Обучение рукописной OCR на синте от GAN’ов / Хабр
Модели распознавания печатного текста (например, с фотографий документов) дают довольно высокие результаты. Это происходит за счёт ограниченного набора шрифтов, цель которых – быть максимально понятными человеку, а также благодаря генерации простой синтетики в виде печати разнообразными шрифтами текста на каком-нибудь фоне.
С распознаванием рукописных материалов дело немного сложнее. У каждого человека свой почерк, который ещё и может меняться с течением времени. Причём вариативность почерков довольно существенная, и часто мы с трудом читаем то, что написал, скажем, врач или ребёнок. Человек с течением жизни может сформировать свои привычки писать ту или иную букву определённым образом (конкретной высоты, наклона, формы и др.), причем эта буква будет такой только у одного человека. Подобную синтетику уже нельзя сымитировать, накладывая печатные шрифты на фон.
Тут же возникает трудность и с разметкой (которой особенно мало на русском языке). Например, при работе с рукописями Петра I пришлось задействовать историков. Конечно, это особый случай документов начала XVIII века, но даже в простых датасетах важно иметь дублирующую разметку нескольких человек для исправления ошибок, которые нередко совершают разметчики при чтении рукописного текста.
Например, при работе с рукописями Петра I пришлось задействовать историков. Конечно, это особый случай документов начала XVIII века, но даже в простых датасетах важно иметь дублирующую разметку нескольких человек для исправления ошибок, которые нередко совершают разметчики при чтении рукописного текста.
Мы в Sber AI заинтересовались идеей генерации синтетических рукописных изображений с помощью GAN, и в этой статье предлагаю рассмотреть несколько таких моделей. А также попробуем сгенерировать синтетику, используя одну из архитектур, и посмотрим, как сильно дополнительные данные улучшают качество OCR-модели (Optical Character Recognition).
Обзор нескольких GAN для генерации рукописных текстов
TextStyleBrush
И начнём со свежей статьи от Facebook. TextStyleBrush – модель для замены текста на картинке (или переноса таргет-стиля на новый текст). На вход принимает картинку со стилем и новый текст для печати. Стиль – это цветовая гамма, текстура, шрифт или почерк и т. д. При этом для обучения не нужна разметка самих стилей, и это, несомненно, плюс: некоторые другие архитектуры требуют разметку почерков авторов (какому человеку принадлежит каждый рукописный текст).
д. При этом для обучения не нужна разметка самих стилей, и это, несомненно, плюс: некоторые другие архитектуры требуют разметку почерков авторов (какому человеку принадлежит каждый рукописный текст).
Самое интересное то, что архитектура позволяет применять стили на новый текст в one-shot манере: можно взять на инференсе любую картинку и сразу же нанести на неё новый текст без необходимости дообучать модель. Из этого следует и другая особенность: мы можем контролировать стиль выходных картинок (он просто принимает стиль входной). Другие архитектуры GAN’ов принимают на вход только случайный шум, а с TextStyleBrush легко можно сгенерировать примеры одного заданного стиля.
Для обучения TextStyleBrush нужны:
Предобученная модель OCR.
Предобученный классификатор шрифтов (авторы обучали его заранее на синтетических картинках).
Разметка bounding box. Входная картинка-стиль вырезается с добавлением контекстного пространства вокруг обрамляющего прямоугольника (что, как утверждают авторы, улучшает качество).
И, конечно, разметка самого текста для картинок (то есть текст, который написан на картинках).
Далее чуть подробнее пройдёмся по архитектуре. TextStyleBrush состоит из 7 сеток, в том числе из 5 loss’ов.
Content encoder и style encoder – обе сетки ResNet34. Причём текст подаётся не в виде закодированных букв, а просто как отдельная картинка: он печатается на белом фоне с использованием стандартного шрифта.
Style mapping network – сетка преобразует выходной вектор style encoder’а во множество отдельных векторов. Затем они подаются на разных слоях на вход генератору как параметры в AdaIN-слои. Это позволяет генератору лучше схватить стиль картинки на разных её уровнях.
Генератор – это StyleGAN, который авторы статьи доработали таким образом, чтобы он принимал на вход результаты работы двух энкодеров: текста и стиля. Генератор на выходе, помимо картинки, предсказывает текстовую маску, которая затем используется в лоссах (для масок нет разметки, сетка сама учится их предсказывать). Такие маски помогают архитектуре лучше отделять текст от фона/стиля.
Такие маски помогают архитектуре лучше отделять текст от фона/стиля.
Далее вкратце про 5 лоссов в TextStyleBrush.
Typeface classifier loss – это классификатор шрифтов, заранее предобученный на синтетических картинках и замороженный во время обучения всей архитектуры. Классификатор даёт генератору градиенты во время обучения для лучшего понимания сущности шрифтов. Этот лосс стремится снизить разницу между шрифтом сгенерированной картинки и таргет-картинкой.
Дискриминатор GAN’а (предсказывает real/fake).
Recognizer loss – предобученная OCR-модель читает текст с масок и сгенерированных картинок. Она способствует тому, чтобы маски отражали текст на самих картинках, и генератор не сливал текст с фоном. А также отвечает за то, чтобы буквы, которые GAN пытается написать, были похожи на настоящие. Текст с сгенерированных картинок сравнивается с таргет-текстом через Cross Entropy loss. При этом OCR заморожена во время обучения всей архитектуры.
Reconstruction loss (l rec) – отражает разницу между сгенерированной картинкой Os,c1 и таргет-картинкой Is,c1 (которую мы вырезали по bbox’у из входной картинки-стиля) с помощью L1-расстояния.

Cycle consistency loss (l cyc) – по аналогии с CycleGAN, помогает сетке научиться восстанавливать из сгенерированной Os,c2 картинки обратно исходную.
Не могу не упомянуть отличное видео с разбором статьи TextStyleBrush.
В итоге TextStyleBrush генерирует отличные картинки! И хорошо справляется с заменой текста in the wild на каких-нибудь билбордах, чайниках, дорожных знаках и прочем. Также она умеет работать и с рукописным текстом.
Итак, обсудим и некоторые проблемы TextStyleBrush:
Можно заметить, что архитектура сети кажется переусложнённой, и если понадобится что-то поправить, то придётся тюнить сетку с поправкой на большое количество компонентов внутри.
Вследствие своей архитектуры TextStyleBrush может сгенерировать только стили/почерки, примеры которых уже есть, и не сможет создать совершенно новые примеры или же некое «усреднение» из имеющегося. Только одна картинка в качестве входного стиля, и одна картинка на выходе с таким же стилем и новым текстом.
Генератор на вход принимает текст как картинку, напечатанную простым шрифтом на белом фоне, и далее апскейлит её. Также в качестве одного из лоссов выступает классификатор стандартных печатных шрифтов. Такая архитектура более приспособлена к генерации картинок с печатным текстом, чем с рукописным. Впрочем, картинки из статьи демонстрируют хороший результат и с рукописью.
Для тестирования TextStyleBrush ждём, когда авторы выложат код к статье.
GANwriting
Следующая статья 2020-го года – GANwriting. Это также GAN по генерации рукописных картинок. Как и в TextStyleBrush, на вход модели мы подаём текст, который хотим напечатать, но вместо одной картинки со стилем в GANwriting необходимо предоставить сразу несколько (авторы использовали 15). И это существенное отличие: это уже не замена текста на картинке, а создание нового шрифта в усреднённом стиле/почерке из 15 входных примеров.
Немного об архитектуре GANwriting. Как и в TextStyleBrush, здесь есть энкодеры для картинок-стилей и текста.
Style encoder принимает на вход 15 изображений и выдаёт тензор, кодирующий стиль (авторы добавляют ещё случайный шум к тензору для искусственного создания вариативности).
Content encoder принимает текст в виде one-hot матрицы (в отличие от TextStyleBrush, который рендерил текст стандартным шрифтом на белом фоне), далее энкодер делится на две головы g1 и g2. Выход g1 коннектится к выходу style encoder и такой объединённый тензор уже подаётся на вход генератору, который затем апскейлит его в результирующую картинку. Выходные контент-векторы головы g2 подаются генератору на четырёх его уровнях в AdaIN слои (тогда как в TextStyleBrush в генератор пробрасывали стиль).
В качестве лоссов используется дискриминатор, классификатор авторов/стилей и OCR-модель. Роль writer classifier в целом похожа на роль классификатора шрифтов из TextStyleBrush: дать генератору дополнительную информацию о типах/особенностях почерков. Однако там мы могли этот классификатор заранее обучить на синтетических данных, в GANwriting же для датасета потребуется разметка автора для каждой картинки, что, конечно же, не всегда можно легко получить. Такую разметку необходимо планировать заранее во время сбора и разметки данных, так как в процессе доразметки понять автора текста по картинке будет уже невозможно. Также создатели GANwriting пишут, что writerclassifier помогает в предотвращении mode collapse.
Однако там мы могли этот классификатор заранее обучить на синтетических данных, в GANwriting же для датасета потребуется разметка автора для каждой картинки, что, конечно же, не всегда можно легко получить. Такую разметку необходимо планировать заранее во время сбора и разметки данных, так как в процессе доразметки понять автора текста по картинке будет уже невозможно. Также создатели GANwriting пишут, что writerclassifier помогает в предотвращении mode collapse.
Все сетки модели учатся с нуля: разработчики получили лучшие результаты именно при таком подходе, чем при создании предобученных сеток какой-либо из частей архитектуры.
Также авторы приводят примеры генерации, используя в качестве входных параметров текст или изображения, которых не было во время обучения. Это очень здорово, ведь модель можно использовать для генерации синтетического датасета, имея всего несколько настоящих примеров почерка одного человека, – без необходимости дообучения.
Ещё одной интересной демонстрацией GANwriting является смешение стилей разных авторов. Ведь не обязательно на инференсе использовать 15 входных изображений одного человека. Можно смешивать почерки разных людей, и тем самым разнообразить синтетический датасет. На картинке ниже видно, как модель плавно меняет почерк в зависимости от того, сколько изображений из 15 было от одного человека и сколько от другого.
Ведь не обязательно на инференсе использовать 15 входных изображений одного человека. Можно смешивать почерки разных людей, и тем самым разнообразить синтетический датасет. На картинке ниже видно, как модель плавно меняет почерк в зависимости от того, сколько изображений из 15 было от одного человека и сколько от другого.
Авторы статьи также поделились своим кодом, и было интересно попробовать обучить модель самостоятельно. Но, к сожалению, после множества экспериментов так и не удалось получить такие же красивые результаты, какие мы видим в статье. Картинки получаются довольно синтетическими на вид:
ScrabbleGAN
Следующая статья 2020-го года от Amazon – ScrabbleGAN. Архитектура проще, чем те, что мы рассмотрели ранее. Есть только генератор, дискриминатор и OCR. На вход модели мы подаём текст, а генератор уже создаёт изображение. В разметке не требуется классификатор почерков или шрифтов, или же разметка bbox’ов, – нужны только картинки с текстом и аннотации для него.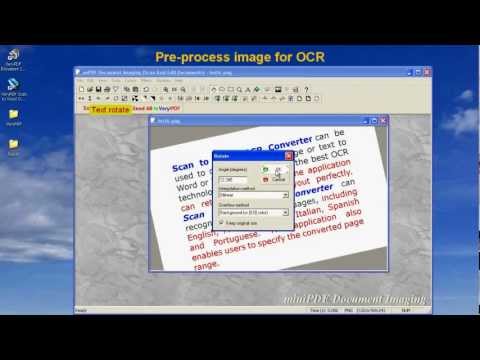
Немного об архитектуре: one-hot-текст умножается на вектор случайного шума, проходит через linear-слои и далее апскейлится генератором (BigGAN-модель). Вектор шума отвечает за стиль букв: почерк/толщину/курсив и прочее. На инференсе, если не менять шум, то картинки, соответственно, все будут в одном стиле. И основной недостаток ScrabbleGAN: на стиль генерации можно повлиять только с помощью вектора случайного шума.
Сгенерированная картинка подаётся на вход дискриминатору, который помогает улучшить общее качество изображения, и рекогнайзеру (OCR), который делает текст читаемым.
Авторы статьи оставили в OCR-модели только конволюционные слои по той причине, что рекуррентные могут выучивать неявную языковую модель датасета и предсказывать правильное написание слова, тогда как на картинке оно написано ошибочно (Implicit Language Model in LSTM for OCR). Это может помешать в случае, когда OCR используется как часть архитектуры GAN, ведь здесь OCR должна читать именно тот текст, который написал генератор, без додумывания. Что также интересно, авторы статьи выбрали как можно более простую OCR-модель, так как в их экспериментах усложнение ухудшало общие результаты.
Что также интересно, авторы статьи выбрали как можно более простую OCR-модель, так как в их экспериментах усложнение ухудшало общие результаты.
Любопытно видеть результаты обучения при разных коэффициентах альфа, отвечающего за вес OCR-лосса во время обучения. При a=∞ GAN обучается фактически без дискриминатора (и это видно по качеству картинок в левой колонке), а при a=0 GAN обучается без рекогнайзера (правая колонка) – и картинки выглядят реалистично, но вместо текста мы видим каракули.
Также авторы статьи провели интересный эксперимент: обучили OCR-модель на IAM-датасете и тестировали на CVL (наблюдая при этом невысокое качество распознавания на тесте в силу большого различия доменов датасетов).
В качестве трейна к IAM-датасету добавили синту от ScrabbleGAN. При этом дискриминатор ScrabbleGAN можно отдельно дообучить на неразмеченных данных (т. к. дискриминатор предсказывает только два класса – real/fake, – можно использовать unlabeled данные). И, соответственно, мы можем дообучить дискриминатор на CVL-стилях: в генерируемых изображениях тогда сымитируем стиль CVL-датасета.![]() Результаты авторов:
Результаты авторов:
В первой строке в качестве бейзлайна OCR обучена только на IAM без синты – видим процент ошибок на уровне 40% на CVL-датасете. И снижение ошибок до 30% (вторая снизу строка) мы получаем при добавлении синты от ScrabbleGAN, дообученого на неразмеченных CVL-картинках и с использованием CVL-текстов для генерации синты. Правильно подобранный лексикон при обучении OCR даёт хорошие результаты – это говорит о том, что полезно понимать словарный домен, который модель будет читать в бою. То есть если модель будет использоваться на каких-то медицинских документах, то хорошо бы и обучать её на лексиконе из медицинских терминов. Последняя строка в таблице – OCR, обученный сразу на CVL-данных (для понимания, где потолок у этих экспериментов, – 23% WER).
Результаты ScrabbleGAN на русскоязычном OCR
Хорошая новость со ScrabbleGAN в том, что авторы выложили свой код. Однако эта реализация мне показалось более приятной (отрефакторенная версия ребят из Amazon). Также можете попробовать наш форк (удобнее запускать из Docker и обучать цветные картинки).
Попробуем повторить результаты авторов ScrabbleGAN, но для экспериментов будем использовать русскоязычные рукописные датасеты: HKR в качестве трейна и наш внутренний датасет Forms для тестов (часть этого датасета открыта, и вы можете взять его здесь). Это достаточно разные датасеты как по стилям (условия фотографирования, разные почерки, текстура и цвет бумаги), так и по лексикону. Forms – это фотографии заполнения различных бланков, и тексты там, соответственно, формальные (названия городов, индексы, имена, даты, время и т. д.). Тогда как в HKR лексикон более «обычный», литературный. Основная цель экспериментов – проверить, что генерация рукописки с помощью GAN’ов будет давать прирост качества OCR-моделей на новых доменах.
Также к трейн-датасету мы можем добавить простую синтетику: фон + текст на основе ttf-шрифтов. Такие шрифты обычно печатные, и те из них, что якобы являются рукописными, скорее имитируют курсив. Но тем не менее, мы для сравнения обучим и на такой синте. Примеры картинок, слева направо — HKR, Forms и синта на основе шрифтов:
И давайте взглянем на синту от ScrabbleGAN, обученного на русскоязычном HKR-датасете. Здорово посмотреть, как ScrabbleGAN меняет стили почерка в зависимости от вектора случайного шума (справа):
Здорово посмотреть, как ScrabbleGAN меняет стили почерка в зависимости от вектора случайного шума (справа):
Итак, результаты экспериментов:
Параметры трейн-датасета | Accuracy, тестовый Forms-датасет |
HKR (naive) | 0,5% |
HKR + TTF | 13,9% |
HKR + GAN | 12,3% |
HKR + TTF + GAN | 24,1% |
HKR + Forms (для понимания максимального качества) | 66,5% |
Первая строка – в качестве обучающего датасета HKR без какой-либо дополнительной синты (но используются обычные аугментации для картинок), и на Forms-тесте такая модель дает не впечатляющие результаты в полпроцента (здесь accuracy – когда предсказанный текст для строки полностью совпадает с таргетом). Такая низкая точность потому, что датасеты отличаются как по стилю, так и по лексикону (плюс маленький объем трейн-датасета).
Второй эксперимент – добавили простую синту на ttf-шрифтах, и точность модели на тесте возросла до 13,9%. Но когда к обучающей выборке мы вместе с ttf-синтой добавляем картинки от ScrabbleGAN (предпоследняя строка), получаем точность уже 24,1%.
Это говорит о том, что добавление синтетики от ScrabbleGAN улучшает качество OCR-модели при чтении текста на новых доменах. При этом рост точности при добавлении синты от GAN сопоставим с обычной синтой на ttf-шрифтах: 9–13% accuracy на новых доменах. При объединении синтетики от GAN и на основе ttf-шрифтов качество OCR-модели на новых доменах возрастает еще сильнее – до 23–24% (видимо, эти синтетические датасеты дают разные фичи для OCR-модели). В процессе экспериментов я пробовал различные параметры обучения GAN (обученной на рандомном лексиконе, на лексиконе от Forms и дообученной на неразмеченных картинках Forms), но результаты получались сопоставимые с тем, как если ScrabbleGAN обучать только на HKR-датасете.
Результаты StackMIX
StackMix – работа наших коллег, о которой подробнее можно почитать в статье, и сам код находится здесь. Идея состоит в создании новых изображений с текстом из уже имеющегося датасета:
Идея состоит в создании новых изображений с текстом из уже имеющегося датасета:
Обучаем базовую OCR-модель с CTC loss’ом на датасете.
Далее используем эту модель для нарезки каждой картинки из датасета по отдельным буквам/n-граммам. Чтобы нарезать её по словам, используем координаты букв, которые можем вытащить из CTC лосса. По итогу у нас получится очень много маленьких картинок по отдельным буквам / последовательностям букв (например, из одного изображения с текстом «кошка» мы накропаем несколько картинок с текстами «к», «ош», «ка»).
Далее мы можем собрать новые слова как конструктор из кропов отдельных букв.
Мы не создаем новые изображения (так как картинки всё-таки состоят из частей старых), это что-то среднее между аугментацией и синтетикой. Концепция Stackmix похожа на такие аугментации, как, например, Cutout, которые заставляют сетку обращать внимание на важные фичи для распознавания, мешая оверфититься под определённые особенности датасета. Ну и конечно, StackMix позволяет расширить датасет новым лексиконом, что не менее важно. Примеры генерации слева. Теперь попробуем обучить OCR-модель на HKR с добавлением StackMix-синты (сгенерированной из HKR-картинок).
Ну и конечно, StackMix позволяет расширить датасет новым лексиконом, что не менее важно. Примеры генерации слева. Теперь попробуем обучить OCR-модель на HKR с добавлением StackMix-синты (сгенерированной из HKR-картинок).
Параметры трейн-датасета | Accuracy, тестовый Forms-датасет |
HKR (naive) | 0,5% |
HKR + S-MIX | 27% |
HKR + S-MIX + TTF | 35,1% |
HKR + S-MIX + TTF + GAN | 38,1% |
Как видим, одно только добавление синты StackMix даёт точность распознавания в 27% на тестовом Forms-датасете. И если объединить все три типа синтетики – от StackMix, обычную на ttf-шрифтах и синту от ScrabbleGAN – то мы получаем точность в 38,1% на тесте Forms (напомню, что домены трейна и теста отличаются). И это очень и очень здорово. Фактически, без использования дополнительных размеченных датасетов нам удалось повысить точность распознавания на новых доменах с 0,5% до 38% за счёт генерации синтетических изображений.
Примеры генерации синты ScrabbleGAN на других датасетах
Интересно посмотреть на сгенерированный почерк Петра I. Здесь, кажется, GAN не так просто имитировать столь витиеватый и неразборчивый текст. Хоть датасет состоит из текстов только Петра I, в зависимости от вектора случайного шума GAN немного меняет почерк генерируемой картинки. Ведь человек одну букву каждый раз пишет как-нибудь иначе, что позволяет сети выучить некоторую вариативность в стилях генерации:
Скачать датасет Петра I вы можете здесь.
Также мы выложили в открытый доступ датасет школьных тетрадей.
Примеры картинок датасета школьных тетрадейЭто довольно большой датасет, представляет собой фотографии тетрадей и состоит из двух частей: разметки сегментации (полигоны для каждого слова) и разметки токенов (пары картинка с текстом и перевод). Слева несколько примеров слов из датасета.
Ну и конечно, примеры синтетических картинок от ScrabbleGAN:
Здесь видно, как вектор случайного шума особенно сильно влияет на почерк генерируемых картинок, так как датасет собирался из довольно большого количества тетрадей разных учеников.
Итоги
Интересно, что GAN-синтетика не даёт самый большой вклад в общую точность OCR-модели, несмотря на то что выглядит наиболее реалистично. Я бы предложил этому следующее объяснение. Во всех трёх GAN-архитектурах, которые мы рассмотрели, есть OCR-голова, которая помогает генератору учиться рисовать читаемые буквы. Но, возможно, генератор в процессе обучения, помимо нормального текста, также закладывает в картинке в каком-то неявном виде кодировку (шумы, цветопередача), таким образом быстрее и легче обманывая OCR-голову. И когда мы подаём такую синтетику в финальную OCR-модель, то она тоже будет выучивать кодировку текста от генератора, которая бесполезна в реальных данных. Но это предположение требует более детальных экспериментов.
Что же, мы посмотрели с вами три статьи по генерации рукописных картинок и попробовали применить одну из них – ScrabbleGAN – на русскоязычных датасетах. Причем для усложнения задачи в качестве тестового датасета взяли примеры со стилями/почерками, которых нет в трейне. И провели эксперименты, чтобы понять, как сильно докидывает в точности распознавания синтетика от GAN по сравнению с основанной на ttf-шрифтах синтетикой, а также по сравнению с методом StackMix. В итоге, что, наверное, не так и удивительно, лучше всего работает модель, объединяющая все три типа синтетических данных.
И провели эксперименты, чтобы понять, как сильно докидывает в точности распознавания синтетика от GAN по сравнению с основанной на ttf-шрифтах синтетикой, а также по сравнению с методом StackMix. В итоге, что, наверное, не так и удивительно, лучше всего работает модель, объединяющая все три типа синтетических данных.
Надеюсь, получилось интересно, и мы ещё вернёмся со статьями и экспериментами по OCR для рукописных изображений. Спасибо за внимание!
Ссылки из статьи:
Датасеты — здесь можно скачать датаеты тетрадей, Forms, Петра
Stackmix
OCR модель — CRNN для чтения текста, с простым запуском для экспериментов
Форк ScrabbleGAN с более понятным запуском обучения и генерации картинок
При поддержке команд SberAI и SberIDP
Коллектив авторов: @ddimitrov, @shonenkov, @markpotanin, @gazizovmarat
Учебный шрифт Tesseract OCR
Обновлено: 12.09.2022
Tesseract OCR — это механизм OCR с открытым исходным кодом, разработанный HP Labs и поддерживаемый Google, который играет ключевую роль в области распознавания символов.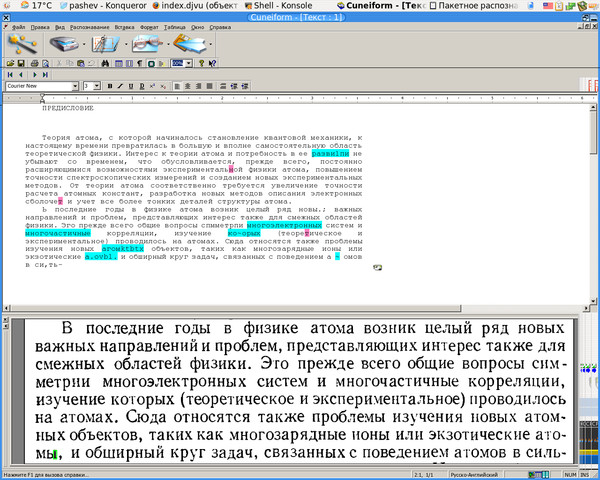 В дополнение к использованию библиотеки распознавания китайского и английского языков, поставляемой с программным обеспечением, мы можем использовать Tesseract OCR для обучения нашей собственной библиотеки шрифтов. Ниже я кратко представлю этапы работы:
В дополнение к использованию библиотеки распознавания китайского и английского языков, поставляемой с программным обеспечением, мы можем использовать Tesseract OCR для обучения нашей собственной библиотеки шрифтов. Ниже я кратко представлю этапы работы:
1. Построение программной среды
Перед использованием Tesseract OCR для обучения собственного шрифта, в дополнение к установке Tesseract OCR, вам необходим вспомогательный обучающий инструмент jTessBoxEditor. Поскольку jTessBoxEditor требует среды выполнения Java, мы должны убедиться, что JRE (среда выполнения Java, среда выполнения Java) установлена перед запуском jTessBoxEditor.
2. Получить образцы файлов
Мы можем использовать инструмент рисования для рисования образцов файлов. Чем больше число, тем лучше.
Примечание:
1. Формат файла образца изображения должен быть в формате tif \ tiff, в противном случае во время процесса файла слияния появится ошибка «Не удается найти».
2. Не изменяйте формат изображения, изменяя суффикс файла. Также в процессе создания файла слияния будут отображаться ошибки «Не удается найти».
Также в процессе создания файла слияния будут отображаться ошибки «Не удается найти».
Три, объединить образец файла
Откройте jTessBoxEditor, Tools-> Merge TIFF, выберите все файлы примеров и сохраните объединенный файл как num.font.exp0.tif.
В-четвертых, генерировать файлы BOX
Откройте командную строку и перейдите в каталог, где находится num.font.exp0.tif, введите следующую команду и сгенерируйте файл с именем num.font.exp0.box.
[Синтаксис]: tesseract [lang]. [Имя шрифта] .exp [num] .tif [lang]. [Имя шрифта] .exp [num] batch.nochop makebox
lang — это имя языка, fontname — это имя шрифта, а num — серийный номер, в tesseract вы должны обратить внимание на формат.
Пять, определить файл конфигурации символов
Создайте текстовый файл с именем font_properties.txt в целевой папке, содержимое
[Синтаксис]:
fontname — это имя шрифта, курсив — курсив, полужирный — полужирный, фиксированный — шрифт по умолчанию, serif — шрифт с засечками, fraktur немецкий черный шрифт, 1 и 0 — наличие и отсутствие, отлично. Может использоваться при различении.
Может использоваться при различении.
В-шестых, коррекция персонажа
Откройте jTessBoxEditor, BOX Editor-> Open, откройте num.font.exp0.tif;
Примечание:
Исправьте символы в , у много страниц!
Не забудьте сохранить после модификации!
Если есть ошибка сегментации символа, ее можно изменить путем слияния или разделения.
Семь, выполнить командный файл
Скопируйте и вставьте следующие команды в cmd и запустите.
Следующие файлы будут созданы в папке:
8. Тестовый этап
Скопируйте num.trainddata в папку tessdata в Tesseract-OCR.
Введите папку с изображениями для распознавания в cmd и выполните следующий код:
Test.jpg — это имя распознаваемой картинки, а результат распознавания существует в файле output.txt.
Изображение для распознавания:
Результат идентификации:
Интеллектуальная рекомендация
Статья 3. Больше используйте буквальную грамматику и меньше эквивалентных методов
Строковый литерал Буквальное значение Литеральный массив Буквальный словарь Массивы переменных и словари ограничение Созданные объекты, за исключением строк, должны принадлежать платформе Foundation. .
.
Использование ActiveMq
Установка (Linux) (1) Загрузите apache-activemq-5.12.0-bin.tar.gz на сервер (2) Разархивируйте этот файл (3) Предоставьте права на каталог apache-activemq-5.12.0 (4) Войдите в каталог apache-activemq-.
Грамматические привычки Java
Более эффективный опыт путешествий с мобильным банком Momis IP66
Когда дело доходит до осьминога, все думают о его многочисленных мягких щупальцах, которые сильны в море. Вдохновленный этим, Momax запустил мобильный банк питания с «щупальцами» — iPower .
Ошибка lnk2019: внешние символы Невозможно разрешить _winmain @ 16, этот символ ссылается в функции ___tmaincrtstartup
Вам также может понравиться
Скриншот Android Получить скриншот (просмотр/просмотр) скриншот
Когда вы открываете дверь, чтобы увидеть гору, следующий код может сыграть соответствующую роль, просто возьмите ее напрямую. 1. Получите скриншот управления (вы можете получить тип View или View Grou.
Собственный js получает ширину и высоту экрана, ширину и высоту элемента / поля / отступы
1. Получите ширину и высоту экрана. 2. Получите ширину и высоту элемента.
Получите ширину и высоту экрана. 2. Получите ширину и высоту элемента.
Music demo
Резервное копирование проекта Music Menifests StartActivity.java MainActivity MusicListActivity FavouriteActivity PlayMusicActivity LocalMusicAdapter ViewPagerAdapter LRCbean LyricView PlayService Mus.
MySQL использует объяснение для проверки плана выполнения индекса
mysql> explain select * from test where name=‘tom’\G *************************** 1. row *************************** id: 1 select_type: SIMPLE table: test type: ALL possible_keys: NULL k.
Установка TTF-шрифтов на компьютер
Windows поддерживает большое количество шрифтов, позволяющих изменять вид текста не только внутри самой ОС, но и в отдельных приложениях. Довольно часто программы работают с библиотекой шрифтов, встроенных в Виндовс, поэтому удобнее и логичнее установить шрифт в системную папку. В дальнейшем это позволит воспользоваться им и в другом ПО. В этой статье мы рассмотрим основные методы решения поставленной задачи.
Установка TTF-шрифта в Windows
Часто шрифт инсталлируется ради какой-либо программы, поддерживающей изменение этого параметра. В этом случае есть два варианта: приложение будет использовать системную папку Windows либо установку нужно производить через настройки конкретного софта. На нашем сайте уже есть несколько инструкций по инсталляции шрифтов в популярное программное обеспечение. Ознакомиться с ними можно по ссылкам ниже, кликнув на название интересующей программы.
Этап 1: Поиск и скачивание TTF-шрифта
Файл, который впоследствии будет интегрирован в операционную систему, как правило, скачивается из интернета. Вам понадобится отыскать подходящий шрифт и скачать его.
Обязательно обращайте внимание на надежность сайта. Поскольку инсталляция происходит в системную папку Виндовс, заразить операционную систему вирусом можно очень легко, выполнив загрузку из ненадежного источника. После скачивания обязательно проверьте архив установленным антивирусом или через популярные онлайн-сервисы, не распаковывая его и не открывая файлы.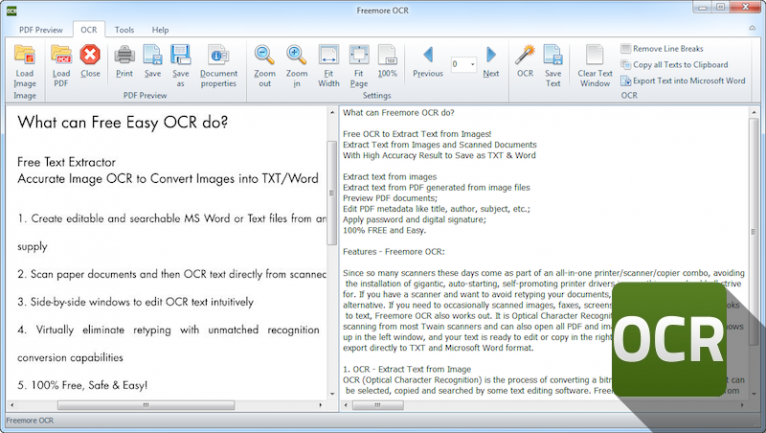
Этап 2: Установка TTF-шрифта
Сам процесс инсталляции занимает несколько секунд и может быть выполнен двумя способами. Если был скачан один или несколько файлов, проще всего воспользоваться контекстным меню:
Зайдите в программу или системные настройки Windows (в зависимости от того, где вы хотите пользоваться этим шрифтом) и найдите установленный файл.
Обычно для того чтобы список шрифтов обновился, следует перезапустить приложение. В противном случае вы просто не найдете нужное начертание.
В случае когда надо установить много файлов, легче поместить их в системную папку, а не добавлять каждый по отдельности через контекстное меню.
- Перейдите по пути C:\Windows\Fonts .
Как и в предыдущем способе, для обнаружения шрифтов открытое приложение нужно будет перезапустить.
Точно таким же образом можно устанавливать шрифты и других расширений, например, OTF. Удалять варианты, которые вам не понравились, очень просто.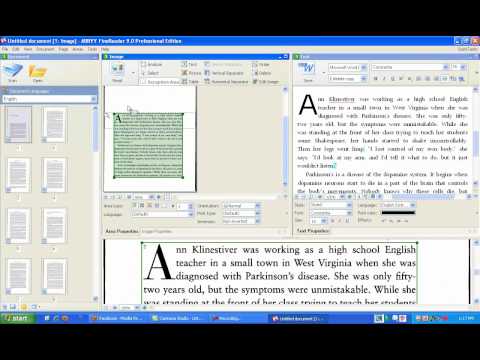 Для этого зайдите в C:\Windows\Fonts , отыщите название шрифта, кликните по нему правой кнопкой мыши и выберите «Удалить».
Для этого зайдите в C:\Windows\Fonts , отыщите название шрифта, кликните по нему правой кнопкой мыши и выберите «Удалить».
Подтвердите свои действия нажатием на «Да».
Теперь вы знаете, как устанавливать и применять TTF-шрифты в Windows и отдельных программах.
Мы рады, что смогли помочь Вам в решении проблемы.
Как установить новый шрифт в Word
Корпорация Microsoft постоянно трудится над усовершенствованием своего текстового редактора (Word). Ведется улучшение оптимизации, скорости отклика функций, а также постоянно добавляются всевозможные новые шрифты, которые своей красотой радуют глаз искушенным потребителям, однако всегда найдутся пользователи, которым будет недостаточно встроенного функционального набора. Поэтому существует безмерное количество дополнительных шрифтов разрабатываемые сторонними производителями и просто энтузиастами.
Однако, чтобы установить новый шрифт в среду Microsoft Office придется немного потрудится.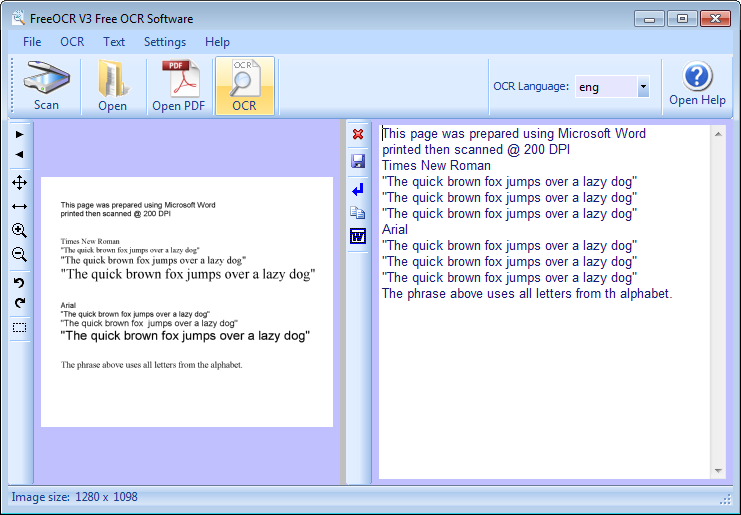 Благодаря данной инструкции вы узнаете, как установить шрифт в ворд и с легкостью сможете проделать описанные ниже действия.
Благодаря данной инструкции вы узнаете, как установить шрифт в ворд и с легкостью сможете проделать описанные ниже действия.
Скачивание нового шрифта
Перво-наперво в интернете необходимо найти тот самый желанный вами вордовский шрифт. Стоит сразу отметить, что скачивать новый шрифт (собственно, как и любой сторонний софт) необходимо с проверенных сайтов.
Безопасные шрифты распространяются архивом, внутри которого запакован файл с расширением OTF или TTF (данный формат поддерживается операционной системой Windows и ничем сторонним его не открыть).
Инсталляция нового шрифта в ОС Windows
Теперь, когда файл-шрифт (расширение OTF или TTF) находится на вашем компьютере — необходимо инсталлировать скаченный шрифт в саму систему.
Для этого нужно открыть панель управления вашего компьютера. Если на вашем ноутбуке установлена новейшая операционная система Windows 8 или10, просто нажмите сочетание клавиш «Win+X», а после найдите в списке активную ссылку «Панель управления».
В более поздних версиях ОС Windows необходимо нажать на «Пуск», а после на «Панель управления».
Теперь необходимо найти раздел, позволяющий управлять шрифтами. Для его обнаружения вам необходимо найти и нажать на раздел «Оформление и персонализация», затем в новой вкладке вы обнаружите необходимый раздел «Шрифты».
Установка нового шрифта в Word
Теперь чтобы установить шрифт в ворде 2010 и 2016 годов (ворд 2007 и 2003 работает по такому же принципу, но с незначительными изменениями) необходимо запустить документ MS Word с ярлыка и найти в списке установленных шрифтов — новый. Для этого найдите на верхней панели незаметный значок, находящейся справа от раздела «Шрифт» и нажмите на него.
Это действие вызовет дополнительное контекстное окно, в котором нужно найти инсталлированный в систему шрифт и выбрать его нажатием ЛКМ. Затем нажмите «OK» и шрифт будет выбран. Теперь можно приступить к набору текста.
Теперь стоит понять дальнейшие действия. Если вы решили просто поэкспериментировать с новыми шрифтами или же вам нужно было распечатать красивый текст на своем принтере и сохранить его на бумаге, то на этом ваши действия закончены.
Если вы решили просто поэкспериментировать с новыми шрифтами или же вам нужно было распечатать красивый текст на своем принтере и сохранить его на бумаге, то на этом ваши действия закончены.
Внедрение шрифта в документ
Для того чтобы ваш друг смог увидеть написанный вашим шрифтом текст, его необходимо внедрить в сохраняемый документ, что в свою очередь немного увеличит объем самого текстового файла.
Первым делом откройте пересылаемый документ, а после перейдите в его параметры. В открывшемся окошке выберите раздел «Сохранение» и поставьте галочку напротив «Внедрить шрифты в файл». Теперь нажмите «OK» после чего сохраните документ.
Готово, теперь его можно пересылать по почте всем своим знакомым.
Как установить шрифт по умолчанию
Для того чтобы каждый раз заново не искать новенький инсталлированный шрифт, имеет смысл сделать его «По умолчанию». Для этого откройте пустой текстовый документ. Затем сочетанием клавиш «Ctrl+D» вызовите дополнительное контекстное меню и из списка шрифтов выберите нужный, после чего нажмите на клавишу с названием «По умолчанию».
Сразу после этого выскочит еще одно окошко, где нужно выбрать строку, отвечающую за все документы и нажать «OK».
После этого все открывшиеся новые документы будут по умолчанию с этим шрифтом.
Вывод
В данной статье мы рассказали вам как установить на свой компьютер сторонний шрифт, с помощью которого можно написать, а после распечатать красивый и уникальный текст. Также был рассмотрен вариант передачи сохраненного документа другому пользователю, на компьютер которого дополнительные шрифты не устанавливались, тем не менее текст был полностью читабелен.
Tiff-Heavy
| b>Сopyright | Generated by Fontographer 3.5 |
| b>Семейство | Tiff-Heavy |
| b>Начертание | Light |
| b>Идентификатор | Alts:Tiff-Heavy |
| b>Полное название шрифта | Tiff-Heavy |
| b>Версия | 1.0 Tue Nov 23 17:05:39 1993 |
| b>PostScript название | Tiff-Heavy |
| b>Изготовитель | Tiff-Heavy |
| b>Размер | 58 Kb |
Предварительный просмотр Tiff-Heavy
Lorem ipsum dolor sit amet, consectetur adipisicing elit, sed do eiusmod tempor incididunt ut labore et dolore magna aliqua.
Lorem ipsum dolor sit amet, consectetur adipisicing elit, sed do eiusmod tempor incididunt ut labore et dolore magna aliqua. Ut enim ad minim veniam, quis nostrud exercitation ullamco laboris nisi ut aliquip ex ea commodo consequat. Duis aute irure dolor in reprehenderit in voluptate velit esse cillum dolore eu fugiat nulla pariatur.
Онлайн — инструменты для любителей PDF
Полностью бесплатные онлайн-инструменты для объединения, разделения, сжатия PDF-файлов, преобразования документов Office в PDF-файлы, преобразования PDF-файлов в JPG и JPG в PDF. Без необходимости установки.
Объединить PDF
Объединяйте PDF файлы и упорядочите их легко и быстро в любом порядке, который вам нравится.
Разделить PDF
Выбирайте диапазон страниц, одну страницу или преобразовывайте каждую страницу документа в независимый PDF-файл.
Сжать PDF
Уменьшайте размер вашего PDF файла, и при этом сохраняйте качество. Оптимизируйте ваши PDF файлы.
PDF в Word
Конвертируйте ваши PDF файлы в легко редактируемые DOC и DOCX документы. Преобразованный WORD документ будет точным почти на 100%.
Преобразованный WORD документ будет точным почти на 100%.
PDF в Powerpoint
Конвертируйте ваши PDF файлы в легко редактируемые PPT и PPTX слайд-шоу.
PDF в Excel
Извлекайте данные прямо из PDF-файлов в электронные таблицы EXCEL, всего через несколько секунд.
Word в PDF
Конвертировать ваши документы в PDF-файл, который будет таким же самым как и оригинальный DOC или DOCX.
PowerPoint в PDF
Конвертировать ваши презентации в PDF-файл, который будет таким же самым как и оригинальный PPT или PPTX.
Excel в PDF
Преобразование ваших таблиц с колонками в PDF файл, с учетом ширины PDF. Книжная или альбомная ориентация. Ваш выбор.
Редактировать PDF
Добавить текст, изображения, формы или рукописные аннотации в PDF-документ. Измените размер, шрифт и цвет содержимого.
PDF в JPG
Извлекайте все изображения, содержащиеся в PDF или конвертируйте каждую страницу в файл JPG.
JPG в PDF
Конвертируйте ваши изображения в формат PDF. Регуляция ориентации и полей.
Регуляция ориентации и полей.
Подписать PDF
Подпишите документ и запросите подписи. Нарисуйте свою подпись или подпишите PDF-файлы с помощью цифрового удостоверения на основе сертификата.
Водяной знак
Выберите изображение или текст, которые вы хотите вставить в ваш PDF. Выберите положение, прозрачность и шрифт.
Повернуть PDF
Вращайте ваш PDF, как только хотите. Вращайте несколько PDF файлов одновременно!
HTML в PDF
Преобразуйте веб-страницы в HTML в PDF-файл. Скопируйте и вставьте URL-адрес нужной страницы и конвертируйте его в формат PDF одним щелчком мыши.
Открыть PDF
Снимите пароль безопасности для свободного использования файла.
Защита PDF
Защитите PDF файлы паролем. Шифруйте PDF документы для предотвращения несанкционированного доступа.
Организовать PDF
Сортируйте страницы вашего PDF-файла, как вам угодно. Удаляйте или добавляйте PDF-страницы в документ по своему усмотрению.
PDF в PDF/A
Преобразуйте ваш PDF-файл в PDF/A, соответствующую стандарту ISO версию PDF для долгосрочного хранения. Формат вашего PDF-файла будет сохранен.
Формат вашего PDF-файла будет сохранен.
Восстановить PDF
Восстановите поврежденный PDF файл и восстановите данные из поврежденного PDF файла. Исправляйте PDF файлы с помощью нашего инструмента восстановления.
Номера страниц
Легко добавляйте номера страниц в PDF документы. Выберите положение, размеры, формат и шрифт!
Сканировать в PDF
Создавайте сканы документов с помощью мобильного устройства и сразу же отправляйте их в браузер.
Загрузите настольное Приложение iLovePDF для работы с вашими любимыми PDF-инструментами на Mac или Windows. Используйте легкое приложение для работы с PDF-файлами, которое поможет вам быстро обрабатывать ресурсоемкие задачи в автономном режиме.
Используйте мобильное приложение iLovePDF для удаленного управления документами или на ходу. Превратите свое устройство Android или iPhone в редактор и сканер PDF-файлов, чтобы с легкостью комментировать, подписывать и обмениваться документами.
iLoveIMG это веб-приложение, которое позволяет вам выполнять групповое редактирование изображений совершенно бесплатно. Вы получаете возможность обрезать, изменить размер, сжимать, преобразовывать любые свои изображения. Все инструменты, необходимые для редактирования ваших изображений прямо под рукой.
Вы получаете возможность обрезать, изменить размер, сжимать, преобразовывать любые свои изображения. Все инструменты, необходимые для редактирования ваших изображений прямо под рукой.
iLovePDF — лучшее веб-приложение для легкого редактирования ваших PDF-файлов. Наслаждайтесь всеми инструментами, необходимыми для эффективной работы с вашими цифровыми документами, сохраняя при этом ваши данные в полной безопасности.
Выполняйте работу еще быстрее с помощью функции пакетной обработки файлов, конвертируйте отсканированные документы с помощью оптического сканирования (OCR) и подписывайте соглашения в электронной форме.
Пожалуйста, не занимайтесь самолечением!При симпотмах заболевания — обратитесь к врачу.
Читайте также:
- Молекулярные мишени в химиотерапии коронавирусной инфекции
- Клинические аспекты применения лактулозы в практике гастроэнтеролога: ТРУДНЫЙ ПАЦИЕНТ
- Можно ли заразиться гепатитом в стадии ремиссии
- Молочница: причины, симптомы и лечение
- Сифилис и беременность
Обучаем вместе с Tesseract OCR
Tesseract — свободная платформа для оптического распознавания текста, исходники которой Google подарил сообществу в 2006 году. Если вы пишете софт для распознавания текста, то вам наверняка приходилось обращаться к услугам этой мощной библиотеки. И если она не справилась с вашим текстом (а скорее всего это именно так), то выход у вас остаётся один — научить её. Процесс этот достаточно сложный и изобилует не очевидными, а порой и прям-таки магическими действиями.
Если вы пишете софт для распознавания текста, то вам наверняка приходилось обращаться к услугам этой мощной библиотеки. И если она не справилась с вашим текстом (а скорее всего это именно так), то выход у вас остаётся один — научить её. Процесс этот достаточно сложный и изобилует не очевидными, а порой и прям-таки магическими действиями.
Оригинальный проект находится на гитхабе, а скачать установщик можно здесь, На момент написания статьи версия установщика была 3.05.01. Мне понадобилось немало времени на постижение всей его глубины, поэтому я решил написать что и как, вдруг забуду что-то в будущем, а также чтобы помочь другим пройти этот путь в следующий раз быстрее.
0. Что нам нужно
- Tesseract собственно.
Сборки этой библиотеки есть под windows (можно скачать установщик отсюда) и под linux. Для большинства linux-дистрибутивов установить tesseract можно просто через sudo apt-get install tesseract-ocr.
- Изображение с текстом для тренировки
Желательно чтобы это был реальный текст, который потом придётся распознавать.
Между всеми символами должны быть чётко различимые промежутки. Кладём наше изображение в отдельную директорию и называем в виде <код языка>.<имя шрифта>.exp<номер>.tif. Изображение может быть не одно и отличаться они должны только номером в наименовании файла. Формат наименований файлов очень важен. На файлы с неверными наименованиями утилиты, которые мы будем использовать будут ругаться ошибками сегментирования и т.п. Для определённости будем считать, что изучаем мы язык ссс и шрифт eee. Таким образом называем файл со сканом тренировочного образца
1. Создаём и редактируем box-файл
Для того чтобы отметить символы на изображении и задать им соответствие utf-8 символам текста служат box-файлы. Это обычные текстовые файлы, в которых каждому символу соответствует строка с символом и координатами прямоугольника в пикселях. Первоначально файл генерируем утилитой из пакета tesseract:
Это обычные текстовые файлы, в которых каждому символу соответствует строка с символом и координатами прямоугольника в пикселях. Первоначально файл генерируем утилитой из пакета tesseract:tesseract ccc.eee.exp0.tif ccc.eee.exp0 batch.nochop makebox
получим файл
ccc.eee.exp0.box
в текущей директории. Заглянем в него. Да, чуть не забыл, не забудьте прописать адрес установленной Tesseract-OCR в переменную среды Path в windows, иначе команда tesseract не будет работать в консоли.
Символы в начале строки полностью соответствуют символам в файле? Если это так, то тренировать ничего не нужно, вы можете спать спокойно. В нашем случае скорее всего символы не будут совпадать ни по существу ни по количеству. Т.е. tesseract со словарём по умолчанию не распознал не только символы, но и посчитал некоторые из них за два или больше. Возможно часть символов у нас «слипнется», т.е. попадёт в общую коробку и будет распознано как один.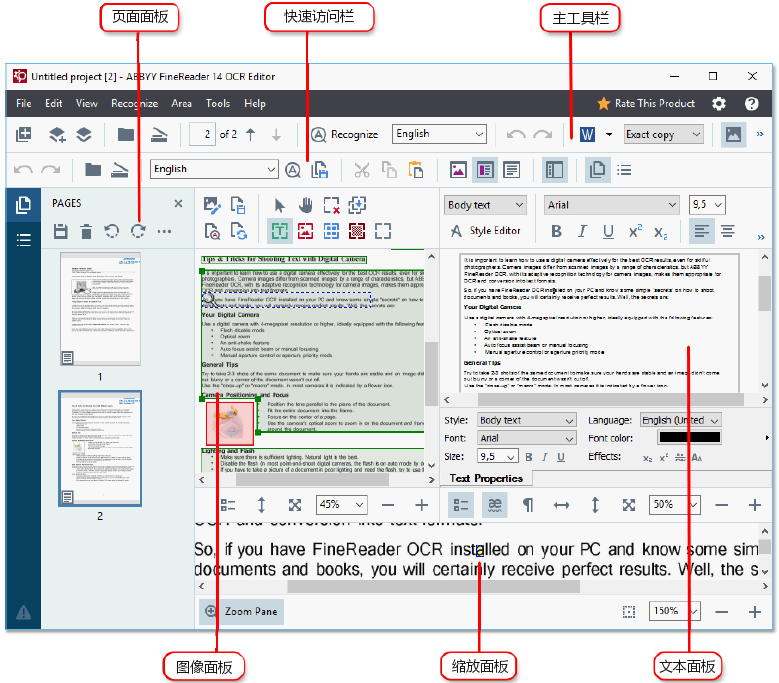
Работа нудная и кропотливая, но к счастью для этого есть ряд сторонних утилит. Я например пользовался jTessBoxEditor. Открываем им изображение, box-файл с таким же именем он сам подтянет (главное чтобы всё лежало в одной папке).
Переходим на вкладку Box Editor перетаскиваем туда наше изображение, либо жмем Open. Поигравшись немного с вкладками Box Coordinates, где с помощью кнопок Merge, Split, Insert, Delete можно соответственно объединить, разделить, добавить или удалить символы, дабы привести все в соответствии с изображением справа. Во вкладке
Прошло полдня… Вы с чувством глубокого удовлетворения закрываете jTessBoxEditor (вы ведь не забыли сохранить результат, верно?) и у вас есть корректный box-файл. Теперь можно переходить к следующему этапу.
2.
 Тренируем Tesseract
Тренируем Tesseract tesseract ccc.eee.exp0.tif ccc.eee.exp0 nobatch box.train
Получаем много ошибок, но ищем в конце что-то вроде «Found 105 good blobs». Если цифра существенно больше числа «изучаемых» символов, то есть шанс, что тренировка в целом удалась. Иначе — возвращаемся в начало. В результате этого шага у вас появился файл
3. Извлекаем набор символов
unicharset_extractor ccc.eee.exp0.box
Получаем набор символов в виде файла unicharset в текущей директории, где каждый символ и его характеристики располагаются в отдельной строке. Тут нашей задачей будет проверить и поправить характеристики символов (вторая колонка в файле). Для маленьких букв алфавита ставим признак 3, для больших 5, для знаков препинания 10 для цифр 8, всё остальное (типа +=-) помечаем 0. Китайские и японские иероглифы помечаем 1. Обычно все признаки стоят правильно, так что этот этап много времени у вас не займёт.
4. Описываем стиль шрифта
Создаём файл ccc.font_properties с единственной строкой: eee 0 0 0 0 0. Тут вначале пишем имя шрифта, затем числом 1 или 0 помечаем наличие у символов стиля (соответственно italic bold fixed serif fraktur). В нашем случае стилей нет, так что оставляем всё по нулям.
5. Кластеры фигур, прототипы и прочая магия
Для дальнейшей учёбы нам понадобиться выполнить ещё три операции. Можете попробовать понять их смысл из официального описания, мне было не до того :). Просто выполняем:shapeclustering -F ccc.font_properties -U unicharset ccc.eee.exp0.tr
…появится файл
shapetableа затем:
mftraining -F ccc.font_properties -U unicharset -O ccc.unicharset ccc.eee.exp0.tr…получим файлы
ccc.unicharset, inttemp, pffmtableи наконец:
cntraining ccc.eee.exp0.tr
…получим файл
normproto.
6. Словари
Теоретически заполнение словарей часто используемых слов (и слов вообще) помогает Tesseract-у разбираться в ваших каракулях. Словари использовать необязательно, но если вдруг захочется, делаем файлы frequent_words_list и words_list
Чтобы конвертировать эти списки в правильный формат выполняем:
wordlist2dawg frequent_words_list ccc.freq-dawg ccc.unicharsetwordlist2dawg words_list ccc.word-dawg ccc.unicharset
7. Последний загадочный файл
Имя ему — unicharambigs. По идее он должен обратить внимание Tesseract на похожие символы. Это текстовый файл, в каждой строке с разделителями табуляцией описываются пары строк, которые могут быть спутаны при распознавании. Полностью формат файла описан в документации, мне он был не нужен и я оставил его пустым.
8. Последняя команда
Все файлы нужно переименовать так чтобы их имена начинались с имени языка. Т.е. у нас в директории останутся только файлы:
ccc.boxccc.inttempccc.pffmtableccc.tifccc.font_propertiesccc.normprotoccc.shapetableccc.trccc.unicharset
И, наконец, выполняем:combine_tessdata ccc.
(!) Точка обязательна. В результате получаем файл ccc.traineddata, который и позволит нам дальше распознавать наш загадочный новый язык.
9. Проверяем, стоило ли оно того
Теперь попробуем распознать наш образец с помощью уже обученного Tesseract-а:sudo cp ccc.traineddata /usr/share/tesseract-ocr/tessdata/tesseract ccc.tif output -l ccc
Теперь смотрим в output. и радуемся (или огорчаемся, в зависимости от результата).  txt
txt
Из пикселей — в буквы: как работает распознавание текста
Что такое OCR?OCR (англ. optical character recognition, оптическое распознавание символов) — это технология автоматического анализа текста и превращения его в данные, которые может обрабатывать компьютер.
Когда человек читает текст, он распознает символы с помощью глаз и мозга. У компьютера в роли глаз выступает камера сканера, которая создает графическое изображение текстовой страницы (например, в формате JPG). Для компьютера нет разницы между фотографией текста и фотографией дома: и то, и другое — набор пикселей.
Именно OCR превращает изображение текста в текст. А с текстом уже можно делать что угодно.
Как это устроено?
Представьте, что в алфавите есть только одна буква «А». Сделает ли это задачу преобразования картинки в текст проще? Нет. Дело в том, что у каждой буквы (и любой другой графемы) есть аллографы — различные варианты начертания.
Человек легко поймет, что все это буква «А». Для компьютера же есть два способа решения проблемы: распознавать символы целостно (распознавание паттерна) или выделять отдельные черты, из которых состоит символ (выявление признаков).
Распознавание паттерна
В 1960-х годах был создан специальный шрифт OCR-A, который использовался в документах типа банковских чеков. Каждая буква в нем была одинаковой ширины (т.н. шрифт фиксированной ширины или моноширинный шрифт).
Образец шрифта OCR-AПринтеры для чеков работали с этим шрифтом, и для его распознавания было разработано программное обеспечение. Поскольку шрифт был стандартизирован, его распознавание стало относительно простой задачей. Следующим шагом стало обучение программ OCR распознавать символы еще в нескольких самых распространенных шрифтах (Times, Helvetica, Courier и т.д.).
Выявление признаков
Этот способ еще называют интеллектуальным распознаванием символов (англ. intelligent character recognition, ICR). Представьте, что вы — OCR-программа, которой дали множество разных букв, написанных разными шрифтами. Как вам отобрать из этого множества все буквы «А», если каждая из них немного отличается от другой?
intelligent character recognition, ICR). Представьте, что вы — OCR-программа, которой дали множество разных букв, написанных разными шрифтами. Как вам отобрать из этого множества все буквы «А», если каждая из них немного отличается от другой?
Можно использовать такое правило: если видишь две линии, сходящиеся наверху в центре под углом, а посередине между ними горизонтальная линия, то это буква «А». Это правило поможет распознать все буквы «А» независимо от шрифта. Вместо распознавания паттерна выделяются характерные индивидуальные черты, из которых состоит символ. Большинство современных омнишрифтовых (умеющих распознавать любой шрифт) OCR-программ работают по этому принципу. Чаще всего в них используются классификаторы на основе машинного обучения (т.к. фактически перед нами стоит задача классификации картинок по классам-буквам) в последнее время некоторые OCR-движки перешли на нейронные сети.
Что делать с рукописным вводом?
Человек способен догадаться о смысле предложения, даже если оно написано самым неразборчивым почерком (если речь не идет о рецепте на лекарства, конечно).![]()
Задачу для компьютера иногда упрощают. Например, людей просят писать почтовый индекс в специальном месте на конверте специальным шрифтом. Формы, созданные для дальнейшей обработки компьютером, обычно имеют отдельные поля, которые просят заполнять печатными буквами.
Планшеты и смартфоны, которые поддерживают рукописный ввод, часто используют принцип выявления признаков. При написании буквы «А» экран «чувствует», что сначала пользователь написал одну линию под углом, затем вторую, и, наконец, провел горизонтальную черту между ними. Компьютеру помогает то, что все признаки появляются последовательно, один за другим, в отличие от варианта, когда весь текст уже записан от руки на бумаге.
OCR по шагам
Предобработка
Чем лучше качество исходного текста на бумажном носителе, тем лучше будет качество распознавания. А вот старый шрифт, пятна от кофе или чернил, заломы бумаги понижают шансы.
Большинство современных OCR-программ сканируют страницу, распознают текст, а затем сканируют следующую страницу. Первый этап распознавания заключается в создании копии черно-белого цвета или в оттенках серого. Если исходное отсканированное изображение идеально, то все черное — это символы, а все белое — фон.
Первый этап распознавания заключается в создании копии черно-белого цвета или в оттенках серого. Если исходное отсканированное изображение идеально, то все черное — это символы, а все белое — фон.
Распознавание
Хорошие OCR-программы автоматически отмечают трудные элементы структуры страницы — колонки, таблицы и картинки. Все OCR-программы распознают текст последовательно, символ за символом, словом за словом и строчка за строчкой.
Сначала OCR-программа объединяет пиксели в возможные буквы, а буквы — в возможные слова. Затем система сопоставляет варианты слов со словарем. Если слово найдено, оно отмечается как распознанное. Если слово не найдено, программа предоставляет наиболее вероятный вариант и, соответственно, качество распознавания будет не таким высоким.
Постобработка
Некоторые программы дают возможность просмотреть и исправить ошибки на каждой странице. Для этого они используют встроенную проверку орфографии и выделяют неверно написанные слова, что может указывать на неправильное распознавание. Продвинутые OCR-программы используют так называемый метод поиска соседа, чтобы найти слова, которые часто встречаются рядом. Этот метод позволяет исправить неверно распознанное словосочетание «тающая собака» на «лающая собака».
Продвинутые OCR-программы используют так называемый метод поиска соседа, чтобы найти слова, которые часто встречаются рядом. Этот метод позволяет исправить неверно распознанное словосочетание «тающая собака» на «лающая собака».
Кроме того, некоторые проекты, которые занимаются оцифровкой и распознаванием текстов, прибегают к помощи волонтеров: распознанные тексты выкладываются в открытый доступ для вычитки и проверки ошибок распознавания.
Особые случаи
Для высокой точности распознавания исторического текста с необычными графическими символами, отличающимися от современных шрифтов, необходимо извлечь соответствующие изображения из документов. Для языков с небольшим набором символов это можно сделать вручную, но для языков со сложными системами письменности (например, иероглифических) ручной сбор этих данных нецелесообразен.
Для распознавания исторических китайских текстов требуется внести в OCR-программу как минимум 3000 символов, которые имеют разную частотность. Если для распознавания исторических английских текстов достаточно ручной разметки нескольких десятков страниц, то аналогичный процесс для китайского языка потребует анализа десятков тысяч страниц.
Если для распознавания исторических английских текстов достаточно ручной разметки нескольких десятков страниц, то аналогичный процесс для китайского языка потребует анализа десятков тысяч страниц.
В то же время многие исторические варианты китайской письменности имеют высокую степень сходства с современным письмом, поэтому модели распознавания символов, обученные на современных данных, часто могут давать приемлемые результаты на исторических данных, хоть и со сниженной точностью. Этот факт вместе с использованием корпусов позволяет создать систему для распознавания исторических китайских текстов. Для этого исследователь Д. Стеджен (Donald Sturgeon) из Гарварда обработал два корпуса: корпус транскрибированных исторических документов и корпус отсканированных документов желаемого стиля.
После предварительной обработки изображений и этапов сегментации символов процедура извлечения обучающих данных состояла из:
1) применения модели распознавания символов, обученной исключительно на современных документах, к историческим документам для получения промежуточного результата оптического распознавания с низкой точностью;
2) использование этого промежуточного результата для соотнесения изображения с его вероятной транскрипцией;
3) извлечение изображений размеченных символов на основе этого соотнесения;
4) выбор из размеченных символов подходящих обучающих примеров.
Полученные данные могут использоваться без проверки для обучения новой модели распознавания символов, позволяющей достичь более высокой точности на аналогичном материале.
Источники:
- Optical character recognition (OCR)
- Unsupervised Extraction of Training Data for Pre-Modern Chinese OCR
Теги:OCR, распознавание текста
FF OCR-F Font | FontShop
Designed by Albert-Jan Pool in 1995. Published by FontFont.
Starts at €55.99 for a single style and is available for:
Type to compare other characters
&
Light
&
Regular
&
Bold
FF OCR-F supports up to 110 different languages such as Spanish, English, Portuguese, Russian, German, French, Turkish, Italian, Polish, Ukrainian, Uzbek, Kurdish (Latin), Azerbaijani (Latin), Azerbaijani (Cyrillic), Romanian, Dutch, Hungarian, Serbian (Latin), Serbian (Cyrillic), Kazakh (Latin), Czech, Bulgarian, Swedish, Belarusian (Latin), Belarusian (Cyrillic), Croatian, Slovak, Finnish, Danish, Lithuanian, Latvian, Slovenian, Irish, Estonian, Basque, Icelandic, and Luxembourgian in Latin, Cyrillic, and other scripts.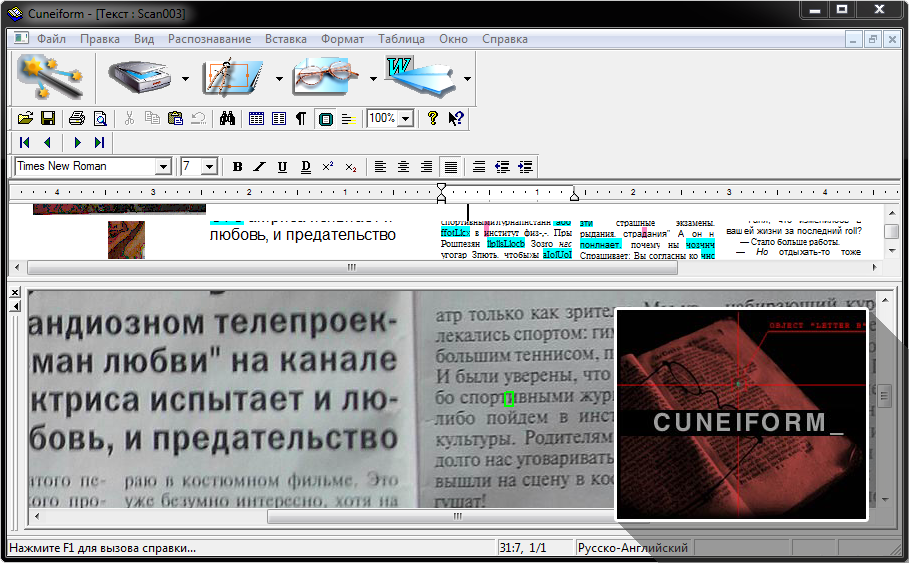
Please note that not all languages are available for all formats.
View all 110 languages
Rülps
Byääh
Prööt
Please select a product:
FF OCR-F Std Light (OpenType .otf – Std)FF OCR-F Pro Light (OpenType .otf – Pro)FF OCR-F Std Regular (OpenType .otf – Std)FF OCR-F Pro Regular (OpenType .otf – Pro)FF OCR-F Std Bold (OpenType .otf – Std)FF OCR-F Pro Bold (OpenType .otf – Pro)
- A
- Afar
- Afrikaans
- Albanian
- Asturian
- B
- Basque
- Breton
- C
- Catalan
- Cornish
- Corsican
- D
- Danish
- Dutch
- E
- English
- F
- Faroese
- Fijian
- Finnish
- French
- Frisian
- Friulian
- G
- Gaelic (Scottish)
- Galician
- German
- I
- Icelandic
- Indonesian
- Irish
- Italian
- K
- Kinyarwanda (Ruanda)
- Kirundi (Rundi)
- L
- Ladin
- Luxembourgian
- M
- Malay (Latin)
- N
- Norwegian
- O
- Occitan
- Oromo (Afan, Galla)
- P
- Papiamentu
- Portuguese
- Q
- Quechua
- R
- Rhaeto-Romance
- S
- Sardinian
- Shona
- Somali
- Spanish
- Swahili (Kiswahili)
- Swedish
- T
- Tagalog
- Tsonga
- Tswana
- U
- Uighur
- W
- Walloon
- X
- Xhosa
- Z
- Zulu
NumbersFormsotherFormatting
Tabular Figures
Lining Figures
Oldstyle Figures
Superscript
Subscript
Fractions
Proportional Figures
Changes figures with tabular widths to figures with proportional widths.
_
`
{
}
¡
§
¨
¯
´
¶
·
¸
¿
;
–
—
―
‚
„
†
‡
•
…
‰
Uppercase
A
B
C
D
E
F
G
H
I
J
K
L
M
N
O
P
Q
R
S
T
U
V
W
X
Y
Z
Lowercase
a
b
c
d
e
f
g
h
i
j
k
l
m
n
o
p
q
r
s
t
u
v
w
x
y
z
Phonetic Extensions
Modifiers
ʻ
ʼ
ˆ
ˇ
ˉ
˘
˙
˚
˛
˜
˝
Combining Diacritical Marks
̀
́
̂
̃
̄
̆
̇
̈
̊
̋
̌
̒
̓
̦
̧
̨
̵
̶
Ligatures
Currency
$
¢
£
¤
¥
€
₴
Symbols
+
=
>
|
~
¬
±
×
÷
Decimal
1
2
3
4
5
6
7
8
9
Other
²
³
¹
¼
½
¾
Mathematical Operators
⁄
∂
∆
∏
∑
−
∙
√
∞
∫
≈
≠
≤
≥
⋅
Superscripts and Subscripts
⁰
⁴
⁵
⁶
⁷
⁸
⁹
₀
₁
₂
₃
₄
₅
₆
₇
₈
₉
Number Forms
⅐
⅑
⅒
⅓
⅔
⅕
⅖
⅗
⅘
⅙
⅚
⅛
⅜
⅝
⅞
⅟
↉
Miscellaneous
Letterlike
Geometric Shapes
Lowercase
µ
ß
à
á
â
ã
ä
å
æ
ç
è
é
ê
ë
ì
í
î
ï
ð
ñ
ò
ó
ô
õ
ö
ø
ù
ú
û
ü
ý
þ
ÿ
ā
ă
ą
ć
ĉ
ċ
č
ď
đ
ē
ĕ
ė
ę
ě
ĝ
ğ
ġ
ģ
ĥ
ħ
ĩ
ī
ĭ
į
ı
ij
ĵ
ķ
ĸ
ĺ
ļ
ľ
ŀ
ł
ń
ņ
ň
ʼn
ŋ
ō
ŏ
ő
œ
ŕ
ŗ
ř
ś
ŝ
ş
š
ţ
ť
ŧ
ũ
ū
ŭ
ů
ű
ų
ŵ
ŷ
ź
ż
ž
ſ
ƒ
ƶ
ǐ
ǧ
ǻ
ǽ
ǿ
ș
ț
ȷ
ẁ
ẃ
ẅ
ẋ
ỳ
Uppercase
À
Á
Â
Ã
Ä
Å
Æ
Ç
È
É
Ê
Ë
Ì
Í
Î
Ï
Ð
Ñ
Ò
Ó
Ô
Õ
Ö
Ø
Ù
Ú
Û
Ü
Ý
Þ
Ā
Ă
Ą
Ć
Ĉ
Ċ
Č
Ď
Đ
Ē
Ĕ
Ė
Ę
Ě
Ĝ
Ğ
Ġ
Ģ
Ĥ
Ħ
Ĩ
Ī
Ĭ
Į
İ
IJ
Ĵ
Ķ
Ĺ
Ļ
Ľ
Ŀ
Ł
Ń
Ņ
Ň
Ŋ
Ō
Ŏ
Ő
Œ
Ŕ
Ŗ
Ř
Ś
Ŝ
Ş
Š
Ţ
Ť
Ŧ
Ũ
Ū
Ŭ
Ů
Ű
Ų
Ŵ
Ŷ
Ÿ
Ź
Ż
Ž
Ə
Ƶ
Ǐ
Ǧ
Ǻ
Ǽ
Ǿ
Ș
Ț
Ẁ
Ẃ
Ẅ
Ẋ
Ỳ
Uppercase
Lowercase
Uppercase
Ѐ
Ё
Ђ
Ѓ
Є
Ѕ
І
Ї
Ј
Љ
Њ
Ћ
Ќ
Ѝ
Ў
Џ
А
Б
В
Г
Д
Е
Ж
З
И
Й
К
Л
М
Н
О
П
Р
С
Т
У
Ф
Х
Ц
Ч
Ш
Щ
Ъ
Ы
Ь
Э
Ю
Я
Ѣ
Ѳ
Ѵ
Ґ
Ғ
Җ
Қ
Ҝ
Ң
Ү
Ұ
Ҳ
Ҷ
Ҹ
Һ
Ӏ
Ә
Ӛ
Ӝ
Ӟ
Ӣ
Ӥ
Ӧ
Ө
Ӫ
Ӯ
Ӱ
Ӳ
Ӵ
Ӹ
Lowercase
а
б
в
г
д
е
ж
з
и
й
к
л
м
н
о
п
р
с
т
у
ф
х
ц
ч
ш
щ
ъ
ы
ь
э
ю
я
ѐ
ё
ђ
ѓ
є
ѕ
і
ї
ј
љ
њ
ћ
ќ
ѝ
ў
џ
ѣ
ѳ
ѵ
ґ
ғ
җ
қ
ҝ
ң
ү
ұ
ҳ
ҷ
ҹ
һ
ӏ
ә
ӛ
ӝ
ӟ
ӣ
ӥ
ӧ
ө
ӫ
ӯ
ӱ
ӳ
ӵ
ӹ
FF OCR-F has 3 Styles
OCR, история и принцип работы этой технологии распознавания
16 октября 2020 Мэтт Миллс Советы и хитрости 0
Технология OCR существует уже давно и является ключом к облегчению работы многих людей, поскольку это способность преобразовывать символы, которые являются неотъемлемой частью изображения, в символы, которыми можно манипулировать, что позволяет избежать утомительной задачи расшифровка текста . Но что за всем этим стоит?
Но что за всем этим стоит?
OCR сегодня используется круглосуточно и не только для оцифровки текстов, но и для таких вещей, как перевод в реальном времени текста, написанного на других языках, и мы даже можем преобразовать рукописный текст в печатный.
Contents [show]
- OCR и распознавание образов
- Распознавание символов через OCR
- Завивка локонов без распознавания текста
- Искусственный интеллект на помощь в распознавании символов
Под паттерном мы понимаем модель, которая служит для получения чего-то подобного; В то время как наши глаза и мозг идентифицируют каждую букву по ее написанию, компьютер не обладает такой способностью к абстракции и должен иметь возможность проводить сравнение, которое всегда является результатом вычитания между двумя элементами: если вычитание дает 0 так что это означает, что сравнение положительное.
В 1960 году Лоуренс (Ларри) Робертс, исследователь Массачусетского технологического института, который, как ни парадоксально, позже стал одним из изобретателей того, что в конечном итоге стало Интернетом, создал систему распознавания символов и связанный с ней шрифт, предназначенный для оцифровки банковских чеков и т. Д. на. конфиденциальная информация, которую нужно было хранить на ранних компьютерах. Этот источник получил название OCR-A.
Д. на. конфиденциальная информация, которую нужно было хранить на ранних компьютерах. Этот источник получил название OCR-A.
Если подумать, для компьютера буква, как и любой другой тип данных, представляет собой не что иное, как набор бит, поэтому все, что нам нужно, это сохранить ее в системе, отвечающей за сравнение шрифта в его разных размерах. как сравнительный шрифт.
Распознавание символов через OCR
Первое, что сделает система OCR, — это прочитает документ, чтобы найти текст и исключить для последующего анализа все, что не полезно для оптического распознавания символов.
Как только у вас будут только символы, вам нужно будет просмотреть то, что осталось от изображения, взять его блоки и оцифровать их для последующего сравнения с информацией в памяти. Другими словами, система обнаружения символов просматривает изображение, считывая его блоками с регулярным числом пикселей и непрерывно сравнивая с формами, которые она хранит в своей памяти.
Если он найдет совпадение, он пометит его в файле, который затем покажет и / или сохранит как заключение; указанный файл будет текстовым файлом с самим текстом, извлеченным в процессе распознавания.
Это означает, что наша система распознавания символов должна иметь в памяти шрифт, которым текст был написан на бумаге, или изображение, из которого мы хотим его извлечь, если она может производить сравнение. Но что происходит в особых случаях, таких как рукописный ввод или специальные шрифты?
Завивка локонов без распознавания текста
Возвращаясь к тому, как работает наш мозг, он идентифицирует вещи, потому что он усвоил шаблон, который позволяет ему их идентифицировать. Наш мозг прекрасно знает через выученный образец, что все буквы на следующем изображении — это буква А.
Но компьютер, как правило, не знает этого напрямую и нуждается в системе отсчета, которую мы прокомментировали выше, чтобы знать, является ли сравнение положительным или нет, что привело к тому, что при чтении почерка, который различен для каждого человека, пришлось пройти через долгие усилия в течение нескольких лет.
Как историческое любопытство, когда Apple выпустили то, что можно было бы считать первым в мире «карманным» компьютером, Apple Newton, они пообещали, что у него будет система распознавания рукописного ввода, которая вовремя преобразует вводимые пользователем тексты в печатные. настоящий.
настоящий.
Результат? Катастрофа, так как я не понимал, как пишут большинство людей, и устройство вышло из строя.
Причина этого заключалась не в том, что системы Newton и более поздние были плохими, а в том, что для распознавания образов требовалось много вычислительной мощности, чего не было и не было в течение длительного времени. Даже системы распознавания рукописного ввода поддерживают огромные центры обработки данных и обработки, с которыми они общаются через Интернет.
Искусственный интеллект на помощь в распознавании символов
Системы искусственного интеллекта на самом деле представляют собой системы, обученные распознавать определенные шаблоны, и их можно обучить распознавать символы не на основе сравнительного элемента, а путем применения шаблонов. Например, мы можем идентифицировать букву A с помощью простого шаблона, подобного следующему:
Но идея состоит в том, чтобы обучить машину так, чтобы она знала, как распознавать шаблон без необходимости проводить сравнение, и именно в этот момент появляется искусственный интеллект. Точно так же, как мы можем обучить искусственный интеллект распознавать дорожные знаки. чтобы он мог двигаться в автоматическом режиме, мы также можем научить его распознавать символы. Как? Ну, через нейронную сеть, которая была этому ранее обучена.
Точно так же, как мы можем обучить искусственный интеллект распознавать дорожные знаки. чтобы он мог двигаться в автоматическом режиме, мы также можем научить его распознавать символы. Как? Ну, через нейронную сеть, которая была этому ранее обучена.
Наиболее широко в этих случаях используются так называемые сверточные нейронные сети, которые представляют собой тип искусственных нейронов, которые имеют структуру, аналогичную нейронам первичной зрительной коры биологического мозга, и отлично подходят для классификации и сегментации изображений. и другие приложения компьютерного зрения.
Эти нейронные сети копируют работу биологических систем, отвечающих за обнаружение шаблонов, которые позволяют нам идентифицировать каждую букву.
В то же время каждый раз, когда идентификация оказывается положительной и подтверждается несколько раз, этот пример сохраняется в базе данных для использования в качестве шаблона позже. Фактически, системы в этом случае работают сначала, если есть соответствие в базе данных, которая была создана, и только тогда, когда она не находит, когда активируются механизмы для идентификации шаблонов с помощью искусственного интеллекта.
- Графика
- OCR
OCR A Обычный | Fonts.com
Перейти к основному содержанию
- Попытайся
- Водопад
- Карта персонажей
- OpenType
- Технические подробности
Рабочий стол Веб-шрифт
Попробуйте этот шрифт прямо сейчас! Используйте элементы управления ниже, чтобы настроить текстовую строку и ее внешний вид.
Образец текста
Быстрая коричневая лиса прыгает через ленивую собаку. Быстрая коричневая лиса прыгает через ленивую собаку.
Размер шрифта:
8
1213141618243248647296Цвет текста:
Фон:
Попробуйте этот веб-шрифт прямо сейчас! Просто отредактируйте образец текста ниже или измените цвет и размер.
Выберите языковую поддержку Desktop CompatibleLatin 1Latin 1 + OT Features
Образец текста Быстрая коричневая лиса прыгает через ленивую собаку. Быстрая коричневая лиса прыгает через ленивую собаку.
Размер шрифта:
8
1213141618243248647296Цвет текста:
Фон:
Быстрая коричневая лиса перепрыгивает через ленивую собаку. Быстрая коричневая лиса прыгает через ленивую собаку.
@font-face{font-family:»OCR A W05 Regular»;src:url(«//fast.fonts.net/dv2/14/27921953-f1d4-48ca-88d9-7e370e84f3de.woff2?d44f19a684109620e484147fa790e81859e92aaaea3d337f84586d5df8888fe5455f55e0f83ed0be044ddfaa95e824a4b1318d5b552aaa24a44025e9&projectid=74f39a9d-a5dc-405f-9690-1c1fd4590ae4») format(«woff2»),url(«//fast. fonts.net/dv2/3/d441a553-ec90-4098-bc5e-7ed6321aacf2.woff?d44f19a684109620e484147fa790e81859e92aaaea3d337f84586d5df8888fe5455f55e0f83ed0be044ddfaa95e824a4b1318d5b552aaa24a44025e9&projectid=74f39a9d -a5dc-405f-9690-1c1fd4590ae4″) формат («woff»)}
fonts.net/dv2/3/d441a553-ec90-4098-bc5e-7ed6321aacf2.woff?d44f19a684109620e484147fa790e81859e92aaaea3d337f84586d5df8888fe5455f55e0f83ed0be044ddfaa95e824a4b1318d5b552aaa24a44025e9&projectid=74f39a9d -a5dc-405f-9690-1c1fd4590ae4″) формат («woff»)}
Быстрая коричневая лиса перепрыгивает через ленивую собаку. Быстрая коричневая лиса прыгает через ленивую собаку.
@font-face{font-family:»OCR A W01 Regular»;src:url(«//fast.fonts.net/dv2/14/cba188d8-b0db-4c90-93ea-a9a197005e7f.woff2?d44f19a684109620e484147fa790e81859e92aaaea3d337f84586d5df8888fe5455f55e0f83ed0be044ddfaa95e824a4b1318d5b552aaa24a44025e9&projectid=74f39a9d-a5dc-405f-9690-1c1fd4590ae4») format(«woff2»),url(«//fast.fonts.net/dv2/3/09411a5d-546c-4e8f-be8c -cce096650951.woff?d44f19a684109620e484147fa790e81859e92aaaea3d337f84586d5df8888fe5455f55e0f83ed0be044ddfaa95e824a4b1318d5b552aaa24a44025e9&projectid=74f39a9d-a5dc-405f-9690-1c1fd4590ae4») format(«woff»)}
Быстрая коричневая лиса перепрыгивает через ленивую собаку. Быстрая коричневая лиса прыгает через ленивую собаку.
Быстрая коричневая лиса прыгает через ленивую собаку.
@font-face{font-family:»OCR A W03 Regular»;src:url(«//fast.fonts.net/dv2/14/83b54884-38e4-4fb5-92de-f8c820871dc3.woff2?d44f19a684109620e484147fa790e81859e92aaaea3d337f84586d5df8888fe5455f55e0f83ed0be044ddfaa95e824a4b1318d5b552aaa24a44025e9&projectid=74f39a9d -a5dc-405f-9690-1c1fd4590ae4») format(«woff2»),url(«//fast.fonts.net/dv2/3/c4fb3c11-fc57-4a78-87f1-e4cf4c1fd01a.woff?d44f19a684109620e484147fa790e81859e92aaaea3d337f84586d5df8888fe5455f55e0f83ed0be044ddfaa95e824a4b1318d5b552aaa24a44025e9Формат &projectid=74f39a9d-a5dc-405f-9690-1c1fd4590ae4»)(«woff»)}
Рабочий стол Веб-шрифт
Попробуйте этот шрифт прямо сейчас! Используйте элементы управления ниже, чтобы настроить текстовую строку и ее внешний вид.
Образец текста
Быстрая коричневая лиса прыгает через ленивую собаку. Быстрая коричневая лиса прыгает через ленивую собаку.
Попробуйте этот веб-шрифт прямо сейчас! Введите текст и нажмите кнопку «Изменить образец текста».
Образец текста Быстрая коричневая лиса прыгает через ленивую собаку. Быстрая коричневая лиса прыгает через ленивую собаку.
72 Быстрая коричневая лиса прыгает через ленивую собаку. Быстрая коричневая лиса прыгает через ленивую собаку.
60 Быстрая коричневая лиса прыгает через ленивую собаку. Быстрая коричневая лиса прыгает через ленивую собаку.
48 Быстрая коричневая лиса прыгает через ленивую собаку. Быстрая коричневая лиса прыгает через ленивую собаку.
36
Быстрая коричневая лиса прыгает через ленивую собаку. Быстрая коричневая лиса прыгает через ленивую собаку.
Быстрая коричневая лиса прыгает через ленивую собаку.
24 Быстрая коричневая лиса прыгает через ленивую собаку. Быстрая коричневая лиса прыгает через ленивую собаку.
18 Быстрая коричневая лиса прыгает через ленивую собаку. Быстрая коричневая лиса прыгает через ленивую собаку.
14 Быстрая коричневая лиса прыгает через ленивую собаку. Быстрая коричневая лиса прыгает через ленивую собаку.
12 Быстрая коричневая лиса прыгает через ленивую собаку. Быстрая коричневая лиса прыгает через ленивую собаку.
10
Быстрая коричневая лиса прыгает через ленивую собаку. Быстрая коричневая лиса прыгает через ленивую собаку.
Быстрая коричневая лиса прыгает через ленивую собаку.
8 Быстрая коричневая лиса прыгает через ленивую собаку. Быстрая коричневая лиса прыгает через ленивую собаку.
Рабочий стол Веб-шрифт
Загрузка…
Загрузка…
Рабочий стол Веб-шрифт
Рабочий стол Веб-шрифт
 otf
otf Window Menu Name(s): Другие продукты Технические детали
| Формат: | OpenType Std (TTF) |
| Количество символов: | 204 |
| Код продукта: | L80051OPN |
| Материал Номер: | 16880051 |
| Техническое имя (S): | |
| Имя файла (S): | |
| Имя файла (S): | |
| . |
Current Product Technical Details
| Format: | Latin 1 + OT Features |
| Character Count: | 204 |
| CSS Name: | OCR A W03 Regular |
Available Web Font Formats
| Format: | WOFF |
| File Size: | 20.85 Kb |
| Browsers: |
| Format: | WOFF2 |
| Размер файла: | 20,18 Кб |
| Браузеры: |
Найти 10 сайтов0001
Иван Кук
• Подано в: OCR PDF
Шрифт OCR изначально был разработан для преодоления ограничений программного обеспечения OCR в первые дни современной компьютерной революции, что позволяет легко читать его машинами. В нем используется ряд широких и простых штрихов, которые легко идентифицировать, и наиболее распространенным сегодня является шрифт для номеров чеков, где он до сих пор пользуется почти универсальным распространением во всем мире. Несмотря на то, что сегодняшняя технология OCR значительно продвинулась вперед, ее по-прежнему стоит загрузить, поскольку она обеспечивает исключительные результаты и снижает количество ошибок при сканировании. Попробуйте лучшее программное обеспечение для распознавания текста: PDFelement Pro.
В нем используется ряд широких и простых штрихов, которые легко идентифицировать, и наиболее распространенным сегодня является шрифт для номеров чеков, где он до сих пор пользуется почти универсальным распространением во всем мире. Несмотря на то, что сегодняшняя технология OCR значительно продвинулась вперед, ее по-прежнему стоит загрузить, поскольку она обеспечивает исключительные результаты и снижает количество ошибок при сканировании. Попробуйте лучшее программное обеспечение для распознавания текста: PDFelement Pro.
ПОПРОБУЙТЕ БЕСПЛАТНО
Часть 1. 10 лучших веб-сайтов для загрузки лучших шрифтов для OCR
Пакеты шрифтов OCR-a и OCR-b можно загрузить из множества источников. Вот некоторые из лучших:
№ | Имя | Информация |
|---|---|---|
| 1 | Прикольный текст | Простой в использовании сайт без излишеств, предлагающий простой процесс загрузки, а также шрифт OCR и широкий выбор других шрифтов, доступных для загрузки. Он дает хорошее представление о том, как выглядит шрифт, краткое изложение каждого символа и инструкции по установке для различных платформ. Он дает хорошее представление о том, как выглядит шрифт, краткое изложение каждого символа и инструкции по установке для различных платформ. |
| 2 | Зона шрифта | Удобный поиск и более изысканный дизайн, каждый шрифт представлен на отдельной странице с заметной кнопкой загрузки и хорошим отображением всех символов в том виде, в котором они появляются в шрифте. Внизу каждой страницы есть хорошее руководство по установке ваших шрифтов, а кроме шрифта OCR есть большой выбор других, разделенных на удобные категории. |
| 3 | SourceForge | Известный источник всех видов бесплатного программного обеспечения, утилит с открытым исходным кодом и так далее. Он также отлично подходит для таких вещей, как шрифты, с простым процессом поиска и загрузкой одним щелчком мыши. Здесь нет представления самого шрифта, как на сайтах специализированных шрифтов. |
| 4 | Фонтзона | Это очень простой сайт, но загруженный выбором шрифтов, простая страница с одним нажатием кнопки загрузки, но только ограниченное представление того, как выглядит шрифт, прежде чем вы его загрузите. У него есть полезный раздел «популярных» шрифтов, который позволяет вам видеть, что люди загружают, если вы просто просматриваете новый шрифт. У него есть полезный раздел «популярных» шрифтов, который позволяет вам видеть, что люди загружают, если вы просто просматриваете новый шрифт. |
| 5 | Дворец шрифтов | Большая панель поиска и кнопка загрузки, защищенная капчей, являются основными функциями здесь. Последнее может раздражать, но не то, что меня слишком сильно беспокоит. Мне нравится представление каждого символа в шрифте, на сайте также много новых шрифтов, на которые стоит обратить внимание. |
| 6 | ФонтЮкле | Простой дизайн с удобным поиском и большой кнопкой загрузки. Хорошие, большие превью, показывающие каждый символ шрифта по очереди, хороший сайт для поиска шрифтов. |
| 7 | Мягкий 112 | Полный пакет шрифтов OCR доступен в Soft 112, его легко найти, и он имеет кнопку загрузки одним нажатием. Есть лучшие места для шрифтов, но он выполняет свою работу. |
| 8 | РадостьСкачать | На этом сайте есть полный пакет OCR, а не отдельные шрифты, поэтому вы получаете OCR A и OCR B, а также шрифт штрих-кода. Хороший сайт с загрузкой в один клик и удобным поиском, хотя другие лучше подходят для отдельных шрифтов. Хороший сайт с загрузкой в один клик и удобным поиском, хотя другие лучше подходят для отдельных шрифтов. |
| 9 | Download.com | Принадлежит CNET, это удобный и хорошо управляемый сайт с множеством бесплатных материалов для поиска и загрузки, программного обеспечения и игр с открытым исходным кодом, утилит и, конечно же, шрифтов. Загрузка осуществляется в один клик, и есть хорошее описание включенных шрифтов. |
| 10 | Fontsgeek | Очень простой сайт, на котором есть немного больше, чем панель поиска и несколько шрифтов. Загрузка проста, и страница дает хорошее представление о шрифте, хотя и не показывает все символы, как некоторые. |
Часть 2. Как распознавать PDF-файл с помощью лучшего программного обеспечения для распознавания текста для Mac
PDFelement Pro — лучший инструмент для распознавания PDF ваши отсканированные документы, редактирование и преобразование их в полностью доступные для поиска и редактирования документы.
 С помощью различных инструментов редактирования вы можете редактировать файлы PDF так же легко, как работать с файлами Word.
С помощью различных инструментов редактирования вы можете редактировать файлы PDF так же легко, как работать с файлами Word.ПОПРОБУЙТЕ БЕСПЛАТНО
Почему стоит выбрать этот PDF-редактор:
- Расширенная функция распознавания текста, включая полную библиотеку на 17 языках, а также привлекательный и понятный пользовательский интерфейс
- Редактируйте тексты PDF, ссылки, изображения, страницы и легко добавляйте пометки и аннотации к файлам PDF с помощью разнообразных инструментов аннотирования.
- Это также комплексный конвертер файлов PDF, конвертирующий в файлы электронных книг epub, документы Word, файлы Excel и обычный текст.
- Мощная функция форм PDF легко заполняет и создает формы PDF, а также извлекает данные формы PDF одним щелчком мыши.
OCR Отсканированные PDF-документы за несколько простых шагов:
Шаг 1. Добавьте PDF-файлы в программу
Первым шагом является импорт файла, который вы хотите преобразовать в доступный для поиска текст, в редактор PDF. Вы можете либо перетащить файлы в программу, либо нажать «Открыть файл» в главном интерфейсе.
Вы можете либо перетащить файлы в программу, либо нажать «Открыть файл» в главном интерфейсе.
Шаг 2. Запустите распознавание PDF
Чтобы распознать отсканированный файл PDF, вы можете перейти на вкладку «Инструменты» и выбрать «Распознавание текста OCR», чтобы включить функцию распознавания.
Советы: это программное обеспечение Mac OCR поддерживает 23 языка. Чтобы настроить язык, вы можете перейти к правой панели управления и выбрать «Язык документа».
Шаг 3. Пакетное распознавание PDF
Вы можете нажать кнопку «Добавить», чтобы импортировать несколько отсканированных PDF-файлов. Наконец, нажмите «Выполнить распознавание», чтобы распознать файлы.
ПОПРОБУЙТЕ БЕСПЛАТНО
AnyOCR — шрифт OCR следующего поколения
Откройте для себя AnyOCR — шрифт OCR следующего поколения. Получите наш оптимизированный для распознавания текста шрифт бесплатно. Оптимизирован как для человека, так и для машинного чтения.
Команда инженеров Anyline
Инженеры Anyline
07 июля 2017 г.
Некоторые из вас могут спросить себя: «Зачем создавать новый шрифт OCR? Существующая технология достаточно хороша, чтобы читать шрифты, не оптимизированные для оптического распознавания символов!» Вы также можете подумать, что за последние 50 лет было уже два OCR-шрифта и мир вообще перегружен шрифтами. Но это было до того, как вы увидели наш новый OCR-шрифт.
Потребовалась серьезная оптимизация, чтобы сформировать идеальную команду, состоящую из технологии OCR и этого нового шрифта OCR. И это именно то, что мы — вместе с командой дизайнеров Многожанрового бюро «laut aber leise» — сделали. Дамы и господа, поприветствуйте AnyOCR!
История шрифтов OCR
Каждый, кто работает в области оптического распознавания символов, в частности распознавания текста, сталкивается с традиционными шрифтами OCR-A и OCR-B. Еще в 1968 году, когда были представлены шрифты, необходимо было выполнить два важных требования.
Шрифт должен был быть идеально читаем машинами и компьютерами, но он также должен был быть читаем человеческим глазом.
Разработка OCR-A
Американский национальный институт стандартов (ANSI) нанял уважаемых американских основателей шрифтов (например, Franklin Gothic, Bank Gothic) для разработки шрифта OCR-A. Из-за особого символа каждой буквы и связанного с этим различия шрифт оптимизирован для машиночитаемости.
Однако вторым требованием немного пренебрегли. OCR-A читается человеком, но форма символов неестественна и поэтому неудобна для чтения.
Разработка OCR-B
Адриан Фрутигер был одним из самых известных типографов. Он был наиболее известен дизайном шрифтов Universe, Frutiger и Avenir. OCR-A не пользовался большой популярностью в Европе, поэтому Frutiger разработал новую версию для Европейской ассоциации производителей компьютеров (ECMA).
Если вы сравните шрифты выше, вы сразу же узнаете читабельность OCR-B. Оба шрифта соответствуют требованиям Международной организации по стандартизации (ISO).
AnyOCR: шрифт OCR следующего поколения
Зачем создавать новый шрифт OCR?
Спустя 58 лет мы подумали, что пришло время для нового и лучше выглядящего шрифта OCR.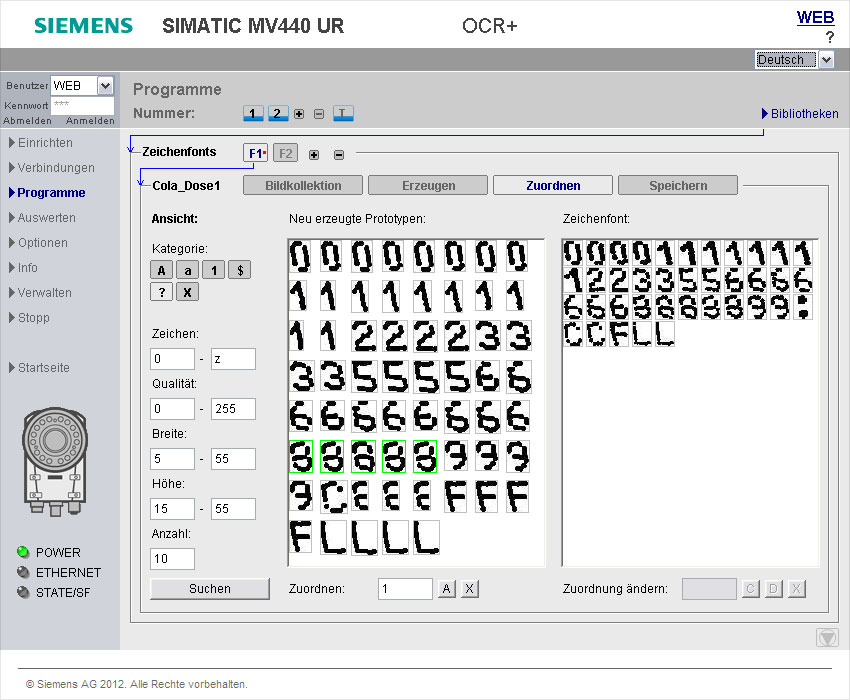 Вот почему мы разработали его сами. Даже если вы думаете, что шрифты OCR устарели, потому что почти каждый написанный компьютером шрифт читабелен, наличие специализированного шрифта все же дает ряд преимуществ.
Вот почему мы разработали его сами. Даже если вы думаете, что шрифты OCR устарели, потому что почти каждый написанный компьютером шрифт читабелен, наличие специализированного шрифта все же дает ряд преимуществ.
Судя по нашему опыту работы с различными отраслями промышленности, многие компании и учреждения по-прежнему используют OCR-A/B для спецификаций своей продукции.
Кроме того, как технологическая компания, специализирующаяся на машинном обучении и компьютерном зрении, мы любим поддерживать разработчиков и наше сообщество наилучшим образом.
Предлагая бесплатный и оптимизированный новый шрифт OCR, мы даем возможность большему количеству людей из сообщества, а также на коммерческом рынке работать с технологией OCR без необходимости тратить деньги на стоимость лицензии, в отличие от традиционных OCR-A и OCR-B. . Короче говоря, мы изменили игру.
Требования для AnyOCR
Дизайн Во-первых, мы действительно считаем, что Фрутигер был одним из лучших типографов. Но понимание дизайна изменилось за последние 60 лет. Мы хотели современный дизайн, что означало более легкую и мягкую форму.
Но понимание дизайна изменилось за последние 60 лет. Мы хотели современный дизайн, что означало более легкую и мягкую форму.
Даже если это просто номер на товаре, он имеет право хорошо выглядеть. В рамках этого изменения улучшилась читаемость как для машины, так и для человеческого глаза.
Наиболее важной целью было повышение точности и скорости сканирования для всех существующих программных решений. Это была самая сложная часть процесса, поскольку она зависела от множества аспектов.
Точность и скоростьКак специалисты по распознаванию текста, мы знаем, что символы, выровненные в виде сетки, гораздо легче обнаружить и отсканировать. Следовательно, кернинг AnyOCR выравнивается по идеальной сетке для оптимизации этого процесса.
Однако кернинг AnyOCR не оптимизирован для непрерывного текста. Но, как вы знаете, мы не ориентированы на сканирование длинных текстовых форматов, таких как длинные предложения, и поэтому работаем как идеальное решение.
Anyline SDK фокусируется на решениях для мобильного сканирования с улучшенным распознаванием текста, поэтому шрифт должен быть читаемым даже в условиях плохого освещения, а также справляться с отражениями и т. д.
С этим SDK не имеет значения, где вы находитесь и что вы сканируете, если вы используете наш шрифт OCR. Anyline предлагает вам лучший SDK для OCR и проект мобильного сканирования, особенно когда вы пользуетесь мощью AnyOCR.
Попробуйте наше демо-приложение
Нравится? Поделись.
ПОДПИСЫВАЙТЕСЬ НА НАС, ЧТИТЕ ПОСЛЕДНИЕ НОВОСТИ О МОБИЛЬНОМ СБОРЕ ДАННЫХ
Хотите быть в курсе всех новейших технологий мобильного сканирования? Подпишитесь на нас в Facebook, LinkedIn или Twitter, чтобы быть в курсе инноваций и разработок в области сбора мобильных данных, оптического распознавания символов и искусственного интеллекта.
Вы также можете присоединиться к нашему списку рассылки, чтобы получать все объявления Anyline прямо на свой почтовый ящик. Регистрация проста, и мы не отправляем слишком много писем.
Регистрация проста, и мы не отправляем слишком много писем.
Наконец, если у вас есть вопросы, предложения или отзывы об этом сообщении, не стесняйтесь обращаться к Anyline. Свяжитесь с нами через социальные сети, контактную форму или отправьте нам электронное письмо по адресу [email protected]
.Поделись этой историей!
Обучение шрифтам OCR
- Во FrontRunner щелкните Редактор .
- Выберите инструмент OCRTrainableFont.
- Нажмите Показать пользовательские свойства для этого шага (Рис. 9-27). Откроется пользовательский редактор, как показано на рис. 9-28. Пользовательский редактор используется для создания и обучения всех шрифтов.
РИСУНОК 9-27.
Показать пользовательские свойства для этой кнопки шага
РИСУНОК 9-28. Пользовательский редактор
- Свернуть редактор FrontRunner (не пользовательский редактор)
- В пользовательском редакторе щелкните Выберите шрифт , чтобы
выберите новый шрифт для обучения.

Отображается диалоговое окно «Диспетчер шрифтов», как показано на рисунке. на Рисунке 9-29.
РИСУНОК 9-29.
Диалоговое окно диспетчера шрифтов
- Щелкните Новый .
Отображается диалоговое окно «Новый шрифт», как показано на Рисунок 9-30.
РИСУНОК 9-30.
Диалоговое окно «Новый шрифт»
- Введите имя нового шрифта.
- Выберите начальный набор символов (символы могут быть удалены или добавлено позже).
- Нажмите OK , чтобы закрыть диалоговое окно «Новый шрифт». коробка.
Диспетчер шрифтов отображается снова.
- Выделите только что созданный шрифт и щелкните Выберите .
- Во FrontRunner щелкните Получить новый образ , чтобы захватить новое изображение.
Получение нового изображения очищает изображение от всех
наложение графики.
- Размер области интереса так, чтобы он полностью окружал символы, которые должны быть обучены, как показано на рис. 9.-31.
РИСУНОК 9-31.
Определение размера ROI
- В пользовательском редакторе введите символы для обучения текстовое поле «Текст или символы для включения» (Рис. 9-31).
Примечание. Не вводите пробелы.
На изображении на рис. 9-31, ROI полностью окружает символы «12345». Красные линии определение ROI не должно касаться символов, которые должны быть включены.
Флажок «Сохранить дело» принудительно устанавливает «Текст или Символ для включения» в верхний регистр, если шрифт состоит из символы верхнего регистра (ABC). Например, если вы наберете «klm», символы будут преобразованы в «KLM», когда вы нажмете кнопку «Включить». кнопка. Сохранение регистра также переводит символы в нижний регистр, если шрифт состоит из символов нижнего регистра (abc).
- Щелкните Включить .

Недавно добавленные символы будут выделены в синем. Символы остаются выделенными до тех пор, пока шрифт не будет обучен и сохранен. Последние включенные символы отображаются в строку состояния, как показано на рис. 9.-32
РИСУНОК 9-32.
Недавно добавленные символы выделены
- Если персонажи плохо тренируются, щелкните правой кнопкой мыши и выберите Отменить включение.
Чтобы отменить включение последнего набора символы, щелкните правой кнопкой мыши где-нибудь в диалоговом окне и выберите option Отменить Включить [символов] . Есть один уровень отмены.
Отмена доступна даже после удаления шрифта. обученный.
- Если найдено меньше символов, чем ожидалось, появится окно сообщения. появится, как показано на Рисунке 9-33. Измените размер ROI или внесите коррективы в инструмент OCRTF.
РИСУНОК 9-33.
Найдено меньше символов
- Если найдено больше символов, чем ожидалось, только найденные
символы включены.

- Повторите шаги 11–14, чтобы включить несколько образцов символов в шрифт.
Поскольку символы включены, графика появляется в изображение для каждого символа.
РИСУНОК 9-34.
Графика для каждого персонажа
- Нажмите Получить новое изображение , чтобы очистить изображение графика.
Пользовательский редактор обновлен, чтобы указать все включенные символы, как показано на рис. 9-35.
РИСУНОК 9-35.
Пользовательский редактор обновлен
- Нажмите Learn , чтобы обучить шрифт с помощью включены персонажи.
При желании вы можете прекратить тренировку.
Вы можете тренироваться в любое время, если включаете персонажи.
- После завершения обучения щелкните Сохранить шрифт или Восстановить , как показано на Рисунке 9-36.
Время, необходимое для обучения, увеличивается по мере увеличения
добавляются образцы. Время ожидания по умолчанию составляет 1 минуту; выберите короче
или более длительные периоды обучения из раскрывающегося списка Timeout.
Время ожидания по умолчанию составляет 1 минуту; выберите короче
или более длительные периоды обучения из раскрывающегося списка Timeout.
РИСУНОК 9-36. Нажмите
Сохранить шрифт
Щелчок Сохранить шрифт сохраняет новое обучение. Дата и время поезда отображаются под имя шрифта, как показано на рис. 9-37.
РИСУНОК 9-37.
Название шрифта и дата и время поезда
Щелчок Вернуть отменяет подготовка. Если шрифт был обучен ранее, он вернется в прежнее обученное состояние.
После обучения символы подсвечиваются с помощью красный, желтый и зеленый, чтобы указать количество обученных образцов для каждого персонажа.
РИСУНОК 9-38.
После тренировки
Когда указатель мыши находится над символом,
всплывающая подсказка с указанием количества обученных образцов для
персонаж. На изображении выше подсказка показывает, что 6 образцов
прошли обучение на персонажа «А».
- Слегка расфокусируйте объектив и повторите шаги 11–18.
Шрифт следует обучать, используя образцы, которые различаются по качеству. Когда доступно меньше образцов, чем требуется, набор образцов можно повторно использовать несколько раз во время обучения.
Чтобы повторно использовать набор символов после первого раунда обучения, слегка расфокусируйте объектив, чтобы персонажи немного нечетко. Если доступ к объективу затруднен, обработка изображения можно использовать для изменения внешнего вида персонажей.
Этот метод имитирует изменчивость, ожидаемую в большие выборочные наборы символов.
РИСУНОК 9-39.
Расфокусировка изображения
Другой альтернативой обработке изображений является корректировка данных Edge Energy для шага OCRTF. Изменение этого параметр аналогичен изменению фокуса для получения более резкого или мягкого изображения. края персонажей.
Использование шрифтов OCR A и OCR B для принтеров ASCII
В этом документе обсуждается использование шрифта OCR A и OCR B при печати на принтерах ASCII.
Использование шрифтов OCR A и OCR B для принтеров ASCII
Метод, используемый для печати шрифтов OCR A и OCR B на принтерах ASCII, зависит от возможностей принтера и от того, установлены ли в принтере шрифты или нет. . Чтобы определить, установлены ли шрифты, распечатайте список шрифтов на принтере и посмотрите в поле «Имя шрифта» или «Начертание шрифта», чтобы увидеть, есть ли они в списке. Обычно эти шрифты не устанавливаются в принтер и должны быть загружены в принтер из IBM® OS/400® или IBM® i5/OS®. Если шрифт установлен на принтере, запишите escape-последовательность или значение строки данных для шрифта, чтобы использовать его в следующем разделе этого документа. Если шрифт не установлен в принтер и не загружен в принтер, то выполняется подстановка шрифта. Идентификатор шрифта для OCR A — 19.а для OCR B равно 3. Обычно они сопоставляются со шрифтом Courier.
Если на принтере установлен шрифт
Для использования встроенного в принтер шрифта требуется объект настройки рабочей станции (WSCST). Этот WSCST сопоставляет идентификатор шрифта, используемый в буферном файле, с escape-последовательностью или значением строки данных для шрифта на принтере. Параметром в WSCST, который отображает эти значения, является тег :INDFNTE. Как правило, для шрифта OCR A используется идентификатор шрифта (FGID) FGID 19.а для шрифта OCR B — FGID 3, но можно использовать и другие номера.
Этот WSCST сопоставляет идентификатор шрифта, используемый в буферном файле, с escape-последовательностью или значением строки данных для шрифта на принтере. Параметром в WSCST, который отображает эти значения, является тег :INDFNTE. Как правило, для шрифта OCR A используется идентификатор шрифта (FGID) FGID 19.а для шрифта OCR B — FGID 3, но можно использовать и другие номера.
Для создания объекта WSCST см. следующие документы базы знаний Rochester Support Center:
N1010140: Инструкции по изменению объекта настройки рабочей станции (WSCST)
N1010138: Структура строк шрифта HP PCL5 16 a14:
N14 Особый шрифт (тег INDFNTE)
См. следующие документы базы знаний Rochester Support Center по использованию объекта WSCST:
N1010288: Использование преобразования печати хоста (HPT) с описанием устройства *LAN
N1019713: Использование преобразования печати хоста (HPT) с удаленной очередью вывода (RMTOUTQ)
N1019712: Использование преобразования печати хоста (HPT) с *LCL или *RMT Описание устройства
N1019470: Использование Host Print Transform (HPT) с сеансом принтера PC5250
N1019670: Использование Host Print Transform (HPT) со сторонним пакетом эмуляции
Идентификатор шрифта (FGID), настроенный для шрифта в WSCST, необходимо отправить в потоке данных для буферного файла. Это можно сделать в файле принтера с помощью команды «Изменить файл принтера» ( CHGPRTF ) или команды «Переопределить файл принтера» ( OVRPRTF ). Его также можно указать в приложении или программе CL или с помощью ключевого слова DDS FONT. Выбранный метод может иметь другие требования к типу используемого потока данных (например, *SCS или *AFPDS).
Это можно сделать в файле принтера с помощью команды «Изменить файл принтера» ( CHGPRTF ) или команды «Переопределить файл принтера» ( OVRPRTF ). Его также можно указать в приложении или программе CL или с помощью ключевого слова DDS FONT. Выбранный метод может иметь другие требования к типу используемого потока данных (например, *SCS или *AFPDS).
Если на принтере не установлен шрифт
Если шрифт не установлен на принтере, его необходимо загрузить из OS/400 или i5/OS на принтер. Принтер должен поддерживать загруженные шрифты. Эти шрифты бесплатно предоставляются вместе с системой как часть шрифтов совместимости IBM AFP (OS/400 или i5/OS, вариант продукта 8), но их необходимо сначала установить. Шрифты будут помещены в библиотеку QFNTCPL.
Примечание: Эти шрифты содержат только прописные буквы и цифры. Строчные буквы можно получить, купив коллекцию шрифтов AFP (5648-B45) и затем установив ее на OS/400 или i5/OS.
Буферный файл должен иметь тип устройства принтера *AFPDS. Шрифт можно указать в файле принтера, в приложении или программе CL или с помощью одного из ключевых слов DDS. Файл принтера можно изменить с помощью команды «Изменить файл принтера» ( CHGPRTF ), а также с помощью приложения или программы CL или с помощью команды «Заменить файл принтера» ().0516 OVRPRTF ). Параметр в файле принтера для указания шрифта — Coded Font. Указав шрифт в файле принтера, он будет использовать шрифт для всего буферного файла.
Шрифт можно указать в файле принтера, в приложении или программе CL или с помощью одного из ключевых слов DDS. Файл принтера можно изменить с помощью команды «Изменить файл принтера» ( CHGPRTF ), а также с помощью приложения или программы CL или с помощью команды «Заменить файл принтера» ().0516 OVRPRTF ). Параметр в файле принтера для указания шрифта — Coded Font. Указав шрифт в файле принтера, он будет использовать шрифт для всего буферного файла.
Если для использования шрифтов OCR A или OCR B предназначены только определенные поля, используйте ключевое слово DDS CDEFNT, чтобы указать шрифт. Другое ключевое слово DDS, которое также можно использовать, — FNTCHRSET. При использовании этого ключевого слова необходимо указать как набор символов шрифта, так и кодовую страницу. Имена наборов символов шрифта начинаются с буквы C, а кодовые страницы начинаются с буквы T. Ключевое слово DDS CDEFNT обычно предпочтительнее, поскольку имя закодированного шрифта указывает как набор символов шрифта, так и кодовую страницу, что немного упрощает использовать.
Кодированные имена шрифтов для OCR A: X0AOD, X0AOA и X0AON. Кодированные имена шрифтов для OCR B: X0BOA и X0BON. (За буквой X следует цифра ноль, затем за буквой A или B следует буква O, за которой следует буква D, A или N.) Наборы символов шрифта для OCR A: C0L00aoa, C0L00aon и C0ocra10. Наборы символов шрифта для OCR B: C0L00boa, C0L00bon, C0L00oab и C0ocra10. Примером использования ключевого слова DDS закодированного шрифта для шрифта OCR A является: CDEFNT(QFNTCPL/X0AOA).
Принтер должен быть настроен с параметром Host Print Transform, установленным на *yes, с соответствующим типом производителя и моделью принтера. Если выходные данные печатаются неправильно, может потребоваться объект настройки рабочей станции (WSCST) для включения растрового режима. Поскольку шрифт будет растеризован, убедитесь, что плотность пикселей указанного объекта шрифта соответствует плотности пикселей принтера.
Команда Показать атрибут ресурса шрифта ( DSPFNTRSCA ) или Опция 5 (Отображать атрибуты) из раздела Работа с ресурсами шрифта ( WRKFNTRSC ), покажет плотность пикселей набора символов шрифта (FNTCHRSET). С кодовой страницей (CDEPAG) не связана плотность пикселей. Чтобы найти плотность пикселей для кодированного шрифта (CDEFNT), сначала просмотрите текстовое описание этого кодированного шрифта, чтобы увидеть, какой набор символов шрифта связан с этим кодированным шрифтом, а затем отобразите атрибуты этого набора символов шрифта, чтобы увидеть плотность пикселей. . Обратите внимание, что контурные или масштабируемые наборы символов шрифта будут иметь «OUTLINE» в списке для плотности пикселей.
С кодовой страницей (CDEPAG) не связана плотность пикселей. Чтобы найти плотность пикселей для кодированного шрифта (CDEFNT), сначала просмотрите текстовое описание этого кодированного шрифта, чтобы увидеть, какой набор символов шрифта связан с этим кодированным шрифтом, а затем отобразите атрибуты этого набора символов шрифта, чтобы увидеть плотность пикселей. . Обратите внимание, что контурные или масштабируемые наборы символов шрифта будут иметь «OUTLINE» в списке для плотности пикселей.
Примечание: Этот параметр не будет печатать так быстро, как если бы шрифт был встроен в принтер.
Для получения дополнительной информации обратитесь к следующим документам базы знаний Rochester Support Center, а также см. документы в предыдущем разделе об изменении WSCST и использовании HPT:
N1010127: Raster Imaging for Host Print Transform (HPT)
N1019670: Использование Host Print Transform (HPT) со сторонним пакетом эмуляции
- Использование шрифтов OCR с Transform Services
Transform Services — это безлицензионный продукт, который можно использовать для создания формата Adobe Acrobat PDF в системе IBM i или i5/OS.

Продукт Transform Services (5761TS1), впервые появившийся в версии 6.1 i5/OS, можно использовать для прямого создания файлов PDF в виде потоков в интегрированной файловой системе (IFS). Дополнительные сведения о службах преобразования см. в следующем документе:
N1018568: Использование служб преобразования для создания файлов потока PDF вместо буферных файлов
6.1 Transform Services (продукт 5761TS1) не имеет возможности встраивать шрифты и поэтому ограничен описанием характеристик шрифта. It is therefore limited to the 14 Standard Type 1 fonts:
o Times Roman o Times Bold o Times Italic o Times Bold/Italic или Гельветика o Helvetica Bold o Helvetica Oblique o Helvetica Bold/Oblique o Courier o Courier Bold o Courier Boulique O Courier Boldoblique O Символ O Zapfddingbtbtbsbtbsbtbbsbtbbsbtbbsbtbsb0110 Шрифты Adobe Standard Type 1 не включают шрифты OCR A и OCR B, а службы Transform 6.
 1 могут сопоставляться только со шрифтами Standard Type 1, поэтому файлы PDF, созданные с помощью служб Transform 6.1, не могут включать шрифты OCR.
1 могут сопоставляться только со шрифтами Standard Type 1, поэтому файлы PDF, созданные с помощью служб Transform 6.1, не могут включать шрифты OCR.7.1 Transform Services (продукт 5770TS1) добавлена возможность встраивания шрифтов, включая наборы символов резидентных шрифтов и закодированные шрифты. Это обеспечивает лучшую поддержку шрифтов, в том числе поддержку шрифтов с перевернутыми изображениями, но может увеличить размер итогового PDF-файла, поскольку каждый упомянутый шрифт должен быть встроен в сам PDF-файл.
7.1 Transform Services имеет встроенную поддержку для создания потоковых файлов PDF со встроенными шрифтами OCR с использованием ключевого слова Font (FONT) DDS, например FONT(19) для OCR A или FONT(3) для OCR B, но только если файл принтера создан с параметром Идентификатор символа (CHRID), установленным в CHRID(968 892).
7.1 Transform Services также может использовать шрифт OCR A или OCR B, установленный в системе IBM i, без указания CHRID(968 892) в файле принтера, точно так же, как Host Print Transform (HPT) может делать при печати на ASCII лазерный принтер, который не имеет резидентного или «встроенного» шрифта OCR.
 Например, если установлены шрифты, совместимые с AFP (продукт 57xxSS1, вариант 8), то вы можете использовать ключевое слово Coded Font (CDEFNT) DDS с кодированными шрифтами QFNTCPL/X0AOD, QFNTCPL/X0AOA или QFNTCPL/X0AON для OCR A или Кодированные шрифты QFNTCPLF/X0BOA или QFNTCPL/X0BON для OCR B.
Например, если установлены шрифты, совместимые с AFP (продукт 57xxSS1, вариант 8), то вы можете использовать ключевое слово Coded Font (CDEFNT) DDS с кодированными шрифтами QFNTCPL/X0AOD, QFNTCPL/X0AOA или QFNTCPL/X0AON для OCR A или Кодированные шрифты QFNTCPLF/X0BOA или QFNTCPL/X0BON для OCR B.
- Дополнительные ссылки
Справочник по OS/400 DDS V4R4 (SC41-5712-03)
Справочник по DDS: Руководство по файлам принтера в разделе Данные и файловые системы > IBM® DB2® Universal Database™ for iSeries®, часть iSeries Information Center, на следующем веб-сайте:
http://publib.boulder.ibm.com/pubs/html/as400/infocenter.htm
OS/400 Printer Device Programming Версия 4 (SC41-5713-03), на следующем веб-сайте:
http://publib.boulder.ibm.com/pubs/pdfs/as400/V4R4PDF/QB3AUJ03.PDFOS/400 Printer Device Programming Version 5 (SC41-5713-04) на следующем веб-сайте:
http://publib.
 boulder.ibm.com/pubs/html/as400/v5r1/ic2924/books/c4157134.pdf
boulder.ibm.com/pubs/html/as400/v5r1/ic2924/books/c4157134.pdf Программа настройки рабочей станции OS/400 V4R3 (SC41-5605) на следующем веб-сайте:
http://publib.boulder.ibm.com/pubs/pdfs/as400/V4R3PDF/QB3AQ600.PDF
[{«Тип»:»МАСТЕР»,»Направление деятельности»:{«код»:»LOB57″,»метка»:»Мощность»},»Бизнес-подразделение»:{«код»:»BU058″ ,»label»:»IBM Infrastructure w\/TPS»},»Product»:{«code»:»SWG60″,»label»:»IBM i»},»Platform»:[{«code»:»PF012 «,»label»:»IBM i»}],»Version»:»6.1.0″}]
OCR History: The Original Machine Learning
Сегодня в скуке: Мы живем в мире, где распознавание лиц стали настолько изощренными, что мы вынуждены задавать очень серьезные этические вопросы по этому поводу. (В США глубина возможностей ФБР по распознаванию лиц вызывает серьезные вопросы у Конгресса. В Китае они используются для обнаружения кражи туалетной бумаги. В каждой стране свои.) Но я хочу сделать шаг назад от большие этические вопросы и подумайте, как мы начали этот путь — с типографики. Оптическое распознавание символов, или OCR, — это технология, пришедшая с вычислительной техникой в целом. Во многих смыслах это все еще похоже на волшебство, хотя это проблема, которую мы давно решили. Сегодняшний Tedium рассказывает свою историю. — Ernie @ Tedium
Оптическое распознавание символов, или OCR, — это технология, пришедшая с вычислительной техникой в целом. Во многих смыслах это все еще похоже на волшебство, хотя это проблема, которую мы давно решили. Сегодняшний Tedium рассказывает свою историю. — Ernie @ Tedium
1954
Год, когда первая коммерческая машина для оптического распознавания символов была установлена в бизнесе — кстати, в офисе «Ридерз Дайджест», хотя она не использовалась для книг. В то время широкое использование OCR рассматривалось как автоматизация бизнес-задач, и в случае Reader’s Digest технология использовалась для управления данными о продажах подписчиков и преобразования этих данных в формат перфокарты. На этом раннем этапе технология поддерживала только символы определенного шрифта.
Шрифт OCR-A, выставленный в Музее современного искусства. (Eric Fischer/Flickr)
Как трудности, связанные с созданием машиночитаемых шрифтов, повлияли на типографику
American Type Founders, трест 23 различных литейных компаний, определявших типографику в США на протяжении десятилетий, имеет множество шрифтов под своим именем, многие из них невероятно хорошо известны и высокого качества. Франклин Готика, школьный учебник века? Оба они принадлежат типографам ATF. (Мы упустим из виду тот факт, что литейный цех отвечает за Hobo.)
Франклин Готика, школьный учебник века? Оба они принадлежат типографам ATF. (Мы упустим из виду тот факт, что литейный цех отвечает за Hobo.)
Но только один из его шрифтов имеет место в коллекции Музея современного искусства, и это шрифт OCR-A, шрифт, созданный в 1966 году для очень специфической аудитории: машин.
И машины того времени не имели возможности различать шрифты, поэтому такой шрифт был необходим. Как поясняется в документе 1999 года «Оптическое распознавание символов: иллюстрированный путеводитель по границе »:
Многие из используемых сегодня шрифтов получены из средневековой каллиграфии, лишь слегка измененные ограничениями ранних технологий печати (деревянные блоки и подвижный шрифт). . Чтобы имитировать тонкий почерк, вертикальные штрихи толще горизонтальных штрихов, а диагонали СЗ-ЮВ толще, чем диагонали СВ-ЮЗ. Поэтому изогнутые штрихи могут различаться по ширине в зависимости от их локальной ориентации. Напротив, шрифты, специально разработанные для точного распознавания текста, такие как шрифты OCR-A и OCR-B, имеют одинаковую ширину штриха и преувеличенные различия между похожими символами, такими как Ο и 0 или 1 и l.

OCR-A был не первым шрифтом, решившим эти проблемы машинного сканирования, но это был большой шаг вперед, поскольку это был полный алфавит, понятный как машинам, так и людям. Раньше наиболее известным применением такой технологии было то, с чем вы, вероятно, знакомы, если обналичивали чек где-то за последние 60 лет: распознавание символов с помощью магнитных чернил или MICR.
Образец шрифта E-13B, как показано в патентной заявке 1995 года. (Патенты Google)
Разработанные в 1950-х годах банковской индустрией, шрифты — их два, которые используются исключительно друг для друга в разных странах — состоят из цифр 0–9 и нескольких специальных кодов, предназначенных специально для связи с компьютерами. . Если вы находитесь в Северной Америке или Великобритании, вы, вероятно, видели E-13B, в котором используются уникальные формы для каждого отдельного персонажа. Если вы живете во Франции, Испании или Южной Америке, возможно, вам больше знаком шрифт CMC-7, который включает в числа белые тире. Чернила также имеют магнитный заряд, чтобы сканеры искали числа.
Чернила также имеют магнитный заряд, чтобы сканеры искали числа.
Кредитная карта, номер которой указан шрифтом Farrington B. Вы имеете в виду, что у вас тоже? (Эд Иванушкин/Flickr)
Другим примечательным шрифтом такого рода является Farrington B, числовой шрифт, придуманный одним из первых разработчиков OCR Дэвидом Х. Шепардом, который до сих пор повсеместно используется на кредитных и дебетовых картах.
(Эти шрифты, примечание сбоку, напрямую вдохновили другие очень блочные шрифты, такие как тот, который использовался в логотипе журнала Byte , что напрямую привело к тому, что дизайн с толстыми закругленными штрихами был тесно связан с ранними вычислениями.)
OCR-A, который вы могли видеть в одной или двух нежелательных почтовых рассылках за последние годы, расширил основную идею MICR, создав набор символов, который мог быть обнаружен либо компьютером, либо парой глаз. Проблема, однако, заключалась в том, что он лучше подходил для компьютеров и имел сильно стилизованный дизайн, который некоторые сочли не очень привлекательным.
«В результате получился шрифт, в котором засечки смешаны с символами без засечек, произвольно смещены его оси и внутренняя симметрия, и его легко распознать по его острой угловатости», — объяснил доцент Вашингтонского университета Зак Уэлен в эссе о шрифте. . «В этом отношении OCR-A — уродливый шрифт, но, конечно, это уродство — человеческое соображение — делает его менее «невидимым», чем, скажем, Helvetica, таким образом, что связывает его техническую функцию с его использованием в графическом дизайне. ”
Это привело ко второй попытке решить проблему швейцарского типографа Адриана Фрутигера, выпущенной в 1968 году.
Образец типа OCR-B. (Identifont)
Европейская ассоциация производителей компьютеров (ECMA) поручила компании Frutiger решить эту проблему, которая считала, что OCR-A не был создан для людей. В статье в блоге Linotype покойный типограф, умерший в 2015 году, вспомнил, что у него было некоторое преимущество, поскольку технология распознавания текста значительно улучшилась, и он смог улавливать более мелкие детали. В результате OCR-B выглядит гораздо ближе по дизайну к стандартному европейскому шрифту, чем когда-либо более стилизованный вид OCR-A.
В результате OCR-B выглядит гораздо ближе по дизайну к стандартному европейскому шрифту, чем когда-либо более стилизованный вид OCR-A.
Не то чтобы это было легко — Фрутигер отмечает, что, например, было непросто убедиться, что символы «8» и «B» читаются как уникальные символы.
Плодом работы Frutiger стало то, что в конечном итоге Международная организация по стандартизации (ISO) приняла его в качестве глобального стандарта, в то время как OCR-A пришлось довольствоваться стандартизацией Американского национального института стандартов.
В этих шрифтах больше нет технической необходимости — начиная с 1970-х годов широкое распространение получили многошрифтовые решения для оптического распознавания текста, — но они по-прежнему используются практически повсеместно.
«В самолете мне довелось сидеть рядом со слепым джентльменом, и он объяснил мне, что единственным реальным недостатком, с которым он столкнулся, была его неспособность читать обычные печатные материалы.
 Было ясно, что его инвалидность по зрению не мешала ни в общении, ни в путешествии. Так что я нашел проблему, которую мы искали».
Было ясно, что его инвалидность по зрению не мешала ни в общении, ни в путешествии. Так что я нашел проблему, которую мы искали».— Технолог Рэй Курцвейл, , описывает случайную встречу, которая дала цель проекту, над которым он работал в то время. Это побудило Курцвейла построить технологию своей компании вокруг этого конкретного варианта использования, в результате чего появилась машина для чтения Курцвейла. Устройство могло сканировать заданную страницу, анализировать текст на странице и декламировать их человеку, который хотел прочитать страницу. Это был определенный шаг вперед по сравнению с виниловыми книгами, и он помог вызвать интерес к технологии OCR в середине 19-го века.70-е годы.
Край чтения Курцвейла. (через Американскую федерацию слепых)
Пять ключевых моментов в эволюции оптического распознавания символов
- В 1952 году бывший сотрудник Агентства национальной безопасности Дэвид Х.
 Шепард основал компанию Intelligent Machines Research Corporation, чтобы помочь продукт, который мог читать. «Мы построили его на моем чердаке, — сказал он Ассошиэйтед Пресс в 1954 году.
Шепард основал компанию Intelligent Machines Research Corporation, чтобы помочь продукт, который мог читать. «Мы построили его на моем чердаке, — сказал он Ассошиэйтед Пресс в 1954 году. - Также в 1950-е годы, Джейкоб Рабинов, сотрудник Национального института стандартов и технологий, построил собственную считывающую машину, основанную на подходе, называемом «наилучшее совпадение», который обнаруживал букву, сравнивая ее с каждым символом в алфавите. и предложение ответа. «Это позволило нам читать очень плохую печать, которую нельзя было прочитать никакими другими средствами», — вспоминал Рабинов. Он мог читать только один символ в минуту, но вскоре стал намного лучше.
- В 1965 году Почтовая служба США, , который (с 1957 года) использовал сортировочную машину, построенную Рабиновым, установил машину OCR в почтовом отделении Детройта. Устройства, согласно видеоролику почтового отделения 1970 года, должны считывать со скоростью 42 000 адресов в час.

- В 1980 году Рэй Курцвейл () продал свою компанию Kurzweil Computer Products компании Xerox, которая в дальнейшем усовершенствовала его технологию, сделав ее полезной для делового мира. Базовая компания, позже проданная Xerox, существует и по сей день под названием Nuance.
- В начале 1990-х годов ручные сканеры , которые полагались на осторожное движение со стороны пользователя, стали очень популярными среди пользователей компьютеров, продающихся сотнями тысяч единиц в год. Эти продукты, популярные среди настольных издательских систем, получили дальнейшее распространение после того, как стандарт TWAIN помог обеспечить согласованность на рынке сканеров. В конце концов, планшетные сканеры, предлагающие лучшее качество и стабильность, захватили рынок.
девять
Количество секунд , которое требуется среднему человеку для решения CAPTCHA, по словам Луиса фон Ана, одного из создателей технологии, которая была создана в Университете Карнеги-Меллона, чтобы эффективно превратить недостатки OCR в форму безопасности. . (Вон Ан сейчас является генеральным директором DuoLingo, службы языкового обучения.) Технология, купленная Google в 2009 году, в конечном итоге стала своего рода отказоустойчивой для собственных потребностей Google в распознавании символов для таких вещей, как Google Books и Street View. Однако Google недавно объявил, что полностью отказывается от CAPTCHA, вместо этого используя методы автоматического обнаружения.
. (Вон Ан сейчас является генеральным директором DuoLingo, службы языкового обучения.) Технология, купленная Google в 2009 году, в конечном итоге стала своего рода отказоустойчивой для собственных потребностей Google в распознавании символов для таких вещей, как Google Books и Street View. Однако Google недавно объявил, что полностью отказывается от CAPTCHA, вместо этого используя методы автоматического обнаружения.
В наши дни OCR гораздо более эффективен , чем когда он только появился — мы делаем это на телефонах и в Интернете в эти дни. Тем не менее, всегда есть способы улучшить процесс. В том числе, конечно, через типографику.
В прошлом году компания Anyline, продающая набор для разработки программного обеспечения для оптического распознавания символов на мобильных устройствах, решила нанести новый удар по шрифту оптического распознавания символов, пытаясь обновить его для современных условий.
Шрифт AnyOCR.
«Спустя 58 лет мы подумали, что пришло время для нового и лучше выглядящего шрифта OCR.
