Как найти нужный шрифт, не зная его названия? / Хабр
Я уверен, что у любого дизайнера был такой момент, когда он видел где-то какой-то шрифт, который так мог бы пригодится в проекте, но… что за шрифт?.. Ответ на этот вопрос затаился в глубине Вашего сознания, либо в глубине Вашего «незнания» (что разумеется простительно).
В этой статье мы рассмотрим несколько ресурсов, которые могут помочь вам в идентификации понравившегося шрифта.
Конечно, нельзя рассчитывать, что эти источники дадут вам 100 процентную уверенность в том что вы найдете нужный шрифт, но что помогут, так это точно.
What The Font?!
Graphic Design Blog полезный ресурс, но может помочь лишь в том случае, если вы знаете имя дизайнера или студию, создавшего шрифт. Список студий и дизайнеров весьма обширный и поиск шрифта в разы упрощается. Но, что делать, если вы видите шрифт в первый раз?
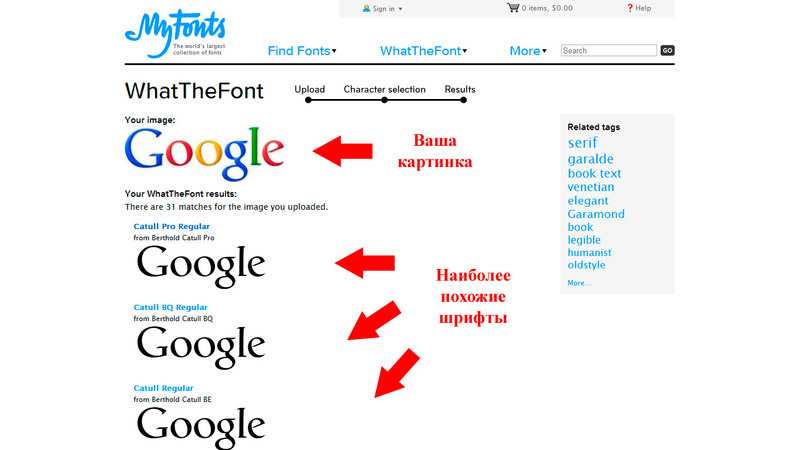
What The Font — известный ресурс, который поможет найти шрифт по загруженной картинке.
Могу сказать, что получаются довольно-таки неожиданные результаты.
Шаг 1: Загрузите картинку. Если картинка с фоновым шумом или с недостаточным контрастом, будь добры потратить несколько минут в Photoshop, что бы довести картинку до ума.
Шаг 2: После загрузки картинки, проверьте, что What The Font правильно определил глифы, и лишь после этого жмите «поиск».
Вкратце, ГЛИФ — это графический образ знака. Один знак может соответствовать нескольким глифам; строчная «а», капительная «а» и альтернативный вариант строчной «а» с росчерком являются одним и тем же знаком, но в то же время это три разных глифа (графемы).
С другой стороны, один глиф также может соответствовать комбинации нескольких знаков, например лигатура «ffi», являясь единой графемой, соответствует последовательности трех знаков: f, f и i. Т.о. для программы проверки орфографии слово suffix будет состоять из 6 знаков, а графический процессор выдаст на экран 4 глифа.
Сначала я загрузил эту картинку:
В результатах поиска, What The Font мне выдал 24 варианта. К чести What The Font могу сказать, что некоторые шрифты из списка были похожи на Adobe Garamond Pro.
К чести What The Font могу сказать, что некоторые шрифты из списка были похожи на Adobe Garamond Pro.
Увеличив размер картинки (максимум 360 на 275 пикселей), список резко сократился:
Minion Regular Small Caps & Oldstyle Figures
Minion Regular
Adobe Garamond
Где, как вы видите, нашелся и правильный шрифт (хотя не совсем точно, между Adobe Garamond и Adobe Garamond Pro, все-таки разница, хоть и небольшая, но есть), если бы я увеличил размер картинки еще больше, то идентификация прошла бы успешно, но мне уже было лень проверять.
Если же What The Font не смог определить шрифт, то Вам в помощь его форум, местожительство шрифтовых гурманов, где вам обязательно помогут с поиском.
Typophile
Отличное сообщество, огромное количество ресурсов, блогов, новостей связных с типографской культурой. Есть даже typography Wiki.
Да, у Typophile нет автоматического идентификатора шрифтов, но зато имеющееся сообщество поможет Вам гораздо лучше, чем какая-то программа.
FontShop
Подход Fontshop в определении шрифта оригинален: сначала вы определяете общую форму шрифта, затем по нарастающей, вы отвечаете на все более сложные вопросы.
Это сервис хорош, не только как инструмент, который помогает идентифицировать шрифт, но и как отличное подспорье для поиска подходящих для вашего проекта шрифта.
Identifont
Это сайт, дает новый поход к поиску с относительным результатом. Identifont задает вопросы, по типу «Имеют ли буквы серифы?» или «Какой формы серифы?»
После этого, Identifont постарается дать ответ на основе заданных вопросов.
Да, конечно, определить неизвестный шрифт нелегко. Никто наверняка не знает, сколько шрифтов было создано за всю историю типографики. Как бы то ни было, он точно есть среди сотни тысяч шрифтов.
Процесс поиска нужного шрифта нельзя назвать бесполезным. Во время поиска, Вы найдете массу интересного не только по какому-то определенному шрифту, но в целом по его собратьям.
Хотя, это уже философия, так как это правило можно применить к любому делу.
Вольный и упрощенный перевод статьи — Identify That Font.
Использование функции «Сканер текста» для взаимодействия с контентом фото или видео на iPhone
При просмотре фото или приостановке видео в приложении «Фото» функция «Сканер текста» распознает текст и другую информацию на изображении, позволяя разными способами с ней взаимодействовать. Можно выбрать текст, чтобы скопировать, отправить или перевести его, или использовать быстрые действия, чтобы позвонить по телефону, открыть веб-сайт или конвертировать валюту.
Функция «Сканер текста» доступна на поддерживаемых моделях и может использоваться в приложениях Safari, Камера, Просмотр и т. д.
Включение функции «Сканер текста»
Перед началом использования функции «Сканер текста» убедитесь, что она включена для всех поддерживаемых языков.
Откройте «Настройки» > «Основные» > «Язык и регион».
Включите «Сканер текста» (зеленый цвет означает, что параметр включен).
Копирование, перевод и поиск текста на фото и в видео
Откройте фото или поставьте видео, содержащее текст, на паузу.
Коснитесь , затем коснитесь выбранного текста и удерживайте его.
Используйте точки захвата для выбора нужного текста, затем выполните одно из приведенных ниже действий.
Скопировать текст. Копирование текста для вставки в другое приложение, такое как Заметки или Сообщения.
Выбрать все. Выбор всего текста в кадре.
Найти. Отображение персонализированных веб-предложений.
Перевести. Перевод текста.
Поиск в интернете. Поиск выделенного текста в интернете.
Поделиться. Отправка текста через AirDrop, Сообщения, Почту или другими доступными способами.

В зависимости от того, что изображено на фотографии, можно коснуться быстрого действия в нижней части экрана, чтобы выполнить такие действия, как совершение телефонного вызова, открытие веб-сайта, создание электронного письма, конвертирование валют и многого другого.
Коснитесь для возврата к фото или видео.
Работа с фотографией или видео с помощью быстрых действий
В зависимости от содержания фотографии или видео, можно коснуться быстрого действия в нижней части экрана, чтобы выполнить такие действия, как совершение телефонного вызова, построение маршрута, перевод на другие языки, конвертирование валют и многое другое.
В приложении «Фото» откройте фото или поставьте видео, содержащее текст, на паузу.
Коснитесь .
Коснитесь быстрого действия в нижней части экрана.
Коснитесь для возврата к фото или видео.
Функция «Сканер текста» доступна не во всех регионах и не на всех языках. См. Доступность функций iOS и iPadOS.
См. Доступность функций iOS и iPadOS.
См. такжеИспользование функции «Сканер текста» с помощью камеры iPhoneИспользование функции «Что на картинке?» для распознавания объектов на фото на iPhone
Распознавание шрифтов с помощью глубокого обучения | Джехад Мохамед | MLearning.ai
Сканируется каллиграфия А.Это основано на DeepFont Paper, методе, созданном Adobe.Inc для обнаружения шрифта на изображениях с использованием глубокого обучения. Они опубликовали свою работу в виде документа для общественности, и реализованный код является производным от того же. В этом блоге обсуждаются необходимые шаги, а также дается обзор кода.
Ключевые точки DeepFont:
- Он обучен на наборе данных AdobeVFR, который содержит 2383 Шрифт Категории!
- Его CNN адаптирована к предметной области (Нажмите здесь, чтобы узнать больше)
- Его обучение основано на сжатии модели
Прежде чем мы начнем — давайте начнем с того, какие библиотеки нам нужны.
Из Matplotlib.pyplot Import Imshow
Импорт Matplotlib.cm AS CM
Импорт MATPLOTLIB.PYLAB AS
от KERS.POLAB AS
от KERS.PROCESS.0006 ImageDataGenerator
import numpy as np
import PIL
from PIL import ImageFilter
import cv2
import itertools
import random
import keras
import imutils
из imutils импорт путей
импорт os
из keras импорт оптимизаторы
from keras.preprocessing.image import img_to_array
from sklearn.model_selection import train_test_split
from keras.utils import to_categorical
from keras import callbacks
from keras.models импорт последовательный
из keras.layers.normalization импорт BatchNormalization
из keras.layers 9Импорт Lense, Lense, выбросы, выброшенные, выбросы
из Keras.layers Import Conv2d, MaxPooling2d, Upsampling2d, Conv2dtranspose
от Keras ImportWill Will Will Will Will
.
Will Will Will Will Will in
.
Will Will Will Will Will Will in
. % % % % % %. манипулировать изображениями, давайте возьмем PIL (библиотеку изображений Python) и создадим функцию для чтения изображения из каталога и изменения размера по мере необходимости.
 деф pil_image(img_path):
деф pil_image(img_path):
пил_им = пил . Изображение . открыть (img_path) . convert('L')
pil_im = pil_im . resize((105,105))
#imshow(np.asarray(pil_im))
return pil_imТеперь мы разобьем всю работу на 4 шага или фазы.
Шаг 1: Набор данных
Поскольку ссылка на набор данных AdobeVFR имеет огромный размер и содержит множество категорий шрифтов, простой способ обойти это — создать собственный набор данных на основе необходимых исправлений шрифтов с помощью TextRecognitionDataGenerator github.
Когда у вас есть набор образцов, вы готовы к работе!
Шаг 2: Предварительная обработка данных
Шрифты не похожи на объекты, и для классификации их функций требуется огромная пространственная информация. Чтобы определить очень незначительное изменение характеристик, DeepFont использует определенные методы предварительной обработки, а именно:
- Шум
- Размытие
- Перспективное вращение
- Затенение (градиентное освещение)
- Переменный интервал между символами
- Переменное соотношение сторон
Исходя из этого — у нас есть функции для каждого из шагов аугментации:
def Noise_image(pil_im):ASARRAY (PIL_IM)
# Добавление шума к изображению
Среднее = 0,0 # Некоторая постоянная
Std = 5 # Некоторая постоянная (стандартное отклонение)
NOISY_IMG = 66 IMG_ARRAY + NP .случайное . нормальное (среднее, станд., img_array . форма)
noisy_img_clipped = np . клип(noisy_img, 0, 255)
шум_img = PIL . Изображение . fromarray(np . uint8(noisy_img_clipped))
шум_изображения = шум_изображения . resize((105,105))
return Noise_img
def blur_image(pil_im):
#Добавление размытия к изображению
blur_img = pil_im3 .
filter(ImageFilter . GaussianBlur(радиус = 3))
blur_img = blur_img . resize((105,105))
return blur_img
def affine_rotation(img):
строк, столбцов = img . shapepoint1 = np .
float32([[10, 10], [30, 10], [10, 30]])
point2 = np . float32([[20, 15], [40, 10], [20, 40]])A = cv2 . getAffineTransform(point1, point2)
вывод = cv2 . warpAffine(img, A, (столбцы, строки))
affine_img = PIL . Изображение . fromarray (np . uint8 (выход))
affine_img = affine_img . изменить размер ((105,105))
вернуть affine_img
def градиент_заполнить (изображение):
лапласиан = cv2 . Лапласиан (изображение, cv2 . CV_64F)
лапласиан = cv2 . изменение размера (лапласиан, (105, 105))
return laplacian
Теперь, когда они готовы, мы можем подготовить набор данных.
data_path = "font_patch/" #Ссылка на все созданные образцы случайный . семян(42)
случайных . shuffle(imagePaths)#Это были 5 шрифтов, взятых за образец def conv_label(label):
IF Метка == 'LATO':
Возврат 0
ELIF Метка == 'Raleway':
return 1
ELIF Label == 'Roboto'
7777777777777777777777777777777777777777777777777777777777777777777777777777777777777777777777777777777777777777777 return 2
ELIF Метка == 'Sansation':
return 3
ELIF Метка == 'Проходная дорожка':
return 4augument = ["Blur" ","аффинный","градиент"]
a = itertools .комбинаций (дополнение, 4)
для i в list(a):
print(list(i))
Теперь, основываясь на a, мы перебираем изображения, используя только что сгенерированные комбинации, добавляя вывод данных и меток каждый раз.
counter = 0
для imagePath в imagePaths:
label = imagePath . split(os . path . sep)[ - 2]
Метка = conv_label (метка)
PIL_IMG = PIL_IMAGE (ImagePath)
#IMSHOW (PIL_IMG)#Добавление оригинального изображения
ORG_IMG = IMG_TO_ARRAP )
данные . append(org_img)
ярлыков . добавление(метка)дополнение = ["шум","размытие","аффинный","градиент"]
для l в диапазоне (0,len(дополнение)):a = itertools .
Комбинации (AUGUMENT, L + 1)
для I в списке (A):
Комбинации = Список (I)
Печать (Len (комбинации))
Temp_img = PIL_IMG
)) Для J в Комбинациях:, если J == 'шума':
# Добавление шумового изображения
Temp_img = rower_image (temp_img)ELIF J .0003 == 'blur':
# Adding Blur image
temp_img = blur_image(temp_img)
#imshow(blur_img)elif j == 'affine':
open_cv_affine = нп . Array (PIL_IMG)
# Добавление аффинного ротационного изображения
Temp_img = Affine_Rotation (OPEN_CV_AFFINE)ELIF J == 'GRADIENT':
OPEN_CV_GRADIVE = 'gradient':
Open_CV_GRADIVE = = = .0003 . array(pil_img)
# Добавление градиентного изображения добавить (temp_img)
меток . append(label)
Наш следующий шаг очень прост — мы разделяем данные, чтобы мы могли использовать 75% для обучения и оставшиеся 25% для тестирования. Затем мы конвертируем метки из целых чисел в векторы.
данные = нп . asarray(data, dtype = "float") / 255.0
labels = np . array(метки)
print("Успех")(trainX, testX, trainY, testY) = train_test_split(данные,
меток, test_size = 0,25, random_state = 42)trainY3 =
3 trainY, num_classes = 5)
testY = to_categorical(testY, num_classes = 5)авг = ImageDataGenerator(rotation_range = 30, width_shift_range = 0.1, height_shift_range = 0,1, shear_range = 0,2, Zoom_range = 0,2, Horizontal_flip = True )
. Классификация сети CNN, они следовали новой схеме, такой как две подсети,
- Низкоуровневая подсеть : извлечены из составного набора синтетических и реальных данных.
- Подсеть высокого уровня : Изучает глубокий классификатор на низкоуровневых функциях. Для получения более подробной информации и пояснений прочитайте их документ
Мы создаем модель, как указано в документе, и компилируем ее.
K.set_image_data_format('channels_last') def create_model():
модель = Sequential() # Cu Layers
модель . добавить(Conv2D(64, размер ядра = (48, 48), активация = 'relu', input_shape = (105,105,1)))
модель . добавить(Пакетная нормализация())
добавить(Пакетная нормализация())
модель . добавить(MaxPooling2D(pool_size = (2, 2)))
модель . добавить(Conv2D(128, размер ядра = (24, 24), активация = 'relu'))
модель . добавить(Пакетная нормализация())
модель . добавить(MaxPooling2D(pool_size = (2, 2)))
модель . add(Conv2DTranspose(128, (24,24), шаги = (2,2), активация = 'relu', заполнение = 'такой же', kernel_initializer = 'однородный'))
модель . добавить(UpSampling2D(размер = (2, 2)))
модель . add(Conv2DTranspose(64, (12,12), шаги = (2,2), активация = 'relu', заполнение = 'то же самое', kernel_initializer = 'униформа'))
модель . add(UpSampling2D(size = (2, 2)))
add(UpSampling2D(size = (2, 2)))
#Cs Layers
модель . добавить(Conv2D(256, размер ядра = (12, 12), активация = 'relu'))
модель . добавить(Conv2D(256, размер ядра = (12, 12), активация = 'relu'))
модель . добавить(Conv2D(256, размер ядра = (12, 12), активация = 'relu'))
модель . добавить(свести())
модель . add(Dense(4096, активация = 'relu'))
модель . добавить(Выпадение(0.5))
модель . добавить(Dense(4096,активация = 'relu'))
модель . добавить(Выпадение(0.5))
модель . add(Dense(2383,активация = 'relu'))
модель .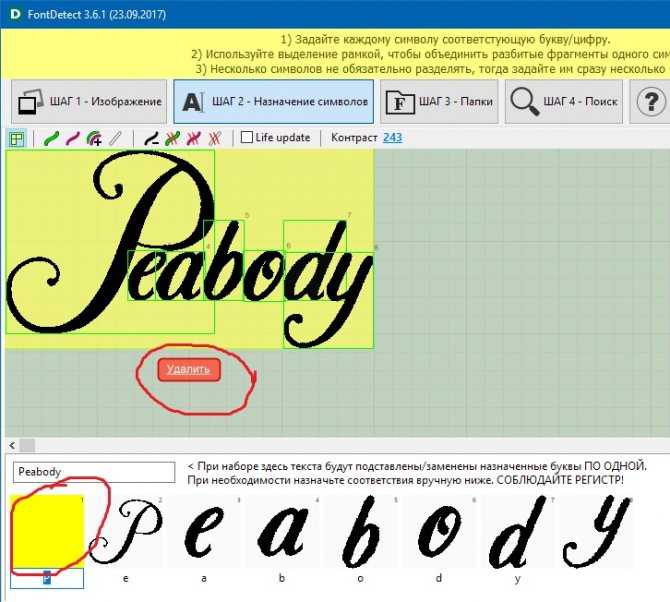 add(Dense(5, активация = 'softmax'))
add(Dense(5, активация = 'softmax'))
return model
batch_size = 128
epochs = 50
model= create_model()
sgd = tensorflow.keras.optimizers.0.SGD0(l. , распад = 1e-6, импульс = 0,9, нестеров = True)
model.compile (потеря = 'mean_squared_error', оптимизатор = sgd, metrics = ['точность']) Early_stopping = обратных вызовов . Ранний стоп (Monitor = 'val_loss', min_delta = 0, терпение = 10, verbose = 0, режим = 'мин')
filePath = "Top_model.h5"
. контрольная точка = обратных вызовов . ModelCheckpoint(путь к файлу, монитор = 'val_loss', подробный = 1, save_best_only = True , режим = 'мин')
callbacks_list = pping]0007
Теперь мы подогнали модель и проверили на потери и точность.
модель . FIT (Trainx, Trainy, Shuffle = True ,
BATCH_SIZE = BATCH_SIZE,
Эпохи = EPOCHS,
Verbose = 1,
Validation_DATA = (testx, testy),
Validation_DATA = (testx, testy), callckback = (testx), testy), callback. )счет = модель . оценить(testX, testY, verbose = 0)
print('Потеря теста:', оценка[0])
print('Точность теста:', оценка[1])
Потеря теста: 0,1341324895620346
Точность теста: 0,6410256624221802
Шаг 4: рамка
в качестве прототипа, мы используем KERAS.
из keras.models импорт load_model
модель = load_model('top_model.h5')
оценка = модель .оценить(testX, testY, verbose = 0)
print('Потеря теста:', оценка[0])
Печать («Точность теста:», оценка [1])
Потеря теста: 0,12708203494548798
Точность теста: 0,5833333313465184
. результаты!img_path="sample/sample.jpg"
pil_im =PIL.Image.open(img_path).convert('L')
pil_im=blur_image(pil_im)
org_img = img_to_array(pil_im) def rev_conv_label(метка) :
если метка == 0:
return 'Lato'
ELIF Метка == 1:
Возврат 'Raleway'
ELIF Лейбл == 2:
return 9000 '
7 == 2:
'
7 == 2:
9000 'Roboto' == 2:
' ELIF Метка == 3:
Возврат 'Sansation'
ELIF Метка == 4:
Данные 'Walwway'data = []
Data .добавить (org_img)
данные = np . asarray(data, dtype = "float") / 255.0y = model.predict(data)
y = np.round(y).astype(int)label = rev_conv_label(y[0,0 ]))
рис, ax = plt . участков (1)
акселерометров . imshow(pil_im, интерполяция = 'ближайший', cmap = см . серый)
ах . text(5, 5, label , bbox = {'facecolor': 'white', 'pad': 10})
plt . show()
Вот и все, ребята! Распознавание шрифтов с помощью DeepFont.
Предложения по отправке на Mlearning.ai
Как стать писателем на Mlearning.ai
medium.com
Распознавание шрифтов в изображениях с помощью новой функции извлечения — видеоруководство по InDesign
Из курса: InDesign Tips for Design Geeks
Видео заблокировано.
Разблокируйте этот курс с бесплатной пробной версией
Присоединяйтесь сегодня, чтобы получить доступ к более чем 21 200 курсам, которые преподают отраслевые эксперты.
Распознавание шрифтов на изображениях с помощью новой функции извлечения
“
- [Энн-Мари] Привет, ребята. Это Энн-Мари из «Советов по InDesign для дизайнеров». Сегодня я хочу показать вам эту действительно удобную новую функцию, появившуюся в InDesign 2022, которая позволяет извлекать информацию из размещенного или связанного изображения.