеркиванием, перечеркнутый, верхний индекс, нижний индекс, малые прописные).
Начальная форма — форма, в которой слова даются в словаре. Для существительных это форма именительного падежа единственного числа; для прилагательных — форма мужского рода единственного числа именительного падежа; для глаголов, причастий и деепричастий — это неопределенная форма (инфинитив).
О
Обучение — создание пар «растровое изображение — название символа».
Омнифонтовая система — система распознавания, которая распознает символы практически любых размеров и начертаний.
Очистка изображения — удаление отдельных мелких черных точек на изображении.
П
К началу
Пакет — это папка, в которой хранятся изображения и
рабочие файлы программы. В пакете может содержаться до 9999
страниц. В один пакет для удобства работы рекомендуется объединять
изображения, логически связанные между собой (например, страницы
одной книги, тексты на одном языке или изображения с однотипным
расположением текста и т.д.).
В пакете может содержаться до 9999
страниц. В один пакет для удобства работы рекомендуется объединять
изображения, логически связанные между собой (например, страницы
одной книги, тексты на одном языке или изображения с однотипным
расположением текста и т.д.).
Парадигма — совокупность всех грамматических форм слова.
Параметры защиты PDF — ограничения на открытие, редактирование копирование и печать PDF документа. В эти параметры входят пароль открытия документа, пароль для изменения прав доступа и уровень шифрования.
Пароль для изменения прав доступа — пароль, присваиваемый PDF документам. Пользователи могут распечатать или внести изменения в PDF документ только после ввода пароля, заданного автором документа. При использовании защиты PDF документа пользователи также должны будут указать этот пароль, для того чтобы изменить параметры защиты PDF.
Пароль открытия документа — пароль, присваиваемый PDF
документам. Пользователи могут открыть PDF документ только после
ввода пароля, заданного автором документа.
Пользователи могут открыть PDF документ только после
ввода пароля, заданного автором документа.
Префиксы — небуквенные символы, которые могут встречаться в абсолютном начале слова.
Принцип одной кнопки — принцип, когда при нажатии на одну кнопку (Scan&Read) система сканирует и распознает документ.
Р
К началу
Разделители — символы, которые могут разделять слова, например, /, \, тире и т.п. и которые пишутся отдельно от слов.
Разрешение — параметр сканирования, показывает кол-во точек на единицу длины. 300 dpi (размер шрифта 10 и более пунктов), 400-600 dpi для текстов, набранных мелким шрифтом (9 и менее пунктов).
С
Свойства документа — свойства, присваиваемые
документу и позволяющие выполнять поиск документов и их сортировку.
Свойства документа включают описательное название, имя
автора, тему и ключевые слова.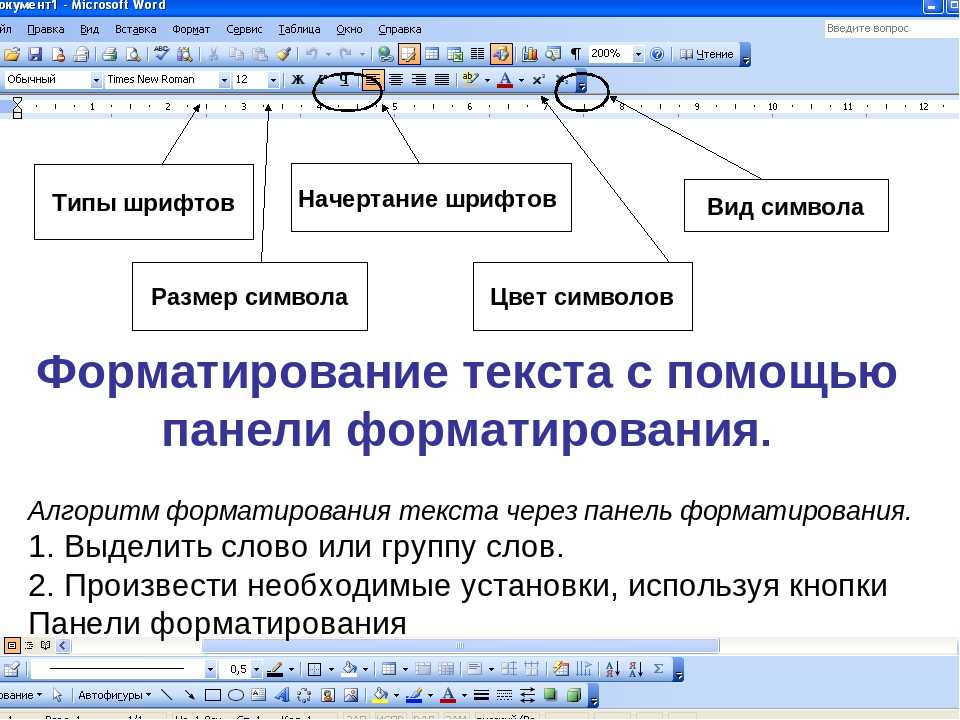
Сканер — устройство, предназначенное для ввода изображений в компьютер.
Сложное слово — слово, отсутствующее в словаре, но которое может быть образовано из имеющихся в словаре слов.
Сценарий ABBYY FineReader — это набор последовательных шагов, каждый из которых соответствует одному этапу обработки документа. В программе ABBYY FineReader 8.0 предусмотрено три встроенные сценария, полностью готовых к использованию, также можно создавать собственные — пользовательские сценарии. Запуск сценария осуществляется по кнопке Scan&Read.
Суффиксы — небуквенные символы, которые могут встречаться в абсолютном конце слова.
К началу
Т
Таблица — блок, используемый для выделения таблиц или
текста, имеющего табличную структуру. При распознавании программа
разбивает данный блок на строки и столбцы и формирует табличную
структуру. В выходном тексте данный блок передается таблицей.
В выходном тексте данный блок передается таблицей.
Теги PDF — специальные теги, используемые для выделения логических частей и разметки таблиц и картинок в PDF документе. Теги, встариваемые в PDF документ, обеспечивают удобство просмотра документа на экранах разного размера, например, экранах карманных компьютеров.
Текст — блок, используемый для выделения текстовых областей. Он должен содержать только одноколоночный текст.
Тип изображения — параметр сканирования; изображение может быть черно-белым, серым или цветным.
Тип (печати) входного текста — особенность в начертании
символов входного текста, в зависимости от того, каким образом он
напечатан (в типографии, на матричном принтере в черновом режиме,
на пишущей машинке). Для типографского текста следует устанавливать
режим Авто, для машинописного — режим Пишущая
машинка, для текста, напечатанного на матричном принтере в
черновом режиме — режим матричный принтер.
Тип блока — блок может быть Зоной распознавания, Текстовым, Картинкой, Таблицей, Штрих-кодом.
Ф
Фоновое распознавание — режим, позволяющий одновременно с распознаванием редактировать и сохранять распознанные страницы.
Ш
Шаблон блоков — в шаблоне описано положение и размеры блоков на странице.
Штрих-код — блок, используемый для участков изображения, содержащих штрих-код.
Э
Эталон — набор пар «усредненное точечное изображение символа — его название», который создается в процессе обучения системы на конкретном тексте.
Я
Яркость — параметр сканирования, определяет
контрастность, т.е. различие между черными и белыми участками
текста. При правильной настройке яркости качество
распознавания возрастает.
- Перевести на английский
Распознавание шрифтов в изображениях с помощью новой функции извлечения — видеоруководство по InDesign
Из курса: InDesign Tips for Design Geeks
Видео заблокировано.
Разблокируйте этот курс с бесплатной пробной версией
Присоединяйтесь сегодня, чтобы получить доступ к более чем 20 600 курсам, которые преподают отраслевые эксперты.
Распознавание шрифтов на изображениях с помощью новой функции извлечения
“
— [Энн-Мари] Привет, ребята.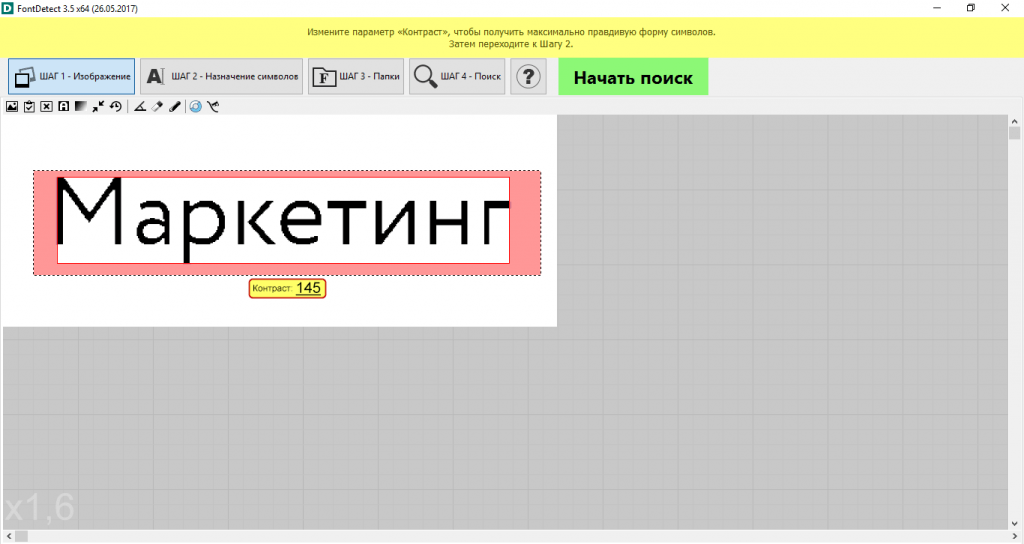 Это Энн-Мари из «Советов по InDesign для дизайнеров». Сегодня я хочу показать вам эту действительно удобную новую функцию, появившуюся в InDesign 2022, которая позволяет извлекать информацию из размещенного или связанного изображения. Итак, здесь я выбрал размещенный файл Illustrator. Вы можете увидеть это здесь, на панели ссылок. Ничего в рукаве, ладно? Теперь я могу извлекать шрифты, цвета или формы прямо в InDesign. Вы найдете эту команду, перейдя в меню «Объект» и выбрав «Извлечь из изображения», «Цветовые темы», «Фигуры» или «Тип», или вы можете сделать это, просто щелкнув правой кнопкой мыши. Теперь, если я выберу «Тип», я хочу, чтобы вы заметили, что здесь открылся мастер, но посмотрите, что произошло с библиотеками CC. Итак, небольшой совет, от которого я собираюсь отказаться, заключается в том, что он настаивает на добавлении ваших шрифтов или цветовых тем в CC Library. Я тоже думаю о формах. Он не может просто поместить это на страницу, или он не может просто…
Это Энн-Мари из «Советов по InDesign для дизайнеров». Сегодня я хочу показать вам эту действительно удобную новую функцию, появившуюся в InDesign 2022, которая позволяет извлекать информацию из размещенного или связанного изображения. Итак, здесь я выбрал размещенный файл Illustrator. Вы можете увидеть это здесь, на панели ссылок. Ничего в рукаве, ладно? Теперь я могу извлекать шрифты, цвета или формы прямо в InDesign. Вы найдете эту команду, перейдя в меню «Объект» и выбрав «Извлечь из изображения», «Цветовые темы», «Фигуры» или «Тип», или вы можете сделать это, просто щелкнув правой кнопкой мыши. Теперь, если я выберу «Тип», я хочу, чтобы вы заметили, что здесь открылся мастер, но посмотрите, что произошло с библиотеками CC. Итак, небольшой совет, от которого я собираюсь отказаться, заключается в том, что он настаивает на добавлении ваших шрифтов или цветовых тем в CC Library. Я тоже думаю о формах. Он не может просто поместить это на страницу, или он не может просто…
Содержание
Получите четкое векторное изображение в своих файлах для публикации в Интернете, часть первая
5 мин 29 с
Получите четкое векторное изображение в своих файлах для публикации в Интернете, часть вторая
4 мин 45 с
Три подсказки для гибких заголовков, вкладок и таблиц
5 мин 51 с
Нет исходного файла для EPUB, который нужно изменить? Без проблем!
6м 53с
Настройка переноса InDesign определенного слова
5 мин 32 с
Как использовать InCopy с InDesign
7 мин 12 с
Передовой опыт комментирования PDF для ваших рецензентов
7 мин 40 с
Масштабирование изображений в InDesign по сравнению с их масштабированием в Photoshop
6 м 51 с
Настройки InDesign по умолчанию, которые следует изменить
6 мин 34 с
Из моей коллекции скриптов: Изменить язык в раскладке
5м 1с
Графика Illustrator в InDesign: копирование/вставка или импорт?
5м
Импорт изображения формата Apple HEIC в InDesign
5 мин 24 с
Как смешивать размеры страниц в одном макете
5 м 10 с
Что это за синий значок счастливого лица (и другие загадочные скрытые символы)?
5 м 25 с
обработка изображений — автоматическое распознавание шрифтов с помощью Python
спросил
Изменено 2 года, 9 месяцев назад
Просмотрено 8к раз
Как вы, возможно, слышали, существует онлайн-служба распознавания шрифтов под названием WhatTheFont
Мне любопытно узнать о технологии, лежащей в основе этого инструмента. Я думаю, что в основном мы можем разделить это на две части:
Я думаю, что в основном мы можем разделить это на две части:
Генерация изображений из файлов шрифтов различного формата, обратитесь к http://www.fileinfo.com/filetypes/font за списком расширений файлов шрифтов.
Сравнить отправленное изображение со всеми сгенерированными изображениями
Я ценю, что вы поделились советом или кодом Python для реализации двух шагов выше.
- python
- обработка изображений
- шрифты
0
Как говорится в OP, есть две части (и, возможно, также третья часть):
Используйте PIL для создания изображений из шрифтов.
Используйте набор инструментов для анализа изображений, например OpenCV (с привязками к Python), для сравнения различных форм. Существует множество стандартных методов сравнения различных объектов на предмет их сходства. Например, инвариантные к масштабу моменты работают довольно хорошо и являются частью набора инструментов OpenCv.
Большинство стандартных инструментов в #2 предназначены для поиска похожих, но не обязательно идентичных форм, но для сравнения шрифтов это может быть не то, что вам нужно, поскольку различия между шрифтами могут основываться на очень мелких деталях. Для детального анализа попробуйте сравнить профили x и y пути по периметру вокруг каждой буквы, разумеется, соответствующим образом нормализованные. (Этот или более математически сложный его вариант успешно использовался при анализе шрифтов.)
Я не могу предложить код Python, но есть два возможных подхода.
«Собственные символы». В распознавании лиц, учитывая большой обучающий набор нормализованных изображений лиц, вы можете использовать анализ основных компонентов (PCA), чтобы получить набор «собственных лиц», которые, когда обучающие лица проецируются на это подпространство, демонстрируют наибольшую дисперсию. «Координаты» входных тестовых граней относительно пространства собственных граней можно использовать в качестве вектора признаков для классификации.
 То же самое можно сделать с текстовыми символами, то есть со многими версиями символа «А».
То же самое можно сделать с текстовыми символами, то есть со многими версиями символа «А».Динамическое искажение времени (DTW). Этот метод иногда используется для распознавания рукописного текста. Идея состоит в том, что траектория, пройденная кончиком карандаша (т. е. d/dx, d/dy), одинакова для одинаковых персонажей. DTW делает неизменными некоторые вариации в экземплярах письма одного человека. Точно так же контур персонажа может представлять траекторию. Затем эта траектория становится вектором признаков для каждого набора шрифтов. Я думаю, что часть DTW не так необходима для распознавания шрифтов, потому что символы создает машина, а не человек. Но все же может быть полезно устранить пространственную неоднозначность.
Этот вопрос немного устарел, поэтому здесь идет обновленный ответ .
Вам следует ознакомиться с этой статьей DeepFont: Определите свой шрифт по изображению. По сути, это нейронная сеть, обученная на множестве изображений.