Описание изменений вошедших в обновление программы ERP.Travel 4.1.2 > Версии, Обновления > Подробнее > Система автоматизации турагентства
Отображение даты курса на форме добавления услуги
При создании услуги показывается не только значение выбранного типа курса и но и дату на которую он найден. Тем самым менеджер сможет контролировать подходит ли ему значение курса или оно устарело и нужно ввести новое.
Учитывая, что фиксированные курсы поставщиков меняются не каждый день, то вывод даты на форму также позволяет визуально понять, что курс не устарел в выходные и праздники.
Печатная форма заявки к договору — все услуги построчно
Изменен принцип вывода табличной части по услугам в приложении к договору «Бланк Заказ». Теперь все услуги выходят в виде отдельных строк и не группируются по типам размещение, транспорт и т.п. Каждой услуге выводятся даты ее действия и свойства.
Для услуги страховка от невыезда пишется только дата начала тура. Если дата начала услуги и дата окончания услуги совпадают, то пишется только одна дата.
Если дата начала услуги и дата окончания услуги совпадают, то пишется только одна дата.
Печатная форма заявки к договору – печать названия бренда поставщика
Для случаев, когда название юр.лица сильно разнится с названием туроператора, в печатную форму Бланка заявки добавлена печать наименования поставщика. Для Данко, например, туда выходит Тез Тур (Tez Tour).
Галочка участвует в рассылке по умолчанию новому клиенту ставить
Каждому клиенту при создании ставится признак «участвует в рассылке». Тем самым все клиенты по умолчанию включаются в дальнейшие рассылки по SMS, адресам почты и email
Форма выбора географии деревом – показывать категорию отеля
Теперь при выборе отеля через кнопку выбора значения в справочнике показывается его категория в сокращенном виде (1*,2*,3*,4*,5*,HV).
Фильтры списка заявок поставщику
Над списком заявок поставщику добавлены такие же фильтры, как и над списком заказов тура: по номеру заказа, по номеру подтверждения, по ФИО туриста.
Форма списка документов заказов — команда отправить email
Добавлена кнопка отправить Email из панели предварительного просмотра списка заказов тура и заявок поставщикам. По нажатию на нее формируется сразу письмо на адрес клиента или поставщика и открывается в почтовом клиенте по умолчанию.
Кнопка обновить в меню списка заказов тура и заявок
Над списком заказов тура и заявок поставщикам теперь сразу отображается кнопка обновить, которая позволяет отобразить список заказов с учетом изменений. Ранее кнопка была доступна только через меню «Все действия», тем самым сокращено количество кликов и увеличена быстрота работы.
По-прежнему, списки заказов тура, заявок поставщикам и прочие документы можно обновлять клавишей F5
Значение по умолчанию для характеристик услуги транспорт
При добавлении услуги транспорт по умолчанию ставится тип транспорта Авиа, и тип перевозки Эконом. Тем самым сокращается на 4-10 кликов общее время создания заказа, поскольку обычно в пакете именно авиа и эконом.
Тем самым сокращается на 4-10 кликов общее время создания заказа, поскольку обычно в пакете именно авиа и эконом.
Вариант отчета «Рейтинг менеджеров» с группировкой заказов по дате вылета
Создан вариант отчета по заказам туров, в котором для расчета бонусной и премиальной части менеджеров заказы группируются не по дате создания, а по году, кварталу, месяцу и дате начала тура.
Сбрасывание округленной стоимости при изменении услуг
Ранее если первоначально в заказе была введена округленная стоимость и потом была изменена стоимость по услугам, то округленная стоимость не учитывала правок и оставалась прежней. Тем самым данная клиенту скидка или изменение курса или стоимости услуг не влияло на итоговую стоимость договора
Создан опциональный режим (по умолчанию отключен), чтобы при изменении стоимости, если полученная стоимость по услугам больше чем округленная стоимость по заказу — округленная стоимость сбрасывается
что это такое и как применяется в программировании
Компилятор — это программа, которая переводит текст, написанный на языке программирования, в машинные коды. С помощью компиляторов компьютеры могут понимать разные языки программирования, в том числе высокоуровневые, то есть близкие к человеку и далекие от «железа».
С помощью компиляторов компьютеры могут понимать разные языки программирования, в том числе высокоуровневые, то есть близкие к человеку и далекие от «железа».
Процесс работы компилятора с кодом называется компиляцией, или сборкой. По сути, компилятор — комплексный «переводчик», который собирает, или компилирует, программу в исполняемый файл. Исполняемый файл — это набор инструкций для компьютера, который тот понимает и может выполнить.
Языки программирования, для перевода которых используются компиляторы, называются компилируемыми.
Для чего нужен компиляторИзначально компьютер не понимает смысл написанного на любом языке программирования. Язык компьютера — машинные коды, нули и единицы, в которых зашифрована информация и команды. Писать на машинных кодах программы практически невозможно: даже простейшее действие будет отнимать много часов работы программиста. Поэтому появились языки программирования, более понятные для людей, и специальные программы, которые переводят эти языки в машинные коды. Эти программы и есть компиляторы.
Эти программы и есть компиляторы.
Без компилятора любой код на компилируемом языке программирования будет для компьютера просто текстом — он не распознает команды и не сможет их выполнить. Поэтому компилятор нужен, чтобы программы могли выполняться. Без него ничего не будет работать.
Еще одна задача компилятора — собрать все модули, например подключенные библиотеки, в единый файл. Нужно, чтобы исполняемый файл содержал в себе все необходимое для нормальной работы программы и полного выполнения инструкций.
Компилятор и интерпретатор: в чем разницаКомпиляция — не единственный подход к «переводу» человекопонятного языка программирования на машинный. Еще есть интерпретаторы и байт-код, но там технологии совсем другие.
Интерпретатор — это тоже программа, которая «переводит» текст на высокоуровневом языке программирования, но делает это иначе. Она не собирает весь код в один исполняемый файл для последующего запуска, а исполняет код сразу, построчно. Это чуть медленнее, но иногда удобнее. Языки, использующие интерпретаторы, называются интерпретируемыми.
Это чуть медленнее, но иногда удобнее. Языки, использующие интерпретаторы, называются интерпретируемыми.
Байт-код — «промежуточное звено» между подходами компиляции и интерпретации. Программа преобразуется в особый код, который запускается под специальной виртуальной машиной. Языков, которые работают так, относительно немного, самый известный и яркий пример — Java.
В каких языках используются компиляторыСреди популярных сегодня языков компилируемыми являются Swift и Go, а также C / C++ и Objective-C. Другие примеры — Visual Basic, Haskell, Pascal / Delphi, Rust, а также Lisp, Prolog и прочие менее известные языки. Разумеется, компилируемым является и язык ассемблера — очень низкоуровневый и написанный напрямую на машинных кодах.
Отдельно можно выделить языки, которые трансформируются в байт-код — это тоже своего рода компиляция. К ним относятся Java, Scala и Kotlin, а также C# и языки платформы .NET.
На каких языках пишут компиляторыДругие языки.
Например, один из компиляторов языка Go частично написан на C++, самый первый компилятор C++ — на ассемблере, а уже ассемблер — на машинных кодах.
Тот же язык. Написать компилятор для языка программирования можно на других версиях того же языка — такой подход разрешен и активно используется в разработке. Это нужно, чтобы компиляторы были более гибкими и «умными» и могли поддерживать больше возможностей, — ассемблер довольно примитивен и не решает всех задач.
Выглядит это так:
- первый, более простой компилятор пишется на ассемблере;
- второй пишется уже на нужном языке и компилируется первым компилятором;
- переведенный в машинные коды второй компилятор компилирует свои же исходники — получается более новая и мощная версия его же.
Например, большинство современных компиляторов для C / C++ написано на C / C++. Такие компиляторы называют самокомпилируемыми.
Такие компиляторы называют самокомпилируемыми.
У большинства языков программирования несколько компиляторов. Их еще называют реализациями. Изначальную реализацию пишет создатель языка, потом со временем появляются альтернативные. Зачем это делается? Цели могут быть разными:
- написать более современный и функциональный компилятор, обновить язык;
- оптимизировать язык и сделать его эффективнее;
- создать свободную реализацию, которую сможет дополнять сообщество;
- исправить ошибки, которые есть в существующих реализациях;
- перенести язык на другую платформу, и так далее.
Подходы к оптимизации, портированию и выполнению других целей у всех групп разработчиков свои. Поэтому разные компиляторы одного и того же языка могут различаться скоростью, особенностями архитектуры, назначением и другими параметрами. Синтаксис языка при этом остается таким же, но есть особые ситуации, когда одна и та же строчка может выполняться по-разному в зависимости от компилятора.
Компиляторы очень многообразны. Есть такие, которые имеют узкую специализацию, например запускаются только под процессоры определенного семейства и оптимизированы под них. Есть и более широкие — так называемые кросс-компиляторы, которые могут поддерживать несколько операционных систем.
Один компилятор может «знать» несколько языков программирования. Яркий пример такого решения — GCC, или GNU Compiler Collection, кросс-компилятор для нескольких операционных систем и языков, полностью бесплатный и свободный. На нем написано программное обеспечение GNU.
Существуют и так называемые компиляторы компиляторов. Они генерируют компиляторы для языка на основе его формального описания.
Как устроены и работают компиляторыПростыми словами, они «читают» пришедшую к ним на вход программу и переводят ее команды в соответствующие им наборы машинных кодов. Детали уже сложнее и различаются в зависимости от реализации. Например, есть модульные гибкие компиляторы, написанные на высокоуровневых языках, есть отладочные компиляторы, способные устранять часть синтаксических ошибок, и так далее.
Например, есть модульные гибкие компиляторы, написанные на высокоуровневых языках, есть отладочные компиляторы, способные устранять часть синтаксических ошибок, и так далее.
Сама компиляция может быть:
- построчной — в машинный код по очереди переводится каждая строка, что похоже на интерпретацию, но отличается технически;
- пакетной — код разбивается на блоки, или пакеты, и компилируется поблочно;
- условной — особенности компиляции зависят от условий, которые прописаны в исходном коде компилируемой программы.
Сначала компилятор разбирает, что написано, потом анализирует команды, а потом генерирует машинные коды. Он не запускает программу, запуск — это отдельное действие.
Преимущества компилируемых языков- Компилируемые языки обычно быстрее, чем интерпретируемые, и их легче оптимизировать.
- Итоговый размер кода у компилируемых языков, как правило, меньше, чем у интерпретируемых.
- В компилируемых языках намного шире возможность контролировать аппаратные ресурсы.
 Это не значит, что они все низкоуровневые, но обратное — верно: практически все низкоуровневые языки — компилируемые.
Это не значит, что они все низкоуровневые, но обратное — верно: практически все низкоуровневые языки — компилируемые. - Когда процессоры становятся мощнее, именно компилируемые языки могут в должной мере задействовать их преимущества.
- Код после компилятора лучше оптимизируется под конкретные устройства, архитектуру «железа», эффективно задействует память и не тратит лишних ресурсов.
- Компилируемые языки обычно мощные и высокопроизводительные, поэтому на них пишут игры и другие серьезно нагруженные приложения.
- В отличие от интерпретируемых языков, компилируемые не выполняют код сразу — его сначала нужно собрать, а это лишний шаг и лишнее время.
- Код сложнее в отладке: приходится заново компилировать его при каждом, даже небольшом изменении. Сам процесс поиска и устранения ошибок бывает довольно неочевидным.
- Машинный код жестко связан с архитектурой платформы и различается в зависимости от системы.
 Поэтому компилируемые языки — по умолчанию не кроссплатформенные. Для переноса языка на другую операционную систему понадобится писать новый компилятор. Правда, есть исключения в виде универсальных кросс-компиляторов, работающих под разными платформами, но они подходят не для всего.
Поэтому компилируемые языки — по умолчанию не кроссплатформенные. Для переноса языка на другую операционную систему понадобится писать новый компилятор. Правда, есть исключения в виде универсальных кросс-компиляторов, работающих под разными платформами, но они подходят не для всего. - Для новичков проблема еще и в том, что компилируемые языки часто сложнее, чем интерпретируемые. Изучать их с нуля может быть тяжело, хотя и тут есть исключения.
Начинающий разработчик редко взаимодействует с компилятором напрямую. Он скачивает язык программирования, в том числе его компилятор, а потом работает в редакторе кода или IDE. Среда разработки сама запускает компилятор каждый раз, когда пользователь кликает на кнопку сборки или выполнения программы. Для этого его не нужно вызывать вручную. Иногда среда может сама включать в себя несколько компиляторов и выбирать подходящий в каждом случае.
Поэтому трогать компилятор на ранних этапах не имеет смысла — просто стоит помнить, что он есть, чтобы лучше разбираться в происходящем. Но он может пригодиться, если вы захотите скомпилировать что-то без среды разработки, например прямо в командной строке. Тогда его придется вызвать с помощью специальной команды — она своя для каждого решения.
Но он может пригодиться, если вы захотите скомпилировать что-то без среды разработки, например прямо в командной строке. Тогда его придется вызвать с помощью специальной команды — она своя для каждого решения.
У любого ПО есть документация, так что, если вы хотите узнать больше о компиляторе, которым пользуетесь, можете прочитать ее.
Узнайте больше об устройстве и работе языков программирования на курсах — получите новую профессию и станьте востребованным IT-специалистом.
python – Как читать файл построчно в список?
Чтобы прочитать файл в список, вам нужно сделать три вещи:
- Открыть файл
- Прочитать файл
- Сохранить содержимое как список
К счастью, Python позволяет очень легко делать эти вещи, поэтому самый короткий способ прочитать файл в список:
lst = list(open(filename))
Однако я добавлю еще несколько пояснений.
Открытие файла
Я предполагаю, что вы хотите открыть конкретный файл и не имеете дело непосредственно с дескриптором файла (или файловоподобным дескриптором). Наиболее часто используемая функция для открытия файла в Python — 9.0021 open , в Python 2.7 принимает один обязательный аргумент и два необязательных:
Наиболее часто используемая функция для открытия файла в Python — 9.0021 open , в Python 2.7 принимает один обязательный аргумент и два необязательных:
- Имя файла
- Режим
- Буферизация (в этом ответе я проигнорирую этот аргумент)
Имя файла должно быть строкой, представляющей путь к файлу . Например:
open('afile') # открывает файл с именем afile в текущем рабочем каталоге
open('adir/afile') # относительный путь (относительно текущего рабочего каталога)
open('C:/users/aname/afile') # абсолютный путь (Windows)
open('/usr/local/afile') # абсолютный путь (linux)
Обратите внимание, что необходимо указать расширение файла. Это особенно важно для пользователей Windows, поскольку расширения файлов, такие как .txt или .doc и т. д., скрыты по умолчанию при просмотре в проводнике.
Вторым аргументом является режим , по умолчанию это r , что означает «только для чтения». Это именно то, что вам нужно в вашем случае.
Это именно то, что вам нужно в вашем случае.
Но если вы действительно хотите создать файл и/или записать в файл, вам понадобится другой аргумент. Есть отличный ответ, если вам нужен обзор.
Для чтения файла вы можете опустить режим или передать его явно:
open(filename) открыть (имя файла, 'р')
Оба откроют файл в режиме только для чтения. Если вы хотите прочитать двоичный файл в Windows, вам нужно использовать режим rb :
open(filename, 'rb')
На других платформах 'b' (двоичный режим) просто игнорируется.
Теперь, когда я показал, как открыть файл, поговорим о том, что всегда нужно закрыть снова. В противном случае он будет держать открытый дескриптор файла до тех пор, пока процесс не завершится (или Python не удалит дескриптор файла).
Хотя вы можете использовать:
f = open(имя файла) # ... делать что-то с f е.закрыть()
Это не позволит закрыть файл, когда что-то между открыть и закрыть выдаст исключение. Вы можете избежать этого, используя
Вы можете избежать этого, используя try и finally :
f = open(filename)
# ничего между ними!
пытаться:
# делать что-то с f
окончательно:
е.закрыть()
Однако Python предоставляет контекстные менеджеры с более красивым синтаксисом (но для open он почти идентичен try и finally выше):
с open(filename) как f:
# делать что-то с f
# Файл всегда закрывается после окончания with-scope.
Последний подход — это рекомендуемый подход для открытия файла в Python!
Чтение файла
Хорошо, вы открыли файл, теперь как его прочитать?
Функция open возвращает объект файла и поддерживает протокол итерации Python. Каждая итерация даст вам строку:
с открытым (имя файла) как f:
для строки в f:
печать (строка)
Будет напечатана каждая строка файла. Однако обратите внимание, что каждая строка будет содержать символ новой строки \n в конце (вы можете проверить, создан ли ваш Python с поддержкой универсальной новой строки — в противном случае вы также могли бы иметь \r\n в Windows или \r в Mac в качестве новой строки). Если вы не хотите этого, вы можете просто удалить последний символ (или два последних символа в Windows):
Если вы не хотите этого, вы можете просто удалить последний символ (или два последних символа в Windows):
с открытым (имя файла) как f:
для строки в f:
печать (строка [:-1])
Но последняя строка не обязательно имеет завершающую новую строку, поэтому ее не следует использовать. Можно проверить, заканчивается ли он завершающей новой строкой, и если да, то удалить ее:
с open(filename) как f:
для строки в f:
если строка.заканчивается('\n'):
строка = строка[:-1]
печать (строка)
Но вы можете просто удалить все пробелы (включая символ \n ) с конца строки , это также удалит все остальные конечные пробелы , поэтому вы должны быть осторожны, если они важны:
с открытым (имя файла) как f:
для строки в f:
печать (f.rstrip())
Однако, если строки заканчиваются на \r\n («новая строка» Windows), то .rstrip() также позаботится о \r !
Сохранить содержимое в виде списка
Теперь, когда вы знаете, как открыть файл и прочитать его, пришло время сохранить содержимое в виде списка. Самый простой вариант — использовать функцию
Самый простой вариант — использовать функцию list :
с open(filename) как f:
лст = список (е)
Если вы хотите удалить завершающие символы новой строки, вы можете вместо этого использовать понимание списка:
с open(filename) как f:
lst = [line.rstrip() для строки в f]
Или еще проще: .readlines() 9Метод 0022 объекта файла по умолчанию возвращает список строк:
с открытым (имя файла) как f:
лст = f.readlines ()
Это также будет включать конечные символы новой строки, если они вам не нужны, я бы рекомендовал подход [line.rstrip() для строки в f] , потому что он позволяет избежать хранения двух списков, содержащих все строки в памяти.
Есть дополнительная возможность получить желаемый результат, но она довольно "субоптимальна": читать весь файл в строке, а затем разбивать на новые строки:
с open(filename) как f:
lst = f.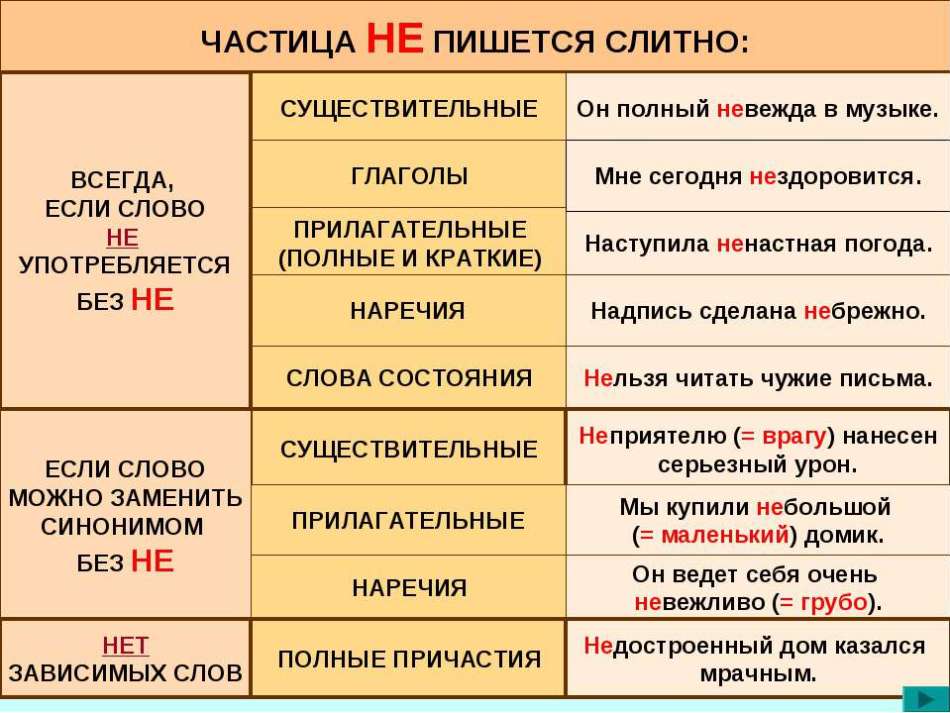 read().split('\n')
read().split('\n')
или:
с открытым (имя файла) как f:
lst = f.read().splitlines()
Они автоматически заботятся о завершающих новых строках, потому что символ разделения не включен. Однако они не идеальны, потому что вы храните файл как строку и как список строк в памяти!
Сводка
- Применение
с open(...) as fпри открытии файлов, потому что вам не нужно заботиться о закрытии файла самостоятельно, и он закрывает файл, даже если происходит какое-то исключение. -
файлобъекты поддерживают протокол итерации, поэтому чтение файла построчно так же просто, какдля строки в the_file_object:. - Всегда просматривайте документацию по доступным функциям/классам. В большинстве случаев есть идеальное соответствие для задачи или, по крайней мере, одно или два хороших. Очевидным выбором в этом случае будет
readlines(), но если вы хотите обработать строки перед их сохранением в списке, я бы порекомендовал простое понимание списка.
python пишет только первую строку в файл
Задавать вопрос
спросил
Изменено 1 год, 2 месяца назад
Просмотрено 655 раз
Мой сценарий записывает в файл только первую строку. Я проверил предыдущие те же вопросы, проблема с ними заключалась в записи в файл после цикла for, поэтому я пробовал оба:
import os
импорт системы
импортировать pdb_atoms как банкоматы
импортировать numpy как np
path_to_ligands=('/home/user/Desktop/small_test/ligands/')
path_to_CMS=('/home/user/Desktop/small_test/CMS/')
с os.scandir(path_to_ligands) как lig:
для каждого_файла в lig:
текст = открыть (каждый_файл, "r")
строки=текст.readlines()
CMS_coord= np. array( atms.CMS(each_file)) #получение координат центра масс каждого атома
для строки в строке:
х =[]
x.append( float(line[30:38]) - CMS_coord[0])
x.append( float(line[38:46]) - CMS_coord[1])
x.append( float(line[46:54]) - CMS_coord[2])
строка = строка.strip()
text_to_write=[строка[:30] + ("%8.3f%8.3f%8.3f" % (x[0],x[1],x[2])) +line[54:]]
новое_имя = путь_к_CMS + каждый_файл.имя.заменить('лиганд', 'лига_CMS')
с open(new_name, 'w') как w:
для я в text_to_write:
w.write(я + '\n')
array( atms.CMS(each_file)) #получение координат центра масс каждого атома
для строки в строке:
х =[]
x.append( float(line[30:38]) - CMS_coord[0])
x.append( float(line[38:46]) - CMS_coord[1])
x.append( float(line[46:54]) - CMS_coord[2])
строка = строка.strip()
text_to_write=[строка[:30] + ("%8.3f%8.3f%8.3f" % (x[0],x[1],x[2])) +line[54:]]
новое_имя = путь_к_CMS + каждый_файл.имя.заменить('лиганд', 'лига_CMS')
с open(new_name, 'w') как w:
для я в text_to_write:
w.write(я + '\n')
а также это:
path_to_ligands=('/home/user/Desktop/small_test/ligands/')
path_to_CMS=('/home/user/Desktop/small_test/CMS/')
с os.scandir(path_to_ligands) как lig:
для каждого_файла в lig:
текст = открыть (каждый_файл, "r")
строки=текст.readlines()
CMS_coord= np.array( atms.CMS(each_file)) #получение координат центра масс каждого атома
для строки в строке:
х =[]
x. append( float(line[30:38]) - CMS_coord[0])
x.append( float(line[38:46]) - CMS_coord[1])
x.append( float(line[46:54]) - CMS_coord[2])
строка = строка.strip()
text_to_write=[строка[:30] + ("%8.3f%8.3f%8.3f" % (x[0],x[1],x[2])) +line[54:]]
новое_имя = путь_к_CMS + каждый_файл.имя.заменить('лиганд', 'лига_CMS')
с open(new_name, 'w') как w:
для я в text_to_write:
w.write(я + '\n')
append( float(line[30:38]) - CMS_coord[0])
x.append( float(line[38:46]) - CMS_coord[1])
x.append( float(line[46:54]) - CMS_coord[2])
строка = строка.strip()
text_to_write=[строка[:30] + ("%8.3f%8.3f%8.3f" % (x[0],x[1],x[2])) +line[54:]]
новое_имя = путь_к_CMS + каждый_файл.имя.заменить('лиганд', 'лига_CMS')
с open(new_name, 'w') как w:
для я в text_to_write:
w.write(я + '\n')
в обоих случаях пишет только первую строку. Выход такой:
ATOM 36 C28 VFL L 288 2,449 -2,116 0,546 1,00 15,00 L C
Новичок в python, буду признателен за помощь 🙂
- python
- запись файлов
5
Проблема в том, что вы открываете файл для каждой строки, когда вы открываете файл с w предыдущее содержимое файла стирается.
Открыть файл только один раз:
import os
импорт системы
импортировать pdb_atoms как банкоматы
импортировать numpy как np
path_to_ligands=('/home/user/Desktop/small_test/ligands/')
path_to_CMS=('/home/user/Desktop/small_test/CMS/')
с os. scandir(path_to_ligands) как lig:
для каждого_файла в lig:
новое_имя = путь_к_CMS + каждый_файл.имя.заменить('лиганд', 'лига_CMS')
с open(new_name, 'w') как w:
текст = открыть (каждый_файл, "r")
строки=текст.readlines()
CMS_coord= np.array( atms.CMS(each_file)) #получение координат центра масс каждого атома
для строки в строке:
х =[]
x.append( float(line[30:38]) - CMS_coord[0])
x.append( float(line[38:46]) - CMS_coord[1])
x.append( float(line[46:54]) - CMS_coord[2])
строка = строка.strip()
text_to_write=[строка[:30] + ("%8.3f%8.3f%8.3f" % (x[0],x[1],x[2])) +line[54:]]
для я в text_to_write:
w.write(я + '\n')
scandir(path_to_ligands) как lig:
для каждого_файла в lig:
новое_имя = путь_к_CMS + каждый_файл.имя.заменить('лиганд', 'лига_CMS')
с open(new_name, 'w') как w:
текст = открыть (каждый_файл, "r")
строки=текст.readlines()
CMS_coord= np.array( atms.CMS(each_file)) #получение координат центра масс каждого атома
для строки в строке:
х =[]
x.append( float(line[30:38]) - CMS_coord[0])
x.append( float(line[38:46]) - CMS_coord[1])
x.append( float(line[46:54]) - CMS_coord[2])
строка = строка.strip()
text_to_write=[строка[:30] + ("%8.3f%8.3f%8.3f" % (x[0],x[1],x[2])) +line[54:]]
для я в text_to_write:
w.write(я + '\n')
11
Рабочая версия:
#!/usr/bin/python3
импорт ОС
импорт системы
импортировать pdb_atoms как банкоматы
импортировать numpy как np
path_to_ligands=('/home/user/Desktop/small_test/ligands/')
path_to_CMS=('/home/user/Desktop/small_test/CMS/')
с os.