Как проверить площадь текста на изображении для прохождения модерации? — блог Aitarget One
Если объявление не проходит модерацию из-за креатива, проверьте площадь текста на изображении. Но как это сделать, если привычные инструменты оказались недоступны в России? Давайте разбираться.
Требования к изображениям
С 23 мая ВКонтакте обновила требования к рекламе: теперь текст должен занимать не более 20%.
Подобные требования есть и в других рекламных системах. Например, в myTarget модерацию не пройдут изображения, на которых более 50% текста, в Яндекс Директе ограничение — 20%.
Объясняются такие требования исследованиями площадок. В справке Яндекса сказано, что у объявлений с крупными водяными знаками, логотипами и большим объёмом текста CTR ниже на 10%.
Помогаем быстрее пройти модерацию ВКонтакте
У Aitarget One прямая линия связи с техподдержкой VK, мы передаем туда все вопросы напрямую. Ответ и помощь можно получить в течение нескольких минут, а не ждать на «общей линии».
Подключайтесь к Aitarget One и обращайтесь со спорными вопросами в нашу поддержку — мы поможем разобраться и быстрее запустить рекламу!
Подключиться
Как определить площадь текста на креативе?
В июне 2022 появился новый и, что самое приятное, бесплатный инструмент для проверки площади текста на креативе — robbi.ai. С помощью Робби, искусственного интеллекта, который обрабатывает контент, можно узнать, сколько места занимает текст.
Как работать с инструментом robbi.ai?- Перейдите по ссылке robbi.ai и пролистайте страницу вниз либо нажмите кнопку «Попробовать».
- Выберите инструмент «Площадь текста на фото» и загрузите рекламный креатив.
- Через несколько секунд система покажет вам результат. Если он больше 20%, креатив может не пройти модерацию. Необходимо сократить текст.
Помимо данных инструмента, ориентироваться нужно на соответствие правилам VK.
Аудит вашей рекламы в VK
- Проверим аккаунт и рекламные кампании.
- Подскажем, что замедляет открутку и как улучшить результаты.
- Поможем настроить первую кампанию, если вы только начинаете работу с площадкой.
Бесплатно для всех клиентов Aitarget One. Напишите кодовое слово Ревью в чат на сайте или группу VK — мы свяжемся с вами в течение рабочего дня.
Как сделать креатив, который пройдет модерацию: советы
- Обычно модераторы не учитывают текст на водяных знаках, логотипах, дисклеймерах. Например, если на изображении присутствует текстовый логотип, но сам рекламный слоган занимает мало места, проблемы с модерацией вряд ли возникнут.
 Также вряд ли будет учитываться текст на книгах, экранах устройств, одежде, если они являются элементами дизайна и не занимают всю площадь изображения.
Также вряд ли будет учитываться текст на книгах, экранах устройств, одежде, если они являются элементами дизайна и не занимают всю площадь изображения.
- Не разбрасывайте части текста по всей картинке, сгруппируйте его в одном месте.
- Используйте как можно меньше слов в тексте. Лучше отказаться от деталей и разместить на картинке только CTA или самую важную информацию — сроки акции, размер скидки, новую цену.
- Уменьшайте размер шрифта, но так, чтобы он оставался читабельным (до 12 px).
- Если очень важно донести много информации (например, рассказать все условия участия в конкурсе, подчеркнуть несколько преимуществ продукта), используйте формат карусели. Маленький лайфхак: добавляйте внизу изображений ленту прокрутки или подсчет, чтобы пользователю хотелось долистать галерею до конца.
- Не нарушайте другие требования к рекламе — не используйте капс, разрядку, заборчик и обилие восклицательных и вопросительных знаков — всё то, что так не любят системы модерации.

Читайте также: подробная статья обо всех правилах модерации ВКонтакте «Модерация рекламы ВКонтакте: как проверяют вашу рекламу» (обновлена в мае 2022 с учетом всех нововведений).
Смотрите также: вебинар Aitarget One и ВКонтакте. Записан летом 2021 года, но рекомендации по-прежнему актуальны, многие требования не изменились.
Данные успешно отправлены!
Поле заполнено не верно!
Как распознать и перевести текст по фото онлайн — 19 октября 2021
Редакция Sport24
Поделиться
Комментарии
Инструкция.
Распознавание текста по фото — это процесс перевода графического изображения символов (букв) в текстовые символы. Сделать это можно имея качественную цифровую копию оригинального текста и набор современных компьютерных программ для распознавания текста. Если вам необходимо перевести текст с фотографии на другой язык, то необязательно перепечатывать его в окно переводчика.
Как распознать и перевести текст по фото с ПК
Яндекс.Переводчик
Популярный в России способ — это переводчик от Яндекса. сервис, который умеет распознавать текст с изображения и затем переводить его на любой из множества языков. Пользоваться им можно бесплатно. Открыть можно на ПК по ссылке. Перевод по картинке осуществляется простым способом через переход на соответствующий раздел и выбор необходимого языка. Перевод текста по фото можно осуществлять по файлам следующих форматов: JPG, PNG, GIF, BMP, TIFF.
Соответственно можно сформулировать простую и ясную инструкцию как распознать текст с картинки:
- Переход на сайт Яндекс.
 Переводчика
Переводчика - Переключить его в режим «Картинка»
- Переащить изображение в окно браузера или выбрать файл через проводник.
- Выбрать языки.
Отличительной особенностью Яндекс.Переводчика также является автоматическое определение языка источника по картинке. Даже такая приятная мелочь может ускорить работу и облегчить восприятие переводчика онлайн по фото. Также можно увеличивать и уменьшать изображение, чтобы сфокусироваться на его отдельных частях при возможном использовании мелкого шрифта. После подготовки изображения останется кликнуть по кнопке «Открыть в переводчике», после чего появится новая вкладка с привычным интерфейсом. Слева будет исходный текст, а справа его перевод.
Яндекс.Переводчик — это удобный переводчик онлайн по фото, но не единственный доступный к использованию. Если результат его работы чем-то не устрооил, всегда можно попробовать и другие сервисы.
img2txt
img2txt — это сервис, который позволяет получить набранный текст из изображения путем оптического распознавания символов (OCR) и Вам не требуется устанавливать дополнительные программы на свой компьютер или смартфон. Для распознавания текста необходимо подготовить нужное изображение и загрузить его, далее следует выбрать язык на котором написан текст, после чего Вы получите результат.
Для распознавания текста необходимо подготовить нужное изображение и загрузить его, далее следует выбрать язык на котором написан текст, после чего Вы получите результат.
Текст с картинки в текст онлайн можно перевести за достаточно быстрое время и к тому же появится возможность сохранить результат перевода в удобный формат. Перевести по фото можно типовые форматы файлов-изображений: jpg, jpeg, png. Также поддерживаются и мульти-страничные документы pdf, что для многих может оказаться очень важной возможностью. Онлайн переводчик по фото работает довольно быстро и выдает результат в удобном для последующей обработке виде.
Free Online OCR
Free Online OCR — еще один популярный онлайн переводчик по фото. Функция перевода в этом сервисе реализована через сервис Google Translate. Главное достоинство сервиса — поддержка большого количества графических форматов. Загрузить на перевод по фотографии можно практически любую картинку одного из форматов: JPEG, JFIF, PNG, GIF, BMP, PBM, PGM, PPM, PCX. Вот только язык на картинке сервис может автоматически не определить, а потому придется его указать вручную.
Вот только язык на картинке сервис может автоматически не определить, а потому придется его указать вручную.
Таким образом, перевод по фото онлайн в данном сервисе можно осуществить довольно просто, следуя такому порядку действий:
- На главной странице сервиса нажать «Выберите файл».
- Через проводки указать файл с изображением.
- Нажать «Preview» и дождаться результата обработки.
- Нажать «OCR», чтобы получить из картинки текст.
Далее получившийся текст можно при необходимости подправить вручную и также воспользоваться кнопкой «Google Translate» для перевода.
iOS и Android приложения для перевода текста по фото
Большинство приложений, позволяющих осуществить распознавание текста по фото качественно реализованы одновременно и для iOS, и для Android устройств, потому имеет смысл рассматривать их вместе.
Google Translate
Google Translate — самое популярное приложение для перевода на Android. Среди его возможностей есть и функция распознавания текста с фотографий и любых других изображений. Распознавание текста с картинки можно осуществлять прямо в интерфейсе камеры. Чтобы понять, что написано на вывеске или в меню не нужно даже делать снимок — главное, чтобы было подключение к интернету.
Распознавание текста с картинки можно осуществлять прямо в интерфейсе камеры. Чтобы понять, что написано на вывеске или в меню не нужно даже делать снимок — главное, чтобы было подключение к интернету.
Можно распознать скриншот с текстом, запустить переводчик по картинке, выбирая изображение из памяти телефона. Запустить переводчик через камеру можно также нажатием на значок с камерой. После этого выбрать язык с которого осуществить перевод и язык на который нужно перевести. Затем навести объектив на текст и дождаться появления перевода на экране прямо поверх изображения.
Есть и другие возможности у Google Translate, которые могут вам пригодиться: поддержка более 100 языков для перевода, режим разговора с озвучиванием перевода, рукописный и голосовой ввод, разговорник для сохранения слов на разных языках.
Google Translate iOS
Google Translate Android
Microsoft Translator
Компания Microsoft также старается не отставать от конкурентов и позаботилась об удостве своих пользователей, добавив функционал распознавания текста с фотографий в свой переводчик, который поддерживает уже более 60 языков.
Для перевода текста с изображения достаточно придерживаться простого алгоритма действий:
- Нажать на значок камеры
- Выбрать языки оригинала и результата перевода
- Навести камеру на нужный текст и сфотографировать его.
- Дождаться завершения обработки.
Кроме новых фото, можно преобразовать старую картинка в текст, воспользовавшись выбором изображения из памяти телефона. Среди другиз возможностей программы также присутсвтуют режим разговора с синхронным переводом речи и режим многопользовательского общения (до 100 собеседников на разных языках). Переводчи от Microsoft пока не славится такой же эффективность, как от Google, но для простых задач пользоваться им уже вполне можно.
Microsoft Translator iOS
Microsoft Translator Android
Translate.ru
Приложение Translate.ru от PROMT имеет важное преимущество над конкурентами, оно может переводить текст из фото, осуществлять перевод по фото с английского на русский без подключения к интернету. Правда, для работы такой функции нужно предварительно скачать языковой пакет OCR. Выбирать следует тот язык, с которого вы планируете переводить.
Правда, для работы такой функции нужно предварительно скачать языковой пакет OCR. Выбирать следует тот язык, с которого вы планируете переводить.
Для работы с приложением достаточно придерживаться простого алгоритма действий:
- Выбрать значок камеры в главном окне приложения.
- Нажать Ок при появлении собщения об отсутсвии пакетов для распознавания текста.
- Выбрать язык с которого нужно переводить и установить пакет при наличии интернета.
Далее можно уже наводить камеру на нужный текст, фотографировать и ожидать результата распознавания текста. Как и в других приожениях тут поддерживается возможность перевести текст с фото сохраненного в галерее мобильного устройства. Также есть функции голосового и рукописного ввода, отображения транскрипции и воспроизведение оригинала текста носителем языка, режим диалога для общения собеседников на разных языках.
Translate.ru iOS
Translate.ru Android
CLIP: Соединение текста и изображений
Мы представляем нейронную сеть под названием CLIP, которая эффективно изучает визуальные концепции на основе наблюдения за естественным языком. CLIP можно применить к любому эталону визуальной классификации, просто указав имена визуальных категорий, которые необходимо распознать, аналогично возможностям «нулевого выстрела» GPT-2 и GPT-3.
CLIP можно применить к любому эталону визуальной классификации, просто указав имена визуальных категорий, которые необходимо распознать, аналогично возможностям «нулевого выстрела» GPT-2 и GPT-3.
Хотя глубокое обучение произвело революцию в компьютерном зрении, у современных подходов есть несколько серьезных проблем: типичные наборы данных о зрении трудоемки и дорогостоящи для создания при обучении только узкому набору визуальных понятий; стандартные модели зрения хорошо справляются с одной задачей и только с одной задачей и требуют значительных усилий для адаптации к новой задаче; и модели, которые хорошо работают в тестах, имеют разочаровывающе низкую производительность в стресс-тестах, что ставит под сомнение весь подход глубокого обучения к компьютерному зрению.
Мы представляем нейронную сеть, которая призвана решить эти проблемы: она обучается на самых разных изображениях с широким спектром контроля естественного языка, которые в изобилии доступны в Интернете. По своему замыслу сеть может быть проинструктирована на естественном языке для выполнения большого количества тестов классификации без прямой оптимизации производительности теста, аналогично возможностям «нулевого выстрела» GPT-2 и GPT-3. Это ключевое изменение: не проводя прямую оптимизацию для эталонного теста, мы показываем, что он становится гораздо более репрезентативным: наша система сокращает этот «разрыв в надежности» до 75%, при этом достигая производительности оригинального ResNet-50 на ImageNet Zero- снят без использования каких-либо оригинальных образцов с маркировкой 1.28M.
По своему замыслу сеть может быть проинструктирована на естественном языке для выполнения большого количества тестов классификации без прямой оптимизации производительности теста, аналогично возможностям «нулевого выстрела» GPT-2 и GPT-3. Это ключевое изменение: не проводя прямую оптимизацию для эталонного теста, мы показываем, что он становится гораздо более репрезентативным: наша система сокращает этот «разрыв в надежности» до 75%, при этом достигая производительности оригинального ResNet-50 на ImageNet Zero- снят без использования каких-либо оригинальных образцов с маркировкой 1.28M.
Хотя обе модели имеют одинаковую точность на тестовом наборе ImageNet, производительность CLIP гораздо более репрезентативна для наборов данных, которые измеряют точность в других настройках, не относящихся к ImageNet. Например, ObjectNet проверяет способность модели распознавать объекты в разных позах и с разным фоном внутри дома, в то время как ImageNet Rendition и ImageNet Sketch проверяют способность модели распознавать более абстрактные изображения объектов.
ЗАЖИМ ( Contrastive Language–Image Pre-training ) основан на большом объеме работы по переносу нулевого выстрела, контролю естественного языка и мультимодальному обучению. Идея обучения с нулевыми данными возникла более десяти лет назад, но до недавнего времени в основном изучалась в области компьютерного зрения как способ обобщения невидимых категорий объектов. Важным открытием было использование естественного языка в качестве гибкого пространства предсказаний, позволяющего обобщать и передавать данные. В 2013 году Ричер Сочер и его соавторы из Стэнфорда разработали доказательство концепции, обучив модель на CIFAR-10 делать прогнозы в пространстве встраивания векторов слов, и показали, что эта модель может предсказывать два невидимых класса. В том же году DeVISE расширил этот подход и продемонстрировал, что можно точно настроить модель ImageNet, чтобы она могла обобщаться для правильного прогнозирования объектов за пределами исходного обучающего набора из 1000.
Наибольшее вдохновение для CLIP послужила работа Анга Ли и его соавторов из FAIR, которые в 2016 году продемонстрировали использование контроля над естественным языком для обеспечения нулевой передачи в несколько существующих наборов данных классификации компьютерного зрения, таких как канонический набор данных ImageNet. Они достигли этого, настроив ImageNet CNN для предсказания гораздо более широкого набора визуальных понятий (визуальных n-грамм) из текста заголовков, описаний и тегов 30 миллионов фотографий Flickr, и смогли достичь точности 11,5% на ImageNet. нулевой выстрел.
Они достигли этого, настроив ImageNet CNN для предсказания гораздо более широкого набора визуальных понятий (визуальных n-грамм) из текста заголовков, описаний и тегов 30 миллионов фотографий Flickr, и смогли достичь точности 11,5% на ImageNet. нулевой выстрел.
Наконец, CLIP является частью группы статей, посвященных изучению визуальных представлений с помощью контроля естественного языка, опубликованных в прошлом году. Это направление работы использует более современные архитектуры, такие как Transformer, и включает в себя VirTex, который исследовал авторегрессивное языковое моделирование, ICMLM, который исследовал моделирование маскированного языка, и ConVIRT, который изучал ту же цель сравнения, которую мы используем для CLIP, но в области медицинской визуализации.
Подход
Мы показываем, что масштабирования простой задачи предварительного обучения достаточно для достижения конкурентоспособной нулевой производительности на большом количестве наборов данных классификации изображений. Наш метод использует широко доступный источник наблюдения: текст в сочетании с изображениями, найденными в Интернете. Эти данные используются для создания следующей прокси-задачи обучения для CLIP: по заданному изображению предсказать, какой из набора из 32 768 случайно выбранных текстовых фрагментов фактически был связан с ним в нашем наборе данных.
Наш метод использует широко доступный источник наблюдения: текст в сочетании с изображениями, найденными в Интернете. Эти данные используются для создания следующей прокси-задачи обучения для CLIP: по заданному изображению предсказать, какой из набора из 32 768 случайно выбранных текстовых фрагментов фактически был связан с ним в нашем наборе данных.
Наша интуиция подсказывает, что для решения этой задачи модели CLIP должны научиться распознавать широкий спектр визуальных понятий в изображениях и ассоциировать их со своими именами. В результате модели CLIP можно применять практически к любым задачам визуальной классификации. Например, если задачей набора данных является классификация фотографий собак и кошек, мы проверяем для каждого изображения, предсказывает ли модель CLIP текстовое описание «фото собаки » или «фото кота ». скорее всего в паре с ним.
CLIP предварительно обучает кодировщик изображений и кодировщик текста, чтобы предсказать, какие изображения были соединены с какими текстами в нашем наборе данных. Затем мы используем это поведение, чтобы превратить CLIP в нулевой классификатор. Мы конвертируем все классы набора данных в подписи, такие как «фотография собаки », и предсказываем класс подписи CLIP оценивает лучшие пары с данным изображением.
Затем мы используем это поведение, чтобы превратить CLIP в нулевой классификатор. Мы конвертируем все классы набора данных в подписи, такие как «фотография собаки », и предсказываем класс подписи CLIP оценивает лучшие пары с данным изображением.
CLIP был разработан для смягчения ряда серьезных проблем в стандартном подходе к компьютерному зрению на основе глубокого обучения:
Дорогостоящие наборы данных : Для глубокого обучения требуется много данных, а модели зрения традиционно обучались на размеченных вручную наборах данных, которые дорого создавать и обеспечивают только наблюдение за ограниченным числом заранее определенных визуальных концепций. Набор данных ImageNet, один из крупнейших проектов в этой области, потребовал более 25 000 рабочих для аннотирования 14 миллионов изображений для 22 000 категорий объектов. Напротив, CLIP учится на парах текст-изображение, которые уже общедоступны в Интернете. Снижение потребности в дорогостоящих больших помеченных наборах данных было тщательно изучено в предыдущих работах, в частности, в обучении с самоконтролем, контрастных методах, подходах к самообучению и генеративном моделировании.
Узкий : Модель ImageNet хорошо предсказывает 1000 категорий ImageNet, но это все, что она может сделать «из коробки». Если мы хотим выполнить какую-либо другую задачу, специалисту по машинному обучению необходимо создать новый набор данных, добавить выходную головку и точно настроить модель. Напротив, CLIP можно адаптировать для выполнения широкого круга задач визуальной классификации без дополнительных обучающих примеров. Чтобы применить CLIP к новой задаче, все, что нам нужно сделать, это «сообщить» текстовому кодировщику CLIP имена визуальных понятий задачи, и он выведет линейный классификатор визуальных представлений CLIP. Точность этого классификатора часто конкурентоспособна с полностью контролируемыми моделями.
Мы показываем случайные прогнозы классификаторов CLIP с нулевым выстрелом на примерах из различных наборов данных ниже. [1] быть намного ниже ожиданий, установленных эталоном. Другими словами, существует разрыв между «эталонной производительностью» и «реальной производительностью». Мы предполагаем, что этот разрыв возникает из-за того, что модели «обманывают», оптимизируя только производительность в тесте, как студент, который сдал экзамен, изучая только вопросы экзаменов прошлых лет. Напротив, модель CLIP можно оценивать на бенчмарках без необходимости обучения на их данных, поэтому она не может «мошенничать» таким образом. Это приводит к тому, что его эталонная производительность намного лучше отражает его производительность в дикой природе. Чтобы проверить «гипотезу мошенничества», мы также измеряем, как изменяется производительность CLIP, когда он может «обучаться» для ImageNet. Когда линейный классификатор устанавливается в дополнение к функциям CLIP, он повышает точность CLIP на тестовом наборе ImageNet почти на 10%. Однако этот классификатор делает не лучше в среднем по оценочному набору из 7 других наборов данных, измеряющих «надежную» производительность.
Мы предполагаем, что этот разрыв возникает из-за того, что модели «обманывают», оптимизируя только производительность в тесте, как студент, который сдал экзамен, изучая только вопросы экзаменов прошлых лет. Напротив, модель CLIP можно оценивать на бенчмарках без необходимости обучения на их данных, поэтому она не может «мошенничать» таким образом. Это приводит к тому, что его эталонная производительность намного лучше отражает его производительность в дикой природе. Чтобы проверить «гипотезу мошенничества», мы также измеряем, как изменяется производительность CLIP, когда он может «обучаться» для ImageNet. Когда линейный классификатор устанавливается в дополнение к функциям CLIP, он повышает точность CLIP на тестовом наборе ImageNet почти на 10%. Однако этот классификатор делает не лучше в среднем по оценочному набору из 7 других наборов данных, измеряющих «надежную» производительность.
Основные выводы
1. CLIP очень эффективен
CLIP учится на нефильтрованных, сильно различающихся и сильно зашумленных данных и предназначен для использования в режиме нулевого выстрела.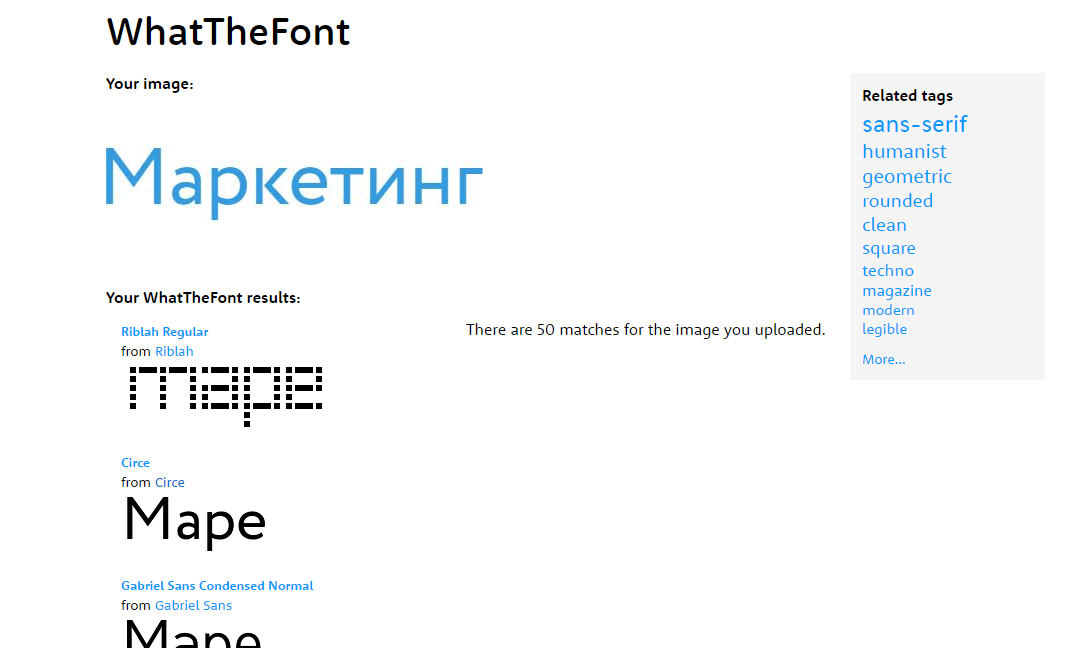 Из GPT-2 и 3 мы знаем, что модели, обученные на таких данных, могут достигать убедительных результатов с нулевым выстрелом; однако такие модели требуют значительных обучающих вычислений. Чтобы сократить объем необходимых вычислений, мы сосредоточились на алгоритмических способах повышения эффективности обучения нашего подхода.
Из GPT-2 и 3 мы знаем, что модели, обученные на таких данных, могут достигать убедительных результатов с нулевым выстрелом; однако такие модели требуют значительных обучающих вычислений. Чтобы сократить объем необходимых вычислений, мы сосредоточились на алгоритмических способах повышения эффективности обучения нашего подхода.
Мы сообщаем о двух вариантах алгоритма, которые привели к значительной экономии вычислительных ресурсов. Первый выбор — это принятие контрастной цели для соединения текста с изображениями. Первоначально мы исследовали подход преобразования изображения в текст, аналогичный VirTex, но столкнулись с трудностями при его масштабировании для достижения современной производительности. В экспериментах малого и среднего масштаба мы обнаружили, что контрастный объектив, используемый CLIP, в 4-10 раз эффективнее при классификации ImageNet с нулевым выстрелом. Вторым вариантом было использование Vision Transformer, что дало нам еще 3-кратный прирост эффективности вычислений по сравнению со стандартным ResNet. В конце концов, наша самая производительная модель CLIP обучается на 256 графических процессорах в течение 2 недель, что аналогично существующим крупномасштабным моделям изображений.
В конце концов, наша самая производительная модель CLIP обучается на 256 графических процессорах в течение 2 недель, что аналогично существующим крупномасштабным моделям изображений.
Первоначально мы изучали обучающие языковые модели преобразования изображений в титры, но обнаружили, что этот подход не справляется с нулевой передачей. В этом 16-дневном эксперименте с графическим процессором языковая модель достигла точности только 16% в ImageNet после обучения на 400 миллионах изображений. CLIP намного эффективнее и обеспечивает ту же точность примерно в 10 раз быстрее.
2. CLIP является гибким и общим
Поскольку они изучают широкий спектр визуальных понятий непосредственно из естественного языка, модели CLIP являются значительно более гибкими и общими, чем существующие модели ImageNet. Мы обнаруживаем, что они способны с нуля выполнять множество различных задач. Чтобы подтвердить это, мы измерили нулевую производительность CLIP на более чем 30 различных наборах данных, включая такие задачи, как детальная классификация объектов, географическая локализация, распознавание действий в видео и оптическое распознавание символов. [2] В частности, обучение OCR является примером захватывающего поведения, которое не встречается в стандартных моделях ImageNet. Выше мы визуализируем случайный прогноз, не являющийся лучшим, из каждого классификатора с нулевым выстрелом.
[2] В частности, обучение OCR является примером захватывающего поведения, которое не встречается в стандартных моделях ImageNet. Выше мы визуализируем случайный прогноз, не являющийся лучшим, из каждого классификатора с нулевым выстрелом.
Этот вывод также отражен в стандартной оценке обучения представлению с использованием линейных датчиков. Лучшая модель CLIP превосходит лучшую общедоступную модель ImageNet, Noisy Student EfficientNet-L2, в 20 из 26 различных наборов данных передачи, которые мы тестировали.
В наборе из 27 наборов данных, измеряющих такие задачи, как детальная классификация объектов, оптическое распознавание символов, распознавание действий в видео и геолокация, мы обнаружили, что модели CLIP изучают более широко полезные представления изображений. Модели CLIP также более эффективны с точки зрения вычислений, чем модели из 10 предыдущих подходов, с которыми мы сравниваем.
Ограничения
В то время как CLIP обычно хорошо справляется с распознаванием обычных объектов, он испытывает затруднения при выполнении более абстрактных или систематических задач, таких как подсчет количества объектов на изображении, и более сложных задач, таких как предсказание, насколько близко ближайший автомобиль находится на фотографии. . В этих двух наборах данных CLIP с нулевым выстрелом лишь немного лучше, чем случайное угадывание. Zero-shot CLIP также борется по сравнению с моделями для конкретных задач при очень тонкой классификации, например, в определении различий между моделями автомобилей, вариантами самолетов или видами цветов.
. В этих двух наборах данных CLIP с нулевым выстрелом лишь немного лучше, чем случайное угадывание. Zero-shot CLIP также борется по сравнению с моделями для конкретных задач при очень тонкой классификации, например, в определении различий между моделями автомобилей, вариантами самолетов или видами цветов.
CLIP также по-прежнему плохо обобщает изображения, не включенные в его набор данных для предварительной подготовки. Например, хотя CLIP изучает способную систему OCR, при оценке рукописных цифр из набора данных MNIST нулевая точность CLIP достигает только 88% точности, что намного ниже 99,75% людей в наборе данных. Наконец, мы заметили, что классификаторы нулевого выстрела CLIP могут быть чувствительны к формулировкам или формулировкам и иногда требуют проб и ошибок «быстрой разработки» для хорошей работы.
Более широкое воздействие
CLIP позволяет людям разрабатывать свои собственные классификаторы и устраняет необходимость в обучающих данных для конкретных задач. Способ проектирования этих классов может сильно повлиять как на производительность модели, так и на ее погрешности. Например, мы обнаруживаем, что при наличии набора ярлыков, включающего ярлыки расы Fairface [3] и нескольких вопиющих терминов, таких как «преступник», «животное» и т. д., модель имеет тенденцию классифицировать изображения людей в возрасте 0 лет. –20 в категории вопиющих при уровне ~ 32,3%. Однако, когда мы добавляем класс «дочерний» в список возможных классов, это поведение снижается до ~8,7%.
Способ проектирования этих классов может сильно повлиять как на производительность модели, так и на ее погрешности. Например, мы обнаруживаем, что при наличии набора ярлыков, включающего ярлыки расы Fairface [3] и нескольких вопиющих терминов, таких как «преступник», «животное» и т. д., модель имеет тенденцию классифицировать изображения людей в возрасте 0 лет. –20 в категории вопиющих при уровне ~ 32,3%. Однако, когда мы добавляем класс «дочерний» в список возможных классов, это поведение снижается до ~8,7%.
Кроме того, учитывая, что CLIP не требует специальных данных для обучения, он может с большей легкостью разблокировать определенные нишевые задачи. Некоторые из этих задач могут создавать риски, связанные с конфиденциальностью или слежкой, и мы изучаем эту проблему, изучая эффективность CLIP в отношении идентификации знаменитостей. CLIP имеет первую точность 59,2% для классификации изображений знаменитостей «в дикой природе» при выборе из 100 кандидатов и первую точность 43,3% при выборе из 1000 возможных вариантов. Хотя достижение этих результатов с помощью предобучения, не зависящего от задачи, заслуживает внимания, эта производительность неконкурентоспособна по сравнению с широко доступными моделями производственного уровня. Мы дополнительно исследуем проблемы, которые ставит CLIP в нашей статье, и мы надеемся, что эта работа мотивирует будущие исследования по характеристике возможностей, недостатков и предубеждений таких моделей. Мы рады взаимодействовать с исследовательским сообществом по таким вопросам.
Хотя достижение этих результатов с помощью предобучения, не зависящего от задачи, заслуживает внимания, эта производительность неконкурентоспособна по сравнению с широко доступными моделями производственного уровня. Мы дополнительно исследуем проблемы, которые ставит CLIP в нашей статье, и мы надеемся, что эта работа мотивирует будущие исследования по характеристике возможностей, недостатков и предубеждений таких моделей. Мы рады взаимодействовать с исследовательским сообществом по таким вопросам.
Заключение
С помощью CLIP мы проверили, можно ли использовать независимое от задач предварительное обучение естественному языку в масштабе Интернета, которое привело к недавнему прорыву в НЛП, для повышения эффективности глубокого обучения в других областях. Мы в восторге от результатов, которые мы уже видели, применяя этот подход к компьютерному зрению. Как и семейство GPT, CLIP изучает широкий спектр задач во время предварительной подготовки, которую мы демонстрируем с помощью переноса с нулевым выстрелом. Нас также обнадеживают наши результаты на ImageNet, которые предполагают, что нулевая оценка является более репрезентативной мерой возможностей модели.
Нас также обнадеживают наши результаты на ImageNet, которые предполагают, что нулевая оценка является более репрезентативной мерой возможностей модели.
Протокол Open Graph
Протокол Open Graph позволяет любой веб-странице стать богатый объект в социальном графе. Например, это используется на Facebook, чтобы разрешить любая веб-страница должна иметь ту же функциональность, что и любой другой объект на Facebook.
Хотя существует множество различных технологий и схем, которые можно комбинировать вместе, не существует ни одной технологии, которая предоставляет достаточно информации для богато представить любую веб-страницу в социальном графе. Протокол Open Graph основывается на этих существующих технологиях и дает разработчикам возможность воплощать в жизнь. Простота для разработчиков — ключевая цель протокола Open Graph, который повлияло на многие технические решения.
Чтобы превратить ваши веб-страницы в графические объекты, вам необходимо добавить основные метаданные в
твоя страница. Мы основывали первоначальную версию протокола на
RDFa, что означает, что вы поместите
дополнительные
Мы основывали первоначальную версию протокола на
RDFa, что означает, что вы поместите
дополнительные теги в вашей веб-страницы. Четыре обязательных
свойства для каждой страницы:
-
og:title— Название вашего объекта, как оно должно отображаться на графике, например, «Скала». -
og:type— Тип вашего объекта, например, «video.movie». В зависимости от тип, который вы укажете, также могут потребоваться другие свойства. -
og:image— URL-адрес изображения, который должен представлять ваш объект в график. -
og:url— канонический URL-адрес вашего объекта, который будет использоваться в качестве его постоянный идентификатор в графике, например, «https://www.imdb.com/title/tt0117500/».
В качестве примера ниже приведена разметка протокола Open Graph для The Rock on IMDB:
<голова>Скала (1996) movie" /> ... ...

Дополнительные метаданные
Следующие свойства являются необязательными для любого объекта и обычно рекомендуется:
-
og:audio— URL-адрес аудиофайла, сопровождающего этот объект. -
og:description— Описание вашего объекта в одном-двух предложениях. -
og:determiner— Слово, которое появляется перед названием этого объекта в предложении. Перечисление (a, an, the, «», auto). Еслиавтовыбран, потребитель ваших данных должен выбрать между «а» или «ан». По умолчанию «» (пусто). -
og:locale— локаль, в которой размечены эти теги. Форматаlanguage_TERRITORY. По умолчаниюen_US. -
og:locale:alternate— Массив других локалей на этой странице доступен в.
-
og:site_name— Если ваш объект является частью более крупного веб-сайта, имя которого должны отображаться для всего сайта. например, «IMDb». -
og:video— URL-адрес видеофайла, дополняющего этот объект.
Например (разрыв строки исключительно для отображения):
Схема RDF (в Черепахе) можно найти на ogp.me/ns.
К некоторым свойствам могут быть прикреплены дополнительные метаданные.
свойством и содержит , но свойство будет иметь дополнительные : . Свойство og:image имеет некоторые необязательные структурированные свойства:
-
og:image:url— идентичноog:image. -
og:image:secure_url— Альтернативный URL для использования, если веб-страница требует HTTPS. -
og:image:type— Тип MIME для этого изображения. -
og:image:width— Количество пикселей в ширину. -
og:image:height— Количество пикселей в высоту. -
og:image:alt— Описание того, что находится на изображении (не подпись). Если на странице указано og:image, она должна указыватьog:image:alt.
Пример полного изображения:
jpg" />
Тег og:video имеет те же теги, что и og:изображение . Вот пример:
Тег og:audio имеет только первые 3 доступных свойства
(поскольку размер не имеет значения для звука):
example.com/sound.mp3" />
Если тег может иметь несколько значений, просто поместите несколько версий одного и того же тег на вашей странице. Дан первый тег (сверху вниз)
предпочтения во время конфликтов.
Поместите структурированные свойства после объявления их корневого тега. Когда бы ни анализируется другой корневой элемент, это структурированное свойство считается выполненным и начинается другое.
Например:
означает, что на этой странице 3 изображения, первое изображение 300x300 , среднее
один имеет неуказанные размеры, а последний имеет высоту 1000 пикселей.
Чтобы ваш объект был представлен на графике, вам необходимо
указать его тип. Это делается с помощью свойства og:type :
Когда сообщество согласовывает схему для типа, он добавляется в список глобальных типов. Все остальные объекты в системе типов КЮРИ формы
Глобальные типы сгруппированы по вертикалям. Каждая вертикаль имеет свою
собственное пространство имен. Значения og:type для пространства имен всегда имеют префикс
пространство имен, а затем точку.
Это делается для того, чтобы избежать путаницы с определяемыми пользователем типами в пространстве имен, которые всегда
иметь двоеточие в них.
Музыка
- URI пространства имен:
https://ogp.me/ns/music#
og:type values:
music. song
song
-
music:duration— integer >=1 — продолжительность песни в секундах. -
music:album— массив music.album — Альбом, из которого эта песня. -
музыка:альбом:диск— целое число >=1 — На каком диске альбома эта песня. -
музыка:альбом:дорожка— целое число >=1 — Какой трек это песня. -
музыка:музыкант— массив профилей — Музыкант, написавший эту песню.
music.album
-
music:song— music.song — Песня из этого альбома. -
музыка:песня:диск— целое число >=1 — То же, что имузыка:альбом:диск, но наоборот. -
музыка:песня:дорожка— целое число >=1 — То же, что иmusic:album:track, но наоборот. -
музыка:музыкант— профиль — Музыкант, написавший эту песню. -
музыка: выпуск_дата— дата и время — Дата выхода альбома.
music.playlist
-
music:song— Идентичен музыкальному альбому -
музыка:песня:диск -
музыка:песня:дорожка -
music:creator— profile — Создатель этого плейлиста.
music.radio_station
-
music:creator— profile — Создатель этой станции.
Видео
- URI пространства имен:
https://ogp.me/ns/video#
og:type значения:
video.movie
-
video:actor— массив профилей — Актеры в фильме. -
video:actor:role— string — Роль, которую они сыграли. -
видео:директор— массив профилей — Режиссеры фильма. -
видео: писатель— массив профилей — Сценаристы фильма. -
видео:длительность— целое число >=1 — Продолжительность фильма в секундах.
-
видео: выпуск_дата— дата и время — Дата выхода фильма. -
видео: тег— массив строк — Отметьте слова, связанные с этим фильмом.
video.episode
-
video:actor— Идентичен video.movie -
видео:актер:роль -
видео:директор -
видео:писатель -
видео: продолжительность -
видео: выпуск_дата -
видео:тег -
видео: сериал— video.tv_show — К какому сериалу относится этот эпизод.
video.tv_show
Многосерийное телешоу. Метаданные идентичны video.movie.
видео.другое
Видео, которое не принадлежит ни к какой другой категории. Метаданные идентичны video.movie.
Без вертикали
Это глобально определенные объекты, которые просто не вписываются в вертикаль, но
тем не менее широко используются и согласованы.
og:type значения:
article — URI пространства имен: https://ogp.me/ns/article#
-
article:published_time— datetime — Когда статья была впервые опубликована. -
статья:modified_time— дата и время — Когда статья была изменена в последний раз. -
статья:expiration_time— datetime — Когда статья устарела после. -
статья:автор— массив профилей — Авторы статьи. -
article:section— string — Высокоуровневое имя раздела. Например. Технология -
статья:тег— массив строк — Отметьте слова, связанные с этой статьей.
книга — URI пространства имен: https://ogp.me/ns/book#
-
книга:автор— массив профилей — Кто написал эту книгу. -
книга: ISBN— строка — ISBN -
book:release_date— datetime — Дата выпуска книги.
-
book:tag— массив строк — Отметьте слова, связанные с этой книгой.
профиль — URI пространства имен: https://ogp.me/ns/profile#
-
профиль:first_name— строка — имя, обычно данное человеку родителем или выбранное им самим. -
profile:last_name— string — Имя, унаследованное от семьи или брака и под которым обычно известен человек. -
profile:username— строка — короткая уникальная строка для их идентификации. -
profile:gender— enum(мужской, женский) — Их пол.
веб-сайт — URI пространства имен: https://ogp.me/ns/website#
Никаких дополнительных свойств, кроме основных.
Любая неразмеченная веб-страница должна рассматриваться как og:type веб-сайт.
Следующие типы используются при определении атрибутов в протоколе Open Graph.
| Тип | Описание | Литералы |
|---|---|---|
| Логический | Логическое значение представляет значение true или false | правда, ложь, 1, 0 |
| ДатаВремя | DateTime представляет временное значение, состоящее из даты (год, месяц, день) и необязательный компонент времени (часы, минуты) | ИСО 8601 |
| Перечисление | Тип, состоящий из ограниченного набора константных строковых значений
(члены перечисления). | Строковое значение, входящее в перечисление |
| Поплавок | 64-битное число с плавающей запятой со знаком | Все литералы, соответствующие следующим форматам: 1,234 |
| Целое число | 32-битное целое число со знаком. Во многих языках целые числа более 32 бит становятся плавает, поэтому мы ограничиваем протокол Open Graph для удобства использования на нескольких языках. | Все литералы, соответствующие следующим форматам: 1234 |
| Строка | Последовательность символов Unicode | Все литералы, состоящие из символов Unicode без escape-символов |
| URL-адрес | Последовательность символов Unicode, идентифицирующая интернет-ресурс. | Все допустимые URL-адреса, использующие протоколы https:// или https:// |
Вы можете обсудить протокол Open Graph в
группе в фейсбуке или на
список рассылки разработчиков. В настоящее время он используется Facebook (см. их документацию),
Google (см. их документацию) и
микси.
Его публикуют IMDb, Microsoft, NHL, Posterous, Rotten Tomatoes,
TIME, Yelp и многие другие.
В настоящее время он используется Facebook (см. их документацию),
Google (см. их документацию) и
микси.
Его публикуют IMDb, Microsoft, NHL, Posterous, Rotten Tomatoes,
TIME, Yelp и многие другие.
Сообщество открытого исходного кода разработало ряд синтаксических анализаторов и инструменты. Сообщите группе Facebook, если вы тоже создали что-то потрясающее!
- Отладчик объектов Facebook — Официальный парсер и отладчик Facebook
- Инструмент тестирования Google Rich Snippets — поддержка протокола Open Graph в определенных вертикалях и поисковых системах.
- PHP Validator and Markup Generator — средство проверки ввода OGP 2011 и генератор разметки в объектах PHP5
- PHP Потребитель — небольшая библиотека для доступа к данным Open Graph Protocol в PHP
- OpenGraphNode в PHP — простой парсер для PHP
- Пиопенграф — библиотека, написанная на Python для разбора протокола Open Graph информация с веб-сайтов
- Рубиновый OpenGraph — Ruby Gem, который анализирует веб-страницы и извлекает разметку протокола Open Graph .

