3.1.5. Запросы в формате XML (SOAP)
3. Запросы из внешних систем 3.1. Запросы к данным 3.1.5. Запросы в формате XML (SOAP)
Рассмотрим обработку запросов в формате XML (SOAP) на основе базового примера. Для отправки запросов мы используем простые скрипты на языке Python. Для приёма и обработки запросов нам понадобится кластер TDG, настроенный ранее.
3.1.5.1. Адаптация конфигурации из базового примера
Для повторения примеров из данного раздела нам потребуется внести определенные исправления в конфигурацию системы, загруженную ранее.
Разархивируйте архив с конфигурацией системы в отдельную директорию.
Откройте файл config.yml и измените его так, чтобы он содержал следующий текст:
types:
__file: model.avsc
functions:
router: {__file: router.lua}
classifier: {__file: classificator. lua}
select_user_books: {__file: select_user_books.lua}
process_user: {__file: process_user.lua}
process_book: {__file: process_book.lua}
process_sub: {__file: process_sub.lua}
pipelines:
router:
- router
classifier:
- classifier
select_user_books:
- select_user_books
process_user:
- process_user
process_book:
- process_book
process_sub:
- process_sub
connector:
input:
- name: soap
type: soap
wsdl: {__file: example.wsdl}
handlers:
- function: Connect
pipeline: router
routing:
- key: input_key
output: to_input_processor
output:
- name: to_input_processor
type: input_processor
input_processor:
classifiers:
- name: classifier
pipeline: classifier
routing:
- key: process_user
pipeline: process_user
- key: process_book
pipeline: process_book
- key: process_sub
pipeline: process_sub
storage:
- key: add_user
type: User
- key: add_book
type: Book
- key: add_subscription
type: Subscription
services:
select_user_books:
doc: "select_user_books"
function: select_user_books
return_type: string
args:
user_id: long
lua}
select_user_books: {__file: select_user_books.lua}
process_user: {__file: process_user.lua}
process_book: {__file: process_book.lua}
process_sub: {__file: process_sub.lua}
pipelines:
router:
- router
classifier:
- classifier
select_user_books:
- select_user_books
process_user:
- process_user
process_book:
- process_book
process_sub:
- process_sub
connector:
input:
- name: soap
type: soap
wsdl: {__file: example.wsdl}
handlers:
- function: Connect
pipeline: router
routing:
- key: input_key
output: to_input_processor
output:
- name: to_input_processor
type: input_processor
input_processor:
classifiers:
- name: classifier
pipeline: classifier
routing:
- key: process_user
pipeline: process_user
- key: process_book
pipeline: process_book
- key: process_sub
pipeline: process_sub
storage:
- key: add_user
type: User
- key: add_book
type: Book
- key: add_subscription
type: Subscription
services:
select_user_books:
doc: "select_user_books"
function: select_user_books
return_type: string
args:
user_id: long
 lua}
select_user_books: {__file: select_user_books.lua}
process_user: {__file: process_user.lua}
process_book: {__file: process_book.lua}
process_sub: {__file: process_sub.lua}
pipelines:
router:
- router
classifier:
- classifier
select_user_books:
- select_user_books
process_user:
- process_user
process_book:
- process_book
process_sub:
- process_sub
connector:
input:
- name: soap
type: soap
wsdl: {__file: example.wsdl}
handlers:
- function: Connect
pipeline: router
routing:
- key: input_key
output: to_input_processor
output:
- name: to_input_processor
type: input_processor
input_processor:
classifiers:
- name: classifier
pipeline: classifier
routing:
- key: process_user
pipeline: process_user
- key: process_book
pipeline: process_book
- key: process_sub
pipeline: process_sub
storage:
- key: add_user
type: User
- key: add_book
type: Book
- key: add_subscription
type: Subscription
services:
select_user_books:
doc: "select_user_books"
function: select_user_books
return_type: string
args:
user_id: long
lua}
select_user_books: {__file: select_user_books.lua}
process_user: {__file: process_user.lua}
process_book: {__file: process_book.lua}
process_sub: {__file: process_sub.lua}
pipelines:
router:
- router
classifier:
- classifier
select_user_books:
- select_user_books
process_user:
- process_user
process_book:
- process_book
process_sub:
- process_sub
connector:
input:
- name: soap
type: soap
wsdl: {__file: example.wsdl}
handlers:
- function: Connect
pipeline: router
routing:
- key: input_key
output: to_input_processor
output:
- name: to_input_processor
type: input_processor
input_processor:
classifiers:
- name: classifier
pipeline: classifier
routing:
- key: process_user
pipeline: process_user
- key: process_book
pipeline: process_book
- key: process_sub
pipeline: process_sub
storage:
- key: add_user
type: User
- key: add_book
type: Book
- key: add_subscription
type: Subscription
services:
select_user_books:
doc: "select_user_books"
function: select_user_books
return_type: string
args:
user_id: long
Обратите внимание на появившийся раздел input_processor/routing и связанные
с ним описания новых конвейеров обработки данных (pipeline) и функций. При этом
модель данных не изменилась. В разделе
При этом
модель данных не изменилась. В разделе Connect (не являющейся функцией TDG, но описываемой
в XML/SOAP) и связанным с ней конвейером (уже известным нам по примеру с JSON — router).
Примечание
В секции wsdl: обязательно указывается файл спецификации веб-сервиса с
расширением .wsdl. В нашем примере это example.wsdl. Данный файл должен
обязательно быть включен в состав архива с конфигурацией системы. В том случае,
если WSDL не используется, данный файл может быть пустым.
Теперь откройте файл classificator.lua и отредактируйте его так, чтобы он имел
следующее содержимое:
#!/usr/bin/env tarantool
local param = ...
if (param.obj[1].tag == "username" or param.obj[2].tag == "username") then
param.routing_key = "process_user"
return param
end
if (param.obj[1].tag == "book_name" or param.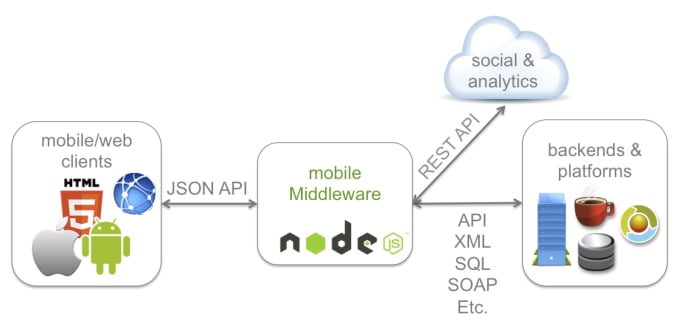 obj[2].tag == "book_name") then
param.routing_key = "process_book"
return param
end
if ((param.obj[1].tag == "user_id" and param.obj[2] == "book_id") or (param.obj[2].tag == "user_id" and param.obj[1].tag == "book_id")) then
param.routing_key = "process_sub"
return param
end
param.routing_key = "unknown_type"
return param
obj[2].tag == "book_name") then
param.routing_key = "process_book"
return param
end
if ((param.obj[1].tag == "user_id" and param.obj[2] == "book_id") or (param.obj[2].tag == "user_id" and param.obj[1].tag == "book_id")) then
param.routing_key = "process_sub"
return param
end
param.routing_key = "unknown_type"
return param
Создайте файлы process_user.lua, process_book.lua и process_sub.lua.
Содержимое этих файлов — скрипт обработки данных, который должен формировать из
получаемого TDG информационного объекта объект, соответствующий описанному
в модели данных.
Далее приведен пример содержимого файла process_user.lua.
Остальные файлы выполняются по аналогии.
#!/usr/bin/env tarantool
local param = ...
local id = param.obj[1][1]
local username = param.obj[2][1]
local data = {id = tonumber(id), username = username}
local ret = {obj = data, priority = 1, routing_key = 'add_user'}
return ret
Сформированный вышеуказанным скриптом объект должен содержать поля id и username,
так как он получит routing_key для добавления объекта типа User в хранилище.
Важно
Для сохранения TDG ожидает объект в формате, представленном выше,
где obj включает в себя весь информационный объект в виде перечисленных
через запятую пар key = value, где для каждого обязательного поля объекта
в модели данных задан одноимённый ключ (key) с непустым значением.
Закончив с подготовкой файлов, упакуйте их в zip-архив и загрузите его согласно инструкции.
3.1.5.2. Описание процесса обработки запроса
Логика обработки поступающего запроса изложена в файле конфигурации config.yml и состоит в следующем:
Согласно разделу
connector/inputфайла конфигурацииconfig.yml, SOAP (XML) запросы передаются на обработку конвейеруrouter, который состоит из функцииrouter;Функция
routerссылается на файлrouter.lua, который упаковывает поступивший объект с ключомrouting_keyравным строкеinput_key;Согласно разделу
connector/routingconfig., все объекты с ключом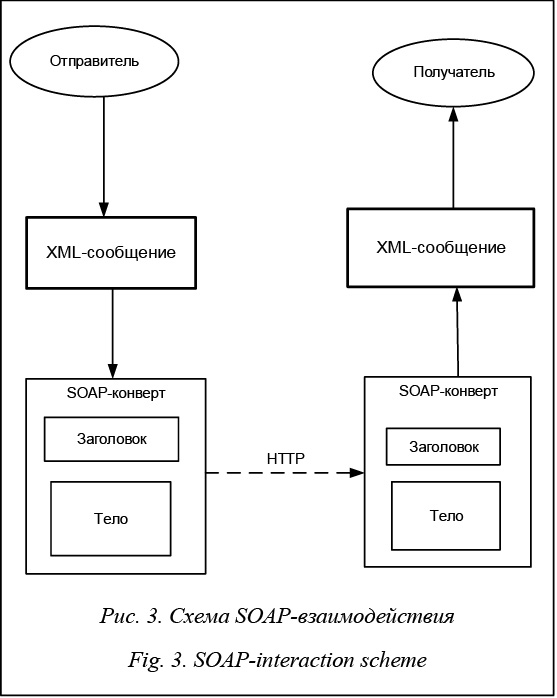 yml
ymlinput_keyпередаютсяto_input_processor;В секции
outputдля разделаconnectorуказана единственная записьto_input_processor, которая переадресует запрос в разделinput_processorдля обработки на одноименной роли;В разделе
input_processorвсе запросы попадают в секциюclassifiers, где в нашем случае указан один единственный объект, вызывающий конвейер обработки объектов (pipeline)Конвейер
classifierвызывает одноименную функцию, которая описана в файлеclassificator.lua. Как можно понять из названия, данная функция занимается классификацией поступающей информации. Логика ее работы следующая:при наличии тэга
usernameу поступившего объекта — ему присваиваетсяrouting_key=process_user, то есть объект направляется для формирования объекта типа пользователь;при наличии тэга
book_nameу поступившего объекта — ему присваиваетсяrouting_key=process_book, то есть объект направляется для формирования объекта типакнига;при наличии тэгов
user_idиbook_idу поступившего объекта — ему присваиваетсяrouting_key=process_sub, то есть объект направляется для формирования объекта типа подписка;во всех остальных случаях объекту присваивается
routing_key=unknown_type, то есть объект не распознан. Такой объект обычно попадает в ремонтную очередь,
но можно настроить и иное поведение;
Такой объект обычно попадает в ремонтную очередь,
но можно настроить и иное поведение;
В разделе
input_processorв секцииroutingrouting_key:process_user,process_bookиprocess_subпри помощи одноименных функций. Каждая из этих функций формирует объект в нужном для сохранения формате и присваивает ему соответствующийrouting_key;В секции
storageописано сохранение данных в TDG.при значении
routing_keyравномadd_userобъект сохраняется какUser;при значении
routing_keyравномadd_bookобъект сохраняется какBook;при значении
routing_keyравномSubscription.
Обратите внимание, что вся лишняя информация, не относящаяся к типу объекта, описанному в модели данных, не будет сохранена.
Из всего файла конфигурации системы остался не рассмотренным участок, отвечающий
за сервисы. В данном примере там описан простой сервис, вызывающий функцию select_user_books с аргументом user_id и возвращающий строковую переменную.
Логика работы этой функции такова — переданное значение Subscription всех книг, записанных за данным пользователем.
Затем выводятся все найденные book_id.
3.1.5.3. Подготовка запроса в формате SOAP (XML)
Создайте файл request.py со скриптом на языке Python для отправки простейшего
запроса с полями объекта типа User (из нашей модели данных:
это поля id и username), который будет выглядеть следующим образом:
import requests data = """<soap:Envelope xmlns:soap="http://schemas.xmlsoap.org/soap/envelope/"> <soap:Body> <NS2:Connect xmlns:NS2="http://172.19.0.2:8080/soap"> <id>1</id> <username>John Smith</username> </NS2:Connect> </soap:Body> </soap:Envelope>""" header = {'Authorization' : 'Bearer c0b26a60-aebe-4899-9ab6-4458627ac61e'} r = requests.post(url = "http://172.19.0.2:8080/soap", data = data, headers = header)
Передаваемый запрос содержит заголовок для авторизации и тело в виде
SOAP объекта с обязательными полями для объекта модели данных типа User.
Примечание
Используйте в качестве значения для параметра Authorization: Bearer токен приложений,
сгенерированный ранее.
Для успешного добавления записи имеющегося в модели данных типа объекта в запросе должны содержаться все обязательные поля для данного типа объекта.
Процедура отправки запроса и ожидаемые результаты описаны ранее в пункте Отправка запросов.
Found what you were looking for?
Feedback
Что такое XML / Хабр
Если вы тестируете API, то должны знать про два основных формата передачи данных:
- XML — используется в SOAP (всегда) и REST-запросах (реже);
- JSON — используется в REST-запросах.

Сегодня я расскажу вам про XML.
XML, в переводе с англ eXtensible Markup Language — расширяемый язык разметки. Используется для хранения и передачи данных. Так что увидеть его можно не только в API, но и в коде.
Этот формат рекомендован Консорциумом Всемирной паутины (W3C), поэтому он часто используется для передачи данных по API. В SOAP API это вообще единственно возможный формат входных и выходных данных!
См также:
Что такое API — общее знакомство с API
Что такое JSON — второй популярный формат
Введение в SOAP и REST: что это и с чем едят — видео про разницу между SOAP и REST.
Так что давайте разберемся, как он выглядит, как его читать, и как ломать! Да-да, а куда же без этого? Надо ведь выяснить, как отреагирует система на кривой формат присланных данных.
Содержание
- Как устроен XML
- Теги
- Корневой элемент
- Значение элемента
- Атрибуты элемента
- XML пролог
- XSD-схема
- Практика: составляем свой запрос
- Well Formed XML
- 1.
 Есть корневой элемент
Есть корневой элемент - 2. У каждого элемента есть закрывающийся тег
- 3. Теги регистрозависимы
- 4. Правильная вложенность элементов
- 5. Атрибуты оформлены в кавычках
- 1.
- Итого
Как устроен XML
Возьмем пример из документации подсказок Дадаты по ФИО:
<req> <query>Виктор Иван</query> <count>7</count> </req>
И разберемся, что означает эта запись.
Теги
В XML каждый элемент должен быть заключен в теги. Тег — это некий текст, обернутый в угловые скобки:
<tag>
Текст внутри угловых скобок — название тега.
Тега всегда два:
- Открывающий — текст внутри угловых скобок
<tag>
- Закрывающий — тот же текст (это важно!), но добавляется символ «/»
</tag>
Ой, ну ладно, подловили! Не всегда. Бывают еще пустые элементы, у них один тег и открывающий, и закрывающий одновременно. Но об этом чуть позже!
Бывают еще пустые элементы, у них один тег и открывающий, и закрывающий одновременно. Но об этом чуть позже!
С помощью тегов мы показываем системе «вот тут начинается элемент, а вот тут заканчивается». Это как дорожные знаки:
— На въезде в город написано его название: Москва
— На выезде написано то же самое название, но перечеркнутое: Москва*
* Пример с дорожными знаками я когда-то давно прочитала в статье Яндекса, только ссылку уже не помню. А пример отличный!
Корневой элемент
В любом XML-документе есть корневой элемент. Это тег, с которого документ начинается, и которым заканчивается. В случае REST API документ — это запрос, который отправляет система. Или ответ, который она получает.
Чтобы обозначить этот запрос, нам нужен корневой элемент. В подсказках корневой элемент — «req».
Он мог бы называться по другому:
<main>
<sugg>
Да как угодно. Он показывает начало и конец нашего запроса, не более того. А вот внутри уже идет тело документа — сам запрос. Те параметры, которые мы передаем внешней системе. Разумеется, они тоже будут в тегах, но уже в обычных, а не корневых.
Он показывает начало и конец нашего запроса, не более того. А вот внутри уже идет тело документа — сам запрос. Те параметры, которые мы передаем внешней системе. Разумеется, они тоже будут в тегах, но уже в обычных, а не корневых.
Значение элемента
Значение элемента хранится между открывающим и закрывающим тегами. Это может быть число, строка, или даже вложенные теги!
Вот у нас есть тег «query». Он обозначает запрос, который мы отправляем в подсказки.
Внутри — значение запроса.
Это как если бы мы вбили строку «Виктор Иван» в GUI (графическом интерфейсе пользователя):
Пользователю лишняя обвязка не нужна, ему нужна красивая формочка. А вот системе надо как-то передать, что «пользователь ввел именно это». Как показать ей, где начинается и заканчивается переданное значение? Для этого и используются теги.
Система видит тег «query» и понимает, что внутри него «строка, по которой нужно вернуть подсказки».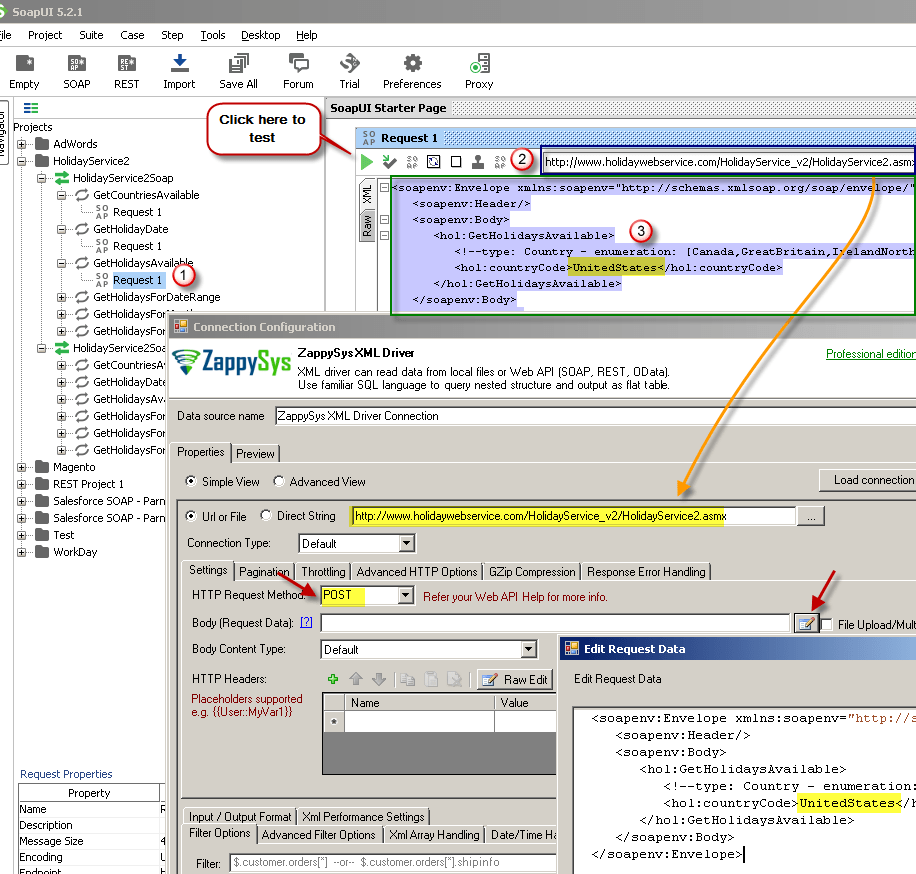
Параметр count = 7 обозначает, сколько подсказок вернуть в ответе. Если тыкать подсказки на демо-форме Дадаты, нам вернется 7 подсказок. Это потому, что туда вшито как раз значение count = 7. А вот если обратиться к документации метода, count можно выбрать от 1 до 20.
Откройте консоль разработчика через f12, вкладку Network, и посмотрите, какой запрос отправляется на сервер. Там будет значение count = 7.См также:
Что тестировщику надо знать про панель разработчика — подробнее о том, как использовать консоль.
Обратите внимание:
- Виктор Иван — строка
- 7 — число
Но оба значения идут
безкавычек. В XML нам нет нужды брать строковое значение в кавычки (а вот в JSON это сделать придется).
Атрибуты элемента
У элемента могут быть атрибуты — один или несколько. Их мы указываем внутри отрывающегося тега после названия тега через пробел в виде
Их мы указываем внутри отрывающегося тега после названия тега через пробел в виде
название_атрибута = «значение атрибута»
Например:
<query attr1=“value 1”>Виктор Иван</query> <query attr1=“value 1” attr2=“value 2”>Виктор Иван</query>
Зачем это нужно? Из атрибутов принимающая API-запрос система понимает, что такое ей вообще пришло.
Например, мы делаем поиск по системе, ищем клиентов с именем Олег. Отправляем простой запрос:
<query>Олег</query>
А в ответ получаем целую пачку Олегов! С разными датами рождения, номерами телефонов и другими данными. Допустим, что один из результатов поиска выглядит так:
<party type="PHYSICAL" sourceSystem="AL" rawId="2">
<field name=“name">Олег </field>
<field name="birthdate">02.01.1980</field>
<attribute type="PHONE" rawId="AL.2.PH.1">
<field name="type">MOBILE</field>
<field name="number">+7 916 1234567</field>
</attribute>
</party>
Давайте разберем эту запись. У нас есть основной элемент party.
У нас есть основной элемент party.
У него есть 3 атрибута:
- type = «PHYSICAL» — тип возвращаемых данных. Нужен, если система умеет работать с разными типами: ФЛ, ЮЛ, ИП. Тогда благодаря этому атрибуту мы понимаем, с чем именно имеем дело и какие поля у нас будут внутри. А они будут отличаться! У физика это может быть ФИО, дата рождения ИНН, а у юр лица — название компании, ОГРН и КПП
- sourceSystem = «AL» — исходная система. Возможно, нас интересуют только физ лица из одной системы, будем делать отсев по этому атрибуту.
- rawId = «2» — идентификатор в исходной системе. Он нужен, если мы шлем запрос на обновление клиента, а не на поиск. Как понять, кого обновлять? По связке sourceSystem + rawId!
Внутри party есть элементы field.
У элементов field есть атрибут name. Значение атрибута — название поля: имя, дата рождения, тип или номер телефона. Так мы понимаем, что скрывается под конкретным field.
Это удобно с точки зрения поддержки, когда у вас коробочный продукт и 10+ заказчиков. У каждого заказчика будет свой набор полей: у кого-то в системе есть ИНН, у кого-то нету, одному важна дата рождения, другому нет, и т.д.
Но, несмотря на разницу моделей, у всех заказчиков будет одна XSD-схема (которая описывает запрос и ответ):
— есть элемент party;
— у него есть элементы field;
— у каждого элемента field есть атрибут name, в котором хранится название поля.
А вот конкретные названия полей уже можно не описывать в XSD. Их уже «смотрите в ТЗ». Конечно, когда заказчик один или вы делаете ПО для себя или «вообще для всех», удобнее использовать именованные поля — то есть «говорящие» теги. Какие плюшки у этого подхода:
— При чтении XSD сразу видны реальные поля. ТЗ может устареть, а код будет актуален.
— Запрос легко дернуть вручную в SOAP Ui — он сразу создаст все нужные поля, нужно только значениями заполнить. Это удобно тестировщику + заказчик иногда так тестирует, ему тоже хорошо.
В общем, любой подход имеет право на существование. Надо смотреть по проекту, что будет удобнее именно вам. У меня в примере неговорящие названия элементов — все как один будут field. А вот по атрибутам уже можно понять, что это такое.
Помимо элементов field в party есть элемент attribute. Не путайте xml-нотацию и бизнес-прочтение:
- с точки зрения бизнеса это атрибут физ лица, отсюда и название элемента — attribute.
- с точки зрения xml — это элемент (не атрибут!), просто его назвали attribute. XML все равно (почти), как вы будете называть элементы, так что это допустимо.
У элемента attribute есть атрибуты:
- type = «PHONE» — тип атрибута. Они ведь разные могут быть: телефон, адрес, емейл…
- rawId = «AL.2.PH.1» — идентификатор в исходной системе. Он нужен для обновления. Ведь у одного клиента может быть несколько телефонов, как без ID понять, какой именно обновляется?
Такая вот XML-ка получилась. Причем упрощенная. В реальных системах, где хранятся физ лица, данных сильно больше: штук 20 полей самого физ лица, несколько адресов, телефонов, емейл-адресов…
Причем упрощенная. В реальных системах, где хранятся физ лица, данных сильно больше: штук 20 полей самого физ лица, несколько адресов, телефонов, емейл-адресов…
Но прочитать даже огромную XML не составит труда, если вы знаете, что где. И если она отформатирована — вложенные элементы сдвинуты вправо, остальные на одном уровне. Без форматирования будет тяжеловато…
А так всё просто — у нас есть элементы, заключенные в теги. Внутри тегов — название элемента. Если после названия идет что-то через пробел: это атрибуты элемента.
XML пролог
Иногда вверху XML документа можно увидеть что-то похожее:
<?xml version="1.0" encoding="UTF-8"?>
Эта строка называется XML прологом. Она показывает версию XML, который используется в документе, а также кодировку. Пролог необязателен, если его нет — это ок. Но если он есть, то это должна быть первая строка XML документа.
UTF-8 — кодировка XML документов по умолчанию.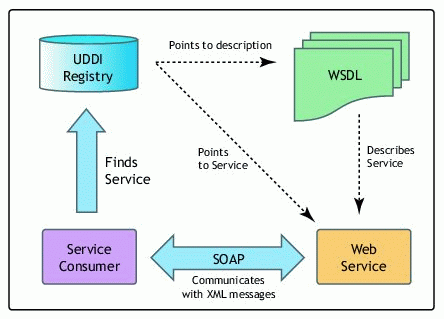
XSD-схема
XSD (XML Schema Definition) — это описание вашего XML. Как он должен выглядеть, что в нем должно быть? Это ТЗ, написанное на языке машины — ведь схему мы пишем… Тоже в формате XML! Получается XML, который описывает другой XML.
Фишка в том, что проверку по схеме можно делегировать машине. И разработчику даже не надо расписывать каждую проверку. Достаточно сказать «вот схема, проверяй по ней».
Если мы создаем SOAP-метод, то указываем в схеме:
- какие поля будут в запросе;
- какие поля будут в ответе;
- какие типы данных у каждого поля;
- какие поля обязательны для заполнения, а какие нет;
- есть ли у поля значение по умолчанию, и какое оно;
- есть ли у поля ограничение по длине;
- есть ли у поля другие параметры;
- какая у запроса структура по вложенности элементов;
- …
Теперь, когда к нам приходит какой-то запрос, он сперва проверяется на корректность по схеме.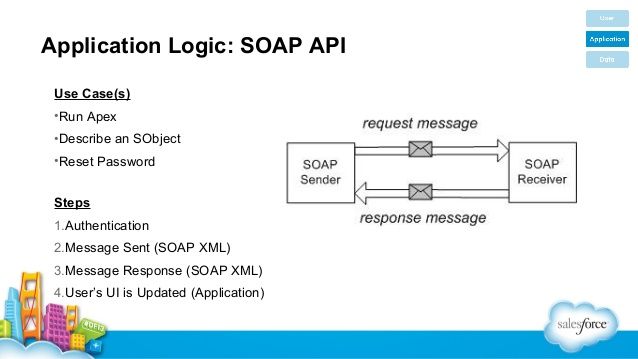 Если запрос правильный, запускаем метод, отрабатываем бизнес-логику. А она может быть сложной и ресурсоемкой! Например, сделать выборку из многомиллионной базы. Или провести с десяток проверок по разным таблицам базы данных…
Если запрос правильный, запускаем метод, отрабатываем бизнес-логику. А она может быть сложной и ресурсоемкой! Например, сделать выборку из многомиллионной базы. Или провести с десяток проверок по разным таблицам базы данных…
Поэтому зачем запускать сложную процедуру, если запрос заведом «плохой»? И выдавать ошибку через 5 минут, а не сразу? Валидация по схеме помогает быстро отсеять явно невалидные запросы, не нагружая систему.
Более того, похожую защиту ставят и некоторые программы-клиенты для отправки запросов. Например, SOAP Ui умеет проверять ваш запрос на well formed xml, и он просто не отправит его на сервер, если вы облажались. Экономит время на передачу данных, молодец!
А простому пользователю вашего SOAP API схема помогает понять, как составить запрос. Кто такой «простой пользователь»?
- Разработчик системы, использующей ваше API — ему надо прописать в коде, что именно отправлять из его системы в вашу.
- Тестировщик, которому надо это самое API проверить — ему надо понимать, как формируется запрос.

Да-да, в идеале у нас есть подробное ТЗ, где всё хорошо описано. Но увы и ах, такое есть не всегда. Иногда ТЗ просто нет, а иногда оно устарело. А вот схема не устареет, потому что обновляется при обновлении кода. И она как раз помогает понять, как запрос должен выглядеть.
Итого, как используется схема при разработке SOAP API:
- Наш разработчик пишет XSD-схему для API запроса: нужно передать элемент такой-то, у которого будут такие-то дочерние, с такими-то типами данных. Эти обязательные, те нет.
- Разработчик системы-заказчика, которая интегрируется с нашей, читает эту схему и строит свои запросы по ней.
- Система-заказчик отправляет запросы нам.
- Наша система проверяет запросы по XSD — если что-то не так, сразу отлуп.
- Если по XSD запрос проверку прошел — включаем бизнес-логику!
А теперь давайте посмотрим, как схема может выглядеть! Возьмем для примера метод doRegister в Users.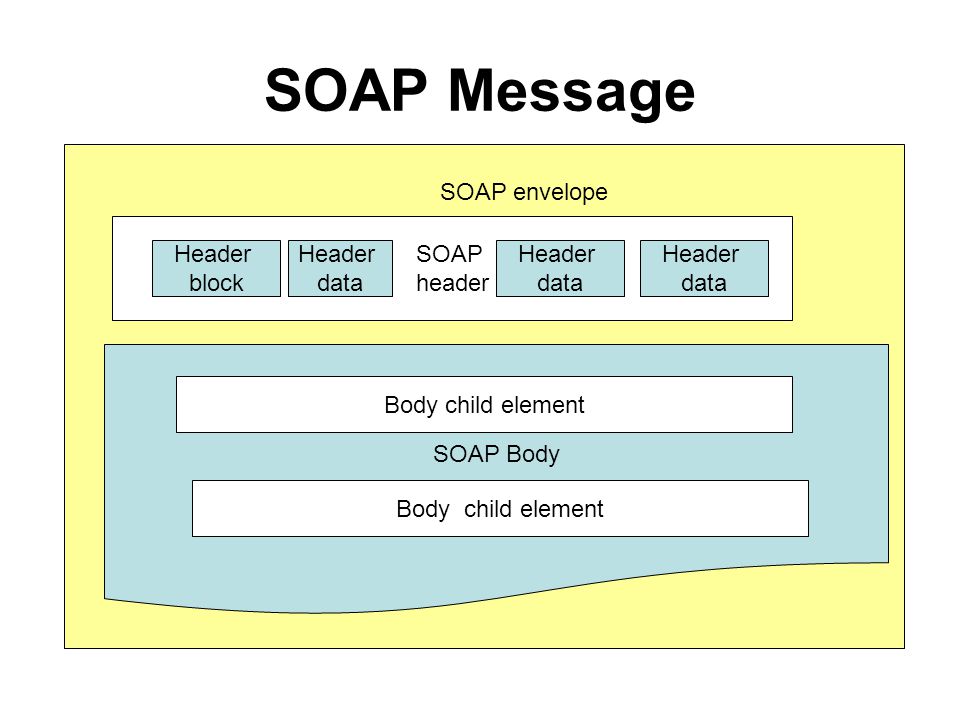 Чтобы отправить запрос, мы должны передать email, name и password. Есть куча способов написать запрос правильно и неправильно:
Чтобы отправить запрос, мы должны передать email, name и password. Есть куча способов написать запрос правильно и неправильно:
Попробуем написать для него схему. В запросе должны быть 3 элемента (email, name, password) с типом «string» (строка). Пишем:
<xs:element name="doRegister ">
<xs:complexType>
<xs:sequence>
<xs:element name="email" type="xs:string"/>
<xs:element name="name" type="xs:string"/>
<xs:element name="password" type="xs:string"/>
</xs:sequence>
</xs:complexType>
</xs:element>А в WSDl сервиса она записана еще проще:
<message name="doRegisterRequest"> <part name="email" type="xsd:string"/> <part name="name" type="xsd:string"/> <part name="password" type="xsd:string"/> </message>
Конечно, в схеме могут быть не только строковые элементы. Это могут быть числа, даты, boolean-значения и даже какие-то свои типы:
Это могут быть числа, даты, boolean-значения и даже какие-то свои типы:
<xsd:complexType name="Test">
<xsd:sequence>
<xsd:element name="value" type="xsd:string"/>
<xsd:element name="include" type="xsd:boolean" minOccurs="0" default="true"/>
<xsd:element name="count" type="xsd:int" minOccurs="0" length="20"/>
<xsd:element name="user" type="USER" minOccurs="0"/>
</xsd:sequence>
</xsd:complexType>А еще в схеме можно ссылаться на другую схему, что упрощает написание кода — можно переиспользовать схемы для разных задач.
См также:
XSD — умный XML — полезная статья с хабра
Язык определения схем XSD — тут удобные таблички со значениями, которые можно использовать
Язык описания схем XSD (XML-Schema)
Пример XML схемы в учебнике
Официальный сайт w3.org
Практика: составляем свой запрос
Ок, теперь мы знаем, как «прочитать» запрос для API-метода в формате XML. Но как его составить по ТЗ? Давайте попробуем. Смотрим в документацию. И вот почему я даю пример из Дадаты — там классная документация!
Но как его составить по ТЗ? Давайте попробуем. Смотрим в документацию. И вот почему я даю пример из Дадаты — там классная документация!
Что, если я хочу, чтобы мне вернуть только женские ФИО, начинающиеся на «Ан»? Берем наш исходный пример:
<req> <query>Виктор Иван</query> <count>7</count> </req>
В первую очередь меняем сам запрос. Теперь это уже не «Виктор Иван», а «Ан»:
<req> <query>Ан</query> <count>7</count> </req>
Далее смотрим в ТЗ. Как вернуть только женские подсказки? Есть специальный параметр — gender. Название параметра — это название тегов. А внутри уже ставим пол. «Женский» по английски будет FEMALE, в документации также. Итого получили:
<req> <query>Ан</query> <count>7</count> <gender>FEMALE</gender> </req>
Ненужное можно удалить. Если нас не волнует количество подсказок, параметр count выкидываем. Ведь, согласно документации, он необязательный. Получили запрос:
Если нас не волнует количество подсказок, параметр count выкидываем. Ведь, согласно документации, он необязательный. Получили запрос:
<req> <query>Ан</query> <gender>FEMALE</gender> </req>
Вот и все! Взяли за основу пример, поменяли одно значение, один параметр добавили, один удалили. Не так уж и сложно. Особенно, когда есть подробное ТЗ и пример )))
Попробуй сам!
Напишите запрос для метода MagicSearch в Users. Мы хотим найти всех Ивановых по полному совпадению, на которых висят актуальные задачи.
Well Formed XML
Разработчик сам решает, какой XML будет считаться правильным, а какой нет. Но есть общие правила, которые нельзя нарушать. XML должен быть well formed, то есть синтаксически корректный.
Чтобы проверить XML на синтаксис, можно использовать любой XML Validator (так и гуглите). Я рекомендую сайт w3schools. Там есть сам валидатор + описание типичных ошибок с примерами.
В готовый валидатор вы просто вставляете свой XML (например, запрос для сервера) и смотрите, всё ли с ним хорошо. Но можете проверить его и сами. Пройдитесь по правилам синтаксиса и посмотрите, следует ли им ваш запрос.
Правила well formed XML:
- Есть корневой элемент.
- У каждого элемента есть закрывающийся тег.
- Теги регистрозависимы!
- Соблюдается правильная вложенность элементов.
- Атрибуты оформлены в кавычках.
Давайте пройдемся по каждому правилу и обсудим, как нам применять их в тестировании. То есть как правильно «ломать» запрос, проверяя его на well-formed xml. Зачем это нужно? Посмотреть на фидбек от системы. Сможете ли вы по тексту ошибки понять, где именно облажались?
См также:
Сообщения об ошибках — тоже документация, тестируйте их! — зачем тестировать сообщения об ошибках
1. Есть корневой элемент
Нельзя просто положить рядышком 2 XML и полагать, что «система сама разберется, что это два запроса, а не один». Не разберется. Потому что не должна.
Не разберется. Потому что не должна.
И если у вас будет лежать несколько тегов подряд без общего родителя — это плохой xml, не well formed. Всегда должен быть корневой элемент:
Что мы делаем для тестирования этого условия? Правильно, удаляем из нашего запроса корневые теги!
2. У каждого элемента есть закрывающийся тег
Тут все просто — если тег где-то открылся, он должен где-то закрыться. Хотите сломать? Удалите закрывающийся тег любого элемента.
Но тут стоит заметить, что тег может быть один. Если элемент пустой, мы можем обойтись одним тегом, закрыв его в конце:
<name/>
Это тоже самое, что передать в нем пустое значение
<name></name>
Аналогично сервер может вернуть нам пустое значение тега. Можно попробовать послать пустые поля в Users в методе FullUpdateUser. И в запросе это допустимо (я отправила пустым поле name1), и в ответе SOAP Ui нам именно так и отрисовывает пустые поля.
И в запросе это допустимо (я отправила пустым поле name1), и в ответе SOAP Ui нам именно так и отрисовывает пустые поля.
Итого — если есть открывающийся тег, должен быть закрывающийся. Либо это будет один тег со слешом в конце.
Для тестирования удаляем в запросе любой закрывающийся тег.
3. Теги регистрозависимы
Как написали открывающий — также пишем и закрывающий. ТОЧНО ТАК ЖЕ! А не так, как захотелось.
А вот для тестирования меняем регистр одной из частей. Такой XML будет невалидным
4. Правильная вложенность элементов
Элементы могут идти друг за другом
Один элемент может быть вложен в другой
Но накладываться друг на друга элементы НЕ могут!
5. Атрибуты оформлены в кавычках
Даже если вы считаете атрибут числом, он будет в кавычках:
<query attr1=“123”>Виктор Иван</query> <query attr1=“атрибутик” attr2=“123” >Виктор Иван</query>
Для тестирования пробуем передать его без кавычек:
<query attr1=123>Виктор Иван</query>
Итого
XML (eXtensible Markup Language) используется для хранения и передачи данных.
Передача данных — это запросы и ответы в API-методах. Если вы отправляете SOAP-запрос, вы априори работаете именно с этим форматом. Потому что SOAP передает данные только в XML. Если вы используете REST, то там возможны варианты — или XML, или JSON.Хранение данных — это когда XML встречается внутри кода. Его легко понимает как машина, так и человек. В формате XML можно описывать какие-то правила, которые будут применяться к данным, или что-то еще.
Вот пример использования XML в коде open-source проекта folks. Я не знаю, что именно делает JacksonJsonProvider, но могу «прочитать» этот код — есть функционал, который мы будем использовать (featuresToEnable), и есть тот, что нам не нужен(featuresToDisable).
Формат XML подчиняется стандартам. Синтаксически некорректный запрос даже на сервер не уйдет, его еще клиент порежет. Сначала проверка на well formed, потом уже бизнес-логика.
Правила well formed XML:
- Есть корневой элемент.

- У каждого элемента есть закрывающийся тег.
- Теги регистрозависимы!
- Соблюдается правильная вложенность элементов.
- Атрибуты оформлены в кавычках.
Если вы тестировщик, то при тестировании запросов в формате XML обязательно попробуйте нарушить каждое правило! Да, система должна уметь обрабатывать такие ошибки и возвращать адекватное сообщение об ошибке. Но далеко не всегда она это делает.
А если система публичная и возвращает пустой ответ на некорректный запрос — это плохо. Потому что разработчик другой системы налажает в запросе, а по пустому ответу даже не поймет, где именно. И будет приставать к поддержке: «Что же у меня не так?», кидая информацию по кусочкам и в виде скринов исходного кода. Оно вам надо? Нет? Тогда убедитесь, что система выдает понятное сообщение об ошибке!
См также:
Что такое XML
Учебник по XML
Изучаем XML. Эрик Рэй (книга по XML)
Заметки о XML и XLST
Что такое JSON — второй популярный формат
PS — больше полезных статей ищите в моем блоге по метке «полезное». А полезные видео — на моем youtube-канале
А полезные видео — на моем youtube-канале
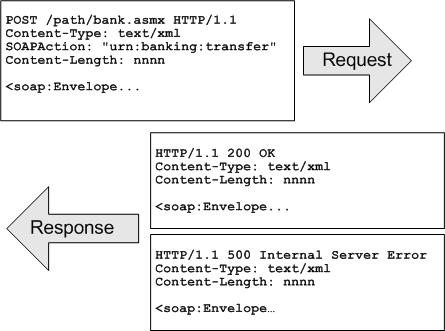
сообщений запросов и ответов SOAP | Documentation
Существует несколько панелей на выбор при работе с сообщениями SOAP Request и Response. Давайте посмотрим на оба.
Сообщения запроса
XML — стандартное текстовое представление базового XML-сообщения, щелкните правой кнопкой мыши в редакторе, чтобы открыть всплывающее меню с соответствующими действиями:
Выберите Подтвердить , чтобы проверить текущее сообщение на соответствие базовой схеме и отобразить список ошибок проверки внизу, если они обнаружены:
Raw — отображает фактические байты последнего отправленного сообщения, включая заголовки HTTP, вложения MIME и т. д.:
Используйте эту панель для проверки результатов раскрытия свойств, фильтров и т. д. Содержимое здесь должно быть таким же, как и в журнале HTTP в нижней части главного окна SoapUI:
.
Отслеживание производительности тестирования по мере масштабирования тестирования API
Сравните: все функции SoapUI Pro
SoapUI с открытым исходным кодом
- Поддержка тестирования SOAP и REST API.
- Простое переключение между несколькими средами.
- Подробная история тестов и отчет о сравнении тестов.
SoapUI Pro
- Поддержка тестирования API SOAP, REST и GraphQL.
- Простое переключение между несколькими средами.
- Подробная история тестов и отчет о сравнении тестов.
Редактор структуры — показывает древовидное представление базового XML-сообщения:
В столбце справа показан тип схемы соответствующего значения.
Здесь вы можете редактировать значения существующих элементов/атрибутов, но не можете добавлять или удалять существующие узлы в дереве.

Форма — отображает удобную для пользователя форму ввода для базового запроса, значительно упрощая ввод содержимого, чем в редакторе XML:
Опция View Type позволяет удалять ненужные элементы или элементы, не содержащие никаких данных. Это может быть полезно при ручном тестировании, если используются только определенные поля. В зависимости от типа поля ReadyAPI отображает различные редакторы, в том числе специальные редакторы для дат, времени, массивов, списков и так далее. Например, ниже скриншот редактора даты:
Примечание: Хотя редактор поддерживает достаточно сложные XML-схемы, он не поддерживает все возможные конструкции XML-схем.
Вставка данных
Все редактируемые поля имеют контекстное меню со стандартными действиями редактора и действием Получить данные , которое автоматически вставляет расширение свойства для выбранного свойства. Например, если вы хотите использовать свойство Пароль в поле пароль , вы можете щелкнуть правой кнопкой мыши в соответствующем поле редактора формы и выбрать Получить данные :
Затем выбрать нужное свойство в последующем Диалоговое окно «Получить данные» :
Здесь мы выбираем свойство «Пароль», определенное на шаге теста «Свойства».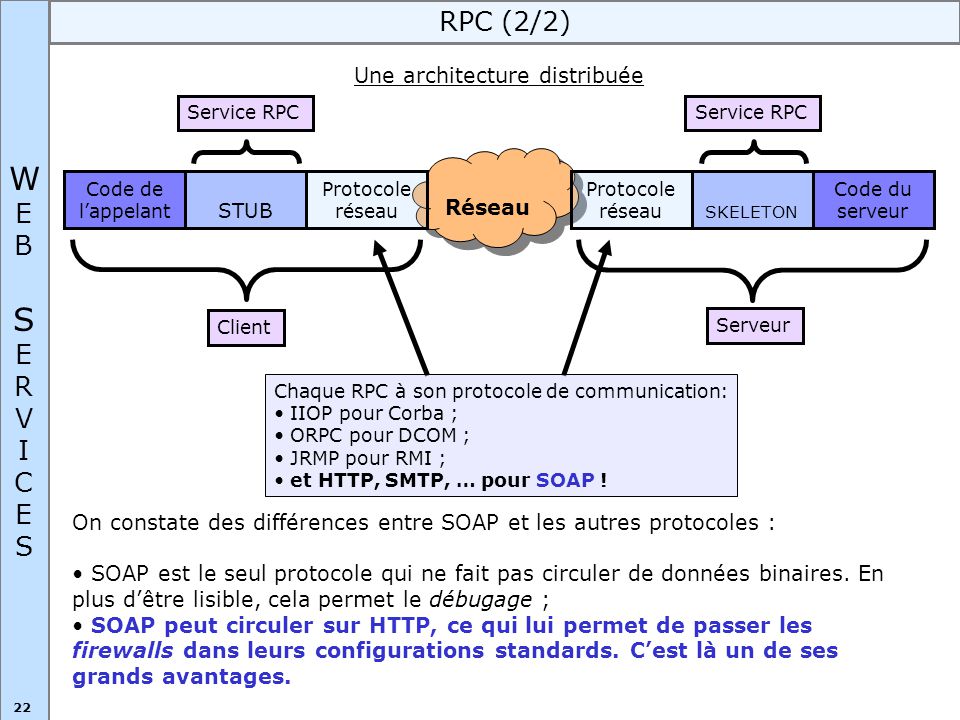 После нажатия кнопки «Добавить» вы увидите следующее:
После нажатия кнопки «Добавить» вы увидите следующее:
Ответные сообщения
Ответное сообщение имеет следующие панели:
XML — показывает XML-содержимое ответного сообщения:
Raw — показывает необработанные байты ответного сообщения:
Редактор структуры — показывает ответное сообщение в виде дерева только для чтения:
Обзорный редактор — показывает удобный для пользователя рендеринг ответа:
URL-адреса в ответном сообщении кликабельны. Они будут открыты в браузере по умолчанию.
Следующие шаги
Вложения и файлы
Аутентификация запросов SOAP
Аутентификация SPNEGO/Kerberos
Операции и запросы
Заголовки HTTP
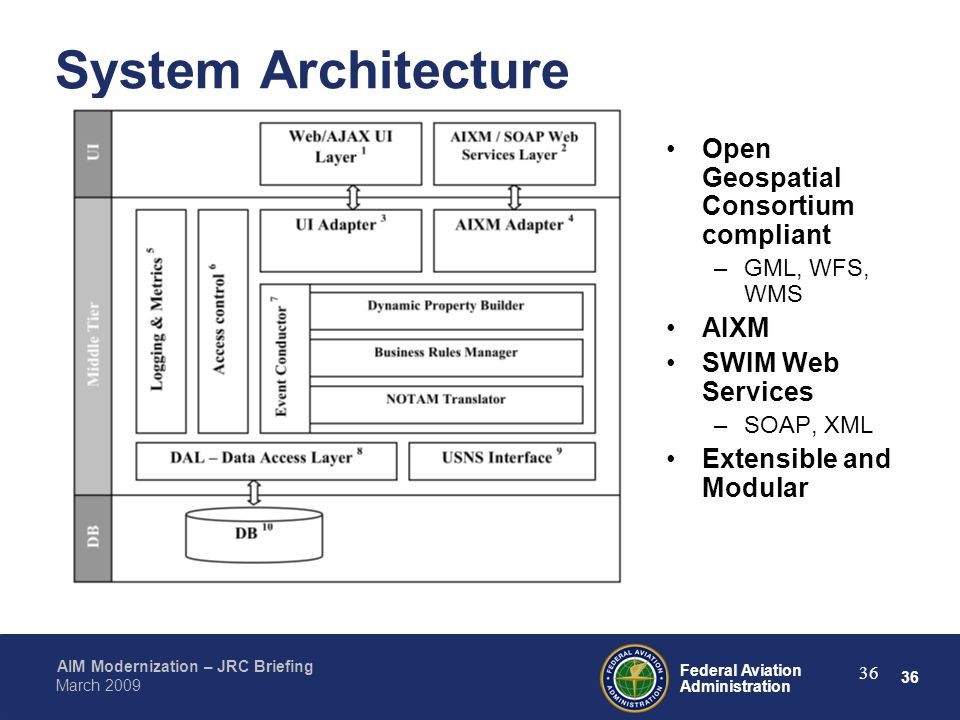
API SOAP | Пример протокола SOAP API | Интерфейс SOAP API
SOAP — важный протокол, который помог широко использовать веб-службы, также называемые API. На основе XML,
протокол SOAP все еще широко используется. Многие организации используют более гибкий шаблон REST API, но другие предпочитают
структура, управление типами данных и определенный стандарт SOAP.
На основе XML,
протокол SOAP все еще широко используется. Многие организации используют более гибкий шаблон REST API, но другие предпочитают
структура, управление типами данных и определенный стандарт SOAP.
В этом руководстве представлены общие сведения об API-интерфейсах SOAP, в том числе о том, как их вызывать, описывать и другие общие сведения. разделы, которые помогут вам понять основы истории протокола и его место в API веб-сервисов.
SOAP — это простой протокол доступа к объектам, стандарт обмена сообщениями, определенный консорциумом World Wide Web и его членами. редакторы. SOAP использует формат данных XML для объявления своих запросов и ответных сообщений, опираясь на XML-схему и другие технологии для обеспечения структуры своих полезных нагрузок.
Как общедоступные, так и частные интерфейсы прикладного программирования (API) используют SOAP в качестве интерфейса. Хотя более популярны в больших
предприятия, организации всех размеров производят и используют API-интерфейсы SOAP.
SOAP использует шаблон удаленного вызова процедур (RPC), где функции или методы передаются в качестве параметров и возвращают результат. Многие решения RPC до SOAP зависели от конкретных языков программирования или технологических стеков. За Например, предыдущие реализации RPC часто требовали, чтобы обе стороны RPC использовали язык программирования C, который предшествует современному Интернету. Даже язык эпохи Интернета, Java, имеет собственную модель RPC, называемую удаленным вызовом метода. (RMI), которая изначально была тесно связана с виртуальной машиной Java (JVM).
Одним из важных аспектов API-интерфейсов SOAP является их независимость от языка программирования и даже лежащего в основе транспорта.
протокол. Отправитель может использовать, например, C#, в то время как стек получателя опирается на Java. В то время как эти более
корпоративно-ориентированные языки наиболее распространены с SOAP, существуют реализации SOAP на Python, Ruby и всех современных языках.
языки программирования.
Последним преимуществом SOAP является его расширяемость. Стандартно его спецификация намеренно ограничена ограничениями. Таким образом, модель расширяемости в рамках спецификации SOAP обеспечивает возможность настройки.
Чтобы вызвать SOAP API, вам, скорее всего, потребуется включить библиотеку SOAP с вашим языком программирования. Несмотря на то что можно совершать вызовы SOAP API без библиотек SOAP, эффективнее работать с абстракцией, чем создание сообщений самостоятельно. Сообщения SOAP многословны, в основном из-за использования XML.
Хотя в следующих примерах для удобства чтения используется Python, помните, что SOAP не зависит от вашего программирования. язык. Чтобы получить профиль пользователя из вымышленного API SOAP, вы можете сделать следующий запрос, используя Zeep библиотека:
В этом примере мы инициируем клиент SOAP на основе конечной точки SOAP. Затем мы вызываем сервис, вызывая опция getuser с параметром идентификатора пользователя. Это простой пример, но он скрывает еще больше деталей сообщений SOAP.
за кулисами.
Это простой пример, но он скрывает еще больше деталей сообщений SOAP.
за кулисами.
Давайте посмотрим, как может быть структурирован этот SOAP-вызов:
Ответ может выглядеть примерно так:
Даже в этом простом примере фактические данные внутри сообщения окружены структурой SOAP. По сравнению с некоторыми более современные примеры запросов API, SOAP может показаться слишком сложным. Имейте в виду, что большинство разработчиков, создающих SOAP API вызовы используют библиотеку, которая обеспечивает более дружественный интерфейс.
Тем не менее, можно выполнять вызовы SOAP API с помощью типичного HTTP-запроса (большинство служб SOAP используют HTTP, хотя спецификация не зависит от протокола). Вот тот же вышеприведенный вызов с использованием библиотеки запросов Python:
В этом случае response.content будет включать необработанный XML-ответ, который необходимо проанализировать, чтобы определить
имя пользователя и любые другие данные, которые возвращает SOAP API.
В приведенных выше примерах уже показан формат сообщений SOAP API. В этом разделе вы можете лучше понимать несколько блоков XML, содержащихся в запросах SOAP. Хотя он преднамеренно минимален («S» в SOAP означает «простой», в конце концов), он обеспечивает основу для сложных реализаций.
Сообщения SOAP состоят из четырех блоков:
-
soap:Envelope -
мыло:Заголовок -
мыло: корпус -
мыло: Ошибка
Только мыло : требуется конверт и мыло : корпус . Однако каждый из них играет важную роль в API-интерфейсах SOAP. Ниже каждый из
эти конструкции SOAP рассматриваются отдельно.
Конверт SOAP
SOAP использует XML, но ему нужен способ отделить его от других документов XML. soap:бирка Envelope предоставляет механизм для
определить XML как SOAP.
Кроме того, для тега soap:Envelope требуется атрибут namespace ( xmlns:soap="http://www. для последней версии SOAP) и может дополнительно предоставить  w3.org/2003/05/soap-envelope/"
w3.org/2003/05/soap-envelope/" атрибут encodingStyle .
Все сообщение SOAP находится внутри конверта, включая остальные три блока.
В базовых примерах API SOAP, показанных в предыдущих разделах, заголовок был пустым. Хотя это необязательно, 9Мыло 0169: Коллектор делает
возможная расширяемость SOAP с помощью модулей SOAP. Эти модули могут быть обязательными или необязательными. В случае, если они
требуются, вы можете включить атрибут mustUnderstand со значением true .
SOAP Body
Как следует из названия и показано в примерах, soap:Body содержит большую часть сообщения SOAP. Можно использовать пространства имен
для описания того, какие данные ожидать в теле, но не требуются. На практике название процедуры,
параметры и данные проходят через тело SOAP.
Ошибка SOAP
Наконец, тег soap:Fault используется в теге soap:Body для сообщений об ошибках, когда вызов SOAP API не может
полный.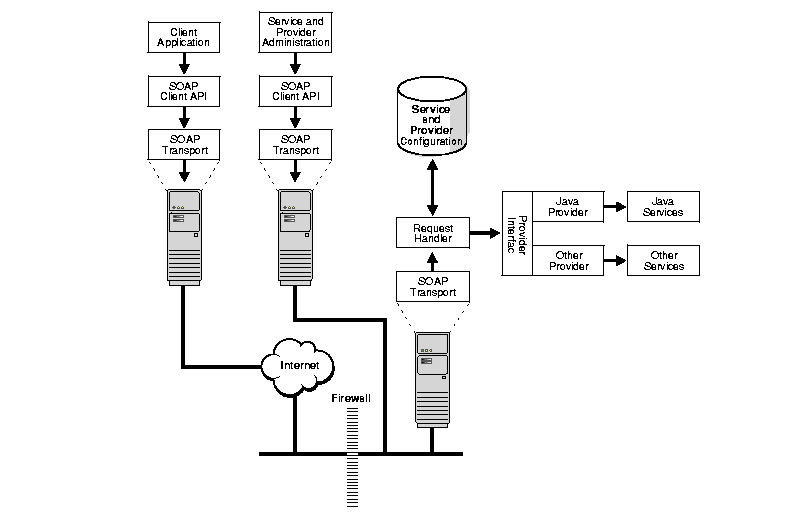 Существует много возможных причин ошибки, в том числе неточное форматирование SOAP, ошибка обработки на
сервер и несоответствующий тип данных.
Существует много возможных причин ошибки, в том числе неточное форматирование SOAP, ошибка обработки на
сервер и несоответствующий тип данных.
Чтобы сообщить о многих ошибках, в теге неисправности могут присутствовать несколько подэлементов:
-
Код: машиночитаемый код ошибки -
Причина: удобочитаемая причина ошибки -
Узел: узел SOAP, на котором произошла ошибка -
Роль: роль узла SOAP, на котором произошла ошибка -
Detail: подробные сведения об ошибках для конкретного приложения, с данными, которые могут быть прочитаны человеком и машиной
Хотя soap:Fault является необязательным, реализация SOAP не будет действительно полной без инкапсуляции потенциальных ошибок с использованием
этот тег.
По мере повсеместного распространения SOAP и других веб-служб для их поддержки было создано множество инструментов, технологий и стандартов. Среди них язык описания веб-служб (WSDL), формат XML, описывающий, как вызывать веб-службу. Это
определяет доступные операции и ожидаемые поля ввода/вывода.
Среди них язык описания веб-служб (WSDL), формат XML, описывающий, как вызывать веб-службу. Это
определяет доступные операции и ожидаемые поля ввода/вывода.
Хотя это и не относится к SOAP, многие реализации API-интерфейсов SOAP сочетают WSDL со схемой XML для обеспечения надежного веб-интерфейса. сервис для обмена сообщениями с использованием определенных процедур и типов полей. Поскольку WSDL является машиночитаемым, SOAP клиент мог определить, какие операции возможны, какие данные необходимы для завершения звонка, а затем предъявить пользователю с нужными данными.
WSDL также используются для создания удобочитаемой документации для SOAP API. Разработчики могут посмотреть на имена методов и ввод, чтобы определить, что требуется для вызова SOAP API. Кроме того, некоторые библиотеки языков программирования и разработчик среды могут использовать файл WSDL, чтобы помочь программистам с доступными методами и синтаксисом при написании кода.
Как и SOAP, WSDL достаточно универсален для многих типов использования, хотя эти две технологии часто используются вместе.
Многие примеры SOAP API, например запросы котировок акций или погоды, не имеют аутентификации. Хотя полезно для быстрого доказательство концепции, более надежные API-интерфейсы SOAP будут аутентифицировать и авторизовать вызовы API, гарантируя, что важные для бизнеса процессы доступны только для утвержденных сторон.
Как и в случае любого API или веб-службы, существует множество способов обеспечения безопасности в API-интерфейсах SOAP. Поскольку многие API-интерфейсы SOAP используют HTTP, в рамках этого протокола можно использовать другие схемы аутентификации и авторизации.
Например, HTTP Basic Auth принимает имя пользователя и пароль. При отправке через SSL/TLS это может быть простым способом аутентифицировать пользователя. Однако в этом методе нет встроенной роли или авторизации. Кроме того, пока это обеспечивает двухточечную безопасность, часто требуется сквозная безопасность.
WS-Security — это расширение SOAP, предоставляющее ряд функций безопасности для API-интерфейсов SOAP. Построен на основе XML
Спецификации шифрования и XML-подписи, WS-Security описывает, как подписывать и шифровать сообщения SOAP. Кроме того,
он поддерживает несколько форматов маркеров безопасности, включая SAML, X.509 и Kerberos.
Построен на основе XML
Спецификации шифрования и XML-подписи, WS-Security описывает, как подписывать и шифровать сообщения SOAP. Кроме того,
он поддерживает несколько форматов маркеров безопасности, включая SAML, X.509 и Kerberos.
Возможно, наиболее часто используемое расширение SOAP, WS-Security обеспечивает сквозную безопасность, авторизацию отправителей и другие функции, необходимые предприятиям в веб-сервисах.
Первая спецификация SOAP была опубликована в 2000 г. Более ранняя версия, выпущенная в 1998 г., была известна как XML-RPC и имела более сфокусированный набор функций. Как и SOAP, XML-RPC позволяет выполнять удаленные вызовы процедур через XML. XML-RPC специально использует только HTTP для передачи данных. Хотя это общий протокол для SOAP, технически SOAP может использовать любой протокол.
Потребовалось три года, чтобы спецификация SOAP достигла стадии рекомендации. Вскоре это стало наиболее распространенным подходом.
к веб-сервисам. До SOAP не существовало основанного на стандартах подхода к созданию программируемых интерфейсов для
обмен данными между системами.
