Система распознавания шрифта Брайля. Читаем написанное белым по белому / Хабр
В 2018 году мы взяли из детдома в семью слепую девочку Анжелу. Тогда я думал, что это чисто семейное обстоятельство, никак не связанное с моей профессией разработчика систем компьютерного зрения. Но благодаря дочери через два года появилась программа и интернет-сервис для распознавания текстов, написанных шрифтом Брайля — Angelina Braille Reader.
Сейчас этот сервис используют сотни людей и в России, и за ее пределами. Тема оказалась хайповой, сюжет о программе даже показали в федеральных новостях на ТВ. Но что важнее — за свою многолетнюю карьеру в ИТ ни в одном проекте я не получал столько искренних благодарностей от пользователей.
Ниже расскажу о том, как делалась эта разработка и с какими трудностями пришлось столкнуться. Более развернутое описание приведено в публикациях [1,2].
Возможно, кто-то захочет внести в проект свой вклад.
Лень — двигатель прогресса
Вы все видели брайлевские символы в лифте и в поликлинике. Каждая буква задана выпуклыми точками. Брайль разработал свою азбуку в 1824 году, и ничего лучше для чтения и письма с тех пор не придумали.
Каждая буква задана выпуклыми точками. Брайль разработал свою азбуку в 1824 году, и ничего лучше для чтения и письма с тех пор не придумали.
Сейчас слепые активно используют компьютеры и смартфоны с голосовым помощником, свободно перемещаются по всему миру без сопровождения, устраиваются на работу, требующую высокой квалификации. Представление о том, что слепые сидят дома и плетут на заказ авоськи, давно устарело.
Но слепые школьники до сих пор читают и пишут на Брайле. Все как у обычных людей. Когда вы последний раз писали страницу текста от руки? А школьники делают это ежедневно, и пропустить этот этап нельзя.
Когда мы отдавали дочь в первый класс, то думали, что будет непросто выучить шрифт Брайля. Но это оказалось ерундовой задачей, не труднее, чем выучить любой незнакомый язык в объеме «алфавит в совершенстве».
А вот дальше сложнее. Дело в том, что брайлевские книги — это выдавленные на белой бумаге пупырышки («точки»), никак не выделенные цветом. Слепые тратят год начальной школы на то, чтобы научиться их нащупывать.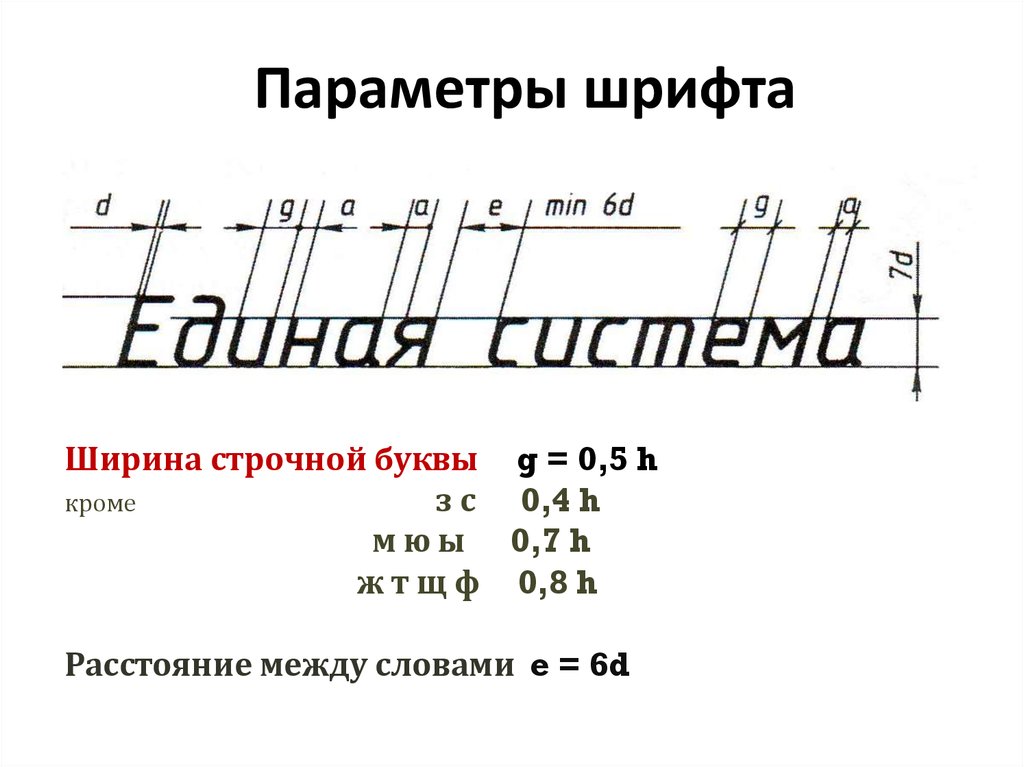 У нас такая чувствительность пальцев не развивается за ненадобностью, поэтому 99% брайлевских педагогов и родителей читают это глазами.
У нас такая чувствительность пальцев не развивается за ненадобностью, поэтому 99% брайлевских педагогов и родителей читают это глазами.
Более того! Как и обычная книга, брайлевская книга обычно двусторонняя. Вместе с выступающими точками, которые надо читать, на той же странице есть точки, выдавленные в обратную сторону. Пальцы слепого эти впуклости не замечают, а глаза зрячего видят, и все это вместе превращается в абсолютную кашу. Вообразите, что вы читаете текст на неродном языке, напечатанный светло-серым на прозрачной пленке с двух сторон.
Фрагмент брайлевской книги с двусторонней печатью (вверху). На нижнем фото отмечены те точки, которые надо читать. Остальные точки — это текст с обратной стороны страницы, на них можете не обращать внимание (если сможете).Рукописный брайлевский текст обычно односторонний, читать его несколько легче, но все равно непросто. В Союзе педагоги приспособились тереть работы школьников копиркой, чтобы сделать точки заметнее, но это решает проблему только отчасти.
Для письма брайлевским шрифтом вручную используется специальный прибор: планшет, состоящий из 2 металлических пластин, между которыми закладывается лист бумаги. В верхней пластине сделаны прямоугольные прорези, одна ячейка — одна буква. Металлическим грифелем (шилом) продавливают бумагу в углах прорези или в середине боковой стороны, всего 6 мест под точки. В этих местах в нижней пластине сделаны углубления, таким образом получаются выдавленные брайлевские точки. Пишут справа налево в зеркальном отражении. А чтобы прочитать текст, бумагу надо вынуть из прибора и перевернуть.
За время обучения дочки в первом классе мы, оба родителя, так замучились таким чтением, что стали весьма мотивированы что-то с этим делать. Мы решили, что приспособить к чтению Брайля компьютер — намного более полезное занятие для папы в свободное время, чем решать конкурсы на Каггле. Потом оказалось, что это нужно не только моей семье, а буквально всем, кто работает со слепыми.
Хочешь сделать хорошо — сделай сам
Разумеется, я был не первым человеком, который занялся компьютерным распознаванием шрифта Брайля на изображении. Есть даже устойчивый термин: OBR (Optical Braille Recognition). Поэтому для начала я попытался найти готовое решение. Напрасно! В открытом доступе имеются только экспериментальные поделки, непригодные для практического применения. Из коммерческих разработок существует специализированный аппаратно-программный комплекс компании ЭлекЖест размером со стол. Это явно не то решение, о котором я мечтал, цену я даже не уточнял.
Система оптического распознавания Брайля от компании ЭлекЖестПопадались программы для распознавания, но они требовали отсканировать лист, причем со специальным светофильтром. Не слишком удобно, тем более что в стандартный сканер А4 брайлевский учебник не помещается. Но хуже то, что даже со сканером и светофильтром у меня не получилось получить приемлемый результат.
После фиаско с поиском готового решения пришлось переключиться на изучение литературы. Статей по оптическому распознаванию Брайля написано много. Во всех статьях процесс распознавания разбивался на этапы, обусловленные ключевым отличием шрифта Брайля от обычных алфавитов в разных языках.
Статей по оптическому распознаванию Брайля написано много. Во всех статьях процесс распознавания разбивался на этапы, обусловленные ключевым отличием шрифта Брайля от обычных алфавитов в разных языках.
В обычном письме буквы представлены связанными линиями, а в письме по Брайлю — комбинацией от 1 до 6 точек, расположенных в узлах воображаемой сетки. Группировка точек в буквы определяется привязкой к этой сетке.
Кодирование букв латинского алфавита шрифтом БрайляВне привязки к сетке, образуемой всеми брайлевскими буквами в целом, точки не имеют смысла. Так, если мы видим на пустом листе бумаги букву А, то мы легко понимаем, что это буква А. Если мы видим одинокую брайлевскую точку, нельзя определить, что это такое: буква А, запятая (она обозначается единственной точкой, но в другом узле сетки) или просто дефект бумаги.
Вследствие этого, для описанных в литературе алгоритмов OBR практически стандартом оказывается следующий набор шагов (см. обзоры [3,4]):
Найти брайлевские точки.

Восстановить воображаемую сетку.
Сопоставить найденные точки с узлами сетки.
Распознать брайлевские символы.
Конвертировать последовательность брайлевских символов в обычный текст.
Разные авторы используют разные методы нахождения точек и, главное, отделения точек лицевой и обратной стороны: динамический порог, детектор окружностей на основе преобразования Хафа, HOG, LBP, SVM, признаки Хаара и алгоритм Виолы-Джонса, — в общем, практически весь джентльменский набор методов классического компьютерного зрения. В более поздних работах нейросетки тоже применяют.
После этого для восстановления сетки используют линейную регрессию, преобразования Хафа, изменения гистограмму распределения координат точек при пошаговом повороте листа…
Не буду приводить подробный обзор литературы (его можно найти в [1,3,4]). Важно, что при таком подходе требуется единая на весь лист воображаемая сетка, к которой привязаны брайлевские точки. Именно поэтому страница должна быть не просто сфотографирована, а отсканирована. Только в этом случае на всем листе точки расположены на параллельных линиях сетки. На случай, если страница при сканировании покосилась, описаны методы нахождения необходимого поворота страницы в исходное положение.
Именно поэтому страница должна быть не просто сфотографирована, а отсканирована. Только в этом случае на всем листе точки расположены на параллельных линиях сетки. На случай, если страница при сканировании покосилась, описаны методы нахождения необходимого поворота страницы в исходное положение.
Я не нашел никаких методов для компенсации перспективных искажений (а без них фотографию не сделаешь). Еще сложнее, если сфотографирован не одиночный лист, а страница раскрытой книги. Брайлевские книги толстые и плотные, полностью расправить страницу невозможно. Линии сетки превращаются в дуги. Так что по всему выходило, что для применения опубликованных методов нужен сканер, причем специальный — обычный бытовой мал.
А хотелось сделать так, чтобы достаточно было сделать фото на смартфон и — вжух! — получить расшифрованный текст. Пришлось делать самому.
У нее внутре нейронка
Когда я начинал эту работу (2019г), нейронные сети уже вовсю покоряли задачи компьютерного зрения. В литературе по распознаванию Брайля тоже говорилось об их использовании. Но весьма ограниченном, не выходя за пределы описанного выше шаблона: или для поиска точек, или для разделения точек лицевой и обратной стороны, или для распознавания отдельного символа после того, как будет восстановлена сетка и точки поделены на символы.
В литературе по распознаванию Брайля тоже говорилось об их использовании. Но весьма ограниченном, не выходя за пределы описанного выше шаблона: или для поиска точек, или для разделения точек лицевой и обратной стороны, или для распознавания отдельного символа после того, как будет восстановлена сетка и точки поделены на символы.
И это при том, что уже несколько лет как были опубликованы one step детекторы типа YOLO[5] и SSD[6], которые решали задачу поиска объектов на изображении за один шаг, совмещая одновременно несколько функций — детекции, классификации, регрессии ограничивающего прямоугольника. Можно было ожидать, что нейросеть справится одновременно с задачей поиска точек, восстановления брайлевской сетки в окрестности каждого символа и распознавания символа за один проход. Это позволяло отойти от требования наличия единой сетки для всего листа и, соответственно, обрабатывать изображения искривленных листов и изображения с небольшими перспективными искажениями.
За основу я взял RetinaNet[7] с некоторыми изменениями по сравнению с исходными настройками: с учетом того, что мы ищем символы примерно известного размера и пропорций, был изменен набор «якорей» и другие параметры.
В конце концов этот подход дал результат, который я считаю весьма успешным. Но его применение упиралось в серьезную проблему.
Где взять данные, или Мойдодыр спешит на помощь.
Как хорошо известно, для решения обучения нейросети требуется много обучающих данных. И если при решении частных задач вроде поиска и классификации точек или даже отдельных символов каждая страница текста порождает множество обучающих примеров, то для обучения object detection сети необходимы достаточно большие фрагменты текста. Поэтому требуется множество размеченных изображений брайлевских страниц.
Сделать фотографии сотни-другой страниц в разных условиях — несложно. А вот разметка… Как выглядят эти страницы, было показано на рисунке выше, трудоемкость разметки можете себе представить. Идея разметить прямоугольниками каждую букву на сотнях таких страниц совсем не вызывала энтузиазма.
В сети удалось найти единственный публично доступный подходящий датасет: DSBI, опубликованный китайскими товарищами. Он включает 114 размеченных страниц брайлевских текстов. Тексты там на китайском, но это как раз неважно (сами по себе брайлевские символы одинаковы во всех языках). Хуже то, что изображения получены с помощью сканера с идеально плоского листа (это позволило авторам упростить процедуру разметки) и очень мало отличаются друг от друга. Поэтому качественно обучить на нем нейросеть для решения поставленной задачи было невозможно. RetinaNet, обученная на этих данных, выдала на реальных фотографиях брайлевских книг более чем скромный результат — от четверти до половины правильно распознанных символов.
Он включает 114 размеченных страниц брайлевских текстов. Тексты там на китайском, но это как раз неважно (сами по себе брайлевские символы одинаковы во всех языках). Хуже то, что изображения получены с помощью сканера с идеально плоского листа (это позволило авторам упростить процедуру разметки) и очень мало отличаются друг от друга. Поэтому качественно обучить на нем нейросеть для решения поставленной задачи было невозможно. RetinaNet, обученная на этих данных, выдала на реальных фотографиях брайлевских книг более чем скромный результат — от четверти до половины правильно распознанных символов.
Лучшего я и не ждал. Однако надо же было с чего-то начать! А дальше на помощь пришел подход Active Learning[8].
Идея традиционного Active Learning состоит в том, что мы обучаем нейросеть на имеющихся данных, применяем ее к неразмеченным данным, оцениваем результат (вручную или автоматически с помощью какого-либо критерия), отбираем неразмеченные примеры, которые распознались хуже всех, размечаем их вручную и повторяем обучение на расширенной выборке. И так несколько раз. Тем самым экономятся трудозатраты на разметку тех примеров, с которыми нейросеть и так справляется. Однако в этой задаче я применил полностью противоположный подход. Дело в том, что разметить страницу, состоящую сплошь из ошибок, гораздо сложнее, чем исправить несколько ошибок там, где существенная часть текста внятно распознана.
И так несколько раз. Тем самым экономятся трудозатраты на разметку тех примеров, с которыми нейросеть и так справляется. Однако в этой задаче я применил полностью противоположный подход. Дело в том, что разметить страницу, состоящую сплошь из ошибок, гораздо сложнее, чем исправить несколько ошибок там, где существенная часть текста внятно распознана.
Особенностью задачи было то, что для многих неразмеченных страниц можно было найти напечатанный там текст в привычном нам виде. Текст, написанный прозой, сопоставить с изображением брайлевской страницы сложно, а вот со стихами все намного проще. Разбивка текста на строки известна, и если в распознанном тексте распознана хотя бы часть символов, которая позволяет идентифицировать строки, то недостающие и ошибочные символы можно восстановить, используя оригинальный текст. Причем лучше использовать даже не стихи, а детские стишки: написанные короткими строками, чтобы не возникало неожиданных переносов строки.
Поэтому первыми русскими текстами, на которых обучалась нейронная сеть, оказались сказки про Мойдодыра, Телефон, Чудо-дерево. Мысль, что иногда автор относится к своему проекту как к собственному ребенку, заиграла новыми красками.
Мысль, что иногда автор относится к своему проекту как к собственному ребенку, заиграла новыми красками.
Когда после нескольких итераций активного обучения качество распознавания достаточно повысилось, можно было включить в обучающий набор прозаические тексты. Сопоставлять их с оригинальным текстом так же, как стихи, было уже слишком сложно, но результаты распознавания можно было преобразовать в плоский текст и проверить спелл-чекером. Большая часть ошибок распознавания при этом подсвечивается, так что разметка радикально облегчается.
Описанный подход привел к идее сделать дальнейший процесс полностью автоматическим. Есть известный метод дообучения нейросети на неразмеченных данных — pseudo labeling[9]. Основная идея метода состоит в том, что результаты распознавания тех неразмеченных данных, где нейросеть показала высокую степень уверенности, включают в обучающий набор в дополнение к исходным размеченным данным, и обучение повторяется.
В описываемой работе в этот цикл я включил этап, на котором учитывается, что найденные нейросетью символы существуют не сами по себе, а должны подчиняться определенным правилам. В первую очередь, можно скорректировать положения символов так, чтобы символы образовывали ровные строки, а также проверить получившиеся слова спелл-чекером и исключить те результаты, которые такую проверку не проходят. Такой подход я предложил назвать «семантически усиленной псевдо-разметкой». В общем случае это — включение в процедуру псевдо-разметки этапа, когда автоматически полученная разметка оценивается и корректируются, используя внешние соображения о допустимости полученных результатов. Это дает существенное улучшение результатов по сравнению с обычной псевдо-разметкой (см. [2]). Возможность вытаскивать самого себя за волосы, обучая нейросеть на ее собственных результатах, заканчивается достаточно быстро и ограничена примерами из того же домена, что и исходные размеченные данные. При семантически усиленной псевдо-разметке в процесс обучения включается дополнительная объективная информация. Это не только позволяет использовать больший объем неразмеченных данных, но и дообучить сеть на неразмеченных данных из домена, отличного от того, к которому относятся исходная размеченная обучающая выборка [2].
В первую очередь, можно скорректировать положения символов так, чтобы символы образовывали ровные строки, а также проверить получившиеся слова спелл-чекером и исключить те результаты, которые такую проверку не проходят. Такой подход я предложил назвать «семантически усиленной псевдо-разметкой». В общем случае это — включение в процедуру псевдо-разметки этапа, когда автоматически полученная разметка оценивается и корректируются, используя внешние соображения о допустимости полученных результатов. Это дает существенное улучшение результатов по сравнению с обычной псевдо-разметкой (см. [2]). Возможность вытаскивать самого себя за волосы, обучая нейросеть на ее собственных результатах, заканчивается достаточно быстро и ограничена примерами из того же домена, что и исходные размеченные данные. При семантически усиленной псевдо-разметке в процесс обучения включается дополнительная объективная информация. Это не только позволяет использовать больший объем неразмеченных данных, но и дообучить сеть на неразмеченных данных из домена, отличного от того, к которому относятся исходная размеченная обучающая выборка [2].
В результате применения описанных подходов получалось программное решение, дающее менее 0.5% ошибочных символов при использовании достаточно качественных изображений (хорошая камера, правильное освещение). Я написал простенький сервис на Flask и развернул на домашнем компьютере сервис, которым стал пользоваться я сам и некоторые наши знакомые по сообществу родителей слепых детей.
Кроме того, в результате этой работы получился «наш ответ Китаю»: датасет Angelina Braille Dataset из 240 размеченных фотографий брайлевских текстов. Существенно более сложный и разнообразный по сравнению датасетом DSBI, опубликованным китайскими разработчиками.
Искусство — в массы
Итак, первое время сервис работал на моем домашнем компьютере и количество пользователей прибывало методом сарафанного радио.
В 2021 описываемый сервис стал одним из победителей конкурса World AI & Data Challenge, который проводит Агентство Стратегических Инициатив. В конкурсе участвуют решения самых разных социльных проблем, построенные с помощью AI и Data science. То, что мой проект занял 2-е место в этом конкурсе, привело к двум важным практическим результатам.
В конкурсе участвуют решения самых разных социльных проблем, построенные с помощью AI и Data science. То, что мой проект занял 2-е место в этом конкурсе, привело к двум важным практическим результатам.
Во-первых, АСИ обеспечило информационную поддержку: в специализированные школы по обучению слепых было направлено официальное письмо с поручением ознакомиться с сервисом и дать отзыв. Организовало несколько zoom-конференций с преподавателями-тифлопедагогами. В результате я получил множество очень мотивирующих отзывов. Самый короткий и емкий прозвучал на одной из видеовстреч: «мы ждали эту программу всю жизнь». Но, самое важное — потенциальные пользователи узнали о программе, преодолели «порог вхождения». Только сарафанным радио достичь такого результата было бы невозможно.
Во-вторых, компания Яндекс выделила победителям конкурса грант на использование вычислительных мощностей Яндекс-облака. Я мог больше не держать сервис на своем домашнем компьютере, а разместить его на выделенной машине Яндекса.
Подробное описание опыта работы с облачной структурой Яндекса заслуживает отдельной статьи. Приведу основной вывод, к которому я пришел. Облачная структура Яндекса очень хороша для масштабных вычислений. Возможность запустить сразу несколько серверов с Tesla V100 — это прекрасно. Однако пока там нет возможности развернуть бюджетный слабонагруженный сервис, если для работы требуется GPU. Выделенная машина с Tesla V100 для данной задачи — сильный «оверкилл за оверпрайс». Надеюсь, что со временем и для этой ниши будет предложено подходящее решение.
Решить проблему помог грант Фонда Президенских Грантов, предоставленный АНО «Ангелина» (для эксплуатации сервиса была создана некоммерческая организация). Такие гранты выделяются на различные социальные проекты. В данном случае грант был выдан на приобретение выделенного сервера и размещение его в дата-центре. Пока это оказывается более доступным способом развертывания малонагруженного интернет-сервиса, требующего GPU, чем облачная структура.
Так что, проблема решена?
До сих пор я говорил о проблеме оптического распознавания письма на Брайле. И за кадром осталась задача преобразования шрифра Брайля в обычный текст.
Дело в том, что в брайлевской азбуке всего 63 символа. Нет привычных зрячим людям подчеркиваний, курсива, верхних и нижних индексов и т.п. Буквы разных языков, цифры, математические знаки кодируются одними и теми же символами. Например, символы б, Б, b, β, 2 — это один и тот же брайлевский символ ⠃. Значение зависит от контекста. Например, перед числом ставится специальный числовой знак ⠼. Т.е. ⠼⠃⠃ — это «22». Другие правила сложнее. А полное описание использования шрифта Брайля, включая математические уравнения, дроби, использование различных языков, символов №, %, $, синтаксический и грамматический разбор предложения и т.п. занимает десятки страниц и очень напоминает Драконий Покер Р.Асприна. Кроме того, в английском языке существует система сокращений, когда длинные распространенные слова заменяются более короткими (вместо immediate пишут imm, а вместо friend — fr и т. д.).
д.).
Сейчас в сервисе эти правила реализованы в минимальном объеме, достаточно прямолинейно: в виде проверки различных условий и переключения в зависимости от них на на различные словари трансляции. Вряд ли разумно дальше развивать этот подход. И не только потому, что исходный код станет совсем нечитаемым. Многие соглашения используются неформально, предполагают контекст. Так, есть специальный символ, обозначающий переход с русского языка на английский. Но иногда он может применяться к отдельному слову, иногда ко всему следующему тексту, пока не встретится знак перехода на русский. Иногда его не ставят вовсе, если фразы вроде «O, yes, — только и смог сказать сыщик» читают интуитивно.
Существует open source библиотека Liblouis для конвертации между Брайлем и обычным плоским письмом, но в основном она применяется для преобразования плоского письма в Брайль, эта задача намного проще. Обратный перевод там реализован плохо, особенно для русского языка.
Думаю, для решения задачи перевода брайлевского текста в обычный нужно применять подходы, основанные на машинном обучении. Но тут снова мы упираемся в вопрос, где взять обучающую выборку.
Но тут снова мы упираемся в вопрос, где взять обучающую выборку.
Так что проблем еще хватает. Описанная — главная, но не единственная. Есть что улучшить и в оптическом распознавании, и в веб-интерфейсе. Проект открытый, буду рад сотрудничеству. Репозитории на GitHub:
Собственно система распознавания Angelina Braille Reader
Angelina Braille Dataset
Веб-интерфейс
Литература
1. Ovodov I. G. Optical Braille Recognition Using Object Detection Neural Network //Proceedings of the IEEE/CVF International Conference on Computer Vision. – 2021. – С. 1741-1748.
2. Ovodov I. G. Semantic-based annotation enhancement algorithm for semi-supervised machine learning efficiency improvement applied to optical Braille recognition //2021 IEEE Conference of Russian Young Researchers in Electrical and Electronic Engineering (ElConRus). – IEEE, 2021. – С. 2190-2194.
3. A review on software algorithms for optical recognition of embossed braille characters / V. Udayashankara [и др.] // International Journal of computer applications. — 2013. — Т. 81, № 3. — С. 25—35.
Udayashankara [и др.] // International Journal of computer applications. — 2013. — Т. 81, № 3. — С. 25—35.
4. Isayed, S. A review of optical Braille recognition / S. Isayed, R. Tahboub //2015 2nd World Symposium on Web Applications and Networking (WSWAN). — IEEE. 2015. — С. 1—6.
5. Joseph Redmon, Santosh Divvala, Ross Girshick, and Ali Farhadi. You only look once: Unified, real-time object detection. In Proceedings of the IEEE conference on computer vision and pattern recognition, pages 779–788, 2016
6. Wei Liu, Dragomir Anguelov, Dumitru Erhan, Christian Szegedy, Scott Reed, Cheng-Yang Fu, and Alexander C Berg. Ssd: Single shot multibox detector. In European conference on computer vision, pages 21–37. Springer, 2016
7. Tsung-Yi Lin, Priya Goyal, Ross Girshick, Kaiming He, and Piotr Dollar. Focal loss for dense object detection. In ´ Proceedings of the IEEE international conference on computer vision, pages 2980–2988, 2017
8. Settles B. Active learning literature survey. University of Wisconsin //Computer Science Department. – 2010.
University of Wisconsin //Computer Science Department. – 2010.
9. Lee D. H. et al. Pseudo-label: The simple and efficient semi-supervised learning method for deep neural networks //Workshop on challenges in representation learning, ICML. – 2013. – Т. 3. – №. 2. – С. 896.
FontDetect
В поисковике FontDetect всё разбито по Шагам — всего четыре:
ШАГ 1: Загрузка изображения, выделение области с текстом.
ШАГ 2: Разбиение на отдельные символы (автоматически при переходе к этому Шагу)
и присвоение каждому символу соответствующих букв/цифр.
ШАГ 3: Указание папок со шрифтами, среди которых будет производится поиск.
Если нет необходимости добавлять/удалять папки, то этот Шаг можно пропускать.
ШАГ 4: Непосредственно поиск. Кнопка «Начать поиск» и список результатов.
Содержание
Горячие клавиши (Шаг 1)
Инверсия изображения (негатив, белый на чёрном)
Назначение символов
Папки, путь к файлам шрифтов
Поиск, результаты поиска
Разделение соединённых символов (стирательная резинка)
Удаление лишних символов
Исправление наклона
Объединение фрагментов символа
Поворот и зеркальное отражение символа
Перевод интерфейса на другие языки
В порядке расположения кнопок тулбара:
Ctrl+Backspace — Очистка изображения
Ctrl+O — Открыть файл
Ctrl+V — Вставить из Буфера обмена
Ctrl+I — Инверсия
Ctrl+G — Чёрно-белый
Ctrl+Q — Уменьшить в 2 раза
Ctrl+Z — Отмена
Ctrl+R — Корректировка наклона
Ctrl+E — Стирательная резинка
Ctrl+P — Карандаш
Для примера поработаем вот с этим изображением (возьмём из запроса пользователей со страницы fontmassive.
В браузере жмём правой кнопкой мыши на изображении и выбираем «Копировать картинку».
В FD нажимаем кнопку в тулбаре, чтобы вставить.
Текст пока не подходит для поиска — выравниваем его с помощью LinearText.
Затем инвертируем:
Выделяем область с текстом и настраиваем Контраст, чтобы получить максимально гладкие символы:
На изображении выше Контрастом удалось также добиться разделения символов «LA» (при Контрасте более 90 они слипались).
О разделении символов см. ниже.
Здесь необходимо каждому фрагменту в нижней части окна
Т.к. в этом примере уже каждая буква является отдельным фрагментом, то для быстрого назначения символов можно воспользоваться строкой ввода (обведено синим).
Соблюдайте регистр!
Внимательно проверьте соответствия символов и переходите далее.
Все тонкости закончены, дальше идут настройки, которые при повторном запуске можно будет пропустить.
Здесь всё просто — укажите в списке пути к файлам шрифтов на вашем компьютере.
Справа имеются две опции, которые рекомендуется оставить по умолчанию.
Если вы не изменяете содержимое папок во время работы FD, то здесь ничего переключать не нужно.
Во время поиска шрифты добавляются в конец списка. Но если попадается шрифт с бо́льшим совпадением — он попадает в начало списка.
По окончанию поиска список будет отсортирован по столбцу Схожесть.
Некоторые опции доступны только по окончанию поиска.
По умолчанию в нижней части окна отображаются символы, введённые при назначении соответствий на 
Для операций с результатами поиска — выделите необходимые шрифты в списке и нажмите правую кнопку мыши.
При работе со сложными текстами можно воспользоваться инструментами Карандаш и Стирательная резинка.
Символы можно и не разделять. Но бывает так, что межсимвольный интервал на изображении был изменён, тогда это сильно помешает при поиске.
Для разделения используйте Стирательную резинку
Колесо мыши — изменение машстаба,
Shift + Колесо мыши либо [ ] — изменение размера курсора.
Теперь при переходе на Шаг 2 картина будет такая:
В данном примере появился паразитный фрагмент — выделите его щелчком в нижней части окна (выделен жёлтым) и затем нажмите Удалить в основном окне.
Обратите внимание — если вы уже назначили символы, то при удалении соответствия сохраняются (на изображении выше символы назначены неправильно — сдвинуты).
Правильно должно быть так (для примера также выделен символ d):
Сначала исправим наклон.
Выберите инструмент , проведите линию параллельно тексту, нажмите жёлтую кнопку Повернуть.
Далее, как обычно, выделите область с текстом, настройте Контраст:
Переходим на Шаг 2.
Выделите все фрагменты одного символа и нажмите Объединить:
После объединения назначим соответствия символов:
Для работы с фрагментами символов можно воспользоваться дополнительными инструментами:
Забегая перёд: удобнее всего для выбора символов использовать двойную кривую
Один символ = одна пара кривых на все его фрагменты.
При работе с этими инструментами нет необходимости выделять область с текстом на Шаге 1.
Если уже есть выделение, то удалите: выделите всё и нажмите Удалить.
Описание кнопок
— Обычное выделение рамкой с плавающими кнопками Удалить и Объединить.
— Произвольное выделение символов.
Удерживайте Shift, чтобы нарисовать несколько кривых.
Выделены будут все символы, которых коснётся нарисованная кривая.
Обратите внимание! Этот инструмент не объединяет фрагменты, а только выделяет.
— Объединение фрагментов в символ.
Работает только с теми фрагментами, которые были выделены предыдущим инструментом.
Удерживайте Shift, чтобы нарисовать несколько кривых.
— Комбинированый: Выделение + Объединение фрагментов символов.
Shift удерживать не нужно — пары всегда добавляются. См. ниже про удаление кривых.
— Разделение символов
Выделите инструментом все необходимые символы и нарисуйте белые линии в местах соединений тех символов, которые должны быть разделены.
За точки на концах линий можно корректировать их направление.
Удерживайте Shift, чтобы добавить несколько разделителей.
При необходимости воспользуйтесь масштабированием (колесо мыши).
— Удаление кривых по одной.
Щёлкайте по кривым, чтобы удалить их.
— Удаление сразу всех кривых соответствующего типа.
При включенной галке Life Update все изменения применяются на ходу в процессе рисования.
В версии 3.7 добавлен поворот и зеркальное отражение символов при их назначении:
Это поможет в случаях, когда есть необходимость найти аналоги букв, отсутствующих на изображении, но с тем же начертанием…
Например при корявой русификации шрифта либо по отсутствию латиницы на изображении можно поискать вместо мягкого знака ь латинские p или q.
Ещё примеры (в соотв. шрифтах есть такие аналоги):
W — M
И — N, Z
Л — V
П — U, C
Я — R
Г — L, 7
Чтобы поверуть — выберите один из полученных символов.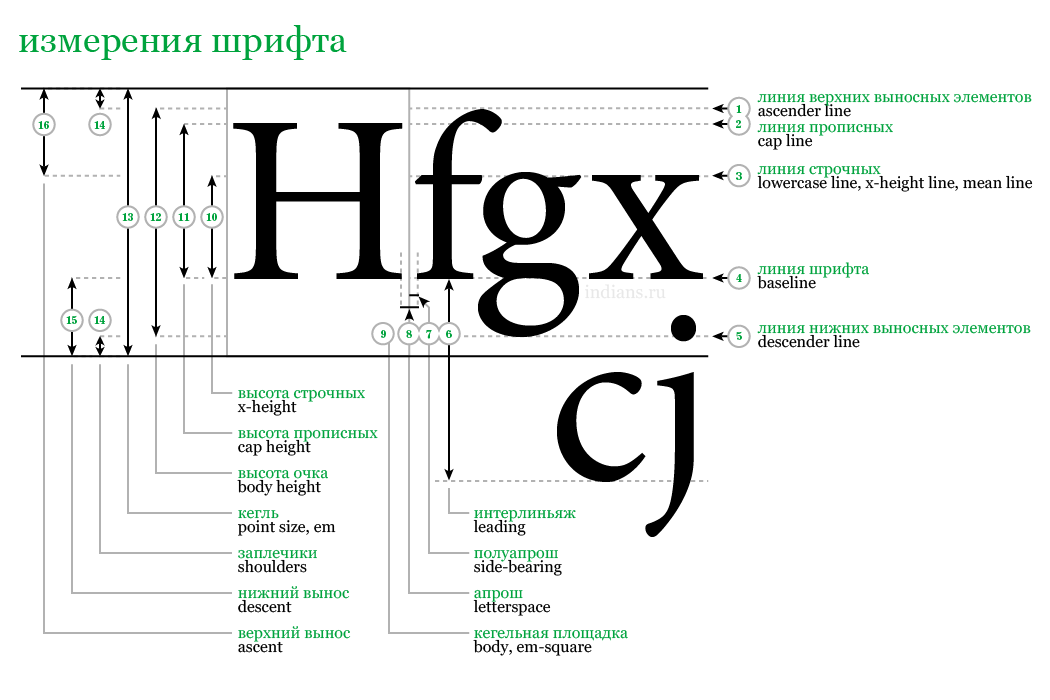
Функция также доступна на Шаге 4 (Поиск) до начала или после окончания поиска.
Также в версии 3.7 добавлена функция отмены на Шаге 2 при работе с кривыми для выделения символов.
Эта отмена действий не связана с отменой на Шаге 1. Т.е. в одном случае отменяются изменения кривых, в другом — манипуляции с изображением.
Для редактирования языковых файлов скачайте специальный редактор —
двухпанельный с параллельной прокруткой.
Скачать Lang Editor
Можно использовать любой текстовый редактор UTF-8, но он позволяет параллельно
работать со вторым уже существующим опорным файлом языка.
В архиве — редактор и актуальные языковые файлы. Для применения в FD всё это можно сразу распаковать в папку FD_Data.
Чтобы создать новый файл языка, скопируйте любой подходящий .lang файл со своим
названием (на латинице), отредактируйте в секции [info] поля «lang_id=» и «lang=«,
а также укажите своё имя и/или ник и дату изменения в формате YYYY-MM-DD.
Свой вариант перевода вы можете выслать на е-майл, указанный в шапке сайта.
© 2005-2023 Алексей Коноплёв aka KLesha28
При использовании материалов с этого сайта указывайте ссылку: http://fontmassive.com
Не является средством массовой информации.
Как мы создали механизм распознавания шрифтов | by pixolution
Опубликовано в
·
Чтение: 5 мин.
·
12 июля 2019 г. изображения, чем шрифты. Но у нас был интересный проект с поставщиком программного обеспечения из Портленда Extensis, который специализируется на управлении активами шрифтов и бренд-менеджменте.
В этом конкретном случае Extensis попросила нас обучить модель ИИ, способную классифицировать шрифты. Идея заключалась в том, чтобы создать сервис, в котором пользователи могли загрузить изображение с текстом, выбрать одно или два слова и определить тип шрифта. Процесс создания этой модели был настолько интригующим и сложным, что было бы позором не поделиться им с вами.
Процесс создания этой модели был настолько интригующим и сложным, что было бы позором не поделиться им с вами.
Мы обучили нейронную сеть, способную классифицировать используемый тип и вариант шрифта во входном изображении — из 370 изученных типов шрифтов. Модель нуждается только в одном или двух словах в качестве образца ввода и не зависит от языка, от конкретного слова, фона, цвета и размера.
Кроме того, нам пришлось реализовать конвейер предварительной обработки для нормализации пользовательского ввода перед идентификацией шрифта.
Как всегда, при обучении моделей ИИ самое главное — иметь разумные данные для обучения. Таким образом, создание достаточно большой базы данных для обучения глубокой сверточной сети с нуля было наиболее сложной задачей. В общем 90% работы — создание и улучшение обучающих данных при разработке модели ИИ. Поскольку мы могли генерировать наши обучающие данные вместо их сбора, мы смогли обучить модель с нуля.
Сначала мы собрали из Интернета списки слов на английском и немецком языках, в общей сложности 450 000 слов. Мы реализовали скрипт Python, который случайным образом выбирает 1-2 слова из этого объединенного списка слов и отображает их в файле изображения. Идея использования настоящих слов вместо случайных букв заключалась в том, чтобы отразить различные вероятности появления — а значит, важность определенных букв — в текстах реального мира. Тем не менее, мы вставили несколько случайных букв, чтобы модель не научилась буквосочетаниям.
Мы реализовали скрипт Python, который случайным образом выбирает 1-2 слова из этого объединенного списка слов и отображает их в файле изображения. Идея использования настоящих слов вместо случайных букв заключалась в том, чтобы отразить различные вероятности появления — а значит, важность определенных букв — в текстах реального мира. Тем не менее, мы вставили несколько случайных букв, чтобы модель не научилась буквосочетаниям.
1. Почему корпоративные проекты ИИ терпят неудачу?
2. Как ИИ будет способствовать следующей волне инноваций в здравоохранении?
3. Машинное обучение с использованием регрессионной модели
4. Лучшие платформы обработки и анализа данных в 2021 году, кроме Kaggle
Для каждого шрифта мы создали 3000 изображений со случайными словами. И для каждого из этих изображений мы сгенерировали 20 дополненных версий. В сумме это составляет до 60 000 обучающих образцов для каждого шрифта и около 23 миллионов изображений в целом.
Было важно, чтобы все слова отображались с одинаковой высотой пикселя, чтобы сеть по ошибке не научилась различать шрифты по размеру.
Затем мы дополнили эти визуализированные изображения различными модификациями, чтобы сделать модель более устойчивой к шуму и отвлекающим визуальным элементам, таким как цвета фона, тени, перекрытия, кадрирование и т. д. Отличной средой для увеличения изображений является imgaug. Мы использовали его для увеличения каждого образца 20 раз.
Несколько случайных выборок, используемых в качестве входных данных для обучения.Получив данные для обучения, мы перешли к обучению модели GoogLeNet. Фаза тестирования была очень приятной, так как точность валидации составила более 98%. Неплохо, правда?
Пользователи службы распознавания шрифтов загружают изображение и выбирают область из одного или двух слов. Затем это субизображение классифицируется моделью ИИ. Конечно, реальные пользователи не будут предоставлять идеальные входные данные. Они могут содержать несколько строк текста с разным шрифтом и размером изображения. Чтобы избежать потери точности, мы внедрили конвейер предварительной обработки для нормализации ввода.
Они могут содержать несколько строк текста с разным шрифтом и размером изображения. Чтобы избежать потери точности, мы внедрили конвейер предварительной обработки для нормализации ввода.
Во-первых, мы применяем ядро эрозии для создания маски связанных областей, которая приблизительно представляет строки текста. Мы определяем самую большую область и вычисляем ее ограничивающую рамку. Если мы нашли такую область, мы обрезаем входное изображение до этой ограничивающей рамки, чтобы удалить несколько строк и смещений из входного изображения и получить одну строку с текстом.
Шаги обработки для нормализации входного изображения Затем мы применяем адаптивный порог (алгоритм CLAHE) для автоматического выравнивания цветовых каналов. После увеличения резкости изображение масштабируется до фиксированной высоты с сохранением соотношения сторон. Мы обрезаем ширину до фиксированной ширины и центрируем полученное изображение в квадратном изображении (256×256 пикселей). Теперь изображение нормализовано и используется в качестве входных данных для модели классификации.
Теперь изображение нормализовано и используется в качестве входных данных для модели классификации.
Мы с гордостью можем сказать, что достигли всех целей проекта с Extensis и обязательно продолжим нашу работу в области распознавания шрифтов.
Есть несколько вещей, которые мы можем улучшить. В настоящее время система не может работать с повернутым текстом, и вход модели должен быть изменен, поэтому нам не нужны квадратные изображения. Мы многому научились и с нетерпением ждем масштабирования системы для распознавания сотен тысяч шрифтов.
Если вам также нужна индивидуальная модель ИИ, просто свяжитесь с нами. Нам любопытно, куда наше путешествие приведет нас в следующий раз.
Как повысить узнаваемость бренда с помощью выбранного шрифта
Брендинг — это первое впечатление. Эти показов имеют значение на целевой странице .
CXL рассказал о британском исследовании, в ходе которого участникам задавали вопрос об их восприятии веб-сайтов, посвященных здоровью. Когда люди, принявшие участие, оставляли отзывы о веб-сайте, 94% их комментариев касались дизайна.
Когда люди, принявшие участие, оставляли отзывы о веб-сайте, 94% их комментариев касались дизайна.
элементов дизайна, которые вы выбираете для своих целевых страниц — , включая шрифты , — влияют на восприятие и узнаваемость вашего бренда. Если вы хотите, чтобы посетители узнавали ваш бренд и доверяли ему при просмотре ваших маркетинговых кампаний, вы должны хорошо разбираться в используемых вами шрифтах.
Итак, как вы можете создать узнаваемый бренд с помощью своих шрифтов? Это руководство расскажет вам о различных категориях шрифтов и о том, как их использовать, чтобы выделить ваш бренд .
Категории шрифтов и их значения
Шрифты делятся на четыре категории шрифтов — с засечками, без засечек, с засечками и шрифт . Каждая группа вызывает разные чувства, отражающие ваш бренд и его тон. Давайте посмотрим, что они из себя представляют.
Serif
Изображение предоставлено OpenClassrooms. Эти шрифты создают классический вид, поэтому вы увидите, что они часто используются в давно зарекомендовавших себя и формальных брендах.
Эти шрифты создают классический вид, поэтому вы увидите, что они часто используются в давно зарекомендовавших себя и формальных брендах.Модный журнал Vogue существует уже более 100 лет. Вот как издание использует шрифт с засечками в своем логотипе:
Изображение предоставлено Vogue/Digital TrendsБез засечек
Изображение предоставлено OpenClassroomsШрифты без засечек не имеют засечек в конце каждого штриха, что придает шрифту более современный вид. Исследование более миллиона веб-страниц показало, что 85,5% используют шрифты без засечек как в заголовке, так и в тексте абзаца. Вы увидите шрифты без засечек, используемые брендами, стремящимися к современности, такими как iTunes:
Изображение предоставлено iTunes/Digital TrendsSlab
Изображение предоставлено OpenClassrooms бывают с засечками или без них. Такие бренды, как Honda, используют их, чтобы произвести эффектное впечатление: Изображение предоставлено HondaScript
Изображение предоставлено OpenClassrooms Шрифты Script используют кривые буквы с соединенными штрихами, чтобы напоминать рукописные курсивные буквы.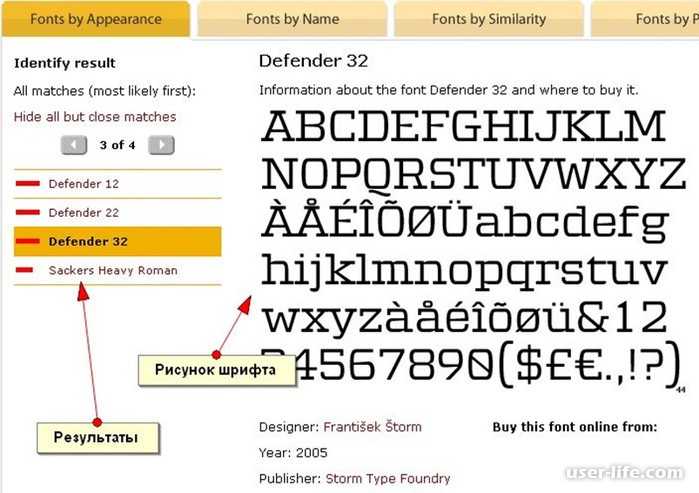 Эти шрифты создают элегантный вид. Некоторые бренды также используют их для демонстрации женственности, например Barbie:
Эти шрифты создают элегантный вид. Некоторые бренды также используют их для демонстрации женственности, например Barbie:
Как повысить узнаваемость бренда с помощью шрифтов
Теперь, когда вы понимаете четыре категории шрифтов, как вы можете использовать эти знания для сделать ваш бренд более узнаваемым? Давайте рассмотрим три совета.
Подберите шрифт к своему бренду
Шрифты, которые вы используете в своем маркетинговом контенте, включая материалы без логотипа, такие как целевые страницы, должны соответствовать тону вашего бренда .
Представьте, что вы покупаете куклу Pretty Pink Princess и нажимаете на целевую страницу, которую найдете в результатах Google. По какой-то причине шрифт в заголовке написан готическим шрифтом — таким вы могли видеть средневековый камерный метал-альбом. Вы задаетесь вопросом, есть ли у вас правильный сайт, не так ли?
Хорошо подумайте о том, как ваши шрифты должны выражать тему и ценности вашего бренда . Duolingo зашли так далеко в этом процессе, что создали шрифт на основе своего логотипа и талисмана. Так что не бойтесь посвятить время выбору шрифтов, которые подходят вашему бренду.
Duolingo зашли так далеко в этом процессе, что создали шрифт на основе своего логотипа и талисмана. Так что не бойтесь посвятить время выбору шрифтов, которые подходят вашему бренду.
Давайте посмотрим, как шрифты могут сочетаться с тоном бренда на этой целевой странице. Заявка на участие в конкурсе:
Изображение предоставлено bearbrick на сайте 99designsнастроение для предстоящего спортивно-боевого зала. Этот выбор шрифта показывает, что вымышленный бренд DarkWolf серьезно относится к высокоинтенсивным соревновательным видам спорта, в которых он специализируется.
Сохраняйте единый шрифт
Покупатели не узнают ваш бренд, если вы постоянно меняете его внешний вид. После того, как вы выберете шрифты, которые подходят вашему бренду, используйте их в своих маркетинговых материалах . Сохраняйте одинаковый шрифт для всех текстов, платформ и продуктов, чтобы повысить вероятность того, что ваша аудитория узнает ваш бренд.
В конце концов, последовательность — это третий принцип дизайна, ориентированного на конверсию. Если вы не знаете, с чего начать, попробуйте использовать свой основной веб-сайт в качестве руководства по стилю . Установите шрифты, которые вы хотите использовать там, а затем используйте те же самые шрифты везде, где вы занимаетесь маркетингом.
Если вы не знаете, с чего начать, попробуйте использовать свой основной веб-сайт в качестве руководства по стилю . Установите шрифты, которые вы хотите использовать там, а затем используйте те же самые шрифты везде, где вы занимаетесь маркетингом.
Хотя может показаться, что шрифт не так важен для разных платформ, как другие элементы дизайна, он действительно имеет значение. Как мы уже говорили в нашем руководстве по дизайну, ориентированному на конверсию, наш мозг обрабатывает визуальную информацию в 60 000 раз быстрее, чем текст. Итак, мы обрабатываем текст еще до того, как узнаем, что он говорит 9.0058 .
Посмотрите, как отличить эти две целевые страницы от одних и тех же людей:
Изображение предоставлено Compressed.fm Изображение предоставлено Compressed.fm ____» вверху, который связывает их вместе. Они используют одинаковую последовательность шрифтов, чтобы оба мероприятия соответствовали бренду.Используйте простые комбинации шрифтов
После того, как вы соберете шрифты, соответствующие вашему бренду, у вас может получиться длинный список. Сократите его до нескольких шрифтов, чтобы использовать для заголовков и основного текста, и сделайте его еще короче для дизайна вашей целевой страницы.
Сократите его до нескольких шрифтов, чтобы использовать для заголовков и основного текста, и сделайте его еще короче для дизайна вашей целевой страницы.
Мы рекомендуем придерживаться двух шрифтов для целевых страниц — шрифта заголовка и основного шрифта.
Почему? Мы понимаем, что большинство людей, читающих этот блог, — скупые маркетологи, у которых много дел. Если вы не зарабатываете на жизнь дизайном веб-страниц, сложно разработать и отслеживать более двух шрифтов на целевой странице.
Дизайнеры часто смешивают шрифты из разных категорий или используют жирный шрифт в качестве заголовка для обычного шрифта основного текста. Экспериментируйте с парами шрифтов , чтобы найти комбинацию, подходящую для вашего бренда. Такие инструменты, как Fontpair, помогут вам создать правильный микс.
Вы можете увидеть комбинацию с засечками и без засечек в действии на целевой странице Sprout:
Изображение предоставлено Sprout Sprout использует шрифт с засечками в заголовках и шрифт без засечек везде.
