Распознавание символов Моделирование мыслительных процессов на естественном…
Распознавание символов Моделирование мыслительных процессов на естественном…Привет, мой друг, тебе интересно узнать все про распознавание символов, тогда с вдохновением прочти до конца. Для того чтобы лучше понимать что такое распознавание символов , настоятельно рекомендую прочитать все из категории Моделирование мыслительных процессов на естественном языке и Символьное моделирование.
В случае, когда речь идет о распознавании печатных символов следует упомянуть, что почти бесконечное разнообразие печатной продукции изготавливается при помощью ограниченного набора оригиналов символов, которые группируются по стилю (набору художественных решений), который отличает данную группу от других. Одна группа, включающая все алфавитные знаки, цифры и стандартный набор служебных символов, называется гарнитурой. Однако в широком кругу людей, имеющих дело с производством различного рода документации, утвердилось другое название гарнитуры — шрифт; этого термина мы и будем придерживаться в дальнейшем.
Однако в широком кругу людей, имеющих дело с производством различного рода документации, утвердилось другое название гарнитуры — шрифт; этого термина мы и будем придерживаться в дальнейшем.
Итак любой печатный текст имеет первичное свойство — шрифты, которыми он напечатан. С этой точки зрения существуют два класса алгоритмов распознавания печатных символов: шрифтовой и безшрифтовый (omnifont). Шрифтовые или шрифтозависимые алгоритмы используют априорную информацию о шрифте, которым напечатаны буквы. Это означает, что программе ОРС должна быть предъявлена полноценная выборка текста, напечатанного данным шрифтом. Программа измеряет и анализирует различные характеристики шрифта и заносит их в свою базу эталонных характеристик. По окончании этого процесса шрифтовая программа оптического распознавания символов (ОРС) готова к распознаванию данного конкретного шрифта. (В последнее время, задачи при решении которых требуется обучение стали ассоциироваться с применением нейронных сетей, однако здесь развивается технология не использующая НС).
- Алгоритм должен заранее знать шрифт, который ему представляют для распознавания, т.е. он должен хранить в базе различные характеристики этого шрифта. Качество распознавания текста, напечатанного произвольным шрифтом, будет прямо пропорционально корреляции характеристик этого шрифта со шрифтами, имеющимися в базе программы. При существующем богатстве печатной продукции в процессе обучения невозможно охватить все шрифты и их модификации. К примеру, Полиграфбуммаш СССР в свое время стандартизировал около 15-20 различных шрифтов, в современных компьютерных системах верстки документов используется более 100 шрифтов. Другими словами, этот фактор ограничивает универсальность таких алгоритмов.
- Для работы программы распознавания необходим блок настройки на конкретный шрифт.
Очевидно, что этот блок будет вносить свою долю ошибок в интегральную оценку качества распознавания, либо функцию установки шрифта придется возложить на пользователя. - Программа, основанная на шрифтовом алгоритме распознавания символов, требует от пользователя специальных знаний о шрифтах вообще, об их группах и отличиях друг от друга, шрифтах, которыми напечатан документ, пользователя. Отметим, что в случае, если бумажный документ не создан самим пользователем, а пришел к нему извне, не существует регулярного способа узнать с использованием каких шрифтов этот документ был напечатан. Фактор необходимости специальных знаний сужает круг потенциальных пользователей и сдвигает его в сторону организаций, имеющих в штате соответствующих специалистов.
С другой стороны, у шрифтового подхода имеется преимущество, благодаря которому его активно используют и, по-видимому, будут использовать в будущем. А именно, имея детальную априорную информацию о символах, можно построить весьма точные и надежные алгоритмы распознавания. Вообще, при построении шрифтового алгоритма распознавания (в отличие от безшрифтового, о чем будет сказано ниже) надежность распознавания символа является интуитивно ясной и математически точно выразимой величиной . Об этом говорит сайт https://intellect.icu . Эта величина определяется как расстояние в каком-либо метрическом пространстве от эталонного символа, предъявленного программе в процессе обучения, до символа, который программа пытается распознать.
Вообще, при построении шрифтового алгоритма распознавания (в отличие от безшрифтового, о чем будет сказано ниже) надежность распознавания символа является интуитивно ясной и математически точно выразимой величиной . Об этом говорит сайт https://intellect.icu . Эта величина определяется как расстояние в каком-либо метрическом пространстве от эталонного символа, предъявленного программе в процессе обучения, до символа, который программа пытается распознать.
Второй класс алгоритмов — безшрифтовые или шрифтонезависимые, т.е. алгоритмы, не имеющие априорных знаний о символах, поступающих к ним на вход. Эти алгоритмы измеряют и анализируют различные характеристики (признаки), присущие буквам как таковым безотносительно шрифта и абсолютного размера (кегля), которым они напечатаны. В предельном случае для шрифтонезависимого алгоритма процесс обучения может отсутствовать. В этом случае характеристики символов измеряет, кодирует и помещает в базу программы сам человек. Однако на практике, случаи, когда такой путь исчерпывающе решает поставленную задачу, встречаются редко.
- Реально достижимое качество распознавания ниже, чем у шрифтовых алгоритмов. Это связано с тем, что уровень обобщения при измерениях характеристик символов гораздо более высокий, чем в случае шрифтозависимых алгоритмов. Фактически это означает, что различные допуски и огрубления при измерениях характеристик символов для работы безшрифтовых алгоритмов могут быть в 2-20 раз больше по сравнению с шрифтовыми.
- Следует считать большой удачей, если безшрифтовый алгоритм обладает адекватным и физически обоснованным, т.е. естественно проистекающим из основной процедуры алгоритма, коэффициентом надежности распознавания. Часто приходится мириться с тем, что оценка точности либо отсутствует, либо является искусственной. Под искусственной оценкой подразумевается то, что она существенно не совпадает с вероятностью правильного распознавания, которую обеспечивает данный алгоритм.

Достоинства этого подхода тесно связаны с его недостатками. Основными достоинствами являются следующие:
- Универсальность. Это означает с одной стороны применимость этого подхода в случаях, когда потенциальное разнообразие символов, которые могут поступить на вход системы, велико. С другой стороны, за счет заложенной в них способности обобщать, такие алгоритмы могут экстраполировать накопленные знания за пределы обучающей выборки, т.е. устойчиво распознавать символы, по виду далекие от тех, которые присутствовали в обучающей выборке.
- Технологичность. Процесс обучения шрифтонезависимых алгоритмов обычно является более простым и интегрированным в том смысле, что обучающая выборка не фрагментирована на различные классы (по шрифтам, кеглям и т.д.). При этом отсутствует необходимость поддерживать в базе характеристик различные условия совместного существования этих классов (некоррелированность, не смешиваемость, систему уникального именования и т.
п.). Проявлением технологичности является также тот факт, что часто удается создать почти полностью автоматизированные процедуры обучения.
- Удобство в процессе использования программы. В случае, если программа построена на шрифтонезависимых алгоритмах, пользователь не обязан знать что-либо о странице, которую он хочет ввести в компьютерную память и уведомлять об этих знаниях программу. Также упрощается пользовательский интерфейс программы за счет отсутствия набора опций и диалогов, обслуживающих обучение и управление базой характеристик. В этом случае процесс распознавания можно представлять пользователю как “черный ящик” (при этом пользователь полностью лишен возможности управлять или каким-либо образом модифицировать ход процесса распознавания). В итоге это приводит к расширению круга потенциальных пользователей за счет включения в него людей обладающих минимальной компьютерной грамотностью.
Синтез двух подходов
Выше рассматривались особенности, достоинства и недостатки двух подходов к созданию алгоритмов ОРС. Из обзора следует, что достоинства и недостатки обоих подходов определяются одними и теми же свойствами алгоритмов: большей либо меньшей степенью универсальности, степенью достижимой точности распознавания и т.п. Сравнительные недостатки и достоинства обоих подходов сведены в таблицу.
Из обзора следует, что достоинства и недостатки обоих подходов определяются одними и теми же свойствами алгоритмов: большей либо меньшей степенью универсальности, степенью достижимой точности распознавания и т.п. Сравнительные недостатки и достоинства обоих подходов сведены в таблицу.
|
Свойства |
Шрифтовые алгоритмы |
Безшрифтовые алгоритмы |
|
|
|
|
|
Универсальность |
Малая степень универсальности, обусловленная необходимостью предварительного обучения всему, что предъявляется для распознавания |
Большая степень универсальности, обусловленная независимостью обучающей выборки от какой-либо системы априорной классификации символов |
|
Точность распознавания |
Высокая, обусловлена детальной классификацией символов в процессе обучения. |
Низкая (в сравнении с шрифтовыми алгоритмами), что обусловлено высокой степенью обобщения и огрубленными измерениями характеристик символов |
|
Технологичность |
Низкая (в сравнении с безшрифтовыми алгоритмами), обусловлена различными накладными расходами, связанными с поддержкой классификации символов |
Высокая, обусловлена отсутствием какой-либо априорной системы классификации символов |
|
Поддержка процесса распознавания со стороны пользователя |
Необходима: — на этапе распознавания для указания конкретных классов символов |
Не требуется |
 А также тем, что материал распознавания находится строго в рамках классов, созданных в процессе обучения
А также тем, что материал распознавания находится строго в рамках классов, созданных в процессе обучения
Рассмотрение обоих подходов в сравнении друг с другом приводит к целесообразности их объединения. Цель объединения очевидна — получить метод, совмещающий одновременно универсальность и технологичность безшрифтового подхода и высокую точность распознавания шрифтового. Предпосылками для исследования в этом направлении послужил следующий круг идей и фактов. Любой алгоритм распознавания символов становится применим на практике при качестве распознавания 94-99%. “Дожимание” последних процентов, т.е. окончательная доводка алгоритма всегда является трудоемкой и дорогостоящей работой. Внутри сферы распознавания символов любой алгоритм имеет свою специфичную область действия, для которой он разработан и в которой проявляет себя наилучшим образом. В целом, путь увеличения качества распознавания лежит не в изобретении сверхинтеллектуального алгоритма, который заменит собой все остальные, а в комбинировании нескольких алгоритмов, каждый из которых сам по себе прост и обладает эффективной вычислительной процедурой. При комбинировании различных алгоритмов важно, чтобы они опирались на независимые источники информации о символах.
Цель объединения очевидна — получить метод, совмещающий одновременно универсальность и технологичность безшрифтового подхода и высокую точность распознавания шрифтового. Предпосылками для исследования в этом направлении послужил следующий круг идей и фактов. Любой алгоритм распознавания символов становится применим на практике при качестве распознавания 94-99%. “Дожимание” последних процентов, т.е. окончательная доводка алгоритма всегда является трудоемкой и дорогостоящей работой. Внутри сферы распознавания символов любой алгоритм имеет свою специфичную область действия, для которой он разработан и в которой проявляет себя наилучшим образом. В целом, путь увеличения качества распознавания лежит не в изобретении сверхинтеллектуального алгоритма, который заменит собой все остальные, а в комбинировании нескольких алгоритмов, каждый из которых сам по себе прост и обладает эффективной вычислительной процедурой. При комбинировании различных алгоритмов важно, чтобы они опирались на независимые источники информации о символах. В случае, если два алгоритма работают над сильно коррелированными между собой данными, то вместо увеличения качества распознавания будет увеличиваться суммарная ошибка. С другой стороны, знания о распознанных символах должны накапливаться и использоваться в последующих шагах процесса распознавания. Более того, как окончательный критерий можно использовать точный шрифтозависимый алгоритм, база характеристик которого построена прямо в процессе работы (“на лету”) по результатам предыдущих шагов распознавания. Метод, обладающий указанным выше свойством, будем называть адаптивным распознаванием, т.к. он использует динамическую настройку (адаптацию) на тные входные символы.
В случае, если два алгоритма работают над сильно коррелированными между собой данными, то вместо увеличения качества распознавания будет увеличиваться суммарная ошибка. С другой стороны, знания о распознанных символах должны накапливаться и использоваться в последующих шагах процесса распознавания. Более того, как окончательный критерий можно использовать точный шрифтозависимый алгоритм, база характеристик которого построена прямо в процессе работы (“на лету”) по результатам предыдущих шагов распознавания. Метод, обладающий указанным выше свойством, будем называть адаптивным распознаванием, т.к. он использует динамическую настройку (адаптацию) на тные входные символы.
Как ты считаеешь, будет ли теория про распознавание символов улучшена в обозримом будующем? Надеюсь, что теперь ты понял что такое распознавание символов и для чего все это нужно, а если не понял, или есть замечания, то нестесняся пиши или спрашивай в комментариях, с удовольствием отвечу. Для того чтобы глубже понять настоятельно рекомендую изучить всю информацию из категории Моделирование мыслительных процессов на естественном языке и Символьное моделирование
Imagaro Z для Mac OS 9/X: в помощь дизайнеру
3 — 2004
Маргарита Григорян
В основе всякого полиграфического воспроизведения или репродуцирования
того или иного сюжета лежит взаимодействие зрителя и запечатываемого материала. При этом не важно, получена ли распечатка на черно-белом струйном принтере
или изображение воспроизведено восемью цветами на флексографской машине.
При этом не важно, получена ли распечатка на черно-белом струйном принтере
или изображение воспроизведено восемью цветами на флексографской машине.
На выставке Macworld в СанФранциско была представлена новая программа Imagaro Z. Эта программа последняя разработка для Mac OS 9/X (включая Panther) в области автоматического трассирования, созданная для автоматического распознавания шрифтов и их замены. Imagaro Z предлагает быстрое решение вопроса сканирования и импортирования текстовой графики для последующей трассировки и восстановления шрифта. Программа может обработать как цветную, так и чернобелую графику непосредственно после ее сканирования и работает с большим количеством файловых форматов, включая AI, EPS, JPG, GIF, TIFF, BMP, PCX и др.
Работа в Imagaro Z не ограничена какимлибо одним способом трассировки выбор методов довольно широк. Используя продвинутую технологию Sensedge ™, программа Imagaro Z быстро конвертирует отсканированную или растровую графику в высококачественную масштабируемую векторную форму. Таким образом, затратив минимум усилий и времени, с помощью интуитивных инструментов редактирования в Imagaro Z можно получить векторную графику, которую впоследствии можно будет использовать для любых целей.
Таким образом, затратив минимум усилий и времени, с помощью интуитивных инструментов редактирования в Imagaro Z можно получить векторную графику, которую впоследствии можно будет использовать для любых целей.
Imagaro Z работает по следующему принципу: посредством трассировки поверх отсканированного текста программа рисует опознанный шрифт. В точности повторяя все линии и детали отсканированного текста, программа создает графическую копию шрифта, наложенную поверх отсканированного изображения. Imagaro Z опознает шрифты в любом отсканированном тексте, даже если фонт был растянут или, наоборот, сжат. Более того, программа указывает коэффициент сжатия или растянутости шрифта, благодаря чему в дальнейшем можно восстановить абсолютно идентичную отсканированному тексту картину. При идентификации отсканированного шрифта Imagaro Z использует встроенную библиотеку из 17 тыс. различных фонтов. Если же программа не сможет заменить отсканированный шрифт по причине отсутствия векторного оригинала в библиотеке Imagaro Z, она предложит похожие шрифты разных производителей, которые можно будет использовать вместо недостающего фонта.
Imagaro Z определяет шрифт, примененный в отсканированном тексте, за очень короткое время для этого требуется около минуты, а ведь у дизайнеров часто каждая минута на счету. Такая скорость и точность распознавания шрифтов становятся возможны благодаря интегрированному в программу инструменту FontEye. После распознавания шрифта программой Imagaro Z появляется возможность заменить фонт в отсканированном тексте на его высококачественный векторный оригинал.
Но главное преимущество Imagaro Z новые возможности для работы с логотипами. С помощью данной программы можно легко восстановить любой логотип. Эта функция решает множество проблем, часто возникающих у дизайнеров при воссоздании логотипов. Для того чтобы заново отрисовать логотип вручную, нужно довольно много времени. Imagaro Z позволяет выполнить эту задачу за считанные минуты. Векторизированные логотипы можно отредактировать и упростить для точности, комбинируя кривые, выпрямляя линии, а также используя интеллектуальные средства очистки.
Графику, созданную в программе Imagaro Z, можно масштабировать без какихлибо потерь в качестве и экспортировать в любое другое графическое программное обеспечение.
КомпьюАрт 3’2004
Как мы создали механизм распознавания шрифтов | by pixolution
Photo by DREW GILLIAM on UnsplashДа, мы в pixolution, естественно, больше любим изображения, чем шрифты. Но у нас был интересный проект с поставщиком программного обеспечения из Портленда Extensis, который специализируется на управлении активами шрифтов и бренд-менеджменте.
В этом конкретном случае Extensis попросила нас обучить модель ИИ, способную классифицировать шрифты. Идея заключалась в том, чтобы создать сервис, в котором пользователи могли загрузить изображение с текстом, выбрать одно или два слова и определить тип шрифта. Процесс создания этой модели был настолько интригующим и сложным, что было бы позором не поделиться им с вами.
Работа с большими данными Мы обучили нейронную сеть, способную классифицировать используемый тип и вариант шрифта во входном изображении — из 370 изученных типов шрифтов. Модель требует только одно или два слова в качестве образца ввода и не зависит от языка, от конкретного слова, фона, цвета и размера.
Модель требует только одно или два слова в качестве образца ввода и не зависит от языка, от конкретного слова, фона, цвета и размера.
Кроме того, нам пришлось реализовать конвейер предварительной обработки для нормализации пользовательского ввода перед идентификацией шрифта.
Как всегда, при обучении моделей ИИ самое главное — иметь разумные данные для обучения. Таким образом, создание достаточно большой базы данных для обучения глубокой сверточной сети с нуля было наиболее сложной задачей. В общем 90% работы — создание и улучшение обучающих данных при разработке модели ИИ. Поскольку мы могли генерировать наши обучающие данные вместо их сбора, мы смогли обучить модель с нуля.
Сначала мы собрали из Интернета списки слов на английском и немецком языках, в общей сложности 450 000 слов. Мы реализовали скрипт Python, который случайным образом выбирает 1-2 слова из этого объединенного списка слов и отображает их в файле изображения. Идея использования настоящих слов вместо случайных букв заключалась в том, чтобы отразить различные вероятности появления — а значит, важность определенных букв — в текстах реального мира. Тем не менее, мы вставили несколько случайных букв, чтобы модель не научилась буквосочетаниям.
Тем не менее, мы вставили несколько случайных букв, чтобы модель не научилась буквосочетаниям.
1. Почему проваливаются проекты корпоративного ИИ?
2. Как ИИ будет способствовать следующей волне инноваций в здравоохранении?
3. Машинное обучение с использованием регрессионной модели
4. Лучшие платформы обработки данных в 2021 г., кроме Kaggle
Для каждого шрифта мы создали 3000 изображений со случайными словами. И для каждого из этих изображений мы сгенерировали 20 дополненных версий. В сумме это составляет до 60 000 обучающих образцов для каждого шрифта и около 23 миллионов изображений в целом.
Было важно, чтобы все слова отображались с одинаковой высотой пикселя, чтобы сеть по ошибке не научилась различать шрифты по размеру.
Затем мы дополнили эти визуализированные изображения различными модификациями, чтобы сделать модель более устойчивой к шуму и отвлекающим визуальным элементам, таким как цвета фона, тени, перекрытия, кадрирование и т. д. Отличной средой для увеличения изображений является imgaug. Мы использовали его для увеличения каждого образца 20 раз.
д. Отличной средой для увеличения изображений является imgaug. Мы использовали его для увеличения каждого образца 20 раз.
Получив данные для обучения, мы перешли к обучению модели GoogLeNet. Фаза тестирования была очень приятной, так как точность валидации составила более 98%. Неплохо, правда?
Пользователи службы распознавания шрифтов загружают изображение и выбирают область из одного или двух слов. Затем это субизображение классифицируется моделью ИИ. Конечно, реальные пользователи не будут предоставлять идеальные входные данные. Они могут содержать несколько строк текста с разным шрифтом и размером изображения. Чтобы избежать потери точности, мы внедрили конвейер предварительной обработки для нормализации ввода.
Нормализация пользовательского ввода Во-первых, мы применяем ядро эрозии для создания маски связанных областей, которая приблизительно представляет строки текста. Мы определяем самую большую область и вычисляем ее ограничивающую рамку. Если мы нашли такую область, мы обрезаем входное изображение до этой ограничивающей рамки, чтобы удалить несколько строк и смещений из входного изображения и получить одну строку с текстом.
Если мы нашли такую область, мы обрезаем входное изображение до этой ограничивающей рамки, чтобы удалить несколько строк и смещений из входного изображения и получить одну строку с текстом.
Затем мы применяем адаптивный порог (алгоритм CLAHE) для автоматического выравнивания цветовых каналов. После увеличения резкости изображение масштабируется до фиксированной высоты с сохранением соотношения сторон. Мы обрезаем ширину до фиксированной ширины и центрируем полученное изображение в квадратном изображении (256×256 пикселей). Теперь изображение нормализовано и используется в качестве входных данных для модели классификации.
Мы с гордостью можем сказать, что достигли всех целей проекта с Extensis и обязательно продолжим нашу работу в области распознавания шрифтов.
Есть несколько вещей, которые мы можем улучшить. В настоящее время система не может работать с повернутым текстом, и вход модели должен быть изменен, поэтому нам не нужны квадратные изображения.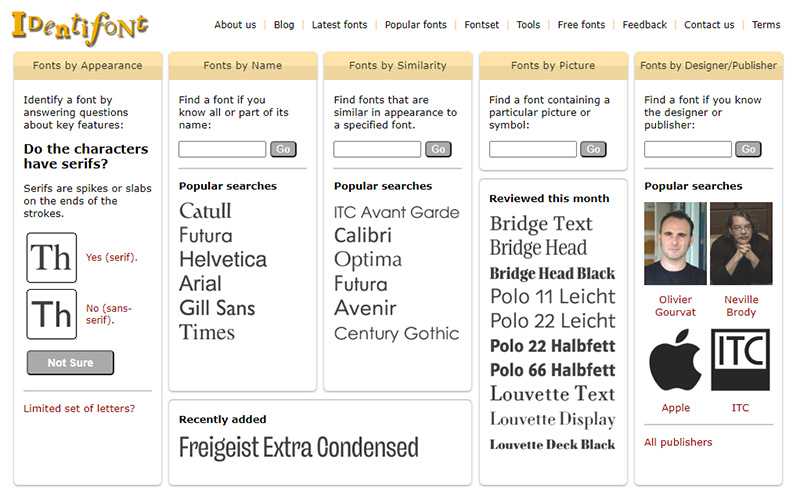 Мы многому научились и с нетерпением ждем масштабирования системы для распознавания сотен тысяч шрифтов.
Мы многому научились и с нетерпением ждем масштабирования системы для распознавания сотен тысяч шрифтов.
Если вам также нужна индивидуальная модель ИИ, просто свяжитесь с нами. Нам любопытно, куда наше путешествие приведет нас в следующий раз.
Я протестировал лучшее в мире программное обеспечение для идентификации шрифтов
Да, как следует из названия статьи, я протестировал лучшее в мире программное обеспечение для идентификации шрифтов и поделюсь с вами всем, что вам нужно знать.
Чтобы протестировать лучший в мире идентификатор шрифта, мне сначала нужно было выяснить, какой он.
Эти критерии были приняты во внимание, чтобы выяснить, что:
Бесплатно или платно, не важно.
Идентификация шрифтов с изображений и веб-сайтов.
Эффективен в идентификации шрифтов.
Простота использования.
Программное обеспечение, которое может идентифицировать как бесплатные, так и платные шрифты, а также шрифты Google.

Огромная база шрифтов.
В заключение отметим, что поиск лучшего в мире идентификатора шрифта оказался довольно простым.
Почему?
Потому что вариантов не так уж много и потому что все решения без одного победителя не соответствуют многим моим критериям.
Некоторые программы могут идентифицировать шрифты только с веб-сайтов, другие вообще не эффективны, что означает, что они не могут действительно идентифицировать шрифты, и все они, кроме победителя, определяют только платные шрифты, что совсем не хорошо (что, если шрифт бесплатно, есть масса великолепных бесплатных шрифтов?).
Победителем моего исследования стал WhatFontIs.
После быстрого использования WhatFontIs и глубокого исследования я легко понимаю, почему это решение на сегодняшний день является лучшим идентификатором шрифта в отрасли.
Вот некоторые факты о WhatFontIs:
Он имеет самую большую базу данных шрифтов в индустрии идентификаторов шрифтов — более 850 тысяч шрифтов.

Это решение может идентифицировать как бесплатные, так и платные шрифты, включая шрифты Google, и работает со всеми производителями шрифтов.
WhatFontIs идентифицирует шрифты с изображений и веб-сайтов (существует специальный плагин Google Chrome для идентификации шрифтов с веб-сайтов).
Его интерфейс очень быстрый, интуитивно понятный и простой в использовании.
Для каждого идентифицированного шрифта WhatFontIs предлагает более 60 бесплатных и платных альтернатив шрифтов.
Вы даже можете использовать WhatFontIs для поиска похожих шрифтов.
100% бесплатное использование независимо от того, сколько шрифтов вы хотите идентифицировать.
Его конкуренты неплохи, если говорить только об идентификации шрифтов с веб-сайтов, что очень просто сделать, но ни один из них не может так легко и успешно идентифицировать шрифты по картинкам, как WhatFontIs.
WhatFontIs был создан, чтобы стать самым популярным и эффективным идентификатором шрифтов в мире, и им удалось достичь своих целей.
Пока мы говорим, SimilarWeb показывает ежемесячный трафик для веб-сайта WhatFontIs в 2,6 миллиона посещений.
Итак, миллионы людей интенсивно используют их.
# Как идентификация шрифтов может помочь вам
Лично я считаю, что лучший способ найти новые шрифты — это просмотреть Интернет и посмотреть, что используют другие люди.
Вот как я это делаю, может быть, это не идеально, но у меня работает.
Вот почему я хочу поделиться им с вами.
Когда мне нужны новые шрифты для моих проектов, я сначала решаю, какой тип шрифта мне нужен.
Если мне нужен радостный шрифт, я иду и смотрю, какие шрифты используют сайты детских садов, магазины игрушек и т. д. шрифта и загружаю его на сайт WhatFontIs.
Процесс идентификации шрифтов по картинкам очень прост и занимает менее 60 секунд.
