Как в Twitter сменить логин и имя
Данное при рождении имя изменить не так-то легко, однако в социальных сетях, к счастью, это сделать намного проще. Используемое в Twitter имя является частью вашей онлайн-личности и зачастую может сказать о вас гораздо больше, чем сами твиты.
♥ ПО ТЕМЕ: Самые сложные пароли: как правильно придумывать и не забывать их – 2 совета от хакера.
Надо сказать, что имя пользователя (логин) и отображаемое имя в Twitter – это не одно и то же. Имя пользователя – это уникальное название вашей учетной записи. Именно оно отображается в URL-адресе вашего профиля и позволяет заходить в аккаунт, оставлять комментарии, отвечать на твиты и отправлять личные сообщения. Если точнее, имя пользователя (логин) – это то, что следует за символом @. В свою очередь, отображаемое имя выводится в профиле непосредственно под именем пользователя, а в новостной ленте – слева от него.
Порой нам очень хочется перемен, так почему же не изменить свои имена в Twitter, благо в сервисе предусмотрена такая возможность. Не беспокойтесь, все ваши читатели, твиты и личные сообщения после смены имени никуда не денутся. Главное, дайте друзьям знать, что отныне вы именуетесь по-другому. Придумывая новое имя, лучше всего остановить выбор на коротком и запоминающемся псевдониме, который у ваших читателей будет ассоциироваться именно с вами, например, как в нашем случае – @yablyk.
♥ ПО ТЕМЕ: Как скачивать видео с Вконтакте, Ютуб, Facebook, Twitter, Инстаграм, Одноклассников на компьютер: лучшие бесплатные сервисы
.
Как изменить имя пользователя (логин) в Twitter на сайте или в приложении
1. Авторизуйтесь в своей учетной записи
Откройте браузер на сайте twitter.com и зайдите в свой аккаунт в Twitter, как обычно.
В мобильном приложении Twitter после авторизации откройте любую из четырех вкладок в нижнем меню кроме домашней. В правом верхнем углу нажмите значок Настройки.
В правом верхнем углу нажмите значок Настройки.
2. Зайдите в настройки учетной записи
На сайте twiiter.com нажмите на кнопку «Еще» в меню слева. В открывшемся меню выберите опцию «Настройки и конфиденциальтность».
В мобильном приложении нужно открыть главную страницу настроек и перейти в раздел
3. Измените имя пользователя
Перейдите в раздел «Учетная запись». В поле «Имя пользователя» введите новый желаемый логин. Его длина не должна превышать 15 знаков. Кроме того, нельзя использовать слова Twitter и Admin и какие-либо другие знаки, кроме букв алфавита, цифр и нижнего подчеркивания.
Если выбранное вами имя использует уже кто-то другой, отобразится соответствующее уведомление. После ввода нового имени не забудьте сохранить изменения.
Обратите внимание, если вы являетесь владельцем официально подтвержденного аккаунта (то есть, если возле вашего имени пользователя стоит галочка), после смены имени нужно будет заново повторить процедуру подтверждения, а галочка исчезнет.
♥ ПО ТЕМЕ: Как написать любую ссылку при помощи смайликов эмодзи.
Как изменить отображаемое имя в Twitter
Авторизуйтесь в своей учетной записи
Откройте браузер или мобильное приложение и зайдите в свой аккаунт в Twitter, как обычно, а затем перейдите на домашнюю страницу.
Зайдите в свой профиль
Перейдите в раздел «Профиль».
Нажмите на расположенную в правой части кнопку «Изменить профиль», после чего появится форма для ввода нового имени, а остальная часть экрана станет бледнее.
В мобильном приложении перейдите на главную страницу, нажмите на аватарку аккаунта в левом верхнем углу, а затем выберите раздел Профиль.
Нажмите кнопку Редактировать.
Измените отображаемое имя
В открывшейся форме введите желаемый псевдоним. Его длина не должна превышать 20 знаков. Закончив, не забудьте сохранить изменения.
Закончив, не забудьте сохранить изменения.
Смотрите также:
Как включить черный фон в Twitter на iPhone
29 Марта, 2019, 10:00
1967
Администрация социальной сети Twitter объявила о том, что добавляет настоящий черный фон в приложение для iOS. Ранее там уже был доступен режим «Темный фон», но при выборе такого режима фон становился фактически темно-синим, а сейчас при выборе режима Lights out цвет фона меняется на настоящий черный.
Чтобы выбрать такой фон, нужно запустить приложение, свайпнуть вправо, затем в настройка приложения выбрать пункт «Экран и звук», выбрать темный фон и включить опцию Lights out. Ниже — видеоинструкция от Twitter.
It was dark. You asked for darker! Swipe right to check out our new dark mode. Rolling out today. pic.twitter.com/6MEACKRK9K
— Twitter (@Twitter) 28 марта 2019 г.
Такое переключение цвета может экономить заряд. Дело в том, что OLED- и AMOLED-экраны способны на передачу почти идеально черного цвета (в отличие от, к примеру, IPS-экранов, которые при полной заливке черным все равно видимо светятся). Этот эффект достигается благодаря специфике OLED-экранов. В них пикселям не нужна отдельная подсветка, как в LCD-панелях.
Напомним, в начале марта в Facebook Messenger появилась возможность переключения на черный фон.
Эпики, истории, темы и идеи
Представьте, что перед вашей командой стоит амбициозная цель: скажем, запустить ракету в космос. Для этого нужно правильно спланировать работу, от самых крупных целей до мельчайших подробностей. Вам потребуется возможность реагировать на изменения, отчитываться о достижениях и придерживаться плана. В этом помогут такие инструменты, как эпики, истории и инициативы.
Популярные методики Agile и DevOps помогают придать работе четкую структуру. Изучив их, ваша команда найдет разумный баланс между жесткой структурой, свободой действий и успешным запуском ракет в космос.
Что такое истории, эпики и инициативы?
- Истории, или пользовательские истории, — это краткое изложение требований или запросов, составленное с точки зрения конечного пользователя.

- Эпики — это крупные этапы работы, которые можно разбить на несколько небольших заданий (историй).
- Инициативы — это ряд эпиков, объединенных общей целью.
Эпики и истории в Agile
В определенной степени истории и эпики в agile похожи на рассказы и циклы в литературе или кино. Рассказ состоит из одной простой сюжетной линии; из ряда схожих и взаимосвязанных рассказов складывается цикл или сериал. Подобную аналогию можно применить к организации работы: завершение ряда связанных историй ведет к завершению эпика. Истории передают суть выполненной работы, а эпик обеспечивает представление о единой цели на более общем уровне.
Для команды, следующей принципам Agile, история — это часть работы, которую можно выполнить за спринт продолжительностью в одну или две недели. Зачастую разработчикам приходится иметь дело с десятками историй каждый месяц. Эпиков меньше, чем историй, но на их завершение уходит больше времени. В команде обычно обозначены два или три эпика, которые нужно завершить за квартал.
В команде обычно обозначены два или три эпика, которые нужно завершить за квартал.
Если ваша компания запускает ракеты в космос и хотела бы усовершенствовать сервис видеотрансляций для показа запусков, упорядочить истории можно по приведенной ниже схеме.
Примеры agile-историй
- Пользователи iPhone хотят при использовании мобильного приложения смотреть прямые трансляции в вертикальной ориентации.
- Пользователям компьютеров нужна кнопка «Полноэкранный режим» в правом нижнем углу видеопроигрывателя.
- Пользователям устройств Android нужна ссылка на магазин Apple.
Узнайте, как настраивать истории (задачи) в Jira Software
Все перечисленные выше истории связаны друг с другом и представляют собой отдельные задания, выполнение которых приведет к выполнению большего объема работы (эпика). В данном случае эпик можно сформулировать как «Усовершенствование сервиса видеотрансляций для запуска ракет в первом квартале».
Когда работа организована в виде историй и эпиков, ваша команда может эффективнее обсуждать ее с другими подразделениями организации. Отчитываясь о достижениях команды перед руководителем отдела проектно-конструкторских работ, вы опираетесь на эпики. В разговоре с коллегой из команды разработчиков вы опираетесь на уровень историй.
Полные определения, примеры и рекомендации приведены в следующих разделах.
Эпики и инициативы в Agile
Эпики состоят из историй, а инициативы аналогичным образом состоят из эпиков. Инициативы — это дополнительный организационный уровень над эпиками. Во многих случаях в инициативу объединяются эпики разных команд для получения более общей цели, превосходящей по масштабу любой отдельно взятый эпик. Если эпик можно завершить за месяц или квартал, для выполнения инициативы зачастую требуется от нескольких кварталов до года.
Пример эпиков в инициативе
Предположим, ваша ракетная компания хочет в этом году сократить стоимость запуска в космос на 5 %. Такая цель идеально походит на роль инициативы, так как за один эпик с этой масштабной задачей не справиться. Инициативу можно разделить на такие эпики, как «сократить потребление топлива на этапе запуска на 1 %», «увеличить частоту запусков в квартал с 3 до 4» и «уменьшить значение температуры на всех терморегуляторах в экономичном режиме с 22 до 20 градусов Цельсия».
Такая цель идеально походит на роль инициативы, так как за один эпик с этой масштабной задачей не справиться. Инициативу можно разделить на такие эпики, как «сократить потребление топлива на этапе запуска на 1 %», «увеличить частоту запусков в квартал с 3 до 4» и «уменьшить значение температуры на всех терморегуляторах в экономичном режиме с 22 до 20 градусов Цельсия».
На примере компании Atlassian
У нас в компании инициативы называются «PC-заявками». Заявки Project Central («проекта всех проектов») формируются в Jira Software так же, как и эпики. Каждая команда выбирает для себя 4–5 самых важных целей на год и создает PC-заявку для каждой из них. За счет таких заявок руководство и учредители понимают, какая работа ведется в компании.
ДАЛЕЕ: узнайте, как настраивать agile-эпики.
За рамками инициатив
Во многих организациях учредители и руководящие лица приветствуют стремление достичь чего-нибудь амбициозного. Для этого они каждый год или квартал ставят цели (иногда на удивление банальные). Инициативы, как правило, представляют собой коллекцию эпиков, однако вы также можете применять пользовательские поля или метки для их упорядочивания по командам, стратегическим планам или временным рамкам либо создавать пользовательские иерархии для эффективного согласования работы с более высокоуровневыми целями организации.
Инициативы, как правило, представляют собой коллекцию эпиков, однако вы также можете применять пользовательские поля или метки для их упорядочивания по командам, стратегическим планам или временным рамкам либо создавать пользовательские иерархии для эффективного согласования работы с более высокоуровневыми целями организации.
Многие клиенты Atlassian используют Advanced Roadmaps в Jira Software, чтобы работать с пятью уровнями, которые находятся выше уровня эпиков. Эти уровни позволяют лучше определять проекты и управлять ими.
Узнайте, как компания Twitter унифицировала проекты и ведение совместной работы с помощью Jira: читать полную историю
Когда подразделению Cloud Foundations компании Atlassian потребовалось наглядное представление работы их команды, насчитывающей сотни инженеров, они воспользовались Advanced Roadmaps в Jira, чтобы решить ключевую проблему, с которой сталкиваются организации с распределенными командами. Возможность Advanced Roadmaps в Jira Software помогла команде составить план, который позволял наблюдать общую картину, отслеживать прогресс и без труда делиться информацией с заинтересованными сторонами.
Так выглядит планирование с помощью Advanced Roadmaps для подразделения Cloud Foundations в Atlassian. Узнать больше
Структурирование работы
Гибкость, которая достигается за счет применения методик Agile, и использование структурированного подхода не исключают друг друга. Описанная выше структура не является универсальной. Чтобы добиться успеха, команде нужно усвоить приведенные понятия и адаптировать их к своим потребностям. Мы строим работу на историях, эпиках и инициативах.
Для начала вы можете узнать о настройке эпиков в Jira Software, а затем ознакомиться со стратегическим планированием и отслеживанием работы нескольких команд с помощью Advanced Roadmaps в Jira Software.
Поделитесь этой статьей
Max Rehkopf
Я считал себя «хаотичным раздолбаем», но методики и принципы agile помогли навести порядок в моей повседневной жизни. Для меня истинная радость — делиться этими знаниями с другими людьми, публикуя многочисленные статьи, участвуя в беседах и распространяя видеоматериалы, которые я создаю для Atlassian.
Поменять тему чата в Инстаграм + 5 секретных фишек
Как установить тему
Перед тем, как мы начнем разбираться в этой и других новых фишках директа, обновите приложение Инстаграм. Так как функция “тема чата” может у Вас просто не работать из-за старой версии. Установка происходит буквально в несколько кликов.
Шаг 1: Зайдите в диалог, в котором хотите сменить тему. В правом верхнем углу нажмите на значок “i”, далее “Тема”.
Шаг 2: Выберите понравившуюся тему чата в инстаграм и вернитесь в диалог. Уведомление о том, какую тему Вы поставили, отобразится в конце переписки.
Выбор и установка темыНиже, после вариантов темы чата, можно настроить цвета и градиенты отправляемых Вами сообщений. Но имейте в виду, выбрать одновременно тему и градиент нельзя.
Но имейте в виду, выбрать одновременно тему и градиент нельзя.
Другие новые фишки директа
Кроме темы чата в директе появились другие удобные и просто визуально необычные для общения штуки.
По теме: Обновления Инстаграм: что нового + как работает
1. Живой текст
2. Наклейки и GIF
В директе можно присылать наклейки и гифки. Принцип тот же, наберите текст, нажмите на лупу. Далее Вы можете выбрать гиф или наклейку из предложенных, а можете найти через поиск на нужную тематику.
Наклейки и GIFИнтересно. Вы можете быстро и безопасно продвинуть свою соцсеть за счет накрутки лайков, репостов и просмотров на публикации. Это недорогой и безопасный способ, который не заставит долго ждать результата.
3. Ответ на конкретное сообщение
Теперь, если Вам пришло подряд несколько сообщений, на каждое можно отправить отдельный ответ. А если у Вас групповой чат – ответить конкретному пользователю. Вы можете потянуть за нужное сообщение вправо, и появится окно для ответа.
Окно для ответаЕще один способ – быстрая реакция. Просто длительно нажмите на сообщение и выберите смайл. Если Вам нужны другие эмоджи, нажмите на +.
Быстрая реакцияКоротко о главном
Пользоваться обновлениями в директе в Инстаграм, в частности темой чата, крайне просто. Но вопросы все равно могут возникнуть, поэтому напоследок ответила на самые частые.
1. Что делать, если у меня нет обновления?
Обновить приложение можно в любом маркете. Если обновления нет и там, проверьте, обновили ли Вы Андроид или IOS до актуальной версии.
2. В разных чатах можно ставить разные темы?
Включить новую тему можно через любой чат. И да, в разных чатах можете настроить темы, какие нравятся, или вернуть старые.
3. Почему у меня есть не все новые функции?
Инстаграм уже не первый раз выпускает обновление, которое доступно людям лишь частично. Таким образом разработчики тестируют, что понравится аудитории, а что – нет. Выход один – писать в техподдержку, больше, увы, ничего сделать нельзя.
4. Что делать, если после обновления стал тупить Инстаграм?
Тут только два варианта: Вы можете удалить и заново скачать приложение, но для этого нужно помнить свой пароль. Или же напишите в поддержку, но, скорее всего, они посоветуют то же самое.
По теме:
Тема для блога в Инстаграм: 100+ идей
Как вести Инстаграм: 50 лайфхаков от SMMщика
Оформление Инстаграм: 25 идей для вдохновения
Автор
Марина Лебединская
Понравилось?
Расскажите друзьям:
Нашли ошибку в тексте? Выделите фрагмент и нажмите ctrl+enter
Невозможно изменить фоновое изображение в Windows 7
Проблема
При попытке изменить фон рабочего стола в Windows 7 вы можете столкнуться с одной из указанных ниже проблем.
Сценарий 1
Когда вы пытаетесь изменить фон рабочего стола, выбрав пункты Панель управления, Персонализация и затем Фон рабочего стола, не устанавливаются флажки при их нажатии, а кнопки Выделить все и Очистить все не работают надлежащим образом. В результате вам не удается изменить фон рабочего стола.
Сценарий 2
При попытке щелкнуть изображение правой кнопкой мыши и выбрать пункт Сделать фоновым изображением рабочего стола вы получаете следующее сообщение об ошибке:
Это изображение не может быть использовано в качестве фона. Произошла внутренняя ошибка.
Сценарий 3
На рабочем столе отображается черный фон, несмотря на то что вы изменили фоновый рисунок.
Сценарий 4
Функция слайд-шоу для фона рабочего стола не работает надлежащим образом.
Причина
Эта проблема может возникать по следующим причинам.
-
На компьютере установлено стороннее приложение, например, Display Manager от Samsung.
-
На панели управления в разделе «Электропитание» отключен параметр «Фон рабочего стола».
-
На панели управления выбран параметр «Удалить фоновые изображения».
-
Изменение фонового рисунка может быть запрещено политикой домена.
-
Файл TranscodedWallpaper.jpg может быть поврежден.
-
Вы используете выпуск Windows 7 Начальная. В выпуске Windows 7 Начальная изменение фона рабочего стола не поддерживается.
Решение
Для устранения проблемы воспользуйтесь одним из описанных ниже способов, в зависимости от вашего случая.
Способ 1. Обновление до версии Windows 7, поддерживающей изменение фоновых рисунков
В выпуске Windows 7 Начальная изменение фона рабочего стола не поддерживается. Если вы работаете на ноутбуке с предустановленной системой Windows, возможно, вы используете выпуск Windows 7 Начальная.
Если у вас установлен выпуск Windows 7 Начальная, вы можете приобрести Windows 7 у дилера или через Интернет в некоторых странах и регионах. Если вы используете нетбук или другой компьютер без DVD-дисковода, простой способ установки Windows 7 — приобрести ее через Интернет и скачать. Дополнительные сведения о том, как купить Windows 7 в своей стране или регионе, см. на веб-странице магазина Windows.
Способ 2. Файл TranscodedWallpaper.jpg поврежден
Если файл TranscodedWallpaper. jpg поврежден, возможно, вам не удастся изменить фон рабочего стола. Чтобы устранить эту проблему, удалите файл TranscodedWallpaper.jpg. Вот как это сделать.
jpg поврежден, возможно, вам не удастся изменить фон рабочего стола. Чтобы устранить эту проблему, удалите файл TranscodedWallpaper.jpg. Вот как это сделать.
Щелкните здесь, чтобы показать или скрыть подробную информацию
-
Нажмите кнопку Пуск, вставьте в поле поиска следующий текст и нажмите клавишу ВВОД:
%USERPROFILE%\AppData\Roaming\Microsoft\Windows\Themes\
-
Щелкните файл TranscodedWallpaper.jpg правой кнопкой мыши и выберите команду Переименовать.
-
Измените имя файла на TranscodedWallpaper.old и нажмите кнопку Да в появившемся окне.
-
Если появится файл slideshow.ini, дважды щелкните его. Файл slideshow.ini должен открыться в приложении «Блокнот». Выделите в файле slideshow.ini весь текст, если таковой имеется, и нажмите клавишу Delete на клавиатуре.

-
В меню Файл выберите команду Сохранить.
-
Закройте приложение «Блокнот».
-
Закройте окно Проводника Windows и перейдите к изображению, которое вы хотите установить в качестве фона.
-
Попробуйте установить фоновый рисунок снова.
Способ 3. Несовместимые приложения
Некоторые приложения, которые помогают управлять параметрами дисплея, могут вызывать проблемы несовместимости при установке фонового рисунка, отображении визуальных эффектов Aero Glass и использовании других функциональных возможностей Windows. В качестве эксперимента отключите или удалите приложения управления дисплеем, установленные на вашем компьютере.
Способ 4. Проверьте настройку фона в разделе «Электропитание».
В разделе «Электропитание» панели управления есть параметр, приостанавливающий фоновое слайд-шоу. Вот как проверить параметры фона рабочего стола в разделе «Электропитание».
Щелкните здесь, чтобы показать или скрыть подробную информацию
-
Нажмите кнопку Пуск, в поле поиска введите Электропитание и выберите в списке пункт Электропитание.
-
В окне Выбор плана электропитания напротив выбранного плана электропитания нажмите Настройка плана электропитания.
-
Выберите Изменить дополнительные параметры питания и разверните раздел Параметры фона рабочего стола.
-
Разверните разделПоказ слайдов и проверьте, чтобы для параметра От сети было установлено значение Доступно.
-
Нажмите кнопку OK и закройте окно Редактировать план.
Способ 5. Установите флажок «Удалить фон» в разделе «Специальные возможности»
Параметр «Специальные возможности» в панели управления удаляет фоновые изображения. Вот как проверить параметры фона рабочего стола в разделе специальных возможностей.
Щелкните здесь, чтобы показать или скрыть подробную информацию
-
Нажмите кнопку Пуск, Панель управления, Специальные возможности, а затем Центр специальных возможностей.
-
В разделе Вывести все параметры нажмите Настройка изображения на экране.
-
Убедитесь, что не установлен флажок Удалить фоновые изображения.
-
Дважды нажмите кнопку OK и закройте окно Центр специальных возможностей.

Способ 6. Проверьте, не отключена ли возможность изменения фона рабочего стола политикой домена.
Если вы подключены к домену, ваш администратор может отключить возможность изменения фона рабочего стола. Вот как проверить политику фона рабочего стола.
Щелкните здесь, чтобы показать или скрыть подробную информацию
-
Нажмите кнопку Пуск, введите Групповая политика в поле Поиска и выберите Изменение групповой политики.
-
Выберите элементы Конфигурация пользователя, Административные шаблоны, а затем дважды нажмите элемент Рабочий стол.
-
Дважды щелкните Выбор фонового изображения.
Примечание. Если политика включена, и в ней указано конкретное изображение, пользователи не могут изменять фон.
 Если этот параметр включен, а изображение недоступно, фоновый рисунок не отображается.
Если этот параметр включен, а изображение недоступно, фоновый рисунок не отображается. -
Щелкните Не задан, чтобы включить этот параметр и изменить фон рабочего стола.
Дополнительная информация
Дополнительные сведения об изменении фонового рисунка в Windows 7 см. в следующих статьях на веб-сайте Майкрософт:
Изменение фона рабочего стола (фоновое изображение)
Изменение фона рабочего стола (только для Windows 7 Home Basic)
Почему я не могу изменить фон рабочего стола? Дополнительные сведения об изменении фонового рисунка в Windows 7 см. в следующих статьях на веб-сайте Microsoft.
Обновление до другого выпуска Windows 7 с помощью обновления Windows Anytime Upgrade
Обновление до Windows 7: часто задаваемые вопросы
Покупка Windows 7: основные вопросы
мы только начинаем осознавать масштабы геноцида в годы Великой Отечественной войны
7 декабря, Минск /Корр. БЕЛТА/. Мы только начинаем осознавать масштабы геноцида в годы Великой Отечественной войны, заявил генеральный прокурор Андрей Швед во время круглого стола «Историческая память: геноцид белорусского народа», передает корреспондент БЕЛТА.
БЕЛТА/. Мы только начинаем осознавать масштабы геноцида в годы Великой Отечественной войны, заявил генеральный прокурор Андрей Швед во время круглого стола «Историческая память: геноцид белорусского народа», передает корреспондент БЕЛТА.
«Я был в Санкт-Петербурге на международной конференции по геноциду. Там были генеральные прокуроры, в том числе европейских стран — тех стран, откуда сейчас фашисты XXI века развязали в отношении нас войну. Очень важно, чтобы было понимание обстановки сегодняшнего дня. Идет реальная война под лозунгами фашистов. Они ничем не отличаются от тех, кто был в 1941-1944 годах. На самом деле формы, методы и подходы остались те же самые, — сказал Андрей Швед. — Когда я стал приводить конкретные примеры, опираясь на свидетельства, знаете, они были шокированы. Ко мне подошел генпрокурор Нидерландов в кулуарах и сказал, что об этом не знал. Поэтому говорить нужно об этом везде, на международных площадках, на всех ресурсах, чтобы они знали».
Генпрокурор уверен, что особое внимание нужно уделить молодежи. «Самое главное, к чему мы должны прийти, — коренным образом поменять идеологию. Начинать надо с детского сада, школ, учебных заведений, менять в том числе учебные программы, — отметил он. — И тот законопроект (о геноциде белорусского народа. — Прим. БЕЛТА), который будет рассматриваться и приниматься, — это отправная точка той большой работы, которая еще нам всем предстоит. На самом деле мы только приступаем к тому, что осознаем реальные масштабы трагедии, которая была в период Великой Отечественной войны. Очень много белых пятен, обстоятельств, которые нельзя замалчивать. Люди должны об этом знать».
Сегодня в Палате представителей прошел круглый стол «Историческая память: геноцид белорусского народа». В нем приняли участие представители Генеральной прокуратуры, Министерства обороны, Национальной академии наук, Белорусского института стратегических исследований и Национального архива.-0-
Фото Рамиля Насибулина
Петра I подменили двойником — когда и почему?
В марте 1697 года из Москвы выехала дипмиссия во главе с великими послами — Францем Лефортом, Федором Головиным и Прокопием Возницыным. При них находилось около 250 человек — толмачей, писцов, лекарей, священников, поваров, слуг, охранников, волонтеров. Среди последних был и Петр I: он отправился в Западную Европу инкогнито с чужим «загранпаспортом», выписанным твореным золотом на «александрийском» листе и скрепленным красной восковой печатью. Государь скрывался под личиной десятника второго десятка Преображенского полка Петра Михайлова, который вместе с урядником Гаврило Кобылиным и еще 22 волонтерами якобы ехал с Великим посольством «для науки воинских дел».
При них находилось около 250 человек — толмачей, писцов, лекарей, священников, поваров, слуг, охранников, волонтеров. Среди последних был и Петр I: он отправился в Западную Европу инкогнито с чужим «загранпаспортом», выписанным твореным золотом на «александрийском» листе и скрепленным красной восковой печатью. Государь скрывался под личиной десятника второго десятка Преображенского полка Петра Михайлова, который вместе с урядником Гаврило Кобылиным и еще 22 волонтерами якобы ехал с Великим посольством «для науки воинских дел».«Петр Алексеевич Михайлов», «Петр Романов», «капитан Петр» — под этими и другими псевдонимами царь за полтора года побывал в Ливонии, Курляндии, Бранденбурге, Голландии, Англии, Саксонии, Империи австрийских Габсбургов, Польше. На верфи Ост-Индской компании в Амстердаме он строил фрегат «Святые Апостолы Петр и Павел» и учился анатомии у Фредерика Рюйша. В Лондоне осматривал Монетный двор в Тауэре и Королевское общество, которым заведовал Исаак Ньютон. В Дрездене познакомился с самой известной Кунсткамерой в Европе саксонского курфюрста Августа Сильного. В Вене посетил сокровищницу Хофбурга и стал участником маскарадов.
В Вене посетил сокровищницу Хофбурга и стал участником маскарадов.
В августе 1698 года Петр I прибыл в Москву и сразу взялся за изменение российского уклада. В частности, ввел новое летоисчисление от Рождества Христова и светский Новый год перенес на 1 января, основал будущую столицу — крепость «Санкт-Питербурх» на Заячьем острове, принял гражданский шрифт и арабские цифры вместо старославянских, начал модернизацию госаппарата, церковных дел, армии, промышленности, образования и культуры. А помимо этого, сослал в монастырь свою жену Евдокию Лопухину, «прописался» в Немецкой слободе, где устраивал на западный манер пиры и сначала в шутку обрезал боярам бороды.
Такие кардинальные перемены насторожили многих. И скоро в обществе появились слухи о том, что царя подменили в путешествии.
Как начать и поддерживать разговор в Twitter
Как начать и поддерживать разговор в Twitter
Twitter — мощная социальная сеть, но все больше людей используют сетевой аспект Twitter вместо социального. Twitter — это место, где предприятия и предприниматели могут легко связаться со своими клиентами и создать базу поклонников, но для того, чтобы иметь качественную базу поклонников, вы должны быть социальными. Все больше людей осознают, насколько важно общаться со своими подписчиками.
Twitter — это место, где предприятия и предприниматели могут легко связаться со своими клиентами и создать базу поклонников, но для того, чтобы иметь качественную базу поклонников, вы должны быть социальными. Все больше людей осознают, насколько важно общаться со своими подписчиками.
Вот 3 способа, которыми вы можете начать разговор в Twitter:
1. Присоединиться к разговору в процессе . При этом участвуйте в разговоре. Если вы случайно скажете что-то, просто чтобы пообщаться, другие люди в разговоре заметят и проигнорируют вас.
2. Упомяните кого-нибудь в Твиттере или ответьте ему . Важно понимать разницу между упоминанием и ответом. Упоминание — это просто твит с именем пользователя и ничего больше.Ответ — это прямой ответ на один из твитов человека. В ответе по-прежнему есть имя пользователя, но упоминания и ответы разные. Если вы хотите начать разговор, не имеющий отношения ни к одному из недавних твитов, упомяните этого человека. Вы можете упомянуть человека в верхнем левом углу, где написано «Твитнуть так и так». Если вы хотите построить разговор вокруг чьего-то твита, ответьте на этот твит.
Вы можете упомянуть человека в верхнем левом углу, где написано «Твитнуть так и так». Если вы хотите построить разговор вокруг чьего-то твита, ответьте на этот твит.
3. Задайте вопрос . Вопрос, который вы задаете, может вызвать споры (если вы спросите, какая спортивная команда лучше в соревновании, вы получите много ответов), вы можете задать вопросы и ответы или задать простой вопрос.Независимо от того, какой вопрос вы задаете в Твиттере, единственный способ ответить на этот вопрос — это ответить вам.
Это 3 способа начать разговор. Это 3 способа поддержать разговор. Важно поддерживать диалог, потому что тогда вы налаживаете связи в Твиттере и получаете больше качественных подписчиков. Иметь настоящих подписчиков — это одно, но иметь качественных подписчиков еще лучше.
1. Ответить менее чем через 6 часов . Некоторые люди скажут, что вы можете ответить менее чем за 12 часов, но я рекомендую отвечать менее чем за 6 часов.Чем быстрее вы ответите, тем лучше вы сможете поддерживать беседу. Это как разговаривать с друзьями на Facebook. Когда они отвечают, и вы отвечаете им, эти ответы превращаются в беседу вперед и назад. Когда разговор заканчивается, оба пользователя Facebook переходят к чему-то другому. Если кто-то решит отправить ответ через 20 минут, он может не получить такой же быстрый ответ. Чем быстрее вы ответите, тем больше вероятность, что вы продолжите разговор.
Это как разговаривать с друзьями на Facebook. Когда они отвечают, и вы отвечаете им, эти ответы превращаются в беседу вперед и назад. Когда разговор заканчивается, оба пользователя Facebook переходят к чему-то другому. Если кто-то решит отправить ответ через 20 минут, он может не получить такой же быстрый ответ. Чем быстрее вы ответите, тем больше вероятность, что вы продолжите разговор.
2. Возьмите разговор за пределами Twitter .Если вы понимаете, что у человека, с которым вы разговариваете, есть блог, напишите в Твиттере о блоге этого человека. У этого человека будет еще одна причина поговорить с вами, потому что вы только что написали в Твиттере одно из его сообщений в блоге. Отправьте комментарий в блог в день начала разговора в Twitter. Если человек разговаривал (или разговаривает) с вами в Твиттере, он также захочет поговорить с вами в своем блоге.
3. Не пытайтесь завершить разговор по ошибке . Если кто-то благодарит вас за то, что вы что-то написали, и вы хотите продолжить разговор, не отвечайте, говоря: «Добро пожаловать.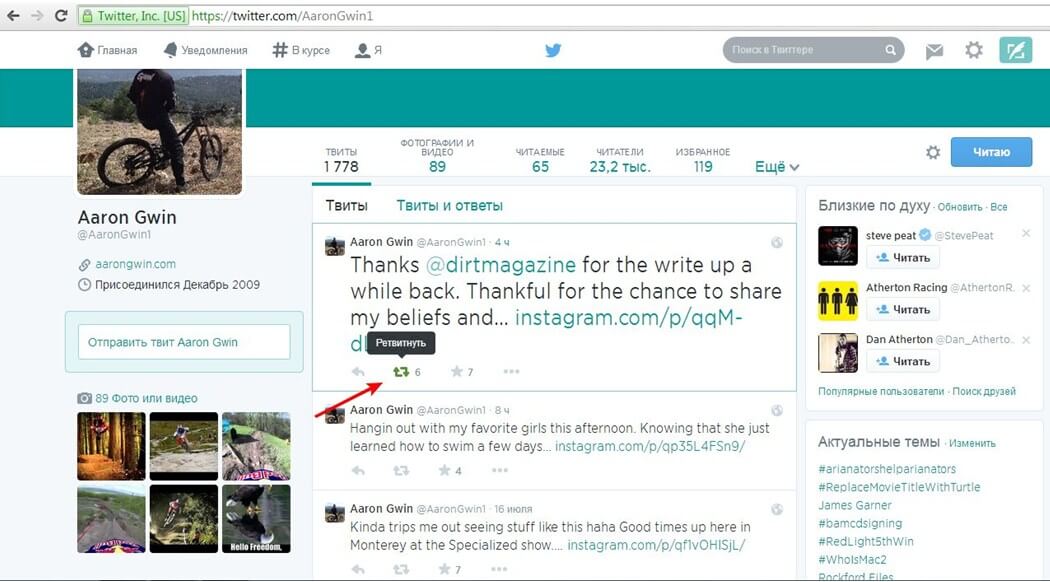 «Если ты так скажешь, то закончишь разговор. Сказать «добро пожаловать» уместно, но если вы скажете это в Твиттере, будет сложно сменить тему. Вместо этого вы можете сказать что-то вроде: «Добро пожаловать. Кстати, как долго ты твитнул »или что-то в этом роде.
«Если ты так скажешь, то закончишь разговор. Сказать «добро пожаловать» уместно, но если вы скажете это в Твиттере, будет сложно сменить тему. Вместо этого вы можете сказать что-то вроде: «Добро пожаловать. Кстати, как долго ты твитнул »или что-то в этом роде.
Дополнительные социальные статьи от Business 2 Community:
Twitter, чтобы добавить новую контекстную функцию в актуальные темы
Twitter заявил во вторник, что добавит больше контекста к темам, имеющим тенденцию в своем сервисе, в попытке очистить функцию, которая часто использовалась для усиления ненависти и дезинформации.
Это изменение связано с тем, что Twitter и другие социальные сети изо всех сил пытаются отреагировать на дезинформацию, связанную с президентскими выборами в США. Но это не дает решения, которое предложили некоторые сотрудники Twitter и сторонние активисты: полностью искоренить популярные темы.
Twitter предлагает тенденции как способ определить, какие темы наиболее популярны. Тенденции служат ориентиром для новых пользователей, которые учатся находить информацию в Twitter, и помогают всем пользователям ориентироваться в новостях.Их можно курировать в соответствии с личными интересами или географическим положением.
Тенденции служат ориентиром для новых пользователей, которые учатся находить информацию в Twitter, и помогают всем пользователям ориентироваться в новостях.Их можно курировать в соответствии с личными интересами или географическим положением.
Но система часто использовалась ботами и интернет-троллями для распространения ложной, ненавистной или вводящей в заблуждение информации.
В феврале российские тролли поддержали выдвинутую в США теорию заговора о том, что бывшие сотрудники Хиллари Клинтон подтасовывали собрания в Айове, и помогли выдвинуть необоснованную теорию на вершину списка тенденций Твиттера.
В июле белые националисты продвигали антисемитский хэштег #JewishPrivilege до тех пор, пока он не стал тенденцией, а QAnon, группа сторонников заговора Трампа, заставила мебельную компанию Wayfair попасть в тренд в Твиттере с ложными заявлениями о том, что компания занимается детьми. торговля людьми.
Эти эпизоды заставили некоторых сотрудников Twitter поверить в то, что функция тенденций не стоит своих обязательств. За последние два года нынешние и бывшие сотрудники утверждали, что Twitter никогда не справится с дезинформацией должным образом, пока не уничтожит свой список тенденций.
За последние два года нынешние и бывшие сотрудники утверждали, что Twitter никогда не справится с дезинформацией должным образом, пока не уничтожит свой список тенденций.
Но после убийств в Кеноша, штат Висконсин и Портленд, штат Орегон, в последние недели их звонки стали более срочными.
На встречах с политиками Twitter и высшим руководством, включая Джека Дорси, генерального директора, сотрудники предупреждали, что актуальные темы, если не уделить должного внимания, могут спровоцировать дальнейшее насилие в преддверии ноябрьских выборов и после них, согласно двум людям, проинформированным о дискуссиях, которым не разрешалось обсуждать их публично.
Наблюдатели соглашаются и недавно начали кампанию с использованием хэштега #UntrendOctober, который просит Twitter отключить свой сервис трендов во время выборов.
«Нам нужно улучшать тенденции, и мы это сделаем», — сказал Фрэнк Оппонг, менеджер по продуктам Twitter, и Лиз Ли, партнер по доверительному управлению продуктами, в сообщении в блоге компании, объявляющем об изменениях.
Популярные темы теперь будут включать пояснительные твиты и описания, которые показывают, почему товар находится в тренде, сообщил Twitter. Раньше Trending Topics содержали заголовок темы или хэштег, сопровождаемый постоянным потоком твитов на эту тему, часто уводя пользователей в кроличью нору, чтобы раскрыть, почему она стала популярной.
«Так много нарративов дезинформации, которые мы видим в Твиттере, распространяются людьми, которые не обязательно согласны с этим — они просто говорят об этом, потому что это имеет тенденцию, и поэтому они усиливают его», — сказала Синди Отис, вице-президент анализа в Alethea Group, которая проводит расследования по дезинформации. «Признание этого должно быть частью расчетов Твиттера, если они хотят иметь дело с дезинформацией».
Начиная со вторника, Twitter сообщил, что предлагает более немедленную информацию.
«К некоторым тенденциям будут прикреплены репрезентативные твиты, чтобы вы сразу же смогли лучше понять тенденцию», — сказали г-н Оппонг и г-жа Ли. «Комбинация алгоритмов и наша команда кураторов определяют, представляет ли твит тенденцию, оценивая, насколько твит отражает тенденцию и является ли популярным».
«Комбинация алгоритмов и наша команда кураторов определяют, представляет ли твит тенденцию, оценивая, насколько твит отражает тенденцию и является ли популярным».
Но люди, знакомые с усилиями Twitter, сказали, что это была лишь половина меры, маловероятной для решения основной проблемы, и что Twitter не хватало финансовых ресурсов для проведения модерации и курирования на значимом уровне.
Twitter полагается на алгоритмы для обнаружения оскорбительных твитов или спама и предотвращения появления этих твитов в тенденциях, добавили они. В июле Twitter заблокировал 150 000 аккаунтов, которые были известны продвижением теорий заговора, от появления в трендах.
«Среди разносчиков дезинформации в Твиттере есть хорошо известная инструкция по использованию алгоритма», — сказал Мэтт Ривиц, создатель «Спящих гигантов», организации, которая подталкивает компании социальных сетей и рекламодателей к разрыву финансовых связей с крайне правыми группами. .
Спящие гиганты недавно призвали в Твиттере отключить тенденции во время подготовки к выборам, утверждая, что тенденции могут служить средством дезинформации.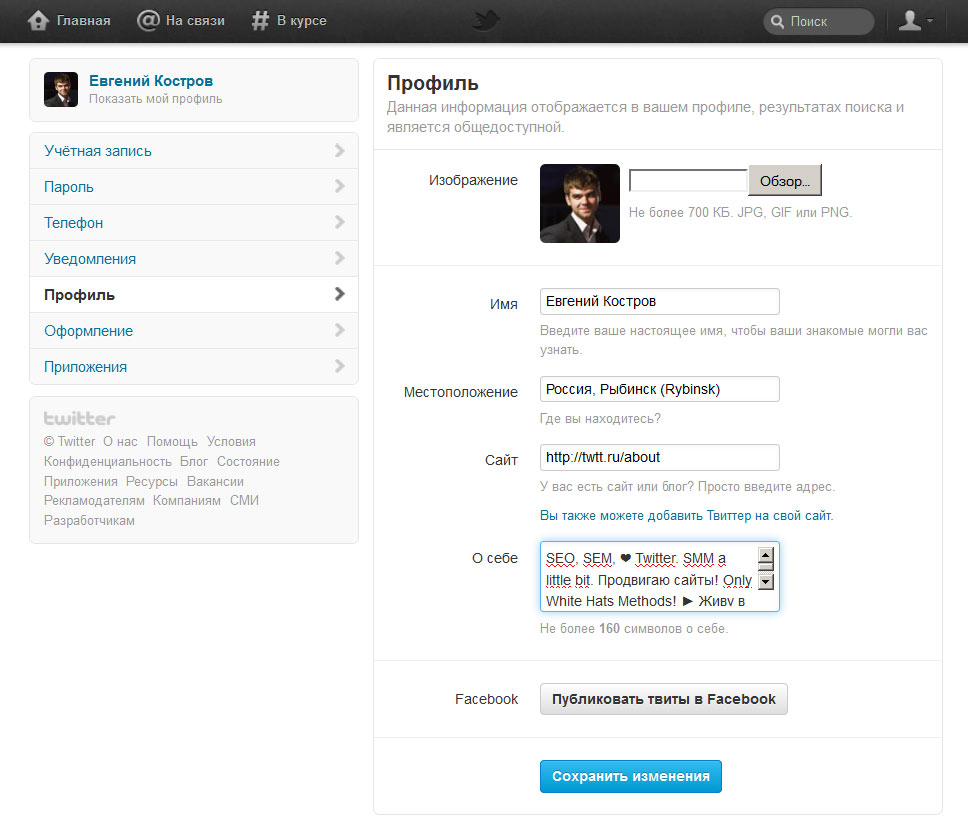
«Как барометр того, что происходит, его так легко использовать», — сказал г-н Ривиц.
Методы обнаружения и отслеживания тем в Твиттере: систематический обзор
Социальные сети — это платформы реального времени, созданные пользователями, включающие разговоры и взаимодействия. Это явление новой информационной эры приводит к появлению огромного количества данных в различных формах и модальностях, таких как текст, изображения, видео и голос.Данные с такими характеристиками также известны как большие данные со свойствами 5-V, а в некоторых случаях также называются большими социальными данными. Чтобы найти полезную информацию из таких ценных данных, многие исследователи пытались обратиться к различным ее аспектам для разных модальностей. Что касается текста, то исследователи НЛП провели множество исследований и научных работ, чтобы извлечь ценную информацию, например, темы. Многие просветительские работы на разных платформах социальных сетей, таких как Twitter, пытались решить проблему поиска важных тем с разных сторон и использовали их, чтобы предложить решения для различных случаев использования. Важность Twitter в этой сфере заключается в его содержании и поведении пользователей. Например, это также известно как социальные сети, сообщающие новости из первых рук, которые были платформой для репортажей и информирования даже политических влиятельных лиц или катастрофических новостей. В этой обзорной статье мы освещаем более 50 исследовательских статей в области выявления тем из Twitter. Мы также обращаемся к методам, основанным на глубоком обучении.
Важность Twitter в этой сфере заключается в его содержании и поведении пользователей. Например, это также известно как социальные сети, сообщающие новости из первых рук, которые были платформой для репортажей и информирования даже политических влиятельных лиц или катастрофических новостей. В этой обзорной статье мы освещаем более 50 исследовательских статей в области выявления тем из Twitter. Мы также обращаемся к методам, основанным на глубоком обучении.
1. Введение
Обнаружение и отслеживание тем, также называемое TDT, — это методы и методы, используемые для обнаружения новостей или связанных с документами тем, наиболее подходящих для соответствующего интеллектуального материала, а также отслеживания этих событий или обнаруженных тем с помощью специальных средств массовой информации.Обнаружение темы — это задача реферирования, которая должна удовлетворять определенным требованиям. Тема как обобщенный набор тегов входного документа отличается от события, которое в большинстве случаев является реальным явлением с определенными пространственными и временными свойствами [1, 2].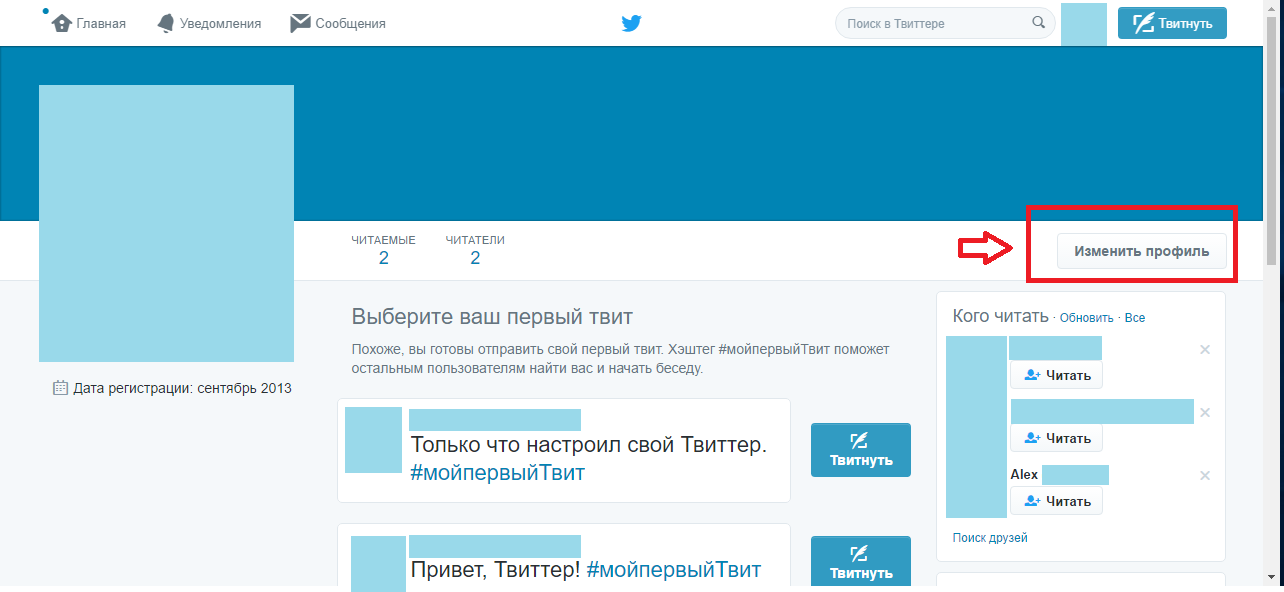 Эта крошечная разница между темой и событием становится более очевидной, когда речь идет о социальных сетях. Идентификация текущих событий на носителе может быть выражена как обнаружение , тогда как отслеживание этих событий и раскадровка — как отслеживание .Этот так называемый носитель может быть одним документом, группой из нескольких документов или даже социальной сетью, такой как Twitter. Обнаружение и отслеживание тем широко применялось к документам, автономному корпусу и новостной ленте, включая пилотное исследование, которое проводилось с 1996 по 1997 год и спонсировалось [3].
Эта крошечная разница между темой и событием становится более очевидной, когда речь идет о социальных сетях. Идентификация текущих событий на носителе может быть выражена как обнаружение , тогда как отслеживание этих событий и раскадровка — как отслеживание .Этот так называемый носитель может быть одним документом, группой из нескольких документов или даже социальной сетью, такой как Twitter. Обнаружение и отслеживание тем широко применялось к документам, автономному корпусу и новостной ленте, включая пилотное исследование, которое проводилось с 1996 по 1997 год и спонсировалось [3].
Социальные сети, такие как Twitter , Facebook , Google+ и LinkedIn , играют важную роль в обмене информацией. В случае Twitter метрики обмена данными предсказывают, что в секунду отправляется 7 454 твита, что составляет примерно 644 025 600 твитов в день [4].Официальные лица Twitter сообщили, что этот показатель за 2013 год составляет более 500000000 в день [5]. Важность этого большого количества данных, содержащих большое количество тем, о которых обычно говорят пользователи, становится очевидной, когда исследователи выявили, что пользователи, скорее всего, будут говорить о реальных событиях в социальных сетях больше, чем традиционные новости и блоги СМИ. Обнаружение тем в этих коротких сообщениях может помочь лучше понять мнения пользователей об именованных событиях и реальных событиях.
Важность этого большого количества данных, содержащих большое количество тем, о которых обычно говорят пользователи, становится очевидной, когда исследователи выявили, что пользователи, скорее всего, будут говорить о реальных событиях в социальных сетях больше, чем традиционные новости и блоги СМИ. Обнаружение тем в этих коротких сообщениях может помочь лучше понять мнения пользователей об именованных событиях и реальных событиях.
Новая область исследований этой гонки TDT началась, когда появились новые социальные сети, такие как Twitter . Twitter по своей природе состоит из пользователей, мгновенно отправляющих короткие сообщения, называемые твитами . Эти твитов могут быть сообщениями из повседневной жизни пользователя, например: « я съел пиццу! yaaay! »; важные сообщения от технического сообщества, например: «Скоро дата выпуска Ubuntu 16.10! »; или даже политическое сообщение вроде « WikiLeaks operative: электронные письма кампании Клинтона пришли из внутренних утечек, а не из русских хакеров . Эти сообщения часто помечаются определенными словами, чтобы сделать их адресными и доступными. На рисунке 1 показан пример тегирования в Twitter . Однако в большинстве случаев этот тег не показывает особой связи между желаемыми новостями и темами, а только точку зрения пользователя на его / ее твит . Одно сообщение может быть о голосовании, а другое — о кормлении уток, и оба помечены как #DuckTales . Эта проблема может быть решена как разновидность , из аспекта больших данных и неоднозначность , из аспекта обработки естественного языка.Более того, обнаружение реального события с большим объемом и скоростью данных требует больше исследований, чем поиск события на выбранных и отфильтрованных наборах данных [6]. Еще одна проблема, связанная с этим СМИ, — это шумность размещаемых твитов. Эти твиты, в отличие от новостных статей и интеллектуальных документов, написаны некорректно и содержат орфографические ошибки, грамматические ошибки и даже слова или выражения вроде « yaaaaaay », которые не являются литературными.
Эти сообщения часто помечаются определенными словами, чтобы сделать их адресными и доступными. На рисунке 1 показан пример тегирования в Twitter . Однако в большинстве случаев этот тег не показывает особой связи между желаемыми новостями и темами, а только точку зрения пользователя на его / ее твит . Одно сообщение может быть о голосовании, а другое — о кормлении уток, и оба помечены как #DuckTales . Эта проблема может быть решена как разновидность , из аспекта больших данных и неоднозначность , из аспекта обработки естественного языка.Более того, обнаружение реального события с большим объемом и скоростью данных требует больше исследований, чем поиск события на выбранных и отфильтрованных наборах данных [6]. Еще одна проблема, связанная с этим СМИ, — это шумность размещаемых твитов. Эти твиты, в отличие от новостных статей и интеллектуальных документов, написаны некорректно и содержат орфографические ошибки, грамматические ошибки и даже слова или выражения вроде « yaaaaaay », которые не являются литературными. Выраженные проблемы данного носителя значительно усложняют задачу TDT.
Выраженные проблемы данного носителя значительно усложняют задачу TDT.
Сообщество интеллектуального анализа данных и искусственного интеллекта стало свидетелем множества исследовательских работ, выполненных в этой области, которые показывают многообещающие преимущества по сравнению друг с другом. Многие из этих работ основаны на простой модели набора слов , в то время как другие продолжают поиск на вероятностных тематических моделях , и все же некоторые из них ищут внезапные изменения в контролируемых свойствах. Общей частью их всех является использование техник и методов обработки естественного языка вместо стохастических моделей n на уровне символов.
Эти методологии помогают в выполнении задачи по обнаружению и отслеживанию событий, и появляются темы об оптимизации социальных сетей, чтобы ответить на несколько вопросов, таких как следующие: (i) О чем все говорят в определенное время? (Ii ) Что в тренде? (Iii) Что происходит где-то на Земле? (Iv) Кроме того, вопросы с динамическими ответами, которые имеют временные и пространственные свойства, вызывают значительный рост общественного интереса.
Чтобы найти наиболее подходящие статьи в этой области, мы использовали академическую поисковую систему Google Scholar.Сначала мы подготовили ключевые слова для поиска, которые перечислены ниже: (i) Обнаружение тем (ii) Обнаружение тем Twitter (iii) Обнаружение событий Twitter (iv) Извлечение событий Twitter (v) Извлечение тем Twitter (vi) Отслеживание тем Twitter (vii) Отслеживание событий Twitter. (Viii) Тенденции в Twitter. (Ix) Трендовые события Twitter
Мы использовали показатель цитируемости в год, чтобы получить общий показатель важности каждой статьи с академической точки зрения. Мы использовали пороговое значение для этого показателя, равное двум, и исключили статьи, которые имели менее двух цитирований в год.В случае новых статей, например, опубликованных за последние два года, мы не удаляли их из списка, даже если они имеют менее двух цитирований в год. Чтобы убедиться, что не связанные статьи исключены из списка, мы читаем заголовок и аннотацию каждой статьи и удаляем те, которые не связаны с заголовком нашего обзора. После этого мы классифицировали оставшиеся статьи в зависимости от их новизны и методологии. Остальные статьи — те, которые использовались для проведения этого исследования.
После этого мы классифицировали оставшиеся статьи в зависимости от их новизны и методологии. Остальные статьи — те, которые использовались для проведения этого исследования.
Эта обзорная статья организована следующим образом. Во-первых, в разделе 2 описывается Twitter как услуга. Раздел 3 классифицирует и объясняет существующие методы и модели. В Разделе 4 объясняется предварительная обработка как общий шаг, который является общим для всех методов. В разделе 5 подробно описаны методы и подходы, основанные на различных категориях. В разделе 6 дается общее обсуждение данных и вопросов оценки. В конце, Раздел 7 завершает статью.
2. Twitter
Twitter описан в текущем разделе с подробным описанием его соответствующих функций.В Разделе 2.1 объясняется этот сервис микроблогов и его типы данных. В разделе 2.2 подробно обсуждаются препятствия для задач TDT в случае Twitter. Наконец, в разделе 2.3 объясняются и подробно рассматриваются инструменты для работы с большими данными в социальных сетях.
2.1. Служба микроблогов Twitter
Twitter , как одна из крупнейших служб социальных блогов, является пятнадцатым веб-сайтом в мире, а в Соединенных Штатах Америки — девятым, и на него ссылаются более 6 087 240 веб-сайтов (извлечены с веб-сайта Alexa).Его услуги включают размещение коротких текстовых сообщений на онлайн-платформе Twitter, которая также позволяет пользователям отслеживать отправленные короткие сообщения других пользователей по , следуя за ними . Эти короткие сообщения называются твитами, которые могут содержать изображение в формате GIF, короткое текстовое сообщение, содержащее не более 140 символов, включая около смайликов, или только текст, изображение или опрос. Все эти части перечислены как части твита : (1) короткое текстовое сообщение, состоящее из 140 символов или меньше, которое может содержать смайлики (2) изображение (3) GIF, описывающее короткое текстовое сообщение, чувства или что-то еще. else (4) Вопрос опроса с предопределенными ответами (можно использовать только одну из последних трех частей твита )
Twitter позволяет пользователям общаться в своей социальной сети с другими пользователями с помощью этих твитов. Они могут делиться своими идеями, чувствами, вопросами для опросов, фотографиями и всем остальным, что не противоречит его правилам. Твит, опубликованный в Твиттере, по умолчанию виден другим пользователям, если только пользователи не изменят свои настройки конфиденциальности, чтобы сделать его доступным для чтения только списку подписчиков или определенным людям.
Они могут делиться своими идеями, чувствами, вопросами для опросов, фотографиями и всем остальным, что не противоречит его правилам. Твит, опубликованный в Твиттере, по умолчанию виден другим пользователям, если только пользователи не изменят свои настройки конфиденциальности, чтобы сделать его доступным для чтения только списку подписчиков или определенным людям.
A Упоминание или Ответить твит можно, используя символ «@» перед именем пользователя. Эти ответы или упоминания создают более социальную веб-службу, помогая пользователям взаимодействовать и отвечать друг другу.Ретвит — это еще одна функция Twitter, которая позволяет пользователям повторно отправлять или пересылать твиты другого пользователя своим подписчикам. Хэштег — это еще одна функция Twitter, которая помогает пользователям классифицировать свои твиты с помощью знака «#» и слова, относящегося к опубликованному твиту; этот простой стиль ключевых слов помогает находить твиты и категоризировать их, а также используется Twitter для обнаружения тенденций.
Twitter также предоставляет интерфейс прикладного программирования (Twitter API), который позволяет разработчикам и исследователям получать доступ к его потоковым твитам.Эта потоковая передача может быть отфильтрована по местоположению, конкретному ключевому слову, автору и т. Д.
2.2. Вызовы Twitter при обнаружении и отслеживании событий Задача
Twitter как отличный источник информации, описанный в предыдущем разделе, имеет огромные проблемы с поиском информации, которые значительно усложняют задачу обнаружения и отслеживания событий в его растущей социальной сети. Потоки Twitter обычно содержат большое количество твитов-слухов, созданных пользователями или спамерами. Эти басни, вымыслы и, в большинстве случаев, лживые твиты сильно влияют на работу систем обнаружения и отслеживания событий.Другая проблема возникает, когда большинство твитов связано с повседневной жизнью пользователей, то есть об их личной информации и повседневной деятельности. В некоторых случаях, таких как выборы, эти повседневные действия можно использовать для получения хорошей информации, но в случае обнаружения общих событий они не так уж и полезны. Для хорошего детектора событий и системы отслеживания необходимо отделить эту нерегулярную и загрязненную информацию от полезной.
Для хорошего детектора событий и системы отслеживания необходимо отделить эту нерегулярную и загрязненную информацию от полезной.
Сообщения Twitter имеют длину не более 140 символов, что создает еще одну проблему.Эти короткие сообщения должны быть сгруппированы или предварительно обработаны, чтобы получился более длинный поток твитов. Обнаружение и отслеживание событий в длинных документах и ленте новостей намного проще с точки зрения разреженности и нерелевантности документов, чем в случае с услугами коротких блогов, таких как Twitter. Большинство сообщений в Твиттере содержат грамматические ошибки и орфографические ошибки, которые усложняют работу по сравнению с обычной новостной лентой. Twitter, как источник пользовательских данных, в основном содержит множество невидимых слов, которые можно увидеть только в коротких сообщениях.В качестве примера таких слов и сокращений мы можем назвать слово «OMG», что эквивалентно «О, Боже мой»; такие слова часто используются и генерируются пользователями. Пользователи также добавляют к таким словам орфографические ошибки и удлиняют их, что приводит к очень неприятной проблеме.
Пользователи также добавляют к таким словам орфографические ошибки и удлиняют их, что приводит к очень неприятной проблеме.
Все упомянутые проблемы также добавляются к 3-V модели больших данных, в которой генерируется большое количество различных из данных скорости вместе с большим объемом , и их необходимо обрабатывать точно в срок для мониторинга и отслеживается.Эта модель 3-V является гораздо более обобщенной, чем модель 5-V, которая определяется следующим образом: (i) Том обозначает большой объем с точки зрения подсчета данных, которые передаются или генерируются. Обработка, группировка, кластеризация и получение полезной информации из крупномасштабных данных имеют решающее значение в приложениях для поиска информации, а также в случае социальных сетей, подобных Twitter. (Ii) Скорость указывает скорость генерации или передачи данных. Источники потоковых и онлайн-данных, такие как Twitter, обладают этим свойством, при котором приложения для извлечения информации в реальном времени необходимы, чтобы соответствовать такой скорости. (iii) Разновидность называется разницей данных, собранных из источника данных, в котором генерируются и собираются различные типы данных для обработки. В случае Twitter эти данные отличаются, поскольку типы данных, сгенерированные пользователями, относятся к разным темам и событиям. (Iv) Значение описывает процесс извлечения информации из источников больших данных. Он также известен как анализ больших данных, который в случае Twitter отмечается как анализ больших социальных данных . (v) Верность относится к правильности и точности информации, извлеченной из большого источника данных.Он также известен как качество данных [7]. Это качество низкое для некоторых твитов (повседневных твитов, создаваемых пользователями), в то время как оно является высоким для учетных записей ленты новостей Twitter (например, учетной записи Twitter, связанной с новостным каналом, которая публикует только насыщенные твиты о реальных событиях).
(iii) Разновидность называется разницей данных, собранных из источника данных, в котором генерируются и собираются различные типы данных для обработки. В случае Twitter эти данные отличаются, поскольку типы данных, сгенерированные пользователями, относятся к разным темам и событиям. (Iv) Значение описывает процесс извлечения информации из источников больших данных. Он также известен как анализ больших данных, который в случае Twitter отмечается как анализ больших социальных данных . (v) Верность относится к правильности и точности информации, извлеченной из большого источника данных.Он также известен как качество данных [7]. Это качество низкое для некоторых твитов (повседневных твитов, создаваемых пользователями), в то время как оно является высоким для учетных записей ленты новостей Twitter (например, учетной записи Twitter, связанной с новостным каналом, которая публикует только насыщенные твиты о реальных событиях).
2.3. Социальные инструменты для больших данных
Многие инструменты для различных приложений анализа больших социальных данных, хранения, систем баз данных, кластерных вычислений, веб-сканера, интеграции данных, параллельного потока данных и сложной обработки событий представлены разными компаниями. Эти инструменты тривиальны для современного анализа больших данных и, конечно же, для анализа данных Twitter. Некоторые методологии в этом обзоре используют некоторые из этих инструментов, а другие — нет: (1) Lucene — это бесплатная Java-библиотека для извлечения информации с открытым исходным кодом, которая была перенесена на другие языки программирования, такие как PHP, C #, C ++, Python, и Руби. Индексирование, поиск и рекомендации — другие возможности этого инструмента. У него есть собственный синтаксис мини-запросов, который легко понять, и его природа помогает исследователям и индустрии поиска информации использовать его в качестве бесплатного инструмента Apache с открытым исходным кодом [8, 9].(2) Apache Storm — еще одна бесплатная вычислительная система реального времени с открытым исходным кодом. Он может надежно обрабатывать неограниченные потоки данных для приложений реального времени. Он прост и может использоваться с любым языком программирования [10]. (3) Базы данных NoSQL , такие как MongoDB, предназначены для хранения и извлечения любых данных со свойствами больших данных в больших масштабах.
Эти инструменты тривиальны для современного анализа больших данных и, конечно же, для анализа данных Twitter. Некоторые методологии в этом обзоре используют некоторые из этих инструментов, а другие — нет: (1) Lucene — это бесплатная Java-библиотека для извлечения информации с открытым исходным кодом, которая была перенесена на другие языки программирования, такие как PHP, C #, C ++, Python, и Руби. Индексирование, поиск и рекомендации — другие возможности этого инструмента. У него есть собственный синтаксис мини-запросов, который легко понять, и его природа помогает исследователям и индустрии поиска информации использовать его в качестве бесплатного инструмента Apache с открытым исходным кодом [8, 9].(2) Apache Storm — еще одна бесплатная вычислительная система реального времени с открытым исходным кодом. Он может надежно обрабатывать неограниченные потоки данных для приложений реального времени. Он прост и может использоваться с любым языком программирования [10]. (3) Базы данных NoSQL , такие как MongoDB, предназначены для хранения и извлечения любых данных со свойствами больших данных в больших масштабах. Для хранения и поиска социальных данных требуются базы данных NoSQL для выполнения вычислительных задач [11].
Для хранения и поиска социальных данных требуются базы данных NoSQL для выполнения вычислительных задач [11].
В этой конкретной работе можно использовать другие инструменты и языки программирования, но основные свойства больших социальных данных требуют использования описанных инструментов в качестве их относительности.
3. Категоризация методов
Существующие методы обнаружения и отслеживания событий в Twitter можно классифицировать по-разному, исходя из различных точек зрения. Одна из этих категорий различает методы, которые обнаруживают только , и методы, которые обнаруживают и отслеживают события . Некоторые из существующих методов только обнаруживают, тогда как другие отслеживают обнаруженные события и создают сюжетную линию обнаруженных тем на основе временной шкалы твитов. Первый также известен как тематический детектор , а другой, осознающий важность отслеживания, — это детектор событий и трекер , соответственно, сокращенно TD и EDT .
Другая категоризация возникает, когда разные методы используют разные источники данных Twitter. Некоторые используют офлайн-наборы данных для обнаружения и / или отслеживания, в то время как другие используют онлайн-API Twitter. Это различие сбора данных для обучающей и тестовой частей алгоритмов вызывает ошибку сравнения при сравнении производительности и точности результатов существующих методов.
Две другие категории для обнаружения и отслеживания событий известны как ретроспективное обнаружение событий и обнаружение новых событий.Эти два сокращенно обозначаются как RED и NED . Основная цель RED — обнаружение ранее неопознанных событий из автономных наборов данных и документов, в то время как NED сосредоточен на обнаружении новых событий в онлайн-потоках данных. Для задач TDT эти две концепции широко исследуются, и для выполнения этой задачи было опубликовано множество исследовательских статей. С точки зрения Twitter, алгоритм обнаружения событий может быть NED или RED. Алгоритмы итерационной кластеризации, такие как k -means, являются обычной практикой в категории RED.Во-первых, документ, предложение или короткий твит выбирается в качестве объекта, а другие объекты сравниваются с первым; если он достаточно близок с точки зрения расстояния в векторном пространстве, то оба объединяются в более крупный кластер; в противном случае создается новый кластер, и этот объект присваивается этому новому кластеру. Этот процесс продолжается до тех пор, пока не будут завершены все объекты (документы / предложения / твиты). В отличие от RED, NED не имеет начального запроса или кластера; таким образом, он должен обеспечивать некоторые правила принятия решения между новыми и старыми событиями.Метрика TF-IDF используется в некоторых практиках для сравнения новых и старых потоков. В некоторых случаях атрибут времени также добавляется к закрытым кластерам по прошествии определенного времени; например, по истечении трех дней в этот конкретный кластер больше не добавляются твиты.
Алгоритмы итерационной кластеризации, такие как k -means, являются обычной практикой в категории RED.Во-первых, документ, предложение или короткий твит выбирается в качестве объекта, а другие объекты сравниваются с первым; если он достаточно близок с точки зрения расстояния в векторном пространстве, то оба объединяются в более крупный кластер; в противном случае создается новый кластер, и этот объект присваивается этому новому кластеру. Этот процесс продолжается до тех пор, пока не будут завершены все объекты (документы / предложения / твиты). В отличие от RED, NED не имеет начального запроса или кластера; таким образом, он должен обеспечивать некоторые правила принятия решения между новыми и старыми событиями.Метрика TF-IDF используется в некоторых практиках для сравнения новых и старых потоков. В некоторых случаях атрибут времени также добавляется к закрытым кластерам по прошествии определенного времени; например, по истечении трех дней в этот конкретный кластер больше не добавляются твиты.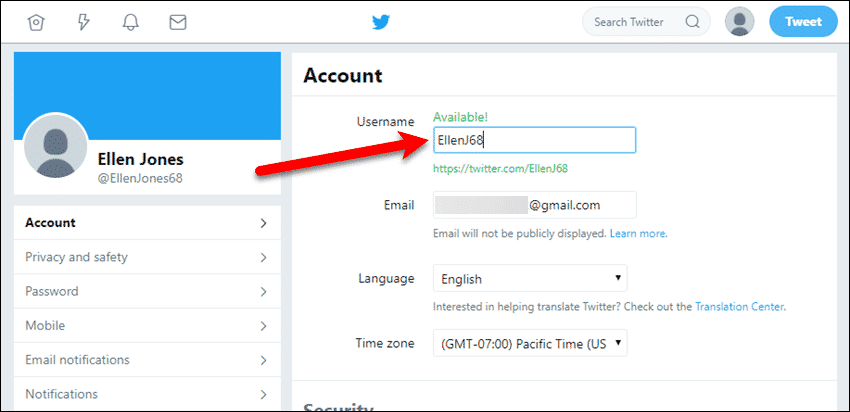
«Новые» и «ретроспективные» термины относятся к методам разворота документа , в которых разрабатываются алгоритмы для исследования текстовых свойств связанных объектов. Эти методы нацелены на предоставление некоторых показателей для вычисления сходства объектов на основе их текстовых и лингвистических свойств.
Находясь в противоречии с методами поворота документа, методы поворота функций и нацелены на обнаружение быстрорастущих свойств в потоке обнаружения. Эта так называемая всплеск активности с возрастающей частотой описывает случайность нового события. Например, может быть, огромный рост частоты использования хэштегов в Twitter связан с новым событием, которое происходит или произошло недавно.
Некоторые методы обнаружения и отслеживания событий Twitter используют заранее заданную информацию об интересах пользователей или администраторов.Эти методы известны как детекторы определенных событий. Некоторые другие методы не нуждаются в какой-либо информации о событиях, которые необходимо отслеживать и обнаруживать, и находят реальные вхождения, темы и события по их свойствам с точки зрения выбора частоты или с точки зрения сходства. Эти две различные методологии известны как системы обнаружения и отслеживания заданного события и неуказанного события .
Эти две различные методологии известны как системы обнаружения и отслеживания заданного события и неуказанного события .
Как описано в этом разделе, для систем детекторов событий нарисовано множество категорий; в этих классификациях отсутствует основная методологическая часть алгоритмов.Раздел 5.1 описывает новую категоризацию и объясняет существующие методы в рамках этой категоризации. Таблица 1 показывает список методологий, которые изучаются в этой рукописи.
| |||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
 Эта задача включает в себя такие части, как нормализация данных, удаление зашумленных данных и исправление. Задачи НЛП требуют грамматически правильного текста с определенными свойствами. Предварительная обработка — одна из основных частей подзадач анализа больших социальных данных. Короткие твиты, передаваемые через службу Twitter, как описано выше, должны быть обработаны, чтобы быть готовыми к дальнейшим вычислениям обнаружения событий.Удаление стоп-слов и знаков препинания является важным шагом в предварительной обработке задач интеллектуального анализа данных, связанных с обработкой естественного языка [38]. Также необходима идентификация URL-адресов и смайлов. Регулярные выражения могут использоваться для обнаружения URL-адресов в коротких сообщениях.
Эта задача включает в себя такие части, как нормализация данных, удаление зашумленных данных и исправление. Задачи НЛП требуют грамматически правильного текста с определенными свойствами. Предварительная обработка — одна из основных частей подзадач анализа больших социальных данных. Короткие твиты, передаваемые через службу Twitter, как описано выше, должны быть обработаны, чтобы быть готовыми к дальнейшим вычислениям обнаружения событий.Удаление стоп-слов и знаков препинания является важным шагом в предварительной обработке задач интеллектуального анализа данных, связанных с обработкой естественного языка [38]. Также необходима идентификация URL-адресов и смайлов. Регулярные выражения могут использоваться для обнаружения URL-адресов в коротких сообщениях. Токенизация — это еще одна часть предварительной обработки, которая присваивает уникальные токены каждому слову в твите. Эта часть предварительной обработки более важна в моделях, связанных с TF-IDF (Term Frequency-Inverse Document Frequency).
Токенизация — это еще одна часть предварительной обработки, которая присваивает уникальные токены каждому слову в твите. Эта часть предварительной обработки более важна в моделях, связанных с TF-IDF (Term Frequency-Inverse Document Frequency). Иногда эти бесполезные наборы символов кажутся полезными (в случае кодирования и важной информации, связанной с данными). Пробелы и знаки препинания, которые также называются пробелами, должны быть отсортированы.Примером таких случаев является кандидатов наук. с неоднозначным окончанием предложения; другой пример — $ 5,79 .
Иногда эти бесполезные наборы символов кажутся полезными (в случае кодирования и важной информации, связанной с данными). Пробелы и знаки препинания, которые также называются пробелами, должны быть отсортированы.Примером таких случаев является кандидатов наук. с неоднозначным окончанием предложения; другой пример — $ 5,79 .
 Частота документа с обратной частотой термина, сокращенно обозначаемая как, является общей метрикой среди большинства методов обнаружения или извлечения тем и описывается как (1) и (2).Соответственно, и в этих уравнениях относятся к термину и документу, которые в последнем случае можно рассматривать как единый документ, содержащий более одного твита, возможно, пару твитов или только один твит, который также может называться сообщением. Кроме того, представляет подсчет вхождений термина в документ / сообщение, а означает подсчет документов / сообщений, которые имеют по крайней мере одно вхождение.
Частота документа с обратной частотой термина, сокращенно обозначаемая как, является общей метрикой среди большинства методов обнаружения или извлечения тем и описывается как (1) и (2).Соответственно, и в этих уравнениях относятся к термину и документу, которые в последнем случае можно рассматривать как единый документ, содержащий более одного твита, возможно, пару твитов или только один твит, который также может называться сообщением. Кроме того, представляет подсчет вхождений термина в документ / сообщение, а означает подсчет документов / сообщений, которые имеют по крайней мере одно вхождение.
 Если этот коэффициент установлен на 1,5, тогда модель n-грамм содержит именованный объект; в противном случае это небольшое число, и соответствующая модель не содержит именованного объекта.На основе n -грамм TF-IDF все твиты оцениваются и на основе этих оценок затем группируются в соответствующие кластеры. Этот процесс оценки и кластеризации выполняется во временных окнах, и на каждом временном шаге твиты, относящиеся к временному окну, сравниваются с другими, которые были опубликованы ранее. Предлагаемый метод был обучен на некоторых специально подобранных наборах данных, собранных из Twitter API, которые были связаны со спортом (Чемпионат мира по крикету 2015 г.), медициной («Свиной грипп» 2015 г.) и счетами (Закон о приобретении земли).По сравнению с частыми методами исследования паттернов этот метод кажется более простым алгоритмом с точки зрения программной реализации с хорошими результатами с точки зрения выходных тем в некоторых случаях, которые постыдно не выражаются как F-мера, точность, отзыв или какие-либо связанные показатели.
Если этот коэффициент установлен на 1,5, тогда модель n-грамм содержит именованный объект; в противном случае это небольшое число, и соответствующая модель не содержит именованного объекта.На основе n -грамм TF-IDF все твиты оцениваются и на основе этих оценок затем группируются в соответствующие кластеры. Этот процесс оценки и кластеризации выполняется во временных окнах, и на каждом временном шаге твиты, относящиеся к временному окну, сравниваются с другими, которые были опубликованы ранее. Предлагаемый метод был обучен на некоторых специально подобранных наборах данных, собранных из Twitter API, которые были связаны со спортом (Чемпионат мира по крикету 2015 г.), медициной («Свиной грипп» 2015 г.) и счетами (Закон о приобретении земли).По сравнению с частыми методами исследования паттернов этот метод кажется более простым алгоритмом с точки зрения программной реализации с хорошими результатами с точки зрения выходных тем в некоторых случаях, которые постыдно не выражаются как F-мера, точность, отзыв или какие-либо связанные показатели. Единственный инструмент для работы с большими данными в социальных сетях, который использует этот метод, — это Lucene для индексации ключевых слов.
Единственный инструмент для работы с большими данными в социальных сетях, который использует этот метод, — это Lucene для индексации ключевых слов. Это моделирование векторного пространства между твитами и страницами Википедии проверяет следующее: если происходит какое-либо новое событие, оно отражается как выбор просмотров страниц пользователя в Википедии; если это было ложное срабатывание, выбор на странице, связанной с Википедией, не происходит.
Это моделирование векторного пространства между твитами и страницами Википедии проверяет следующее: если происходит какое-либо новое событие, оно отражается как выбор просмотров страниц пользователя в Википедии; если это было ложное срабатывание, выбор на странице, связанной с Википедией, не происходит. Сходство твита с предыдущими показывает, новый он или нет, и эта задача помогает предлагаемой системе открыть новую историю или оставить ее такой, какой она была.
Сходство твита с предыдущими показывает, новый он или нет, и эта задача помогает предлагаемой системе открыть новую историю или оставить ее такой, какой она была. Один из этих подходов, представленный в [23], использует наивный байесовский классификатор, называемый NB-Text, для удовлетворения этого требования. Этому вероятностному методу обучено более 2600000 сообщений Twitter, аннотированных людьми и опубликованных в 2010 году.Этот набор данных помечен для этапов обучения и тестирования. Во-первых, классификатор под названием RW-Tweet обучен различать события реального и нереального мира. Инструментарий Weka [43] вместе с извлеченными функциями уровня кластера используется для обучения модели классификации. Этот наивный байесовский классификатор обрабатывает все сообщения в кластере как единый документ и использует метрику TF-IDF как функции. В этом классификаторе используются функции событий на уровне кластера, такие как временные, социальные, центральные и тематические функции Twitter.
Один из этих подходов, представленный в [23], использует наивный байесовский классификатор, называемый NB-Text, для удовлетворения этого требования. Этому вероятностному методу обучено более 2600000 сообщений Twitter, аннотированных людьми и опубликованных в 2010 году.Этот набор данных помечен для этапов обучения и тестирования. Во-первых, классификатор под названием RW-Tweet обучен различать события реального и нереального мира. Инструментарий Weka [43] вместе с извлеченными функциями уровня кластера используется для обучения модели классификации. Этот наивный байесовский классификатор обрабатывает все сообщения в кластере как единый документ и использует метрику TF-IDF как функции. В этом классификаторе используются функции событий на уровне кластера, такие как временные, социальные, центральные и тематические функции Twitter. Шум, по мнению авторов, — это кластеры, не относящиеся к реальным событиям; таким образом, вместо обычных пользователей используются надежные источники новостей в качестве семян, что ослабляет эту систему. Это предположение верно, когда источники новостей публикуют новости в режиме реального времени, но природа социальных сетей доказала, что пользователи — это реальные люди, которые оказались участниками события или бедствия.С другой стороны, фрагментация относится к повторяющимся кластерам, которые означают одно и то же событие. Периодическая проверка повторяющихся кластеров решает эту проблему в системе. Геолокация событий этой системы делает ее сильнее и полезнее.
Шум, по мнению авторов, — это кластеры, не относящиеся к реальным событиям; таким образом, вместо обычных пользователей используются надежные источники новостей в качестве семян, что ослабляет эту систему. Это предположение верно, когда источники новостей публикуют новости в режиме реального времени, но природа социальных сетей доказала, что пользователи — это реальные люди, которые оказались участниками события или бедствия.С другой стороны, фрагментация относится к повторяющимся кластерам, которые означают одно и то же событие. Периодическая проверка повторяющихся кластеров решает эту проблему в системе. Геолокация событий этой системы делает ее сильнее и полезнее. Это отношение может быть определено между объектами и их атрибутами. Экстент : если мы видим A как набор объектов (набор элементов), то он называется экстентом Намерение : если B является набором всех атрибутов набора A, то оно называется намерением
Это отношение может быть определено между объектами и их атрибутами. Экстент : если мы видим A как набор объектов (набор элементов), то он называется экстентом Намерение : если B является набором всех атрибутов набора A, то оно называется намерением Некоторые из этих концепций отбрасываются, чтобы иметь лучшую тему. С помощью этой методологии можно вычислить небольшую решетку понятий и термины, в то время как больший размер корпуса и твитов и огромное количество терминов приводят к огромной решетке.В таком случае требуется стратегия выбора термина, чтобы сузить эту проблему. Большинство стратегий выбора общих атрибутов отбрасывают наименьшее количество общих атрибутов (терминов). Эта сбалансированная версия алгоритма использует периодичность каждого атрибута. Этот термин «частота» показывает порог выбора, какой термин следует использовать в решетке понятий. На каждой итерации выбираются термины с наивысшим значением, а объекты (твиты) с менее чем двумя терминами в своих атрибутах отбрасываются. Последняя итерация этой тонко настроенной стратегии выводит атрибуты с наивысшим значением и объекты, которые ими обладают.Последний шаг этой структуры — фактически создавать темы из этих решеток. Однако предыдущий шаг сократил потенциальные решетки понятий, чтобы стать кандидатами на окончательную тему.
Некоторые из этих концепций отбрасываются, чтобы иметь лучшую тему. С помощью этой методологии можно вычислить небольшую решетку понятий и термины, в то время как больший размер корпуса и твитов и огромное количество терминов приводят к огромной решетке.В таком случае требуется стратегия выбора термина, чтобы сузить эту проблему. Большинство стратегий выбора общих атрибутов отбрасывают наименьшее количество общих атрибутов (терминов). Эта сбалансированная версия алгоритма использует периодичность каждого атрибута. Этот термин «частота» показывает порог выбора, какой термин следует использовать в решетке понятий. На каждой итерации выбираются термины с наивысшим значением, а объекты (твиты) с менее чем двумя терминами в своих атрибутах отбрасываются. Последняя итерация этой тонко настроенной стратегии выводит атрибуты с наивысшим значением и объекты, которые ими обладают.Последний шаг этой структуры — фактически создавать темы из этих решеток. Однако предыдущий шаг сократил потенциальные решетки понятий, чтобы стать кандидатами на окончательную тему. Концепция стабильности, которая была ранее предложена в [45], показывает, насколько намерение концепции зависит от объектов, доступных в степени. Это сокращение при сохранении стабильности помогает сформировать тему.
Концепция стабильности, которая была ранее предложена в [45], показывает, насколько намерение концепции зависит от объектов, доступных в степени. Это сокращение при сохранении стабильности помогает сформировать тему. Три фазы выделения темы в этом методе — это выбор термина, формирование вектора совпадения и постобработка. Первый этап указывает на то, что вероятность появления терминов в корпусе является серьезной проблемой. Вероятность, такая как полученная на этом этапе, и между новым корпусом и этим эталонным корпусом, эта вероятность сравнивается с отношением. Это соотношение является показателем, показывающим, как меняется частота термина.Более высокое соотношение означает более высокую частоту появления, и, следовательно, этот термин может появиться в последней теме. Конструкции и матрицы следующей фазы, которые позже используются для частого анализа паттернов. Матрица показывает, сколько терминов встречается в нескольких документах, а сколько раз термин встречается в нескольких документах. Косинусное сходство между этими двумя матрицами показывает, насколько термин подходит для добавления к последней теме. Сигмовидная функция используется для ограничения этого сходства и действует как порог.
Три фазы выделения темы в этом методе — это выбор термина, формирование вектора совпадения и постобработка. Первый этап указывает на то, что вероятность появления терминов в корпусе является серьезной проблемой. Вероятность, такая как полученная на этом этапе, и между новым корпусом и этим эталонным корпусом, эта вероятность сравнивается с отношением. Это соотношение является показателем, показывающим, как меняется частота термина.Более высокое соотношение означает более высокую частоту появления, и, следовательно, этот термин может появиться в последней теме. Конструкции и матрицы следующей фазы, которые позже используются для частого анализа паттернов. Матрица показывает, сколько терминов встречается в нескольких документах, а сколько раз термин встречается в нескольких документах. Косинусное сходство между этими двумя матрицами показывает, насколько термин подходит для добавления к последней теме. Сигмовидная функция используется для ограничения этого сходства и действует как порог. Заключительный этап этого алгоритма — этап очистки для удаления повторяющихся тем.
Заключительный этап этого алгоритма — этап очистки для удаления повторяющихся тем. . Макро- и микровсплески определены ниже как основные составляющие этой работы.
. Макро- и микровсплески определены ниже как основные составляющие этой работы. Их можно назвать как если / тогда (антецедент / последствие) шаблонами с помощью поддержки критериев для определения самых сильных и наиболее важных связей между элементами данных. В [18] два основных уравнения используются для сопоставления правил с точки зрения их подобия; они взяты из [48]. Новые правила как вклад в эту работу предлагаются для выявления последних новостей.Набор данных US Elections использовался для оценки предложенной методологии, которая показывает хорошие результаты с точки зрения F-меры, отзыва и точности.
Их можно назвать как если / тогда (антецедент / последствие) шаблонами с помощью поддержки критериев для определения самых сильных и наиболее важных связей между элементами данных. В [18] два основных уравнения используются для сопоставления правил с точки зрения их подобия; они взяты из [48]. Новые правила как вклад в эту работу предлагаются для выявления последних новостей.Набор данных US Elections использовался для оценки предложенной методологии, которая показывает хорошие результаты с точки зрения F-меры, отзыва и точности.
 Эти спецификации побудили авторов [49] разделить все характеристики на четыре основных типа: HH, HL, LH и LL (первая буква показывает доминирующий спектр мощности, а вторая буква указывает доминирующий период, в котором H означает высокий и L означает низкий). Обнаружение периодических всплесков признаков осуществляется с помощью гауссовой смеси.
Эти спецификации побудили авторов [49] разделить все характеристики на четыре основных типа: HH, HL, LH и LL (первая буква показывает доминирующий спектр мощности, а вторая буква указывает доминирующий период, в котором H означает высокий и L означает низкий). Обнаружение периодических всплесков признаков осуществляется с помощью гауссовой смеси. Вычисленное значение для гипотез n -грамм дает ясное представление о правильности нулевой гипотезы, которая утверждается, что « два отдельных набора текстовых данных , из двух временных рамок генерируются из одного источника .Из-за большого разнообразия n -грамм также предлагается дерево суффиксов для хранения n -грамм. Вычисленная частота сохраняется в этой новой структуре данных, а другой алгоритм проходит по дереву для вычисления и сохранения значений вместе с ним.
Вычисленное значение для гипотез n -грамм дает ясное представление о правильности нулевой гипотезы, которая утверждается, что « два отдельных набора текстовых данных , из двух временных рамок генерируются из одного источника .Из-за большого разнообразия n -грамм также предлагается дерево суффиксов для хранения n -грамм. Вычисленная частота сохраняется в этой новой структуре данных, а другой алгоритм проходит по дереву для вычисления и сохранения значений вместе с ним.
 Эта методология кластеризации подходит для обнаружения преобразованного сигнала. Модульная разреженная матрица формируется на последнем этапе этой работы для обнаружения событий путем кластеризации взвешенной матрицы. Эта матрица называется и имеет вид, в котором вершины, ребра и веса графа.
Эта методология кластеризации подходит для обнаружения преобразованного сигнала. Модульная разреженная матрица формируется на последнем этапе этой работы для обнаружения событий путем кластеризации взвешенной матрицы. Эта матрица называется и имеет вид, в котором вершины, ребра и веса графа. В [25] предлагается схема обнаружения пространственно-временных событий; он обнаруживает события, а также время их возникновения, а также геолокацию.Перед дальнейшим описанием алгоритма необходимо знать некоторые определения; эти определения пространственно-временного события и статьи .
В [25] предлагается схема обнаружения пространственно-временных событий; он обнаруживает события, а также время их возникновения, а также геолокацию.Перед дальнейшим описанием алгоритма необходимо знать некоторые определения; эти определения пространственно-временного события и статьи . Со всеми этими настройками мы можем погрузиться в концепцию этикетки . Метка твита, как известно, состоит из троек, где обозначает событие, указывает связанные твиты и выражает несвязанные твиты. Создание ярлыков — это задача классификации ярлыков определенной темы, которые также связаны / не связаны с событием.После завершения этого шага следующим шагом предлагаемой работы является обнаружение пространственно-временных событий. На этом последнем шаге вводится набор меток для конкретной темы, полученный на предыдущем шаге, и поток Twitter в реальном времени, а также выводятся наборы сетевых событий целевого домена, которые происходят или произошли в определенном месте в определенное время.
Со всеми этими настройками мы можем погрузиться в концепцию этикетки . Метка твита, как известно, состоит из троек, где обозначает событие, указывает связанные твиты и выражает несвязанные твиты. Создание ярлыков — это задача классификации ярлыков определенной темы, которые также связаны / не связаны с событием.После завершения этого шага следующим шагом предлагаемой работы является обнаружение пространственно-временных событий. На этом последнем шаге вводится набор меток для конкретной темы, полученный на предыдущем шаге, и поток Twitter в реальном времени, а также выводятся наборы сетевых событий целевого домена, которые происходят или произошли в определенном месте в определенное время. Оценка местоположения события — последний шаг этой схемы для оценки фактического местоположения классифицированных твитов.
Оценка местоположения события — последний шаг этой схемы для оценки фактического местоположения классифицированных твитов.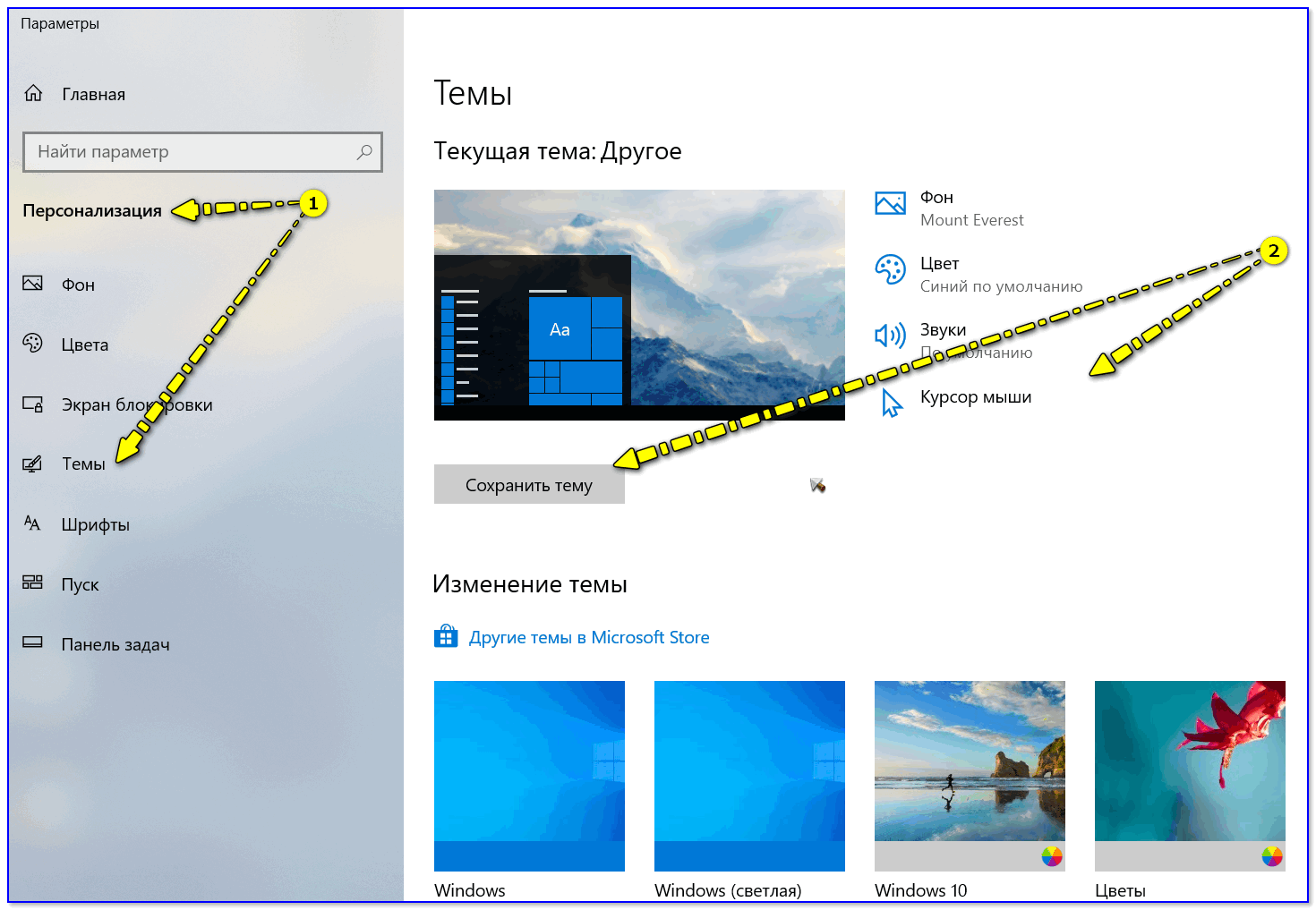 Последний этап этой схемы использует функции, связанные с контентом, пользователем и использованием, для ранжирования обнаруженных событий, в то время как предыдущий этап сосредоточен на угадывании местоположения пользователя. Первое предположение состоит в том, что местоположение пользователя указано в его твитах с GPS-тегами, если таковые имеются; в противном случае его / ее друзья, скорее всего, будут рядом с ним. Последнее предположение гласит, что его / ее местонахождение хотя бы раз упоминается в его твитах. Одна из основных проблем такого угадывания местоположения заключается в том, что в случае второго и третьего предположений извлеченная информация может быть ложной.
Последний этап этой схемы использует функции, связанные с контентом, пользователем и использованием, для ранжирования обнаруженных событий, в то время как предыдущий этап сосредоточен на угадывании местоположения пользователя. Первое предположение состоит в том, что местоположение пользователя указано в его твитах с GPS-тегами, если таковые имеются; в противном случае его / ее друзья, скорее всего, будут рядом с ним. Последнее предположение гласит, что его / ее местонахождение хотя бы раз упоминается в его твитах. Одна из основных проблем такого угадывания местоположения заключается в том, что в случае второго и третьего предположений извлеченная информация может быть ложной. Известно, что каждый твит представляет собой сенсорную ценность, и пользователи являются датчиками этой схемы.Они пишут о событии в Твиттере, что означает, что они являются датчиками, а полученные значения публикуются в виде твитов. Этот отчет полезен для обнаружения реальных бедствий, таких как землетрясения. Настоящая проблема этого предположения состоит в том, что существует вероятность ошибки, когда пользователь публикует нерелевантные твиты, которые кажутся актуальными; Примером этого, по мнению авторов, может быть этот твит: «Мой босс кому-то пожимает руку!» В этом твите в качестве основного ключевого слова используется тряска, но это не означает, что Земля трясется.Остальные особенности предыдущей части снижают вероятность ошибки, но вероятность все же есть. Для уточнения предположений предлагаются две пространственные и временные модели. Эти модели полагаются на отметку времени твита и отметку GPS. Результаты оценки и экспериментов показывают, что система показывает точность более 60 процентов по двум связанным запросам.
Известно, что каждый твит представляет собой сенсорную ценность, и пользователи являются датчиками этой схемы.Они пишут о событии в Твиттере, что означает, что они являются датчиками, а полученные значения публикуются в виде твитов. Этот отчет полезен для обнаружения реальных бедствий, таких как землетрясения. Настоящая проблема этого предположения состоит в том, что существует вероятность ошибки, когда пользователь публикует нерелевантные твиты, которые кажутся актуальными; Примером этого, по мнению авторов, может быть этот твит: «Мой босс кому-то пожимает руку!» В этом твите в качестве основного ключевого слова используется тряска, но это не означает, что Земля трясется.Остальные особенности предыдущей части снижают вероятность ошибки, но вероятность все же есть. Для уточнения предположений предлагаются две пространственные и временные модели. Эти модели полагаются на отметку времени твита и отметку GPS. Результаты оценки и экспериментов показывают, что система показывает точность более 60 процентов по двум связанным запросам. Эта ценная система используется в Японии в качестве системы предупреждения о землетрясениях, которая со временем может спасти жизни нескольких человек.
Эта ценная система используется в Японии в качестве системы предупреждения о землетрясениях, которая со временем может спасти жизни нескольких человек. Эта система превосходит современные методы для трех разных наборов данных и является одним из первых методов, которые использовали Transformers для обнаружения и отслеживания тем из Twitter.
Эта система превосходит современные методы для трех разных наборов данных и является одним из первых методов, которые использовали Transformers для обнаружения и отслеживания тем из Twitter. Авторы сообщают о своих результатах в наборе данных Berita, который представляет собой набор индонезийских новостей из Twitter.
Авторы сообщают о своих результатах в наборе данных Berita, который представляет собой набор индонезийских новостей из Twitter.
 Весь процесс этого алгоритма может выполняться параллельно на выделенном графическом процессоре, что дает ему большую вычислительную мощность, чем обычные процессоры, и больше подходит для вычисления задачи TDT в реальном времени, потому что другие алгоритмы слабы в этом аспекте, и большинство из них применимо к автономным наборам данных.
Весь процесс этого алгоритма может выполняться параллельно на выделенном графическом процессоре, что дает ему большую вычислительную мощность, чем обычные процессоры, и больше подходит для вычисления задачи TDT в реальном времени, потому что другие алгоритмы слабы в этом аспекте, и большинство из них применимо к автономным наборам данных. Глубокое обучение, как следует из его названия, позволяет вычислительным моделям иметь множество уровней абстракции для представления данных [54]. Создание унифицированных архитектур многослойных нейронных сетей для задач НЛП кажется многообещающей методологией для решения многих нерешенных проблем в этой области [55], в то время как вложения слов, такие как GloVe [56] и Word2Vec [57], предлагают новое векторное представление слов, которые также обладают сентиментальное свойство выделенных слов и может применяться в терминах матричного исчисления.
Глубокое обучение, как следует из его названия, позволяет вычислительным моделям иметь множество уровней абстракции для представления данных [54]. Создание унифицированных архитектур многослойных нейронных сетей для задач НЛП кажется многообещающей методологией для решения многих нерешенных проблем в этой области [55], в то время как вложения слов, такие как GloVe [56] и Word2Vec [57], предлагают новое векторное представление слов, которые также обладают сентиментальное свойство выделенных слов и может применяться в терминах матричного исчисления.

 2.1. Обнаружение неопределенных событий
2.1. Обнаружение неопределенных событий StreamListener прослушивает поток данных Twitter API и обнаруживает прерывистые ключевые слова; эти ключевые слова затем группируются и вместе с индексом передаются в модуль анализа тенденций.Все описанные шаги образуют внутреннюю часть системы, в то время как пользовательский интерфейс суммирует всю информацию и представляет ее пользователю. Другие реализации, такие как AllTop, Radian6, Scout Lab, Sysomos, Thoora и TwitScoop, имеют пользовательский интерфейс для представления информации, собранной из различных социальных сетей, новостной ленты и других линий потоков данных, для внешнего пользователя.
StreamListener прослушивает поток данных Twitter API и обнаруживает прерывистые ключевые слова; эти ключевые слова затем группируются и вместе с индексом передаются в модуль анализа тенденций.Все описанные шаги образуют внутреннюю часть системы, в то время как пользовательский интерфейс суммирует всю информацию и представляет ее пользователю. Другие реализации, такие как AllTop, Radian6, Scout Lab, Sysomos, Thoora и TwitScoop, имеют пользовательский интерфейс для представления информации, собранной из различных социальных сетей, новостной ленты и других линий потоков данных, для внешнего пользователя.
 Авторы предложили три модели для этой задачи: прямую модель, двухступенчатую модель конвейера и двухступенчатую смешанную модель. Прямая модель оценивает событие на основе алгоритма на основе регрессии машинного обучения, двухэтапная конвейерная модель обнаруживает события из моментального снимка, а затем оценивает их на основе разногласий, а мягкая модель описанной является двухэтапной смешанной моделью.Основными классами функций, используемыми этой системой, являются функции, основанные на новостях Twitter, а также новости и полемика в сети. Эта система представляет собой интеллектуальный анализ негативного мнения пользователей, а не систему обнаружения событий, хотя она по-прежнему обнаруживает события на основе запроса сущности.
Авторы предложили три модели для этой задачи: прямую модель, двухступенчатую модель конвейера и двухступенчатую смешанную модель. Прямая модель оценивает событие на основе алгоритма на основе регрессии машинного обучения, двухэтапная конвейерная модель обнаруживает события из моментального снимка, а затем оценивает их на основе разногласий, а мягкая модель описанной является двухэтапной смешанной моделью.Основными классами функций, используемыми этой системой, являются функции, основанные на новостях Twitter, а также новости и полемика в сети. Эта система представляет собой интеллектуальный анализ негативного мнения пользователей, а не систему обнаружения событий, хотя она по-прежнему обнаруживает события на основе запроса сущности.
 Как было описано ранее, NED — это термин, используемый для идентификации новых систем обнаружения событий, которые, в отличие от RED (ретроспективное обнаружение событий), обнаруживают и идентифицируют новые события, в то время как последняя обнаруживает и идентифицирует определенные события.Неконтролируемые методы настоятельно рекомендуются для задач, требующих кластеризации неизвестных категорий, которые точно соответствуют домену NED. Кроме того, отсутствует предварительная информация о количестве классов, которые следует классифицировать, из-за динамического характера действий пользователей в социальных сетях.
Как было описано ранее, NED — это термин, используемый для идентификации новых систем обнаружения событий, которые, в отличие от RED (ретроспективное обнаружение событий), обнаруживают и идентифицируют новые события, в то время как последняя обнаруживает и идентифицирует определенные события.Неконтролируемые методы настоятельно рекомендуются для задач, требующих кластеризации неизвестных категорий, которые точно соответствуют домену NED. Кроме того, отсутствует предварительная информация о количестве классов, которые следует классифицировать, из-за динамического характера действий пользователей в социальных сетях. Систему, предназначенную для поиска и отслеживания реальных инцидентов, нельзя обучать под наблюдением; Это связано с неизвестными событиями, которые еще не наступили, и отсутствием информации об их количестве и сущности.
Систему, предназначенную для поиска и отслеживания реальных инцидентов, нельзя обучать под наблюдением; Это связано с неизвестными событиями, которые еще не наступили, и отсутствием информации об их количестве и сущности. Предположим, что два алгоритма или системы, такие как и, имеют одинаковую точность и отзыв при обнаружении событий и отслеживании их на снимке данных Twitter, но имеют разное время обнаружения.Время обнаружения определяется как время, которое требуется типичному алгоритму для обнаружения и идентификации событий и их отслеживания. Если эти времена (что связано с временной сложностью) одинаковы, мы можем предположить, что оба алгоритма одинаковы, но в случае разного времени следует использовать алгоритм, близкий к реальному времени, и предпочтение следует отдавать. Эта метрика не указана ни в одной из работ, которые были изучены в этой рукописи, но кажется важным шагом для определения системы обнаружения и отслеживания событий в реальном времени.В случае офлайн-систем этот показатель не важен.
Предположим, что два алгоритма или системы, такие как и, имеют одинаковую точность и отзыв при обнаружении событий и отслеживании их на снимке данных Twitter, но имеют разное время обнаружения.Время обнаружения определяется как время, которое требуется типичному алгоритму для обнаружения и идентификации событий и их отслеживания. Если эти времена (что связано с временной сложностью) одинаковы, мы можем предположить, что оба алгоритма одинаковы, но в случае разного времени следует использовать алгоритм, близкий к реальному времени, и предпочтение следует отдавать. Эта метрика не указана ни в одной из работ, которые были изучены в этой рукописи, но кажется важным шагом для определения системы обнаружения и отслеживания событий в реальном времени.В случае офлайн-систем этот показатель не важен. В конкурсе приняли участие крупные компании индустрии информационных технологий (SentiMetrix, IBM, USC, DESPIC, B. Fusion, G. Tech). Для оценки ботов, созданных участниками, использовалась математическая система подсчета очков.Уравнение (9) определяет эту систему оценок. Этот конкурс был направлен на создание ботов, которые могут идентифицировать поддельных пользователей (ботов), которые публикуют сообщения в Twitter и создают влияние. Однако актуальность этого исследования важна, и оно связано с системой обнаружения и отслеживания событий, потому что система подсчета очков, используемая в этом соревновании, представляет собой обычную систему измерения, связанную с искусственным интеллектом, которая также указывает на скорость.
В конкурсе приняли участие крупные компании индустрии информационных технологий (SentiMetrix, IBM, USC, DESPIC, B. Fusion, G. Tech). Для оценки ботов, созданных участниками, использовалась математическая система подсчета очков.Уравнение (9) определяет эту систему оценок. Этот конкурс был направлен на создание ботов, которые могут идентифицировать поддельных пользователей (ботов), которые публикуют сообщения в Twitter и создают влияние. Однако актуальность этого исследования важна, и оно связано с системой обнаружения и отслеживания событий, потому что система подсчета очков, используемая в этом соревновании, представляет собой обычную систему измерения, связанную с искусственным интеллектом, которая также указывает на скорость. Неправильное обнаружение событий и выявление несобытийных явлений также представляет собой огромную проблему. Причина, по которой эта проблема имеет более крупные потоки, заключается в том, что систему информирования о бедствиях в реальном времени можно обмануть и неправильно обнаружить катастрофу или даже не обнаружить ее.
Неправильное обнаружение событий и выявление несобытийных явлений также представляет собой огромную проблему. Причина, по которой эта проблема имеет более крупные потоки, заключается в том, что систему информирования о бедствиях в реальном времени можно обмануть и неправильно обнаружить катастрофу или даже не обнаружить ее. Чтобы разворачивать эти реальные события и извлекать их из Twitter, нужны системы реального времени с высокой точностью и точностью. Оценка систем сталкивается с множеством проблем, таких как проблемы с данными и метриками оценки. В этой статье мы изучили некоторые системы TEDT, которые направлены на поиск, обнаружение, извлечение и отслеживание реальных инцидентов из Twitter, а также описали проблемы, связанные с оценкой таких систем. Было предложено множество категорий для классификации этих алгоритмов и методов, которые также представлены в этой статье; Кроме того, в статье предлагается еще одна категоризация, основанная на методологии полагающихся алгоритмов.Наконец, в этой статье обсуждалась методология пост-обнаружения, предложенная как классификация коротких предложений с глубоким обучением, которая может быть полезна после обнаружения событий.
Чтобы разворачивать эти реальные события и извлекать их из Twitter, нужны системы реального времени с высокой точностью и точностью. Оценка систем сталкивается с множеством проблем, таких как проблемы с данными и метриками оценки. В этой статье мы изучили некоторые системы TEDT, которые направлены на поиск, обнаружение, извлечение и отслеживание реальных инцидентов из Twitter, а также описали проблемы, связанные с оценкой таких систем. Было предложено множество категорий для классификации этих алгоритмов и методов, которые также представлены в этой статье; Кроме того, в статье предлагается еще одна категоризация, основанная на методологии полагающихся алгоритмов.Наконец, в этой статье обсуждалась методология пост-обнаружения, предложенная как классификация коротких предложений с глубоким обучением, которая может быть полезна после обнаружения событий.