Что такое исходный код сайта. Как посмотреть HTML-код страницы или отдельного элемента в браузере. Разбираемся вместе с экспертами Ingate.
Исходный код сайта: что это и как его использовать
Что такое исходный код сайта? С этим вопросом сталкивались все, кто начинал осваивать интернет-маркетинг или веб-разработку. Казалось бы, можно просто воспользоваться поиском, чтобы получить ответ на этот вопрос. Но в таком случае вы получите сухое определение типа: исходный код страницы — это комплекс данных, состоящий из разметки HTML, скриптов JavaScript и CSS-стилей, которые сервер передает браузеру в ответ на соответствующие запросы. Много ли понимания подарит такое определение начинающему пользователю или специалисту? Вопрос риторический. Поэтому мы подготовили этот материал, чтобы простым языком подробно разобраться с тем, что такое исходный код сайта, как его узнать и использовать на практике. Итак, начнём.
Код сайта
Исходный код сайта
Суть темы простыми словами
Весь сайт, включая его программную часть и контент, хранится на сервере, который передает код страницы по запросу юзера. Запрос генерируется путем ввода URL в адресную строку или клика по функциональному элементу страницы. Вне зависимости от типа и сложности сайта главная задача сервера остается прежней: это отправка специальных тегов и текста в ответ на соответствующие запросы. Веб-код исходной страницы — это совокупность данных, которые включают в себя:
HTML-разметку;
исполнительные программы на JavaScript;
таблицу стилей CSS;
ссылки на отдельные файлы со стилевыми таблицами или кодом JS.
Любой браузер создан таким образом, чтобы быстро и корректно обрабатывать эти типы данных. Сервер же на них не реагирует, так как для его программного обеспечения — это только просто текстовые блоки, которые необходимо передать клиентской стороне.
Для чего нужно извлекать исходники
Просмотр кода страницы позволяет получить значительный массив информации, который можно, а часто и нужно использовать для технической и поисковой оптимизации веб-ресурса. Расшифровка кода сайта даёт возможность:
проанализировать метатеги собственного или стороннего проекта;
проверить наличие и провести идентификацию отдельных функциональных элементов кода, включая системы отслеживания, счётчики, скрипты и пр. ;
определить параметры шрифтов, размеров и цветов элементов оформления;
определить прямые ссылки к изображениям и другому контенту, размещённому на странице;
проанализировать все имеющиеся ссылки;
обнаружить технические проблемы, включая невалидный код, стили, не интегрированные в отдельные файлы, и пр.
И это только базовые возможности, которые открываются перед специалистом, который знает, как найти код и правильно «прочитать» его.
Как получить доступ к исходному документу
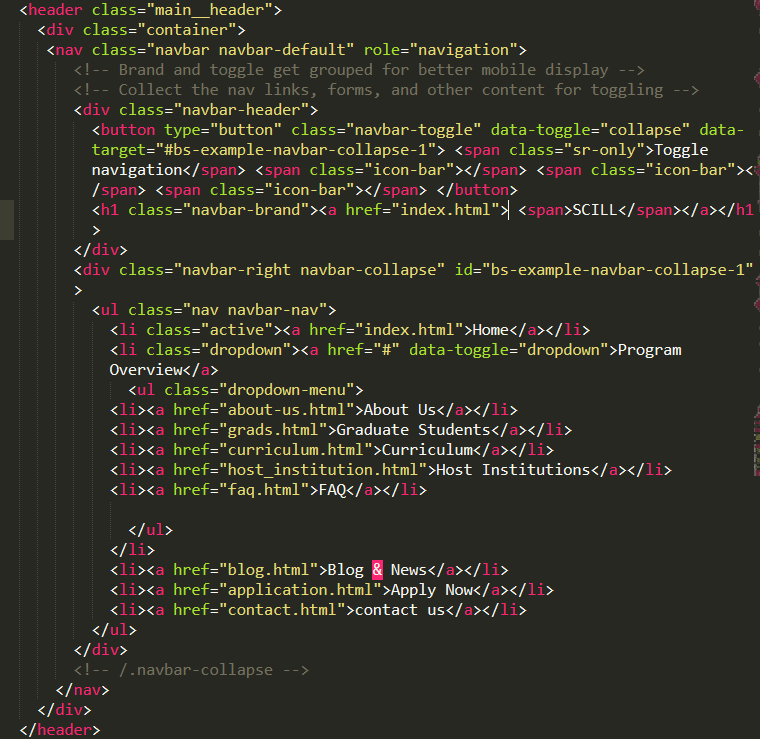
Сразу нужно сказать, что получить оригинальную и полную версию кода из браузера не получится, так как сервер все-таки несколько обрезает данные. Но проанализировать разметку можно, и довольно просто. Сейчас мы рассмотрим варианты получения кода страницы с помощью популярного обозревателя Google Chrome. Чтобы найти необходимые данные, нужно кликнуть правой кнопкой мыши по любому участку окна и выбрать в контекстном меню пункт «Просмотр кода страницы». После этого сразу откроется новая вкладка с полной версией site code, доступной для открытого доступа. Эту «стену текста» со спецсимволами сложно анализировать даже опытным разработчикам. Поэтому лучше воспользоваться специальными встроенными инструментами для разработчиков.
Как увидеть «дружелюбный» исходный код
Чтобы увидеть код главной страницы сайта, нужно кликнуть по значку с тремя точками или полосками. Перейдя в главное меню, следует найти «Инструменты разработчика». Сразу после этого появится окно, в котором в режиме реального времени будет отображаться исходный код. Теперь при клике мыши на отдельном элементе странице в интерактивном окне будет подсвечиваться соответствующий блок. Вкладка Source code позволяет проанализировать скрипты, шрифты, картинки и другие приложенные файлы. При необходимости отдельные фрагменты можно сохранить с помощью функции Save. Переход во вкладку Security даёт возможность просмотреть данные о сертификате безопасности, который используется на сайте. Вкладка Audits включает в себя функцию проверки веб-сайта по различным техническим параметрам.
Просмотр кода сайта
Исходный код страниц сайта
Как проанализировать метатеги
Все HTML-документы состоят из тегов, которые и определяют его структуру. Можно выделить следующие самые распространенные операторы:
Html – начало документа;
Head –директория служебных данных;
Title – заголовок страницы, который будет демонстрироваться в качестве подписи вкладки;
Body – тело документа.
h2 – H6 – заголовки основного текста;
Article – статья;
Section – раздел;
Menu – меню;
Div – отдельный блок;
Span – строка;
P – абзац.
Table – таблица.
Эти элементы разметки нужны для логического форматирования контента на странице. При желании разработчик может оформить документ с помощью стилей. Тег Head необходим для передачи браузеру и серверу служебных данных, необходимых для корректного отображения. Отдельного внимания заслуживает тег Link. В его рамках прописываются адреса ссылок на внешние файлы. При необходимости их содержимое можно скопировать для переноса на диск или в код собственного сайта. Для этого нужно направить курсор мыши на адрес и кликнуть правой кнопкой. После этого откроется контекстное меню, в котором нужно активировать функцию Open in new Tab. Это откроет новую вкладку с целевым файлом, с которым можно будет подробно ознакомиться или сохранить.
Как отладить скрипт с помощью исходного кода
Для реализации этой задачи лучше открыть код сайта на локальном сервере. Если в правке нуждаются только стили, скрипты или разметка, то все операции можно проводить непосредственно в корневой директории. HTML-код сайта будет отображаться без изменений. Но если перейти во вкладку Console, то здесь будут подсвечиваться все присутствующие ошибки JS. Консоль укажет название ошибки, а также покажет номер строки с её локализацией.
Как проанализировать код отдельной части страницы
Поиск в коде страницы современных сайтов часто осложняется большим объёмом элементов в документе. Из-за этого быстро найти конкретный элемент без специальных вспомогательных инструментов практически невозможно. Для этих целей предусмотрена специальная команда. Чтобы воспользоваться ей, нужно навести курсор на целевой элемент и вызвать контекстное меню правой кнопкой мыши. Здесь следует выбрать команду «Просмотреть код». После этого откроется стандартное окно, но с уже подсвеченным элементом.
Подведём итоги
Теперь вы знаете, как зайти посмотреть и пользоваться исходным кодом страницы. Согласитесь, это не так сложно, как казалось до прочтения этой статьи. Эти знания точно помогут в поисковой и технической оптимизации сайтов.
ЧИТАЙ ТАКЖЕ
Вики-разметка ВКонтакте для чайников
Гид по API Google Maps: разбираем по шагам
Как написать письмо в службу поддержки Яндекса
Структура HTML-кода | htmlbook.ru
Если открыть любую веб-страницу, то она будет содержать в себе типичные элементы,
которые не меняются от вида и направленности сайта. В примере 4.1 показан
код простого документа, содержащего основные теги.
Пример 4.1. Исходный код веб-страницы
<!DOCTYPE HTML PUBLIC "-//W3C//DTD HTML 4.01//EN" "http://www.w3.org/TR/html4/strict.dtd">
<html>
<head>
<meta http-equiv="Content-Type" content="text/html; charset=utf-8">
<title>Пример веб-страницы</title>
</head>
<body>
<h2>Заголовок</h2>
<!-- Комментарий -->
<p>Первый абзац.</p>
<p>Второй абзац.</p>
</body>
</html>
Скопируйте содержимое данного примера и сохраните его в папке c:\www\ под
именем example41.html. После этого запустите браузер и откройте файл через пункт меню Файл > Открыть
файл (Ctrl+O). В диалоговом окне выбора документа укажите файл example41.html. В браузере откроется веб-страница, показанная на рис. 4.1.
Рис. 4.1. Результат выполнения примера
Далее разберем отдельные строки нашего кода.
<!DOCTYPE HTML PUBLIC "-//W3C//DTD HTML 4.01//EN" "http://www.w3.org/TR/html4/strict.dtd">
Элемент <!DOCTYPE> предназначен для указания типа текущего документа —
DTD (document type definition, описание типа документа). Это необходимо, чтобы
браузер понимал, как следует интерпретировать текущую веб-страницу, ведь HTML
существует в нескольких версиях, кроме того, имеется XHTML (EXtensible HyperText
Markup Language, расширенный язык разметки гипертекста), похожий на HTML, но
различающийся с ним по синтаксису. Чтобы браузер «не путался» и понимал,
согласно какому стандарту отображать веб-страницу и необходимо в первой строке
кода задавать <!DOCTYPE>.
Существует несколько видов <!DOCTYPE>, они различаются в зависимости
от версии HTML, на которую ориентированы. В табл. 4.1. приведены основные
типы документов с их описанием.
Табл. 4.1. Допустимые DTD
DOCTYPE
Описание
HTML 4.
01
<!DOCTYPE HTML PUBLIC «-//W3C//DTD
HTML 4.01//EN» «http://www.w3.org/TR/html4/strict.dtd»>
Строгий синтаксис HTML.
<!DOCTYPE HTML PUBLIC «-//W3C//DTD
HTML 4.01 Transitional//EN» «http://www.w3.org/TR/html4/loose.dtd»>
Переходный синтаксис HTML.
<!DOCTYPE HTML PUBLIC «-//W3C//DTD
HTML 4.01 Frameset//EN» «http://www.w3.org/TR/html4/frameset.dtd»>
В HTML-документе применяются фреймы.
HTML 5
<!DOCTYPE html>
В этой версии HTML только один доктайп.
XHTML 1.0
<!DOCTYPE html PUBLIC «-//W3C//DTD
XHTML 1.0 Strict//EN» «http://www.w3.org/TR/xhtml1/DTD/xhtml1-strict.dtd»>
Строгий синтаксис XHTML.
<!DOCTYPE html PUBLIC «-//W3C//DTD
XHTML 1.0 Transitional//EN» «http://www.w3.org/TR/xhtml1/DTD/xhtml1-transitional. dtd»>
Переходный синтаксис XHTML.
<!DOCTYPE html PUBLIC «-//W3C//DTD
XHTML 1.0 Frameset//EN» «http://www.w3.org/TR/xhtml1/DTD/xhtml1-frameset.dtd»>
Документ написан на XHTML и содержит фреймы.
XHTML 1.1
<!DOCTYPE html PUBLIC «-//W3C//DTD XHTML 1.1//EN» «http://www.w3.org/TR/xhtml11/DTD/xhtml11.dtd»>
Разработчики XHTML 1.1 предполагают,
что он постепенно вытеснит HTML. Как видите, никакого деления на виды
это определение не имеет, поскольку синтаксис один и подчиняется четким
правилам.
Разница между строгим и переходным описанием документа состоит в различном
подходе к написанию кода документа. Строгий HTML требует жесткого соблюдения
спецификации HTML и не прощает ошибок. Переходный HTML более «спокойно» относится
к некоторым огрехам кода, поэтому этот тип в определенных случаях использовать
предпочтительнее.
Например, в строгом HTML и XHTML непременно требуется наличие тега <title>,
а в переходном HTML его можно опустить и не указывать. При этом помним, что
браузер в любом случае покажет документ, независимо от того, соответствует
он синтаксису или нет. Подобная проверка осуществляется при помощи валидатора
и предназначена в первую очередь для разработчиков, чтобы отслеживать ошибки
в документе.
В дальнейшем будем применять преимущественно строгий <!DOCTYPE>, кроме
случаев, когда это оговаривается особо. Это позволит нам избегать типичных
ошибок и приучит к написанию синтаксически правильного кода.
Часто можно встретить код HTML вообще без использования <!DOCTYPE>,
веб-страница в подобном случае все равно будет показана. Тем не менее, может
получиться, что один и тот же документ отображается в браузере по-разному при
использовании <!DOCTYPE> и без него. Кроме того,
браузеры могут по-своему показывать такие документы, в итоге страница «рассыплется»,
т.е. будет отображаться совсем не так, как это требуется разработчику. Чтобы
не произошло подобных ситуаций, всегда добавляйте <!DOCTYPE> в начало документа.
<html>
Тег <html> определяет начало HTML-файла, внутри него хранится заголовок
(<head>) и тело документа (<body>).
<head>
Заголовок документа, как еще называют блок <head>, может содержать текст
и теги, но содержимое этого раздела не показывается напрямую на странице, за
исключением контейнера <title>.
Тег <meta> является универсальным и добавляет целый класс возможностей,
в частности, с помощью метатегов, как обобщенно называют этот тег, можно изменять
кодировку страницы, добавлять ключевые слова, описание документа и многое другое.
Чтобы браузер понимал, что имеет дело с кодировкой UTF-8 (Unicode transformation format, формат преобразования Юникод) и добавляется данная строка.
<title>Пример веб-страницы</title>
Тег <title> определяет заголовок веб-страницы, это один из важных элементов
предназначенный для решения множества задач. В операционной системе Windows
текст заголовка отображается в левом верхнем углу окна браузера (рис. 4.2).
Рис. 4.2. Вид заголовка в браузере
Тег <title> является обязательным и должен непременно присутствовать
в коде документа.
</head>
Обязательно следует добавлять закрывающий тег </head>, чтобы показать,
что блок заголовка документа завершен.
<body>
Тело документа <body> предназначено для размещения тегов и содержательной
части веб-страницы.
<h2>Заголовок</h2>
HTML предлагает шесть текстовых заголовков разного уровня, которые показывают
относительную важность секции, расположенной после заголовка. Так, тег <h2> представляет
собой наиболее важный заголовок первого уровня, а тег <h6> служит
для обозначения заголовка шестого уровня и является наименее значительным.
По умолчанию, заголовок первого уровня отображается самым крупным шрифтом
жирного начертания, заголовки последующего уровня по размеру меньше.
Теги <h2>…<h6> относятся
к блочным элементам, они всегда начинаются с новой строки, а после них другие
элементы отображаются на следующей строке. Кроме того, перед заголовком и
после него добавляется пустое пространство.
<!-- Комментарий -->
Некоторый текст можно спрятать от показа в браузере, сделав его комментарием.
Хотя такой текст пользователь не увидит, он все равно будет передаваться
в документе, так что, посмотрев исходный код, можно обнаружить скрытые заметки.
Комментарии нужны для внесения в код своих записей, не влияющих на вид страницы.
Начинаются они тегом <!— и заканчиваются тегом —>. Все, что находится
между этими тегами, отображаться на веб-странице не будет.
<p>Первый абзац.</p>
Тег <p> определяет абзац (параграф) текста. Если закрывающего тега нет,
считается, что конец абзаца совпадает с началом следующего блочного элемента.
<p>Второй абзац. </p>
Тег <p> является блочным элементом, поэтому текст всегда начинается
с новой строки, абзацы идущие друг за другом разделяются между собой отбивкой (так называется пустое пространство между ними). Это хорошо видно на рис. 4.1.
</body>
Следует добавить закрывающий тег </body>, чтобы показать, что тело документа
завершено.
</html>
Последним элементом в коде всегда идет закрывающий тег </html>.
Как утащить простой сайт за 5 минут
Когда начинаешь практиковаться в вёрстке сайтов, может быть очень полезно разобраться, как устроены сайты у других ребят. Вот как это сделать.
👉 Всё, что мы делаем в этой статье, мы делаем в учебных целях. Если вы просто скопируете себе чужой сайт и будете выдавать его за свой, это может плохо кончиться.
💡 На самом деле всё сказанное в этой статье нужно для тех, кто боится отключения интернета и хочет сохранить у себя на компьютере самую важную информацию. Но эта мысль бредовая сразу на стольких уровнях, что мы стесняемся её произносить вслух. Разве что шёпотом.
В чём идея
Мы будем копировать чужой сайт, чтобы его можно было запустить на своём сервере или на домашнем компьютере. Задача — не просто открыть сайт в браузере и посмотреть его код, а забрать из него все важные файлы — и стили, и скрипты, и изображения. Чтобы было проще, мы будем практиковаться на одностраничном сайте, но всё то же самое будет работать и на многостраничном.
❌ Мы не сможем утащить чужие PHP-скрипты и страницы, связанные с данными пользователя (например, не сможем утащить из интернет-магазина рабочую версию корзины с покупками). Для этого нужен доступ к файлам сервера, а этого у нас нет.
Главный принцип этой работы: когда ваш браузер запрашивает страницу чужого сайта, веб-сервер отправляет ему эту страницу, в буквальном смысле. То же с картинками, стилями и скриптами: каждый раз, когда вы посещаете сайт, вы как будто делаете его копию у себя на компьютере. Браузер получает страницу от сервера и выводит её копию на экран, а в памяти держит исходный код. Разве что он не сохраняет эту страницу на диск, чтобы вы могли её редактировать.
Вот этот последний этап мы и исправим: теперь мы будем сохранять чужие сайты к себе на диск.
Весь процесс покажем на примере сайта ux-posters.ru – простом одностраничном сайте, где есть картинки, стили и скрипты. Автору этого текста пришлось помогать авторам этого сайта с похожей задачей, так что пример свеженький.
Быстрый путь: грабберы
Есть категория программ под названием «веб-грабберы», или «веб-рипперы». Они работают так:
Ты говоришь программе, на какую страницу сайта зайти.
Программа собирает все ссылки с этой страницы, переходит по этим ссылкам и строит себе виртуальную карту сайта — то есть пытается понять, сколько на этом сайте страниц и как они связаны.
Потом граббер начинает ползать по этим страницам подряд, запрашивать их у сервера, получать ответы и сохранять ответы на вашем жёстком диске.
В какой-то момент граббер останавливается, потому что он скачал все доступные ему страницы с этого сайта.
После работы граббер оставляет у вас на диске гору файлов, которые представляют собой статичный отпечаток чужого сайта. Эту гору можно загрузить на собственный сервер, и издалека это будет похоже на чужой сайт.
✅ Плюсы: граббер может быстро охватить много страниц и скачать из них огромное количество стилей, картинок и всего подряд. Работа очень быстрая и хорошо автоматизирована.
❌ Минусы: часто он качает всё без разбора, оставляя на диске много дублей. Также он бессилен с сайтами, в которых контент выводится динамически или имеет нестандартную систему адресации.
💡 В целом грабберы можно использовать, чтобы скачивать сайты библиотек, архивов и других мест, где документов много и всё устроено логично. Например, с помощью граббера можно скачать какую-нибудь классическую книгу из онлайн-библиотеки.
Вот ссылки на грабберы для разных платформ:
HTTrack — старый интерфейс из нулевых, но свою задачу выполняет полностью. Бесплатный и надёжный, работает везде.
Getleft — мультиплатформенный граббер, который пытается выкачивать всё, до чего дотянется, включая PHP-скрипты.
Cyotek WebCopy — для тех, кто любит только Windows, тоже бесплатный.
Типичный интерфейс типичного граббера
Сложный путь: ручное сохранение
Допустим, мы хотим сохранить какую-то отдельную страницу сайта или конкретные её части (например, картинки). Но эти картинки как-то так хитро встроены, что вы не можете просто нажать «Сохранить картинку как…». Тогда потребуется ручной метод.
Заходим на страницу и нажимаем в браузере Ctrl + I (в Виндоус) или ⌥ + ⌘ + I (если у вас мак). Появляется окно «Инспектора», где видна внутренняя структура страницы:
Мы видим, что текущий документ в браузере состоит:
из страницы index.html;
скрипта likely.js;
четырёх таблиц стилей;
шрифтов, подключённых через сервис Google;
папки с картинками.
Шрифты нам скачивать необязательно — сайт и так их подключит с сервера гугла, а всё остальное скачать нужно. Чтобы не создавать хаос на компьютере, создадим сначала папку ux-posters — в ней будет храниться наш сайт. Потом в эту папку сохраняем все файлы таким способом:
Нажимаем правой кнопкой мыши на очередной файл.
Выбираем пункт Save as, или «Сохранить как».
Пишем имя и расширение файла — точно так, как указано в списке.
Если лень писать самому — скопируйте перед этим название файла, нажав правую кнопку мыши и выбрав Copy file name, или «Скопировать имя файла».
Чаще всего название файла подставится само, но если нет — смотрите пункт 4.
Исключения в названии файлов два:
(index) — это index.html.
В любом файле знак вопроса и всё, что после него, писать не нужно.
Скачать можно всё, а можно только то, что вам нужно для работы и экспериментов. Например, если вам нужны только стили и код страницы, сохраняйте файлы .css и (index). Если нужны картинки, заходите в папку pics и сохраняйте всё оттуда.
Щёлкаем на очередном файле и выбираем «Сохранить как»Выбираем нашу папку для сохранения и пишем имя файла
Что в итоге
Если мы пройдёмся по всем папкам и сохраним в них всё нужное нам, у нас получится локальный слепок сайта. Теперь можно:
Изучить, как он устроен, что-то отредактировать и увидеть результат у себя на компьютере.
Открыть файл index.html в браузере, и будет ощущение, что вы зашли на сайт, но с локального компьютера. Сайт откроется по протоколу file:// — это так браузер говорит нам, что файл взялся с нашего компьютера, а не из интернета.
Запустить MAMP и завести на нём локальную копию сайта для экспериментов. Тогда браузер будет думать, что ходит за этим сайтом в интернет. Можно написать какие-нибудь php-скрипты и оживить сайт.
Что нужно поставить на компьютер, чтобы делать сайты
💡 Важно понимать, что перед нами именно «слепок» — то, что мы бы увидели, если бы сервер сегодня ответил на наш запрос. Если завтра сервер будет отвечать по-другому, мы этого в своей локальной копии не увидим.
Когда ещё это пригодится
Защитить сайт перед наплывом пользователей. С помощью грабберов можно быстро создать неубиваемую статическую копию сайта и временно подменить ей динамическую версию сайта. Это полумера, но может сработать. А вообще вместо этого есть специальные надстройки, которые делают почти то же самое, но более умно, — поищите слово «кеширование».
Делаем неубиваемый сайт: статика и динамика
Сделать копию своего блога, личного сайта или ещё чего-то важного вам, если вы потеряли к нему доступ, но сайт всё ещё на ходу.
Если вы едете туда, где не будет интернета, а вам нужна информация с сайта (например, путеводитель по чужой стране). Помните, что динамические карты и видеоролики так не сохранятся.
Сделать собственный «веб-архив» — это сервис, который ползает по сайтам и делает их «слепки» для истории. Благодаря этому сервису можно посмотреть, как выглядели ваши любимые сайты много лет назад — например, Яндекс.
Текст:
Михаил Полянин
Редактор:
Максим Ильяхов
Художник:
Даня Берковский
Корректор:
Ирина Михеева
Вёрстка:
Кирилл Климентьев
Соцсети:
Олег Вешкурцев
Тег источника HTML
❮ Предыдущий
Полный справочник HTML
Далее ❯
Пример
Аудиоплеер с двумя исходными файлами. Браузер выберет первый <источник> он поддерживает:
<управление звуком> Ваш браузер не поддерживает аудио элементы.
Попробуйте сами »
Другие примеры «Попробуйте сами» ниже.
Определение и использование
Тег используется для указания нескольких медиа-ресурсов для медиа-элементов, таких как <видео>, <аудио>,
и <картинка>.
Тег позволяет указать альтернативное видео/аудио/изображение
файлы, из которых браузер может выбирать в зависимости от поддержки браузера или области просмотра
ширина. Браузер выберет первый он поддерживает.
Поддержка браузера
Цифры в таблице указывают на первую версию браузера, полностью поддерживающую элемент.
Элемент
<источник>
4,0
9,0
3,5
4,0
10,5
Атрибуты
Атрибут
Значение
Описание
СМИ
медиа_запрос
Принимает любой допустимый медиа-запрос, который обычно определяется в CSS
размеры
Задает размеры изображений для разных макетов страниц
источник
URL-адрес
Требуется, когда <источник> используется в <аудио> и <видео>. Указывает URL-адрес медиафайла
источник
URL-адрес
Требуется, когда <источник> используется в <изображении>. Указывает URL-адрес
изображение для использования в различных ситуациях
тип
MIME-тип
Указывает MIME-тип ресурса
Глобальные атрибуты
Тег также поддерживает глобальные атрибуты в HTML.
Атрибуты событий
Тег также поддерживает атрибуты событий в HTML.
Дополнительные примеры
Пример
Используйте в
Попробуйте сами »
Пример
Используйте внутри для определения различных изображений на основе
ширина области просмотра:
jpg»>
Попробуйте сами »
Связанные страницы
Учебник по HTML: HTML Видео
Учебник по HTML: HTML Аудио
Справочник по HTML DOM: Источник Объект
Настройки CSS по умолчанию
Нет.
❮ Предыдущий
Полный справочник HTML
Далее ❯
НОВИНКА
Мы только что запустили Видео W3Schools
Узнать
ВЫБОР ЦВЕТА
КОД ИГРЫ
Играть в игру
Лучшие учебники
Учебник по HTML Учебник по CSS Учебник по JavaScript Учебник How To Учебник по SQL Учебник по Python Учебник по W3.CSS Учебник по Bootstrap Учебник по PHP Учебник по Java Учебник по C++ Учебник по jQuery
W3Schools оптимизирован для обучения и обучения. Примеры могут быть упрощены для улучшения чтения и обучения.
Учебники, ссылки и примеры постоянно пересматриваются, чтобы избежать ошибок, но мы не можем гарантировать полную правильность всего содержания.
Используя W3Schools, вы соглашаетесь прочитать и принять наши условия использования,
куки-файлы и политика конфиденциальности.
Copyright 1999-2022 Refsnes Data. Все права защищены. W3Schools работает на основе W3.CSS.
&двоеточие; Элемент Media или Image Source — HTML: Язык разметки гипертекста
HTML-элемент указывает несколько медиаресурсов для элемента , элемента или элемента . Это элемент void, что означает, что он не имеет содержимого и не имеет закрывающего тега. Он обычно используется для предоставления одного и того же мультимедийного контента в нескольких форматах файлов, чтобы обеспечить совместимость с широким спектром браузеров, учитывая их различную поддержку форматов файлов изображений и форматов файлов мультимедиа.
Этот элемент включает глобальные атрибуты.
тип
Тип носителя MIME ресурса, необязательно с параметром codecs .
источник
Требуется, если родительским элементом исходного элемента является элемент и , но не допускается, если родительским элементом исходного элемента является элемент <картинка> элемент.
Адрес медиаресурса.
источник
Требуется, если родительским элементом исходного элемента является элемент , но не допускается, если родительским элементом исходного элемента является элемент или .
Список из одной или нескольких строк, разделенных запятыми, указывающих набор возможных изображений, представленных источником для использования браузером. Каждая строка состоит из:
Один URL-адрес, указывающий изображение.
Дескриптор ширины, состоящий из строки, содержащей положительное целое число, за которым непосредственно следует "w" , например 300w . Значение по умолчанию, если оно отсутствует, равно бесконечности.
Дескриптор плотности пикселей, представляющий собой положительное число с плавающей запятой, за которым непосредственно следует "x" . Значение по умолчанию, если оно отсутствует, равно 1x .
Каждая строка в списке должна иметь по крайней мере дескриптор ширины или дескриптор плотности пикселей, чтобы быть допустимой. Среди списка должна быть только одна строка, содержащая один и тот же кортеж дескриптора ширины и дескриптора плотности пикселей. Браузер выбирает наиболее подходящее изображение для отображения в данный момент времени. Если используются дескрипторы ширины, 9Атрибут 0023 размеры также должен присутствовать, иначе значение srcset будет проигнорировано.
размеры
Разрешено, если родительским элементом исходного элемента является элемент , но не разрешено, если родительским элементом исходного элемента является элемент или .
Список исходных размеров, описывающий окончательную визуализируемую ширину изображения, представленного источником. Каждый исходный размер состоит из разделенного запятыми списка пар «условие-длина носителя». Эта информация используется браузером, чтобы определить перед выводом страницы, какое изображение определено в srcset для использования. Обратите внимание, что размеры будут действовать только в том случае, если дескрипторы размеров ширины предоставлены с srcset вместо значений соотношения пикселей (например, 200w вместо 2x).
носитель
Разрешено, если родительским элементом исходного элемента является элемент , но не разрешено, если родительским элементом исходного элемента является элемент или <видео> элемент.
Медиа-запрос предполагаемого носителя ресурса.
высота
Разрешено, если родительским элементом исходного элемента является элемент , но не разрешено, если родительским элементом исходного элемента является элемент или .
Внутренняя высота изображения в пикселях. Должно быть целым числом без единицы.
ширина
Разрешено, если родительским элементом исходного элемента является элемент , но не разрешено, если родительским элементом исходного элемента является элемент или .
Внутренняя ширина изображения в пикселях. Должно быть целым числом без единицы.
Если атрибут type не указан, тип носителя извлекается с сервера и проверяется, может ли пользовательский агент его обработать; если это не может быть отображено, следующие <источник> проверено. Если указан атрибут типа , он сравнивается с типами, которые может представлять пользовательский агент, и, если он не распознан, сервер даже не запрашивается; вместо этого сразу проверяется следующий элемент .
При использовании в контексте элемента браузер вернется к использованию изображения, указанного дочерним элементом элемента , если он не сможет найти подходящее изображение для использовать после изучения каждого предоставленного <источник> .
Элемент является пустым элементом , что означает, что он не только не имеет содержимого, но и не имеет закрывающего тега. То есть вы никогда не используете «» в своем HTML.
Информацию о форматах изображений, поддерживаемых веб-браузерами, и рекомендации по выбору подходящих форматов см. в нашем руководстве по типам и форматам файлов изображений в Интернете. Подробнее о типах видео и аудио, которые вы можете использовать, см. в Руководстве по форматам типов мультимедиа, используемых в Интернете.
Пример видео
В этом примере показано, как предлагать видео в формате Ogg для пользователей, браузеры которых поддерживают формат Ogg, и видео в формате QuickTime для пользователей, браузеры которых поддерживают этот формат. Если элемент audio или video не поддерживается браузером, вместо него отображается уведомление. Если браузер поддерживает элемент, но не поддерживает ни один из указанных форматов, возникает событие error , а элементы управления мультимедиа по умолчанию (если они включены) будут указывать на ошибку. Обязательно ознакомьтесь с нашим руководством по типам и форматам медиафайлов в Интернете, чтобы узнать, какие форматы медиафайлов вы можете использовать и насколько хорошо они поддерживаются браузерами.
<управление видео>
Мне жаль; ваш браузер не поддерживает HTML-видео.
Дополнительные примеры см. в статье области обучения Видео- и аудиоконтент — отличный ресурс.
Пример изображения
В этом примере два элемента включены в , предоставляя версии изображения для использования, когда доступное пространство превышает определенную ширину. Если доступная ширина меньше наименьшей из этих ширин, пользовательский агент вернется к изображению, заданному элементом .
<картинка>
С элементом вы всегда должны включать с резервным изображением с атрибутом alt для обеспечения доступности (если только изображение не является нерелевантным фоновым декоративным изображением).
Спецификация
HTML Standard # the-source-element
Загрузка только 90 таблиц в браузере BCD. Включите JavaScript для просмотра данных.
Руководство по типам и форматам мультимедиа в Интернете
Руководство по типам и форматам файлов изображений
<картинка> элемент
<аудио> элемент
<видео> элемент
Веб-производительность
Последнее изменение: , участниками MDN
Как читать исходный код веб-сайта
Под всеми изображениями, текстом и призывами к действию на вашем веб-сайте находится исходный код вашей веб-страницы.
Google и другие поисковые системы «читают» этот код, чтобы определить, где ваши веб-страницы должны отображаться в их индексах для данного поискового запроса.
Это краткое руководство покажет вам, как читать исходный код вашего собственного веб-сайта, чтобы убедиться, что он оптимизирован для SEO. Я также рассмотрю несколько других ситуаций, когда знание того, как просматривать и анализировать нужные части исходного кода, может помочь в других маркетинговых усилиях.
Как просмотреть исходный код
Первым шагом в проверке исходного кода вашего веб-сайта является просмотр фактического кода. Каждый веб-браузер позволяет вам сделать это легко. Ниже приведены команды клавиатуры для просмотра исходного кода вашей веб-страницы для ПК и Mac.
ПК
Firefox: CTRL + U (это означает, что нажмите и удерживайте клавишу CTRL на клавиатуре. Удерживая клавишу CTRL, нажмите клавишу «u».) Кроме того, вы можете перейти к меню «Firefox», а затем нажмите «Веб-разработчик», а затем «Источник страницы».
Edge/ Internet Explorer : CTRL + U. Или щелкните правой кнопкой мыши и выберите «Просмотр исходного кода».
Chrome : CTRL + U. Или вы можете нажать на странную клавишу с тремя горизонтальными линиями в правом верхнем углу. Затем нажмите «Инструменты» и выберите «Просмотр исходного кода».
Opera : CTRL + U. Вы также можете щелкнуть правой кнопкой мыши веб-страницу и выбрать «Просмотреть исходный код страницы».
Mac
Safari: Комбинация клавиш — Option+Command+U. Вы также можете щелкнуть правой кнопкой мыши веб-страницу и выбрать «Показать исходный код страницы».
Firefox : вы можете щелкнуть правой кнопкой мыши и выбрать «Источник страницы» или перейти в меню «Инструменты», выбрать «Веб-разработчик» и нажать «Источник страницы». Сочетание клавиш Command + U.
Chrome: Перейдите к «Просмотр», нажмите «Разработчик», а затем «Просмотреть исходный код». Вы также можете щелкнуть правой кнопкой мыши и выбрать «Просмотреть исходный код страницы». Комбинация клавиш — Option+Command+U.
Если вы знаете, как просматривать исходный код, вам нужно знать, как искать в нем что-то. Обычно те же функции поиска, которые вы используете для обычного просмотра веб-страниц, применимы к поиску в вашем исходном коде. Такие команды, как CTRL + F (для поиска), помогут вам быстро просмотреть исходный код на наличие важных элементов SEO.
Теги заголовка исходного кода
Тег заголовка — это святой Грааль SEO на странице. Это самое важное в вашем исходном коде. Если вы хотите что-то вынести из этой статьи, обратите внимание на это:
Вы знаете, какие результаты выдает Google, когда вы что-то ищете?
Все эти результаты получены из тегов заголовков веб-страниц, на которые они указывают. Если у вас нет тегов title в исходном коде, вы не сможете появиться в Google (или в любой другой поисковой системе, если уж на то пошло). Хотите верьте, хотите нет, но я действительно видел веб-сайты без тегов заголовков!
Теперь давайте быстро поищем в Google термин «Руководства по маркетингу»:
Вы можете видеть, что первый результат относится к разделу блога KISSmetrics, посвященному маркетинговым руководствам. Если мы нажмем на этот первый результат и просмотрим исходный код страницы, мы увидим тег заголовка:
Тег заголовка обозначается открывающим тегом:
. Заканчивается закрывающим тегом:. Тег title обычно находится в верхней части исходного кода в разделе.
Вы можете видеть, что содержимое внутри тега title совпадает с тем, что используется в заголовке первого результата Google.
Мало того, что теги заголовков необходимы для включения в результаты поиска Google, Google также определяет важные ключевые слова в вашем заголовке, которые, по их мнению, имеют отношение к поисковым запросам пользователей.
Если вы хотите, чтобы определенная веб-страница ранжировалась по определенной теме, вам лучше убедиться, что слова, описывающие эту тему, находятся в теге заголовка. Чтобы узнать больше о важности ключевых слов и тегов заголовков в общей архитектуре сайта, ознакомьтесь с этой статьей.
И последнее, что нужно помнить: каждая веб-страница на вашем веб-сайте должна иметь уникальный тег заголовка. Никогда не дублируйте этот контент.
Если у вас небольшой веб-сайт, например, 10 или 20 страниц, достаточно просто проверить уникальность каждого тега заголовка. Однако, если у вас большой веб-сайт, вам понадобится помощь. Это простой четырехэтапный процесс:
Шаг № 1: Откройте Ubersuggest, введите свой URL-адрес и нажмите «Поиск»
Шаг № 2: Нажмите «Аудит сайта» на левой боковой панели
Шаг № 3 : Обзор основных проблем SEO
После перехода к обзору аудита сайта прокрутите вниз до четвертого раздела результатов (он последний на странице), чтобы просмотреть основные проблемы SEO.
Здесь вы найдете дублирующиеся теги заголовков или метаописания. Если здесь ничего не отображается, вы в безопасности. Если вы видите дубликаты, например, 30 страниц моего веб-сайта, копайте глубже.
Шаг № 4: Нажмите «Страницы с повторяющимися тегами
 Запрос генерируется путем ввода URL в адресную строку или клика по функциональному элементу страницы. Вне зависимости от типа и сложности сайта главная задача сервера остается прежней: это отправка специальных тегов и текста в ответ на соответствующие запросы. Веб-код исходной страницы — это совокупность данных, которые включают в себя:
Запрос генерируется путем ввода URL в адресную строку или клика по функциональному элементу страницы. Вне зависимости от типа и сложности сайта главная задача сервера остается прежней: это отправка специальных тегов и текста в ответ на соответствующие запросы. Веб-код исходной страницы — это совокупность данных, которые включают в себя: ;
; Эту «стену текста» со спецсимволами сложно анализировать даже опытным разработчикам. Поэтому лучше воспользоваться специальными встроенными инструментами для разработчиков.
Эту «стену текста» со спецсимволами сложно анализировать даже опытным разработчикам. Поэтому лучше воспользоваться специальными встроенными инструментами для разработчиков.
 При необходимости их содержимое можно скопировать для переноса на диск или в код собственного сайта. Для этого нужно направить курсор мыши на адрес и кликнуть правой кнопкой. После этого откроется контекстное меню, в котором нужно активировать функцию Open in new Tab. Это откроет новую вкладку с целевым файлом, с которым можно будет подробно ознакомиться или сохранить.
При необходимости их содержимое можно скопировать для переноса на диск или в код собственного сайта. Для этого нужно направить курсор мыши на адрес и кликнуть правой кнопкой. После этого откроется контекстное меню, в котором нужно активировать функцию Open in new Tab. Это откроет новую вкладку с целевым файлом, с которым можно будет подробно ознакомиться или сохранить. Из-за этого быстро найти конкретный элемент без специальных вспомогательных инструментов практически невозможно. Для этих целей предусмотрена специальная команда. Чтобы воспользоваться ей, нужно навести курсор на целевой элемент и вызвать контекстное меню правой кнопкой мыши. Здесь следует выбрать команду «Просмотреть код». После этого откроется стандартное окно, но с уже подсвеченным элементом.
Из-за этого быстро найти конкретный элемент без специальных вспомогательных инструментов практически невозможно. Для этих целей предусмотрена специальная команда. Чтобы воспользоваться ей, нужно навести курсор на целевой элемент и вызвать контекстное меню правой кнопкой мыши. Здесь следует выбрать команду «Просмотреть код». После этого откроется стандартное окно, но с уже подсвеченным элементом. В примере 4.1 показан
код простого документа, содержащего основные теги.
В примере 4.1 показан
код простого документа, содержащего основные теги.
 dtd»>
dtd»> При этом помним, что
браузер в любом случае покажет документ, независимо от того, соответствует
он синтаксису или нет. Подобная проверка осуществляется при помощи валидатора
и предназначена в первую очередь для разработчиков, чтобы отслеживать ошибки
в документе.
При этом помним, что
браузер в любом случае покажет документ, независимо от того, соответствует
он синтаксису или нет. Подобная проверка осуществляется при помощи валидатора
и предназначена в первую очередь для разработчиков, чтобы отслеживать ошибки
в документе.
 В операционной системе Windows
текст заголовка отображается в левом верхнем углу окна браузера (рис. 4.2).
В операционной системе Windows
текст заголовка отображается в левом верхнем углу окна браузера (рис. 4.2).
</p>
 Но эта мысль бредовая сразу на стольких уровнях, что мы стесняемся её произносить вслух. Разве что шёпотом.
Но эта мысль бредовая сразу на стольких уровнях, что мы стесняемся её произносить вслух. Разве что шёпотом.  Браузер получает страницу от сервера и выводит её копию на экран, а в памяти держит исходный код. Разве что он не сохраняет эту страницу на диск, чтобы вы могли её редактировать.
Браузер получает страницу от сервера и выводит её копию на экран, а в памяти держит исходный код. Разве что он не сохраняет эту страницу на диск, чтобы вы могли её редактировать.
 Бесплатный и надёжный, работает везде.
Бесплатный и надёжный, работает везде.  Чтобы не создавать хаос на компьютере, создадим сначала папку ux-posters — в ней будет храниться наш сайт. Потом в эту папку сохраняем все файлы таким способом:
Чтобы не создавать хаос на компьютере, создадим сначала папку ux-posters — в ней будет храниться наш сайт. Потом в эту папку сохраняем все файлы таким способом: Теперь можно:
Теперь можно:  Это полумера, но может сработать. А вообще вместо этого есть специальные надстройки, которые делают почти то же самое, но более умно, — поищите слово «кеширование».
Это полумера, но может сработать. А вообще вместо этого есть специальные надстройки, которые делают почти то же самое, но более умно, — поищите слово «кеширование».  Браузер выберет первый <источник> он поддерживает:
Браузер выберет первый <источник> он поддерживает: Указывает URL-адрес медиафайла
Указывает URL-адрес медиафайла jpg»>
jpg»> 
 CSS Reference
CSS Reference  Это элемент void, что означает, что он не имеет содержимого и не имеет закрывающего тега. Он обычно используется для предоставления одного и того же мультимедийного контента в нескольких форматах файлов, чтобы обеспечить совместимость с широким спектром браузеров, учитывая их различную поддержку форматов файлов изображений и форматов файлов мультимедиа.
Это элемент void, что означает, что он не имеет содержимого и не имеет закрывающего тега. Он обычно используется для предоставления одного и того же мультимедийного контента в нескольких форматах файлов, чтобы обеспечить совместимость с широким спектром браузеров, учитывая их различную поддержку форматов файлов изображений и форматов файлов мультимедиа.
 Браузер выбирает наиболее подходящее изображение для отображения в данный момент времени. Если используются дескрипторы ширины, 9Атрибут 0023 размеры также должен присутствовать, иначе значение
Браузер выбирает наиболее подходящее изображение для отображения в данный момент времени. Если используются дескрипторы ширины, 9Атрибут 0023 размеры также должен присутствовать, иначе значение 

 То есть вы никогда не используете «
То есть вы никогда не используете «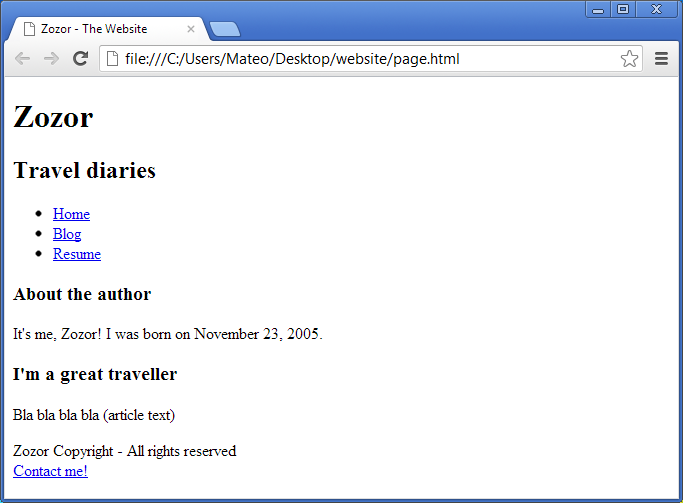

 Или щелкните правой кнопкой мыши и выберите «Просмотр исходного кода».
Или щелкните правой кнопкой мыши и выберите «Просмотр исходного кода». Вы также можете щелкнуть правой кнопкой мыши и выбрать «Просмотреть исходный код страницы». Комбинация клавиш — Option+Command+U.
Вы также можете щелкнуть правой кнопкой мыши и выбрать «Просмотреть исходный код страницы». Комбинация клавиш — Option+Command+U. Если у вас нет тегов title в исходном коде, вы не сможете появиться в Google (или в любой другой поисковой системе, если уж на то пошло). Хотите верьте, хотите нет, но я действительно видел веб-сайты без тегов заголовков!
Если у вас нет тегов title в исходном коде, вы не сможете появиться в Google (или в любой другой поисковой системе, если уж на то пошло). Хотите верьте, хотите нет, но я действительно видел веб-сайты без тегов заголовков!