12 скрытых функций WhatsApp | Rusbase
WhatsApp — один из самых популярных мессенджеров в мире. В нем регулярно появляется все больше инструментов и возможностей, однако не все из них хорошо известны. Представляем список из 12 функций WhatsApp, о которых вы, возможно, не знали.
Дарья Сидорова
Форматируйте текст
Сообщения в WhatsApp можно разнообразить, выделив шрифт жирным, курсивом или зачеркиванием. Чтобы это сделать, просто поставьте пару символов до и после текста:
- * жирный *;
- _курсив_ ;
- ~ зачеркивание ~ .
Отправляйте исчезающие сообщения
Эта функция удаляет сообщения через некоторое время, помогая защитить ценную информацию. Вот как ее включить.
- Коснитесь имени контакта в чате.
- Выберите опцию «Сообщения».
- Активируйте функцию «Временные сообщения».
Добавляйте сообщения в «Избранные»
Чтобы важное сообщение не затерялось, можно добавить его в «Избранные». Для этого удерживайте на нем палец, а затем нажмите на звездочку.
Узнайте время прочтения сообщения
Чтобы узнать, когда получатель прочитал сообщение, нажмите на него и переведите палец влево. Эти данные также можно найти в меню, обозначенном тремя точками, в разделе «Данные». В обоих случаях вы увидите, в какое время было отправлено, получено и прочитано сообщение.
Отключите автозагрузку медиа
Фото и видео, присланные в WhatsApp, часто засоряют память телефона. К счастью, автоматическую загрузку можно отключить. Перейдите в «Настройки» и выберите «Чаты». В этом разделе отключите опцию «Видимость медиа».
Скройте время последнего посещения
WhatsApp предлагает возможность скрыть информацию о том, когда вы в последний раз заходили в приложение. Чтобы это сделать, откройте «Настройки» и выберите «Аккаунт». Затем перейдите в «Конфиденциальность» и отключите «Был(-а)». Вы также можете сохранить эту опцию включенной для нескольких контактов. Из соображений безопасности лучше показывать время последнего посещения хотя бы одному пользователю.
Помечайте переписку как «непрочитанное»
Эта функция напоминает вам о том, что нужно ответить собеседнику. Просто нажмите на чат и удерживайте пару секунд, а затем выберите опцию «Пометить как непрочитанное».
Узнайте любимый контакт
Этот инструмент позволяет узнать, с какими контактами вы взаимодействуете чаще всего, а также управлять внутренним хранилищем. Для этого нужно перейти в «Настройки», выбрать «Данные и хранилище» и «Управление хранилищем».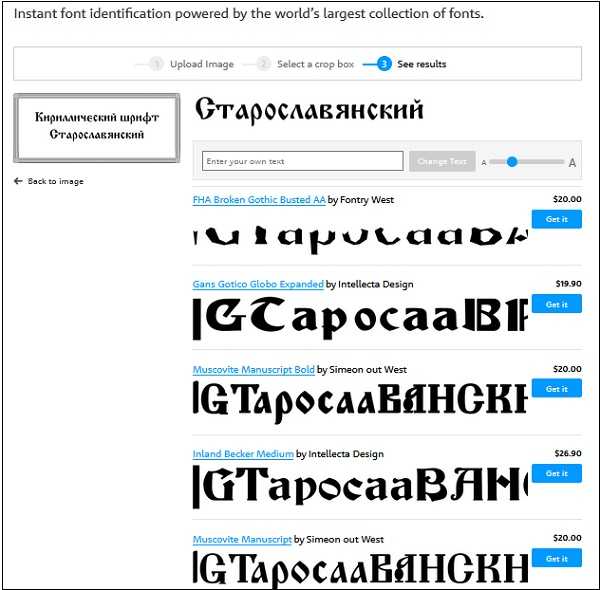
Прослушивайте аудио перед отправкой
Этот трюк дает возможность прослушать голосовое сообщение, прежде чем его отправить. Начните записывать аудио, а когда захотите его завершить, выйдите из приложения, удерживая при этом кнопку записи. Когда вы вернетесь к переписке, то обнаружите, что сообщение сохранилось. Теперь его можно прослушать, отправить или удалить.
Персонализируйте уведомления
Это опция позволяет настроить персонализированные рингтоны для отдельных контактов. Просто зайдите в чат с нужным человеком и нажмите на его имя. Откройте раздел «Индивидуальные уведомления» и выберите желаемый рингтон.
Настраивайте индивидуальные фоны
Эта функция позволяет установить фон для каждого чата. Это могут быть как изображения, так и темы для темного и светлого режима. Для этого просто перейдите в «Настройки», а затем выберите «Чаты». В разделе «Обои» вы найдете все доступные изображения.
Присоединяйтесь к бета-тестированию
Бета-тестеры одними из первых получают возможность попробовать новые функции приложения. Чтобы к ним присоединиться, перейдите по ссылке и следуйте указанным инструкциям.
Источник: Entrepreneur.com
Фото на обложке: Temitiman / Shutterstock
новости, письмо, учёные, археология, исследование, наука и технологии
Новости России / Наука и Технологии
ТУТ Новости
11.01.2022 15:32
Специалисты из Института истории человечества им. Макса Планка в Германии заявили о том, что смогли узнать подробности эволюции письменности.
До этого было известно, что впервые письменность появилась более 5 тысяч лет назад на Ближнем Востоке.
В журнале Current Anthropology рассказали о том, что письмо становилось более «сжатым» достаточно быстро для эффективного чтения и письма.
Стоит заметить, что изучение первых этапов развития письменности происходило долгое время. Стоит заметить, что первые следы письма были потеряны или фрагментированы.
Стоит заметить, что первые следы письма были потеряны или фрагментированы.
Чтобы прийти к определенным выводам о первых этапах эволюции письма, специалисты провели исследование редкой африканской системы письма, которая принадлежало народу вай.
Иностранных специалистов она привлекала еще в начале XIX века. Исследователи тщательно проанализировали рукописи на данной языке из архивов, расположенных в Либерии, США и Европе.
После проведенного анализа букв данной письменности им удалось проследить эволюцию письма с 1834 года. Благодаря вычислительным инструментам они смогли визуально измерить сложность букв. Результаты их исследования показали, что письменность с годами действительно начала упрощаться.
Автор: Екатерина Дробышевская
связаться с автором
- письмо
- учёные
- археология
- исследование
Последние новости
Здоровье
11. 02.2023
02.2023
Почему мужчине нужно делать педикюр: 4 аргумента в пользу мнения
Диеты и кулинария
11.02.2023
Почему суп получается невкусный: ТОП-5 ошибок, которые совершают все
Политика
11.02.2023
Посол Антонов сообщил о срыве планов Запада нанести поражение РФ
В мире
11.02.2023
Кирби: американские военные сбили аэростат над Аляской
Главные новости
Шоу-бизнес
10.02.2023
«Не верю, что это происходит со мной»: внук Пугачевой сменил имя
Гороскопы
10.02.2023
«Познают настоящее счастье»: 4 знака зодиака до Дня Всех Влюбленных встретят свою вторую половинку
В мире
10.02.2023
Зеленского предупредили о тревожном сломе ситуации на Западе в отношении Украины
Политика
10.02.2023
Минюст добавил в реестр иноагентов Земфиру и Дмитрия Гудкова
Новости сегодня
10. 02.2023
02.2023
Пригожин заявил, что освобождение Донбасса может занять два года
10.02.2023
Бывший разведчик армии США Риттер: Путин сражается со всем Западом и побеждает
10.02.2023
Макрон рассмешил французов словами о Путине
10.02.2023
Эксперт спрогнозировал рост числа землетрясений в ближайшее время
Все новости
Что это за шрифт — Как найти шрифт?
У нас есть для вас список инструментов, которые вы можете использовать для идентификации шрифтов, используемых в приложениях, на веб-сайтах, а также в логотипах.
Читая, вы обнаружите, что некоторые из этих инструментов идентифицируют шрифты по изображению текста . Вы можете использовать эти инструменты для поиска шрифтов, используемых в приложении или на веб-сайте, используя их скриншоты для этой цели .
По другим инструментам вы получите несколько вопросов, которые будут основаны на внешнем виде шрифта и вернуть результаты, сосредоточенные на вашем описании. Если вы помните шрифт, который вы видели в приложении или на веб-сайте, но не помните источник, тогда эти инструменты вам пригодятся.
Если вы помните шрифт, который вы видели в приложении или на веб-сайте, но не помните источник, тогда эти инструменты вам пригодятся.
1. WhatFontis.
Один из самых популярных онлайн-инструментов для поиска шрифтов — WhatFontis. Вам нужно создать учетную запись, чтобы использовать его, но это бесплатно.
Вам просто нужно загрузить четкое изображение с текстом, написанным этим шрифтом, или вставить URL-адрес изображения в специальное поле , и вы можете узнать название его шрифта. Веб-сайту удается найти шрифт в впечатляющих 90% случаев. Если вы не получили результат для вашего поиска, это, скорее всего, из-за плохого качества изображения
2. WhatTheFont
Еще один онлайн-инструмент, который может идентифицировать шрифт по изображению , — WhatTheFont. Вы можете начать с загрузки изображения, и инструмент вернет близкое совпадение из своей базы данных после анализа изображения. Даже когда в изображении или подключенных скриптах более одного шрифта, этот инструмент работает отлично.
3. Font Squirrel Matcherator
Вы также можете определить шрифт по изображению с помощью Font Squirrel Matcherator. Вы можете загрузить изображение или даже указать URL-адрес изображения, чтобы Matcherator мог помочь вам с идентификацией шрифта. Этот инструмент поддерживает функции OpenType.
4. /r/identifythisfont
Даже Reddit можно использовать для поиска шрифта. Если у вас есть изображение с образцом текста, вы можете опубликовать его в сабреддите /r/identifythisfont 9.0006 и получить помощь в определении шрифта, который использовался их сообществом.
5. Identifont
Здесь вы должны наилучшим образом описать свой шрифт, Idntifont задаст вам вопросов по ключевым характеристикам шрифта , и вы сможете либо выбрать один из предложенных вариантов, либо описать шрифт. Теперь шрифт будет определяться на основе ваших ответов. Шрифт также можно искать по различным параметрам, включая имя издателя/дизайнера и внешнее сходство с другим шрифтом.
6. Шрифт в логотипе
Вы можете искать и находить шрифты, используемые в популярных брендах , используя Front in Logo. Вам просто нужно найти название бренда, и сайт сообщит вам, какой шрифт был использован в его логотипе. Вы также можете найти все другие популярные бренды, которые используют тот же шрифт.
7. Руководство по идентификации шрифтов с засечками
Руководство по идентификации шрифтов с засечками, как следует из названия, поможет вам идентифицировать шрифты с засечками. Особенности вашего шрифта с засечками должны быть описаны, такие функции, как форма засечек, перекладина и т. д., описаны путем выбора варианта из представленных на сайте, который, по вашему мнению, лучше всего определяет шрифт. Инструмент покажет вам все шрифты, соответствующие описанному вами внешнему виду.
8. Инструмент WhatFont
С помощью этого инструмента вы можете идентифицировать шрифты при просмотре веб-сайта. Букмарклет должен быть добавлен в ваш браузер. После того, как вы активируете его, вам нужно навести курсор на текст на веб-странице, чтобы получить информацию о шрифте. Доступны расширения для Chrome и Safari.
Букмарклет должен быть добавлен в ваш браузер. После того, как вы активируете его, вам нужно навести курсор на текст на веб-странице, чтобы получить информацию о шрифте. Доступны расширения для Chrome и Safari.
Эти инструменты, несомненно, помогут вам идентифицировать шрифты, с которыми вы сталкиваетесь при просмотре различных веб-сайтов или использовании приложений.
Как мы создали механизм распознавания шрифтов
размещено в Технологии
Photo by DREW GILLIAM on UnsplashДа, мы в pixolution, естественно, больше любим изображения, чем шрифты. Но у нас был интересный проект с поставщиком программного обеспечения из Портленда Extensis, который специализируется на управлении активами шрифтов и бренд-менеджменте.
В этом конкретном случае Extensis попросила нас обучить модель ИИ, способную классифицировать шрифты. Идея заключалась в том, чтобы создать сервис, в котором пользователи могли загрузить изображение с текстом, выбрать одно или два слова и определить тип шрифта. Процесс создания этой модели был настолько интригующим и сложным, что было бы позором не поделиться им с вами.
Процесс создания этой модели был настолько интригующим и сложным, что было бы позором не поделиться им с вами.
Что мы сделали
Мы обучили нейронную сеть, способную классифицировать используемый тип шрифта и вариант шрифта на входном изображении - из 370 изученных типов шрифта. Модель нуждается только в одном или двух словах в качестве образца ввода и не зависит от языка, от конкретного слова, фона, цвета и размера.
Кроме того, нам пришлось реализовать конвейер предварительной обработки для нормализации пользовательского ввода перед идентификацией шрифта.
23 миллиона изображений в качестве данных для обучения
Как всегда при обучении моделей ИИ, самое главное — иметь разумные данные для обучения. Таким образом, создание достаточно большой базы данных для обучения глубокой сверточной сети с нуля было наиболее сложной задачей. В общем 90% работы — создание и улучшение обучающих данных при разработке модели ИИ. Поскольку мы могли генерировать наши обучающие данные вместо их сбора, мы смогли обучить модель с нуля.
Сначала мы собрали из Интернета списки слов на английском и немецком языках, в общей сложности 450 000 слов. Мы реализовали скрипт Python, который случайным образом выбирает 1-2 слова из этого объединенного списка слов и отображает их в файле изображения. Идея использования настоящих слов вместо случайных букв заключалась в том, чтобы отразить различную вероятность появления - и, таким образом, важность определенных букв - в текстах реального мира. Тем не менее, мы вставили несколько случайных букв, чтобы модель не научилась буквосочетаниям.
Для каждого шрифта мы сгенерировали 3000 изображений со случайными словами. И для каждого из этих изображений мы сгенерировали 20 дополненных версий. В сумме это составляет до 60 000 обучающих образцов для каждого шрифта и около 23 миллионов изображений в целом.
Было важно, чтобы все слова отображались с одинаковой высотой пикселя, чтобы сеть по ошибке не научилась различать шрифты по размеру.
Затем мы дополнили эти визуализированные изображения различными модификациями, чтобы сделать модель более устойчивой к шуму и отвлекающим визуальным элементам, таким как цвета фона, тени, перекрытия, кадрирование и т.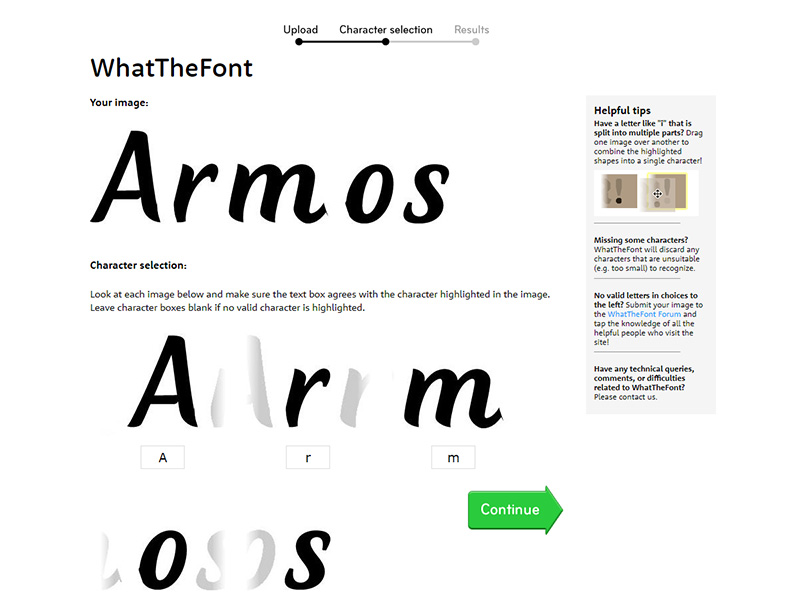 д. Отличной средой для увеличения изображений является imgaug. Мы использовали его для увеличения каждого образца 20 раз.
д. Отличной средой для увеличения изображений является imgaug. Мы использовали его для увеличения каждого образца 20 раз.
Получив данные для обучения, мы перешли к обучению модели GoogLeNet. Фаза тестирования была очень приятной, так как точность проверочного набора составила более 98%. Неплохо, правда?
Нормализация пользовательского ввода
Пользователи службы распознавания шрифтов загружают изображение и выбирают область из одного или двух слов. Затем это субизображение классифицируется моделью ИИ. Конечно, реальные пользователи не будут предоставлять идеальные входные данные. Они могут содержать несколько строк текста с разным шрифтом и размером изображения. Чтобы избежать потери точности, мы внедрили конвейер предварительной обработки для нормализации ввода.
Нормализация пользовательского ввода Во-первых, мы применяем ядро эрозии для создания маски связанных областей, которая примерно представляет собой строки текста. Мы определяем самую большую область и вычисляем ее ограничивающую рамку. Если мы нашли такую область, мы обрезаем входное изображение до этой ограничивающей рамки, чтобы удалить несколько строк и смещений из входного изображения и получить одну строку с текстом.
Мы определяем самую большую область и вычисляем ее ограничивающую рамку. Если мы нашли такую область, мы обрезаем входное изображение до этой ограничивающей рамки, чтобы удалить несколько строк и смещений из входного изображения и получить одну строку с текстом.
Затем мы применяем адаптивный порог (алгоритм CLAHE) для автоматического выравнивания цветовых каналов. После увеличения резкости изображение масштабируется до фиксированной высоты с сохранением соотношения сторон. Мы обрезаем ширину до фиксированной ширины и центрируем полученное изображение в квадратном изображении (256×256 пикселей). Теперь изображение нормализовано и используется в качестве входных данных для модели классификации.
Резюме
Мы с гордостью можем сказать, что достигли всех целей проекта с Extensis и обязательно продолжим нашу работу в области распознавания шрифтов.
Есть несколько вещей, которые мы можем улучшить. В настоящее время система не может работать с повернутым текстом, и вход модели должен быть изменен, поэтому нам не нужны квадратные изображения.
