Система распознавания шрифта Брайля. Читаем написанное белым по белому / Хабр
В 2018 году мы взяли из детдома в семью слепую девочку Анжелу. Тогда я думал, что это чисто семейное обстоятельство, никак не связанное с моей профессией разработчика систем компьютерного зрения. Но благодаря дочери через два года появилась программа и интернет-сервис для распознавания текстов, написанных шрифтом Брайля — Angelina Braille Reader.
Сейчас этот сервис используют сотни людей и в России, и за ее пределами. Тема оказалась хайповой, сюжет о программе даже показали в федеральных новостях на ТВ. Но что важнее — за свою многолетнюю карьеру в ИТ ни в одном проекте я не получал столько искренних благодарностей от пользователей.
Ниже расскажу о том, как делалась эта разработка и с какими трудностями пришлось столкнуться. Более развернутое описание приведено в публикациях [1,2].
Возможно, кто-то захочет внести в проект свой вклад.
Лень — двигатель прогресса
Вы все видели брайлевские символы в лифте и в поликлинике. Каждая буква задана выпуклыми точками. Брайль разработал свою азбуку в 1824 году, и ничего лучше для чтения и письма с тех пор не придумали.
Каждая буква задана выпуклыми точками. Брайль разработал свою азбуку в 1824 году, и ничего лучше для чтения и письма с тех пор не придумали.
Сейчас слепые активно используют компьютеры и смартфоны с голосовым помощником, свободно перемещаются по всему миру без сопровождения, устраиваются на работу, требующую высокой квалификации. Представление о том, что слепые сидят дома и плетут на заказ авоськи, давно устарело.
Но слепые школьники до сих пор читают и пишут на Брайле. Все как у обычных людей. Когда вы последний раз писали страницу текста от руки? А школьники делают это ежедневно, и пропустить этот этап нельзя.
Когда мы отдавали дочь в первый класс, то думали, что будет непросто выучить шрифт Брайля. Но это оказалось ерундовой задачей, не труднее, чем выучить любой незнакомый язык в объеме «алфавит в совершенстве».
А вот дальше сложнее. Дело в том, что брайлевские книги — это выдавленные на белой бумаге пупырышки («точки»), никак не выделенные цветом. Слепые тратят год начальной школы на то, чтобы научиться их нащупывать.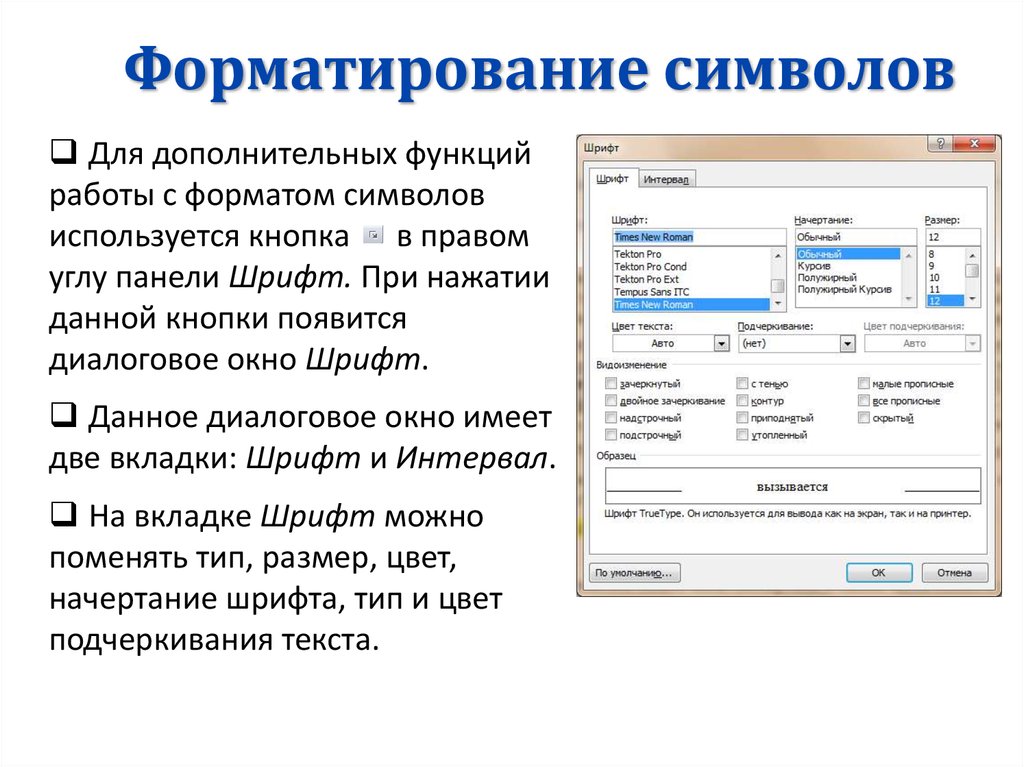 У нас такая чувствительность пальцев не развивается за ненадобностью, поэтому 99% брайлевских педагогов и родителей читают это глазами.
У нас такая чувствительность пальцев не развивается за ненадобностью, поэтому 99% брайлевских педагогов и родителей читают это глазами.
Более того! Как и обычная книга, брайлевская книга обычно двусторонняя. Вместе с выступающими точками, которые надо читать, на той же странице есть точки, выдавленные в обратную сторону. Пальцы слепого эти впуклости не замечают, а глаза зрячего видят, и все это вместе превращается в абсолютную кашу. Вообразите, что вы читаете текст на неродном языке, напечатанный светло-серым на прозрачной пленке с двух сторон.
Фрагмент брайлевской книги с двусторонней печатью (вверху). На нижнем фото отмечены те точки, которые надо читать. Остальные точки — это текст с обратной стороны страницы, на них можете не обращать внимание (если сможете).Рукописный брайлевский текст обычно односторонний, читать его несколько легче, но все равно непросто. В Союзе педагоги приспособились тереть работы школьников копиркой, чтобы сделать точки заметнее, но это решает проблему только отчасти.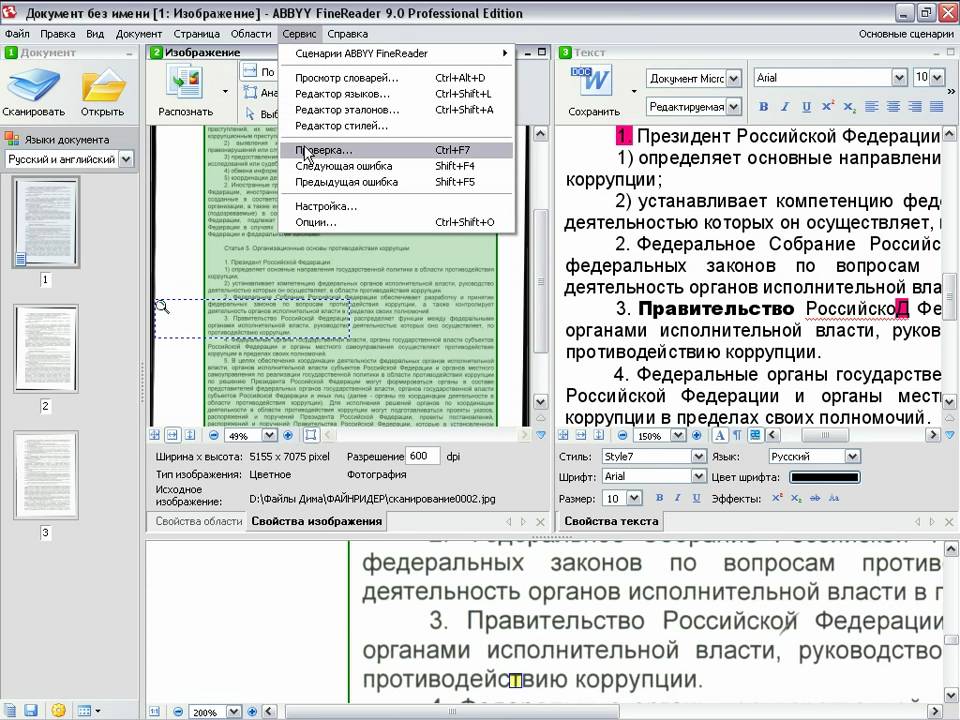
Для письма брайлевским шрифтом вручную используется специальный прибор: планшет, состоящий из 2 металлических пластин, между которыми закладывается лист бумаги. В верхней пластине сделаны прямоугольные прорези, одна ячейка — одна буква. Металлическим грифелем (шилом) продавливают бумагу в углах прорези или в середине боковой стороны, всего 6 мест под точки. В этих местах в нижней пластине сделаны углубления, таким образом получаются выдавленные брайлевские точки. Пишут справа налево в зеркальном отражении. А чтобы прочитать текст, бумагу надо вынуть из прибора и перевернуть.
За время обучения дочки в первом классе мы, оба родителя, так замучились таким чтением, что стали весьма мотивированы что-то с этим делать. Мы решили, что приспособить к чтению Брайля компьютер — намного более полезное занятие для папы в свободное время, чем решать конкурсы на Каггле. Потом оказалось, что это нужно не только моей семье, а буквально всем, кто работает со слепыми.
Хочешь сделать хорошо — сделай сам
Разумеется, я был не первым человеком, который занялся компьютерным распознаванием шрифта Брайля на изображении. Есть даже устойчивый термин: OBR (Optical Braille Recognition). Поэтому для начала я попытался найти готовое решение. Напрасно! В открытом доступе имеются только экспериментальные поделки, непригодные для практического применения. Из коммерческих разработок существует специализированный аппаратно-программный комплекс компании ЭлекЖест размером со стол. Это явно не то решение, о котором я мечтал, цену я даже не уточнял.
Система оптического распознавания Брайля от компании ЭлекЖестПопадались программы для распознавания, но они требовали отсканировать лист, причем со специальным светофильтром. Не слишком удобно, тем более что в стандартный сканер А4 брайлевский учебник не помещается. Но хуже то, что даже со сканером и светофильтром у меня не получилось получить приемлемый результат.
После фиаско с поиском готового решения пришлось переключиться на изучение литературы.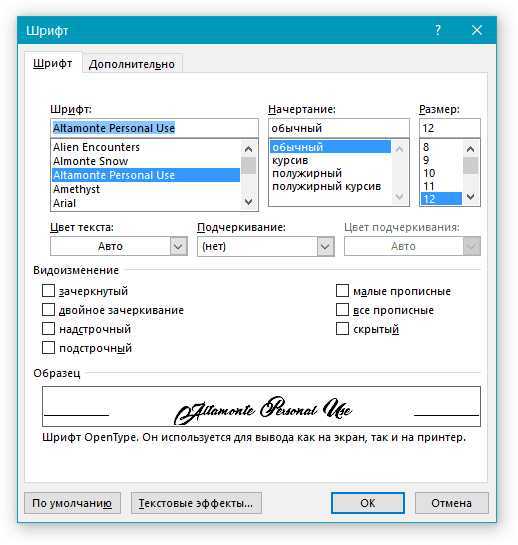 Статей по оптическому распознаванию Брайля написано много. Во всех статьях процесс распознавания разбивался на этапы, обусловленные ключевым отличием шрифта Брайля от обычных алфавитов в разных языках.
Статей по оптическому распознаванию Брайля написано много. Во всех статьях процесс распознавания разбивался на этапы, обусловленные ключевым отличием шрифта Брайля от обычных алфавитов в разных языках.
В обычном письме буквы представлены связанными линиями, а в письме по Брайлю — комбинацией от 1 до 6 точек, расположенных в узлах воображаемой сетки. Группировка точек в буквы определяется привязкой к этой сетке.
Кодирование букв латинского алфавита шрифтом БрайляВне привязки к сетке, образуемой всеми брайлевскими буквами в целом, точки не имеют смысла. Так, если мы видим на пустом листе бумаги букву А, то мы легко понимаем, что это буква А. Если мы видим одинокую брайлевскую точку, нельзя определить, что это такое: буква А, запятая (она обозначается единственной точкой, но в другом узле сетки) или просто дефект бумаги.
Вследствие этого, для описанных в литературе алгоритмов OBR практически стандартом оказывается следующий набор шагов (см. обзоры [3,4]):
Найти брайлевские точки.
Восстановить воображаемую сетку.
Сопоставить найденные точки с узлами сетки.
Распознать брайлевские символы.
Конвертировать последовательность брайлевских символов в обычный текст.
Разные авторы используют разные методы нахождения точек и, главное, отделения точек лицевой и обратной стороны: динамический порог, детектор окружностей на основе преобразования Хафа, HOG, LBP, SVM, признаки Хаара и алгоритм Виолы-Джонса, — в общем, практически весь джентльменский набор методов классического компьютерного зрения. В более поздних работах нейросетки тоже применяют.
После этого для восстановления сетки используют линейную регрессию, преобразования Хафа, изменения гистограмму распределения координат точек при пошаговом повороте листа…
Не буду приводить подробный обзор литературы (его можно найти в [1,3,4]). Важно, что при таком подходе требуется единая на весь лист воображаемая сетка, к которой привязаны брайлевские точки. Именно поэтому страница должна быть не просто сфотографирована, а отсканирована. Только в этом случае на всем листе точки расположены на параллельных линиях сетки. На случай, если страница при сканировании покосилась, описаны методы нахождения необходимого поворота страницы в исходное положение.
Именно поэтому страница должна быть не просто сфотографирована, а отсканирована. Только в этом случае на всем листе точки расположены на параллельных линиях сетки. На случай, если страница при сканировании покосилась, описаны методы нахождения необходимого поворота страницы в исходное положение.
Я не нашел никаких методов для компенсации перспективных искажений (а без них фотографию не сделаешь). Еще сложнее, если сфотографирован не одиночный лист, а страница раскрытой книги. Брайлевские книги толстые и плотные, полностью расправить страницу невозможно. Линии сетки превращаются в дуги. Так что по всему выходило, что для применения опубликованных методов нужен сканер, причем специальный — обычный бытовой мал.
А хотелось сделать так, чтобы достаточно было сделать фото на смартфон и — вжух! — получить расшифрованный текст. Пришлось делать самому.
У нее внутре нейронка
Когда я начинал эту работу (2019г), нейронные сети уже вовсю покоряли задачи компьютерного зрения. В литературе по распознаванию Брайля тоже говорилось об их использовании. Но весьма ограниченном, не выходя за пределы описанного выше шаблона: или для поиска точек, или для разделения точек лицевой и обратной стороны, или для распознавания отдельного символа после того, как будет восстановлена сетка и точки поделены на символы.
В литературе по распознаванию Брайля тоже говорилось об их использовании. Но весьма ограниченном, не выходя за пределы описанного выше шаблона: или для поиска точек, или для разделения точек лицевой и обратной стороны, или для распознавания отдельного символа после того, как будет восстановлена сетка и точки поделены на символы.
И это при том, что уже несколько лет как были опубликованы one step детекторы типа YOLO[5] и SSD[6], которые решали задачу поиска объектов на изображении за один шаг, совмещая одновременно несколько функций — детекции, классификации, регрессии ограничивающего прямоугольника. Можно было ожидать, что нейросеть справится одновременно с задачей поиска точек, восстановления брайлевской сетки в окрестности каждого символа и распознавания символа за один проход. Это позволяло отойти от требования наличия единой сетки для всего листа и, соответственно, обрабатывать изображения искривленных листов и изображения с небольшими перспективными искажениями.
За основу я взял RetinaNet[7] с некоторыми изменениями по сравнению с исходными настройками: с учетом того, что мы ищем символы примерно известного размера и пропорций, был изменен набор «якорей» и другие параметры.
В конце концов этот подход дал результат, который я считаю весьма успешным. Но его применение упиралось в серьезную проблему.
Где взять данные, или Мойдодыр спешит на помощь.
Как хорошо известно, для решения обучения нейросети требуется много обучающих данных. И если при решении частных задач вроде поиска и классификации точек или даже отдельных символов каждая страница текста порождает множество обучающих примеров, то для обучения object detection сети необходимы достаточно большие фрагменты текста. Поэтому требуется множество размеченных изображений брайлевских страниц.
Сделать фотографии сотни-другой страниц в разных условиях — несложно. А вот разметка… Как выглядят эти страницы, было показано на рисунке выше, трудоемкость разметки можете себе представить. Идея разметить прямоугольниками каждую букву на сотнях таких страниц совсем не вызывала энтузиазма.
В сети удалось найти единственный публично доступный подходящий датасет: DSBI, опубликованный китайскими товарищами. Он включает 114 размеченных страниц брайлевских текстов. Тексты там на китайском, но это как раз неважно (сами по себе брайлевские символы одинаковы во всех языках). Хуже то, что изображения получены с помощью сканера с идеально плоского листа (это позволило авторам упростить процедуру разметки) и очень мало отличаются друг от друга. Поэтому качественно обучить на нем нейросеть для решения поставленной задачи было невозможно. RetinaNet, обученная на этих данных, выдала на реальных фотографиях брайлевских книг более чем скромный результат — от четверти до половины правильно распознанных символов.
Он включает 114 размеченных страниц брайлевских текстов. Тексты там на китайском, но это как раз неважно (сами по себе брайлевские символы одинаковы во всех языках). Хуже то, что изображения получены с помощью сканера с идеально плоского листа (это позволило авторам упростить процедуру разметки) и очень мало отличаются друг от друга. Поэтому качественно обучить на нем нейросеть для решения поставленной задачи было невозможно. RetinaNet, обученная на этих данных, выдала на реальных фотографиях брайлевских книг более чем скромный результат — от четверти до половины правильно распознанных символов.
Лучшего я и не ждал. Однако надо же было с чего-то начать! А дальше на помощь пришел подход Active Learning[8].
Идея традиционного Active Learning состоит в том, что мы обучаем нейросеть на имеющихся данных, применяем ее к неразмеченным данным, оцениваем результат (вручную или автоматически с помощью какого-либо критерия), отбираем неразмеченные примеры, которые распознались хуже всех, размечаем их вручную и повторяем обучение на расширенной выборке. И так несколько раз. Тем самым экономятся трудозатраты на разметку тех примеров, с которыми нейросеть и так справляется. Однако в этой задаче я применил полностью противоположный подход. Дело в том, что разметить страницу, состоящую сплошь из ошибок, гораздо сложнее, чем исправить несколько ошибок там, где существенная часть текста внятно распознана.
И так несколько раз. Тем самым экономятся трудозатраты на разметку тех примеров, с которыми нейросеть и так справляется. Однако в этой задаче я применил полностью противоположный подход. Дело в том, что разметить страницу, состоящую сплошь из ошибок, гораздо сложнее, чем исправить несколько ошибок там, где существенная часть текста внятно распознана.
Особенностью задачи было то, что для многих неразмеченных страниц можно было найти напечатанный там текст в привычном нам виде. Текст, написанный прозой, сопоставить с изображением брайлевской страницы сложно, а вот со стихами все намного проще. Разбивка текста на строки известна, и если в распознанном тексте распознана хотя бы часть символов, которая позволяет идентифицировать строки, то недостающие и ошибочные символы можно восстановить, используя оригинальный текст. Причем лучше использовать даже не стихи, а детские стишки: написанные короткими строками, чтобы не возникало неожиданных переносов строки.
Поэтому первыми русскими текстами, на которых обучалась нейронная сеть, оказались сказки про Мойдодыра, Телефон, Чудо-дерево. Мысль, что иногда автор относится к своему проекту как к собственному ребенку, заиграла новыми красками.
Мысль, что иногда автор относится к своему проекту как к собственному ребенку, заиграла новыми красками.
Когда после нескольких итераций активного обучения качество распознавания достаточно повысилось, можно было включить в обучающий набор прозаические тексты. Сопоставлять их с оригинальным текстом так же, как стихи, было уже слишком сложно, но результаты распознавания можно было преобразовать в плоский текст и проверить спелл-чекером. Большая часть ошибок распознавания при этом подсвечивается, так что разметка радикально облегчается.
Описанный подход привел к идее сделать дальнейший процесс полностью автоматическим. Есть известный метод дообучения нейросети на неразмеченных данных — pseudo labeling[9]. Основная идея метода состоит в том, что результаты распознавания тех неразмеченных данных, где нейросеть показала высокую степень уверенности, включают в обучающий набор в дополнение к исходным размеченным данным, и обучение повторяется.
В описываемой работе в этот цикл я включил этап, на котором учитывается, что найденные нейросетью символы существуют не сами по себе, а должны подчиняться определенным правилам.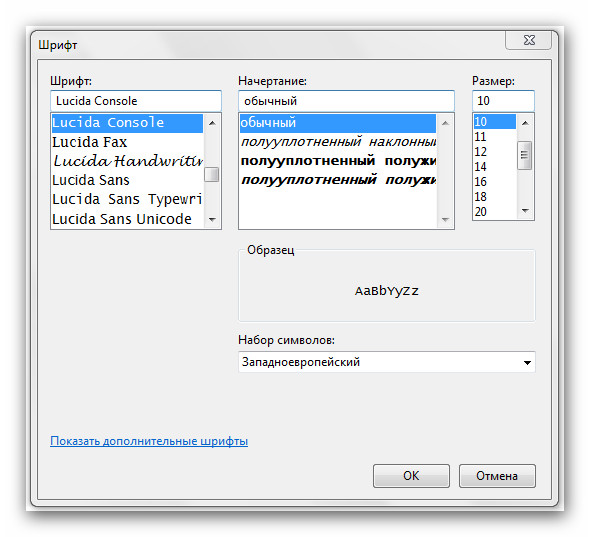 В первую очередь, можно скорректировать положения символов так, чтобы символы образовывали ровные строки, а также проверить получившиеся слова спелл-чекером и исключить те результаты, которые такую проверку не проходят. Такой подход я предложил назвать «семантически усиленной псевдо-разметкой». В общем случае это — включение в процедуру псевдо-разметки этапа, когда автоматически полученная разметка оценивается и корректируются, используя внешние соображения о допустимости полученных результатов. Это дает существенное улучшение результатов по сравнению с обычной псевдо-разметкой (см. [2]). Возможность вытаскивать самого себя за волосы, обучая нейросеть на ее собственных результатах, заканчивается достаточно быстро и ограничена примерами из того же домена, что и исходные размеченные данные. При семантически усиленной псевдо-разметке в процесс обучения включается дополнительная объективная информация. Это не только позволяет использовать больший объем неразмеченных данных, но и дообучить сеть на неразмеченных данных из домена, отличного от того, к которому относятся исходная размеченная обучающая выборка [2].
В первую очередь, можно скорректировать положения символов так, чтобы символы образовывали ровные строки, а также проверить получившиеся слова спелл-чекером и исключить те результаты, которые такую проверку не проходят. Такой подход я предложил назвать «семантически усиленной псевдо-разметкой». В общем случае это — включение в процедуру псевдо-разметки этапа, когда автоматически полученная разметка оценивается и корректируются, используя внешние соображения о допустимости полученных результатов. Это дает существенное улучшение результатов по сравнению с обычной псевдо-разметкой (см. [2]). Возможность вытаскивать самого себя за волосы, обучая нейросеть на ее собственных результатах, заканчивается достаточно быстро и ограничена примерами из того же домена, что и исходные размеченные данные. При семантически усиленной псевдо-разметке в процесс обучения включается дополнительная объективная информация. Это не только позволяет использовать больший объем неразмеченных данных, но и дообучить сеть на неразмеченных данных из домена, отличного от того, к которому относятся исходная размеченная обучающая выборка [2].
В результате применения описанных подходов получалось программное решение, дающее менее 0.5% ошибочных символов при использовании достаточно качественных изображений (хорошая камера, правильное освещение). Я написал простенький сервис на Flask и развернул на домашнем компьютере сервис, которым стал пользоваться я сам и некоторые наши знакомые по сообществу родителей слепых детей.
Кроме того, в результате этой работы получился «наш ответ Китаю»: датасет Angelina Braille Dataset из 240 размеченных фотографий брайлевских текстов. Существенно более сложный и разнообразный по сравнению датасетом DSBI, опубликованным китайскими разработчиками.
Искусство — в массы
Итак, первое время сервис работал на моем домашнем компьютере и количество пользователей прибывало методом сарафанного радио.
В 2021 описываемый сервис стал одним из победителей конкурса World AI & Data Challenge, который проводит Агентство Стратегических Инициатив. В конкурсе участвуют решения самых разных социльных проблем, построенные с помощью AI и Data science. То, что мой проект занял 2-е место в этом конкурсе, привело к двум важным практическим результатам.
В конкурсе участвуют решения самых разных социльных проблем, построенные с помощью AI и Data science. То, что мой проект занял 2-е место в этом конкурсе, привело к двум важным практическим результатам.
Во-первых, АСИ обеспечило информационную поддержку: в специализированные школы по обучению слепых было направлено официальное письмо с поручением ознакомиться с сервисом и дать отзыв. Организовало несколько zoom-конференций с преподавателями-тифлопедагогами. В результате я получил множество очень мотивирующих отзывов. Самый короткий и емкий прозвучал на одной из видеовстреч: «мы ждали эту программу всю жизнь». Но, самое важное — потенциальные пользователи узнали о программе, преодолели «порог вхождения». Только сарафанным радио достичь такого результата было бы невозможно.
Во-вторых, компания Яндекс выделила победителям конкурса грант на использование вычислительных мощностей Яндекс-облака. Я мог больше не держать сервис на своем домашнем компьютере, а разместить его на выделенной машине Яндекса.
Подробное описание опыта работы с облачной структурой Яндекса заслуживает отдельной статьи. Приведу основной вывод, к которому я пришел. Облачная структура Яндекса очень хороша для масштабных вычислений. Возможность запустить сразу несколько серверов с Tesla V100 — это прекрасно. Однако пока там нет возможности развернуть бюджетный слабонагруженный сервис, если для работы требуется GPU. Выделенная машина с Tesla V100 для данной задачи — сильный «оверкилл за оверпрайс». Надеюсь, что со временем и для этой ниши будет предложено подходящее решение.
Решить проблему помог грант Фонда Президенских Грантов, предоставленный АНО «Ангелина» (для эксплуатации сервиса была создана некоммерческая организация). Такие гранты выделяются на различные социальные проекты. В данном случае грант был выдан на приобретение выделенного сервера и размещение его в дата-центре. Пока это оказывается более доступным способом развертывания малонагруженного интернет-сервиса, требующего GPU, чем облачная структура.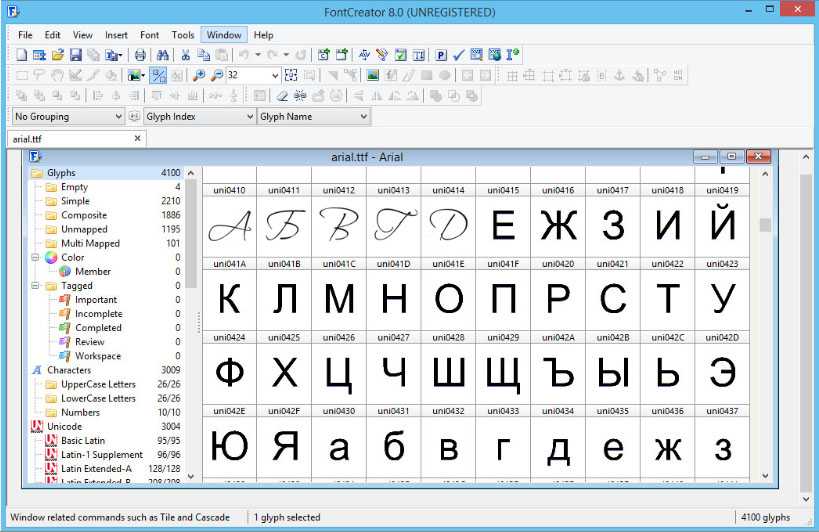
Так что, проблема решена?
До сих пор я говорил о проблеме оптического распознавания письма на Брайле. И за кадром осталась задача преобразования шрифра Брайля в обычный текст.
Дело в том, что в брайлевской азбуке всего 63 символа. Нет привычных зрячим людям подчеркиваний, курсива, верхних и нижних индексов и т.п. Буквы разных языков, цифры, математические знаки кодируются одними и теми же символами. Например, символы б, Б, b, β, 2 — это один и тот же брайлевский символ ⠃. Значение зависит от контекста. Например, перед числом ставится специальный числовой знак ⠼. Т.е. ⠼⠃⠃ — это «22». Другие правила сложнее. А полное описание использования шрифта Брайля, включая математические уравнения, дроби, использование различных языков, символов №, %, $, синтаксический и грамматический разбор предложения и т.п. занимает десятки страниц и очень напоминает Драконий Покер Р.Асприна. Кроме того, в английском языке существует система сокращений, когда длинные распространенные слова заменяются более короткими (вместо immediate пишут imm, а вместо friend — fr и т. д.).
д.).
Сейчас в сервисе эти правила реализованы в минимальном объеме, достаточно прямолинейно: в виде проверки различных условий и переключения в зависимости от них на на различные словари трансляции. Вряд ли разумно дальше развивать этот подход. И не только потому, что исходный код станет совсем нечитаемым. Многие соглашения используются неформально, предполагают контекст. Так, есть специальный символ, обозначающий переход с русского языка на английский. Но иногда он может применяться к отдельному слову, иногда ко всему следующему тексту, пока не встретится знак перехода на русский. Иногда его не ставят вовсе, если фразы вроде «O, yes, — только и смог сказать сыщик» читают интуитивно.
Существует open source библиотека Liblouis для конвертации между Брайлем и обычным плоским письмом, но в основном она применяется для преобразования плоского письма в Брайль, эта задача намного проще. Обратный перевод там реализован плохо, особенно для русского языка.
Думаю, для решения задачи перевода брайлевского текста в обычный нужно применять подходы, основанные на машинном обучении.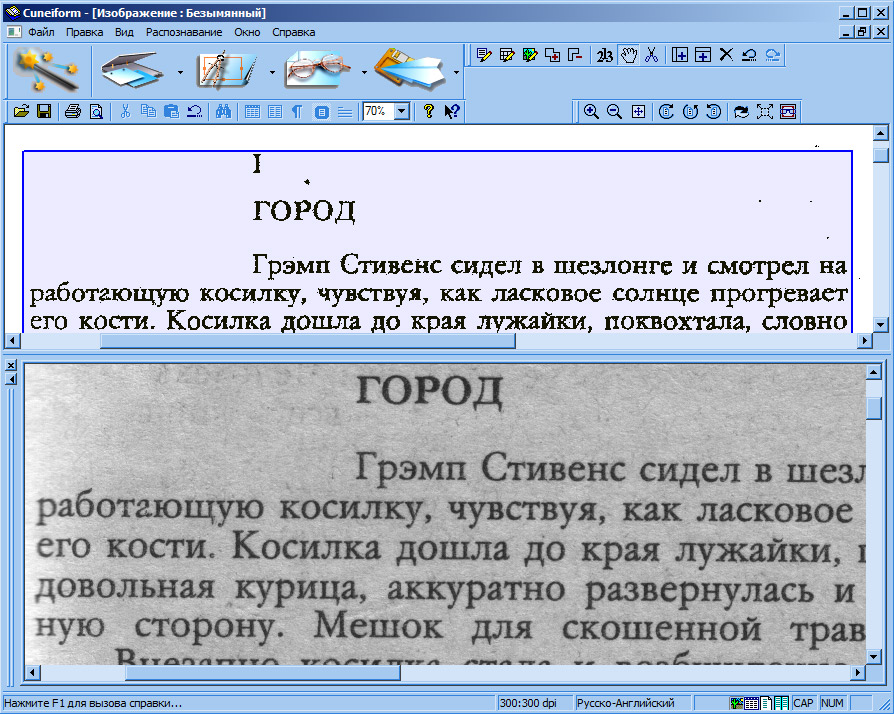 Но тут снова мы упираемся в вопрос, где взять обучающую выборку.
Но тут снова мы упираемся в вопрос, где взять обучающую выборку.
Так что проблем еще хватает. Описанная — главная, но не единственная. Есть что улучшить и в оптическом распознавании, и в веб-интерфейсе. Проект открытый, буду рад сотрудничеству. Репозитории на GitHub:
Собственно система распознавания Angelina Braille Reader
Angelina Braille Dataset
Веб-интерфейс
Литература
1. Ovodov I. G. Optical Braille Recognition Using Object Detection Neural Network //Proceedings of the IEEE/CVF International Conference on Computer Vision. – 2021. – С. 1741-1748.
2. Ovodov I. G. Semantic-based annotation enhancement algorithm for semi-supervised machine learning efficiency improvement applied to optical Braille recognition //2021 IEEE Conference of Russian Young Researchers in Electrical and Electronic Engineering (ElConRus). – IEEE, 2021. – С. 2190-2194.
3. A review on software algorithms for optical recognition of embossed braille characters / V. Udayashankara [и др.] // International Journal of computer applications. — 2013. — Т. 81, № 3. — С. 25—35.
Udayashankara [и др.] // International Journal of computer applications. — 2013. — Т. 81, № 3. — С. 25—35.
4. Isayed, S. A review of optical Braille recognition / S. Isayed, R. Tahboub //2015 2nd World Symposium on Web Applications and Networking (WSWAN). — IEEE. 2015. — С. 1—6.
5. Joseph Redmon, Santosh Divvala, Ross Girshick, and Ali Farhadi. You only look once: Unified, real-time object detection. In Proceedings of the IEEE conference on computer vision and pattern recognition, pages 779–788, 2016
6. Wei Liu, Dragomir Anguelov, Dumitru Erhan, Christian Szegedy, Scott Reed, Cheng-Yang Fu, and Alexander C Berg. Ssd: Single shot multibox detector. In European conference on computer vision, pages 21–37. Springer, 2016
7. Tsung-Yi Lin, Priya Goyal, Ross Girshick, Kaiming He, and Piotr Dollar. Focal loss for dense object detection. In ´ Proceedings of the IEEE international conference on computer vision, pages 2980–2988, 2017
8. Settles B. Active learning literature survey. University of Wisconsin //Computer Science Department. – 2010.
University of Wisconsin //Computer Science Department. – 2010.
9. Lee D. H. et al. Pseudo-label: The simple and efficient semi-supervised learning method for deep neural networks //Workshop on challenges in representation learning, ICML. – 2013. – Т. 3. – №. 2. – С. 896.
Как определить шрифт на картинке, изображении (в т.ч. распознавание русского шрифта)
Здравствуйте.
В своей офисной работе мне иногда приходится писать текст тем же шрифтом, который был использован для документа. Это хорошо, если он электронный, но что если он только бумажный? Иногда нам приходится искать шрифт на скане (фотографии).
Но могут быть и другие причины, чтобы узнать шрифт. Вы увидели красивую надпись и хотите сделать что-то похожее, вам нужно исправить (скорректировать) какую-то надпись под картинкой (чтобы она не выделялась среди остального текста) и т.д.
В любом случае, в этой статье я собираюсь предложить несколько альтернативных вариантов, как это сделать. Вскоре я понял, что если на картинке изображен уникальный шрифт (не используемый больше нигде, т. е. созданный самим дизайнером), то найти его невозможно (хотя вы можете найти похожий).
е. созданный самим дизайнером), то найти его невозможно (хотя вы можете найти похожий).
А теперь вернемся к основной теме…
👉Добавление!
Если у вас есть только фотография на бумаге (печатный документ), то для начала вам нужно оцифровать ее (отсканировать). Сегодня это можно сделать с помощью обычного смартфона на базе Android.
*
Вариант 1: Использование ABBY Fine Reader
Для тех из вас, кто не знаком с программой ABBY Fine Reader, это программа, которая распознает текст с фотографий, PDF-файлов, отсканированных изображений и т.д. (Другими словами, она распознает текст, когда вы набираете текст. (То есть на входе у вас обычный графический файл, а на выходе программа предоставляет вам текст, который вы можете затем перенести в Word).
Официальный сайт 👉 «ABBY Fine Reader» — https://www.abbyy.com/ru-ru/download/finereader/.
Теперь Fine Reader не изменяет шрифт по умолчанию при распознавании текста. Это означает, что для распознавания будет выбран шрифт текста в файле изображения (фотографии, рисунке и т.д.).
Это означает, что для распознавания будет выбран шрифт текста в файле изображения (фотографии, рисунке и т.д.).
Давайте покажем вам пример…
1) Мы пропустим установку и запуск программы (они стандартны и не должны вызвать затруднений). Далее необходимо нажать в меню «Файл/Открыть PDF или изображение» и указать изображение/фотографию, содержащую необходимый текст…
Открыть PDF или изображение
2) Изображение будет распознано автоматически по умолчанию (примечание: слева отображается исходное изображение, справа — результат распознавания).
Обычно, когда программа завершает свою работу, вы можете просто щелкнуть на нужной части полученного текста, и шрифт будет отображен. Например, когда я загрузил скриншот своей домашней страницы, Fine Reader отобразил шрифт Georgia (именно так!). Вы также можете использовать следующие шрифты
Шрифт Georgia (скриншот: ABBY Fine Reader)
Это легко проверить. Откройте любую страницу сайта ocomp.info в браузере и посмотрите исходный код документа (на скриншоте ниже он показан в Chrome).
Посмотрите на Джорджию.
Для другого примера мы взяли разворот из книги «Война и мир». Используемый шрифт — Times New Roman.
Скриншот Times New Roman — ABBY Fine Reader
Удобно ли это? Это очень удобно. Я считаю, что это один из самых эффективных методов (особенно для русскоязычных текстов).
Примечание: если распознанная фотография или изображение использует необычный шрифт (отсутствующий в вашей системе), Fine Reader автоматически выберет наиболее похожий из доступных шрифтов.
*
Вариант 2: С онлайн-сервисом
Онлайн-сервисы привлекательны в первую очередь тем, что вы можете сразу же начать их использовать, без необходимости их установки или настройки. С другой стороны, их функциональность и эффективность очень низки (по крайней мере, для того, чтобы их можно было использовать, они должны быть гораздо качественнее, чем Fine Reader).
Однако его преимущество заключается в том, что он способен обнаружить шрифты, даже если они отсутствуют на вашем компьютере. Вот некоторые ссылки
Вот некоторые ссылки
- https://www.myfonts.com/WhatTheFont (служба, автоматически распознающая шрифты. Они всегда рекомендуют платную версию, хотя она почти идентична традиционным шрифтам…) .
- https://www.fontspring.com/matcherator (аналогичная услуга).
- https://www.whatfontis.com/ (аналог предыдущего, который работает только иногда, но все же…) .
- https://www.xfont.ru/russian (богатая коллекция русских шрифтов).
- https://fontstorage.com/ru/ (еще один…) Здесь вы найдете коллекцию из более чем 1000 различных шрифтов! 😉)
Работа с вышеперечисленными сервисами может быть построена как с ручными вариантами (когда вы сами подбираете шрифт и сравниваете его с оригиналом), так и с автоматическими вариантами (когда сервис по сходству подбирает коллекцию шрифтов).
Вы можете рассмотреть возможность работы с одним из сервисов, myfonts.com (он занимает первое место в моем мини-списке). Как только вы окажетесь на сайте, вам нужно будет загрузить изображение, а затем выбрать на нем текстовую область (см. шаги 1 и 2 на скриншоте ниже).
шаги 1 и 2 на скриншоте ниже).
Загрузка изображения и выделение текстовой области
Затем вам будет представлен список шрифтов. Из них вы можете выбрать тот, который ближе всего к вашему шрифту (обычно первым в списке идет нужный вам шрифт).
Чем Impact MT отличается от Impact…? Чем это отличается от «Воздействия…»? (Результаты)
Обратите внимание, что англоязычный сервис не всегда хорошо обрабатывает русский текст (часто вместо определенного шрифта выбирается немного другой).
Примечание: Имейте в виду, что платные шрифты (которые вам предложат купить на различных сервисах) часто мало чем отличаются от бесплатных шрифтов, уже установленных в вашей системе.
*
Это все на этот раз.
Удачи!
✌
Распознавание шрифта по картинке
Очень многие пользователи современных компьютерных систем, вернее, дизайнеры, так или иначе сталкиваются с проблемой, когда требуется произвести распознавание шрифта текста, который содержится в каком-то изображении.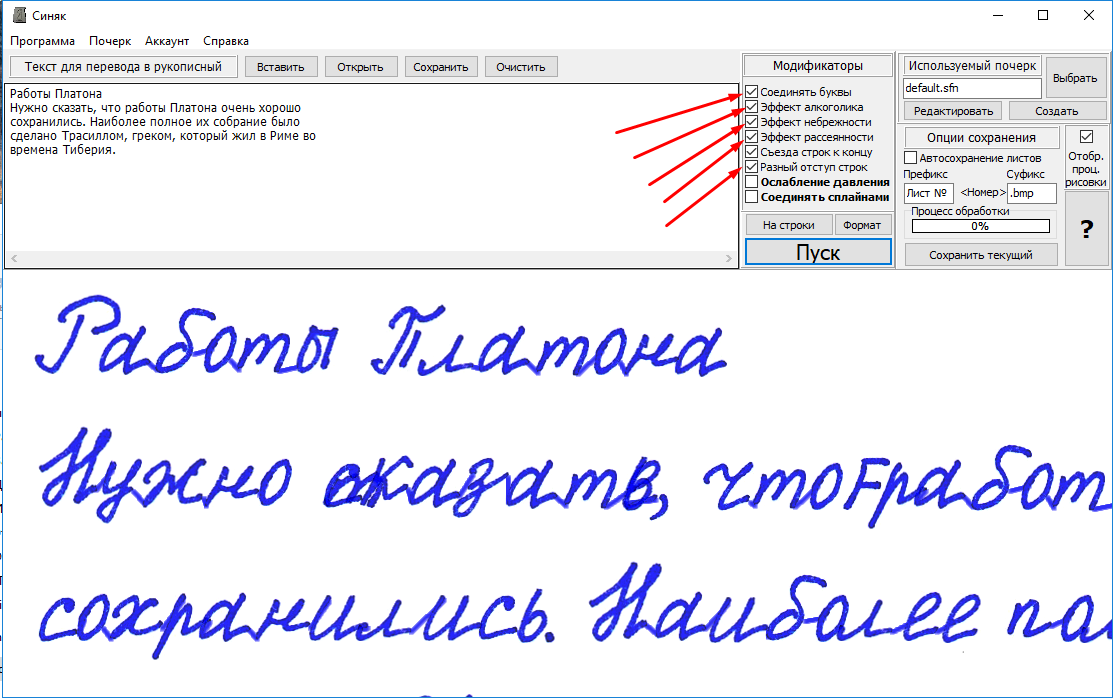 Сейчас будет рассмотрено несколько простейших вариантов того, как это сделать с минимальными затратами времени и сил.
Сейчас будет рассмотрено несколько простейших вариантов того, как это сделать с минимальными затратами времени и сил.
Распознавание шрифта: основные аспекты
Начнем, пожалуй, с того, что, в общем-то, наивно думать, что определение шрифта — это то же самое, что распознавание текста. Распознавание текста, созданного в каком-либо редакторе или просто отпечатанного на старых машинках, это всего лишь частный случай более общего определения. И даже такие мощные программы, как ABBYY Fine Reader, для этого подходят не всегда. Конечно, они умеют выделять из искомого изображения текстовые фрагменты, однако анализ в большинстве случаев производится исключительно на основе стандартных шрифтов, которые являются универсальными для всех типов текстовых редакторов и свободно интегрируются в приложения такого типа, что позволяет использовать их даже независимо от основной программной платформы.
Но что делать, когда требуется распознавание шрифта, созданного вручную, скажем, в графическом приложении или вообще нарисованного от руки? Посудите сами, ведь художник может изобразить любую букву как угодно.
В качестве самого простого примера можно взять хотя бы оригинальные сборники русских народных сказок, где каждая заглавная литера в начале первого абзаца текста оформлялась узорчатым рисунком. Из всего этого скопления компьютерная программа должна выбрать именно букву, отбросив в сторону все остальное. Собственно, именно поэтому распознавание кириллических шрифтов, даже по сравнению с иероглифами, является достаточно трудной задачей. Тем не менее, кое-какие средства для этого есть.
Приложения для распознавания шрифтов на картинке
Сейчас остановимся на нескольких простейших программных продуктах, которые подойдут пользователю любого уровня.
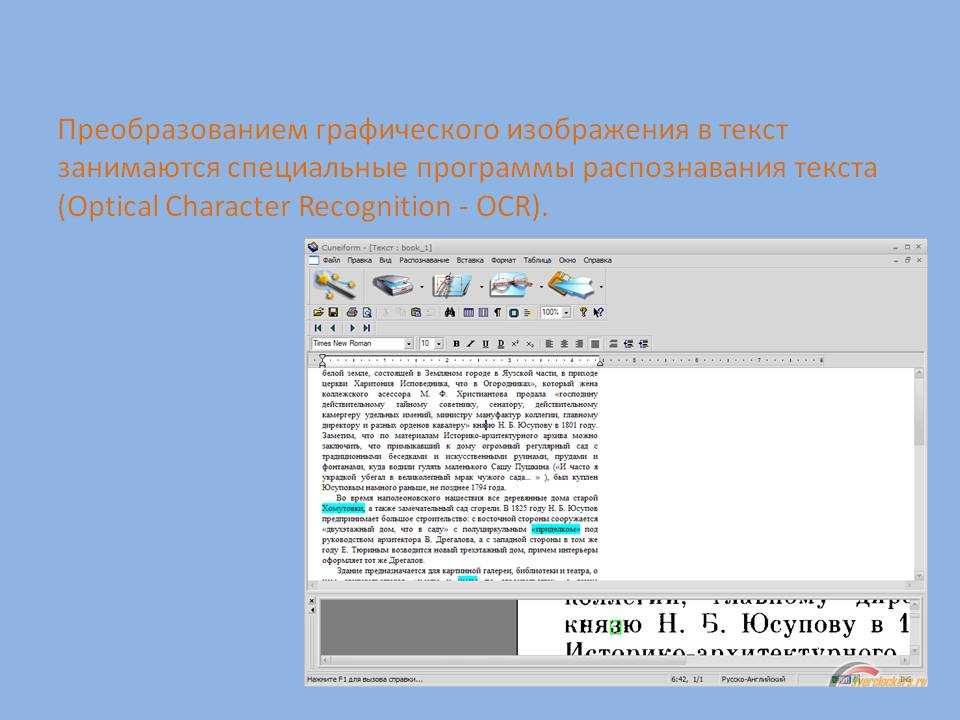
Прежде всего стоит отметить приложение CuneiForm. Это программа распознавания шрифтов, в том числе и кириллицы, которая позволяет не только определить, к какому именно языку относится текст даже с необычным шрифтом, а еще и сохранить первоначальную структуру всего документа. К примеру, если он был создан в каком-то компьютерном приложении, в нем присутствуют табличные данные (равно как и сама таблица), приложение сможет запросто определить такую структуру и сохранить ее при выводе результатов. То же самое касается и применяемого в документе форматирования.
То же самое касается и применяемого в документе форматирования.
Одной из главных особенностей приложения является и то, что кроме поддержки нескольких языков программа имеет собственный словарь, который применяется при анализе текста, проводимого по окончании процесса распознавания шрифта. При этом программа довольно неплохо работает с документами низкого качества, скажем, отсканированными старыми фотографиями с текстом или историческими документами. Кроме всего прочего, в словарную базу можно добавлять новые данные для дальнейшего использования.
Очень простым приложением можно назвать и программу Font Analyze. Не вникая в принципы ее функционирования, отметим только сам процесс. Здесь пользователю необходимо просто загрузить изображение со шрифтом в поле анализатора, после чего активировать процесс распознавания. Тут «фишка» в том, что после получения результата сканирования и обработки его можно редактировать.
Интересной является и система Font Matching Tool. Кроме всего прочего, данное приложение рекомендуется использовать совместно с программой Compare It!, которая позволяет производить сравнение исходного документа и результата с распознанными шрифтами.
Онлайн-сервис по распознаванию шрифта
Кроме программ, устанавливаемых на компьютер, или их портативных версий можно воспользоваться услугами множества интернет-ресурсов. Распознавание шрифта на картинке в плане действий производится аналогично предыдущим приложениям. Разница только в том, что пользователь загружает картинку непосредственно на сайт, а результат скачивает себе на компьютер.
Среди наиболее популярных и востребованных сервисов можно привести такие онлайн-системы, как What The Font, Identifont, Message Boards: Typophile, Bowfin Printworks, Type Navigator, Flickr Typeface Identification и многие другие.
Заключение
Остается добавить только то, что особо ни на программы, ни на интернет-ресурсы лучше не рассчитывать. Ждать от них чего-то сверхъестественного не приходится. Посудите сами, ведь даже обычную капчу распознают далеко не все интернет-боты. А ведь аналогия с программами, предназначенными для распознавания шрифта, здесь очевидна. Так что при использовании таких средств можно надеяться в основном только на результаты определения простейших шрифтов. Другое дело, что они распознаются не из печатных офисных документов, а из картинок. В этом, собственно, и заключается главный плюс всех программных продуктов и служб такого типа.
Другое дело, что они распознаются не из печатных офисных документов, а из картинок. В этом, собственно, и заключается главный плюс всех программных продуктов и служб такого типа.
Метод распознавания шрифта текста с изображения
Авторы: Коробов Дмитрий Владимирович, Патин Михаил Владиславович
Рубрика: Информационные технологии
Опубликовано в Молодой учёный №12 (116) июнь-2 2016 г.
Дата публикации: 11.06.2016 2016-06-11
Статья просмотрена: 2346 раз
Скачать электронную версию
Скачать Часть 2 (pdf)
Библиографическое описание: Коробов, Д.
В настоящее время в интернете и социальных сетях прослеживается тенденция к передаче и обмену информацией с помощью цифровых изображений. В связи с этим большим спросом пользуются программы, позволяющие среднестатистическому пользователю работать с данными, полученными с изображения.
В данной работе описывается алгоритм распознавания шрифта текста с изображения. Для проведения исследовательской работы была написана программа для мобильных устройств на платформе iOS.
Ключевые слова: компьютерное зрение, распознавание шрифта, контурный анализ, OpenCV, iOS
В настоящий момент развитие цифровых технологий позволяет людям передавать и принимать информацию с большой скоростью. Доступность и развитость современной техники сделало особо распространенным такой вид данных, как цифровые изображения. В связи с этим большим спросом пользуются программы, позволяющие среднестатистическому пользователю получать и работать с данными, полученными с изображения. Эти задачи можно решить с помощью методов цифровой обработки. Первоначально эти методы разрабатывались и исследовались специалистами, работающими в области прикладной математики. Сейчас создано несколько общедоступных библиотек, например OpenCV, позволяющих вести работу с цифровыми данными, однако их использование все еще требует определенного технического образования. Такие библиотеки компьютерного зрения не содержат готовых решений и являются лишь инструментом для создания рабочих алгоритмов.
Доступность и развитость современной техники сделало особо распространенным такой вид данных, как цифровые изображения. В связи с этим большим спросом пользуются программы, позволяющие среднестатистическому пользователю получать и работать с данными, полученными с изображения. Эти задачи можно решить с помощью методов цифровой обработки. Первоначально эти методы разрабатывались и исследовались специалистами, работающими в области прикладной математики. Сейчас создано несколько общедоступных библиотек, например OpenCV, позволяющих вести работу с цифровыми данными, однако их использование все еще требует определенного технического образования. Такие библиотеки компьютерного зрения не содержат готовых решений и являются лишь инструментом для создания рабочих алгоритмов.
Алгоритм.
Для распознавания шрифта текста используется методы контурного анализа. Контур буквы или цифры с входного изображения сравниваются с контуром этого же символа в различных шрифтах. Для данной работы первоначально была создана демонстрационная база шрифтов, которая содержит в себе эталонные изображения букв и цифр.
Алгоритм можно поделить на 3 этапа: предобработка изображения, выделение символов текста на изображении и сравнение контуров. Рассмотрим первый этап более подробно:
Предобработка изображения.
- Первым делом входное изображение следует перевести в градации серого. В OpenCV это делается с помощью функции cvtColor().
- Далее используется медианный фильтр, для удаления шумов. Он хорошо справляется с шумами типа «перец и соль», а так же данный фильтр улучшает контур ла (рис. 1), что очень важно для дальнейшего контурного анализа. В OpenCV для этого ис
- Используется функция medianBlur().
- Следующий шаг заключает в себе бинаризацию изображения или перевод изображения в черно-белое (рис. 2) с помощью функции thresholdMat(). Бинаризация проводится по пороговому значению яркости пикселя, которое равняется 127.
Рис. 1. Фильтрация шумов
Рис. 2. Бинаризация изображения
Выделение символов.
На данном этапе происходит выделение каждого символа в отдельное изображение.
- С помощью детектора границ Кэнни, реализованного в OpenCV в виде функции Canny(), на изображении выделяются границы всех объектов (рис.3).
Рис. 3. Выделение границ
- Затем с помощью функции findContours(), можно получить контуры объектов в виде набора точек с координатами. Имея набор точек для каждого контура можно определить наименьший прямоугольник, который будет содержать область внутри контура. Найти прямоугольник можно с помощью функции boundingRect() (рис. 4).
Рис. 4. Выделение контуров
Прямоугольник будет опять же представлен в виде набора точек его контура. Используя эту информацию, выделяем на начальном изображении контур каждого прямоугольника и сохраняем внутреннюю область в виде нового изображения (рис. 5).
Рис. 5. Выделенные объекты
Сравнение контуров.
Контур каждого символа сравнивается с контуром этого же символа в различных шрифтах с помощью функции сomputeDistance() из библиотеки OpenCV. Принцип работы функции следующий: на вход подается два контура, а на выходе численное значение. Чем больше число, тем меньше похожи контура. В основе алгоритма лежит сравнение точек контуров между собой (рис. 6).
Рис. 6. Сравнение контуров
Отыскиваются похожие точки и строится гистограмма различий, по которой считается расстояние. Подробная реализация алгоритма, заложенного в основе функции computeDistance() описана в статье Belongie S., Malik J., Puzicha J. «Shape matching and object recognition using shape contexts» [1].
Рассмотрим результаты полученные при использовании функции computeDistance(). Для примера были взяты изображения трех символов в семи различных шрифтах: Arial, Calibri, Cambria, Candara, JavaneseText, MongolianBaiti, TimesNewRoman (рис. 7–9).
Рис. 7. Результаты для буквы S
Рис. 8. Результаты для буквы t
8. Результаты для буквы t
Рис. 9. Результаты для буквы P
На рисунках 7–9 показано, как меняются значения функции computeDistance() от шрифта к шрифту. Не вооруженным глазом видно, что похожие буквы имеют близкие выходные значения функции, и как эти значения увеличиваются с при добавлении различных элементов на букву. Например, буква P имеет характерные засечки в шрифтах Cambria, JavaneseText, MongolianBaiti, TimesNewRoman. Можно наблюдать, что выходное значение делает большой скачок при переходе от шрифта Calibri к Cambria.
Определение шрифта.
Процедура сравнения с эталонными изображениями в различных шрифтах производится для каждого символа. Первые три наилучших шрифта, т. е. имевшие наименьшие выходные значения функции computeDistance(), получают от 1 до 3 баллов соответственно. После того, как контуры всех символов будут сравнены, выбираются три шрифта с наибольшими баллами. Именно эти шрифты выбираются, как наиболее похожие с шрифтом текста с входного изображения.
Выводы.
В ходе экспериментов было установлено, что функция computeDistance() дает достаточно точные результаты и чувствительна только к качеству входного изображения и эталонного изображения символа. К сожалению, существует один значимый недостаток — время работы. Так как сравнение контуров идет попиксельно, при хорошем входном изображении контуры могут достигать размерности от 250 до 500 пикселей. Неоднократный перебор такого массива требует большой вычислительной мощности.
Для исследований данный алгоритм был реализован в виде мобильного приложения для устройств на платформе iOS. Тестирование велось на устройстве iPhone 5s. Его характеристики: 2-ух ядерный процессор AppleA7 64-bit, 1.3 Гц, 1GbRAM. На данном устройстве распознавание шрифта текста на изображении (рис. 1) заняло около 10 секунд.
Литература:
- Garcia G. B., Suarez O. D., Aranda J. L. E. Learning Image Processing with OpenCV. ISBN-13: 978–1-78328–765–9. Birmingham: Packt Publishing, 2015.
 319 p.
319 p. - Belongie S., Malik J., Puzicha J. Shape matching and object recognition using shape contexts // IEEE Transactions on Pattern Analysis and Machine Intelligence. 2002. Vol. 24. No 4. P. 509–522.
- Dawson-Howe K. A Practical Introduction to Computer Vision with OpenCV. John Wiley&Sons Ltd, 2014. 235 p.
- Suzuki S, Abe K. Topological Structural Analysis of Digitized Binary Images by Border Following // CVGIP. 1985. Vol. 1. P. 32–46.
- OpenCV documentation. htt://docs.opencv.org/.
Основные термины (генерируются автоматически): изображение, контур, помощь функции, входное изображение, сравнение контуров, шрифт, выходное значение функции, компьютерное зрение, контурный анализ, среднестатистический пользователь.
Ключевые слова
компьютерное зрение, распознавание шрифта, контурный анализ, OpenCV, IOSкомпьютерное зрение, распознавание шрифта, контурный анализ, OpenCV, iOS
Похожие статьи
Методы определения объектов на
изображенииОсновным разделом компьютерного зрения является извлечение информации из изображений или последовательности изображений.
Определение объекта с помощью поиска контуров.
Обработка и сегментация тепловизионных
изображенийТочки контура, в сравнении с остальными пикселями изображения, более устойчивы, полученные в разное время, разных ракурсах, условиях погоды и смены температуры. За счет того, что контурные точки составляют незначительную часть всех точек на изображениях…
Сравнение методов нахождения ключевых точек на контуре…Шаг 3. Производится анализ полученного контурного изображения, в результате которого запоминаются координаты всех белых точек и сортируются в виде цепочек рядом стоящих точек, образующих линию контура.
Формирование методов и задач
компьютерного зрения. ..
..Рассмотрены методы и задачи повышения качества, выделения контуров и сегментация изображений на основе нечетких множеств. Разработана структурная схема основных функциональных подсистем с учетом “мягких вычислений”.
Разработка информационного обеспечения автоматизированной…
Опишем более подробно входные и выходные данные автоматизированной системы.
Сойфер, В. А. Методы компьютерной обработки изображений / В. А. Сойфер, — М.: Физматлит, 2001.
Анализ методов обнаружения лиц на изображении.
Методы распознавания образов | Статья в журнале…
изображение, преобразование, класс, анализ изображений, распознавание образов, машинное обучение, машинное зрение, искусственный интеллект, вектор признаков, фильтрация контуров.
Алгоритмы распознавания объектов | Статья в сборнике…
Ключевые слова: распознавание образов, обработка изображений, компьютерное зрение, машинное обучение.
Первая задача решается путем отображения пространства входных векторов в пространство значений простых классификаторов
Математическое и программное обеспечение распознавания…
– методы контурного анализа [8]: методы нахождения контуров: детектор границ Кэнни [8]
сравнение контуров с помощью вычисления моментов [3]; cравнение контуров методом морфинга (метод активных контуров) [9].
Методы определения объектов на
изображенииОсновным разделом компьютерного зрения является извлечение информации из изображений или последовательности изображений.
Определение объекта с помощью поиска контуров.
Обработка и сегментация тепловизионных
изображенийТочки контура, в сравнении с остальными пикселями изображения, более устойчивы, полученные в разное время, разных ракурсах, условиях погоды и смены температуры. За счет того, что контурные точки составляют незначительную часть всех точек на изображениях…
Сравнение методов нахождения ключевых точек на контуре…Шаг 3. Производится анализ полученного контурного изображения, в результате которого запоминаются координаты всех белых точек и сортируются в виде цепочек рядом стоящих точек, образующих линию контура.
Формирование методов и задач
компьютерного зрения. ..
..Рассмотрены методы и задачи повышения качества, выделения контуров и сегментация изображений на основе нечетких множеств. Разработана структурная схема основных функциональных подсистем с учетом “мягких вычислений”.
Разработка информационного обеспечения автоматизированной…
Опишем более подробно входные и выходные данные автоматизированной системы.
Сойфер, В. А. Методы компьютерной обработки изображений / В. А. Сойфер, — М.: Физматлит, 2001.
Анализ методов обнаружения лиц на изображении.
Методы распознавания образов | Статья в журнале…
изображение, преобразование, класс, анализ изображений, распознавание образов, машинное обучение, машинное зрение, искусственный интеллект, вектор признаков, фильтрация контуров.
Алгоритмы распознавания объектов | Статья в сборнике…
Ключевые слова: распознавание образов, обработка изображений, компьютерное зрение, машинное обучение.
Первая задача решается путем отображения пространства входных векторов в пространство значений простых классификаторов
Математическое и программное обеспечение распознавания…
– методы контурного анализа [8]: методы нахождения контуров: детектор границ Кэнни [8]
сравнение контуров с помощью вычисления моментов [3]; cравнение контуров методом морфинга (метод активных контуров) [9].
Похожие статьи
Методы определения объектов на
изображенииОсновным разделом компьютерного зрения является извлечение информации из изображений или последовательности изображений.
Определение объекта с помощью поиска контуров.
Обработка и сегментация тепловизионных
изображенийТочки контура, в сравнении с остальными пикселями изображения, более устойчивы, полученные в разное время, разных ракурсах, условиях погоды и смены температуры. За счет того, что контурные точки составляют незначительную часть всех точек на изображениях…
Сравнение методов нахождения ключевых точек на контуре…Шаг 3. Производится анализ полученного контурного изображения, в результате которого запоминаются координаты всех белых точек и сортируются в виде цепочек рядом стоящих точек, образующих линию контура.
Формирование методов и задач
компьютерного зрения. ..
..Рассмотрены методы и задачи повышения качества, выделения контуров и сегментация изображений на основе нечетких множеств. Разработана структурная схема основных функциональных подсистем с учетом “мягких вычислений”.
Разработка информационного обеспечения автоматизированной…
Опишем более подробно входные и выходные данные автоматизированной системы.
Сойфер, В. А. Методы компьютерной обработки изображений / В. А. Сойфер, — М.: Физматлит, 2001.
Анализ методов обнаружения лиц на изображении.
Методы распознавания образов | Статья в журнале…
изображение, преобразование, класс, анализ изображений, распознавание образов, машинное обучение, машинное зрение, искусственный интеллект, вектор признаков, фильтрация контуров.
Алгоритмы распознавания объектов | Статья в сборнике…
Ключевые слова: распознавание образов, обработка изображений, компьютерное зрение, машинное обучение.
Первая задача решается путем отображения пространства входных векторов в пространство значений простых классификаторов
Математическое и программное обеспечение распознавания…
– методы контурного анализа [8]: методы нахождения контуров: детектор границ Кэнни [8]
сравнение контуров с помощью вычисления моментов [3]; cравнение контуров методом морфинга (метод активных контуров) [9].
Методы определения объектов на
изображенииОсновным разделом компьютерного зрения является извлечение информации из изображений или последовательности изображений.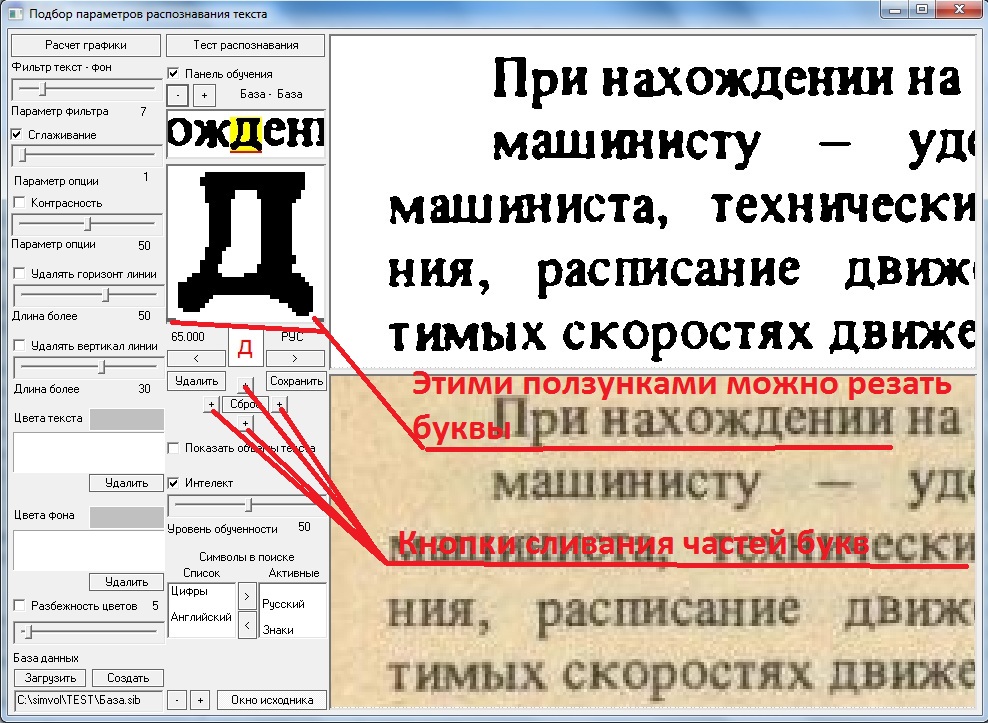
Определение объекта с помощью поиска контуров.
Обработка и сегментация тепловизионных
изображенийТочки контура, в сравнении с остальными пикселями изображения, более устойчивы, полученные в разное время, разных ракурсах, условиях погоды и смены температуры. За счет того, что контурные точки составляют незначительную часть всех точек на изображениях…
Сравнение методов нахождения ключевых точек на контуре…Шаг 3. Производится анализ полученного контурного изображения, в результате которого запоминаются координаты всех белых точек и сортируются в виде цепочек рядом стоящих точек, образующих линию контура.
Формирование методов и задач
компьютерного зрения. ..
..Рассмотрены методы и задачи повышения качества, выделения контуров и сегментация изображений на основе нечетких множеств. Разработана структурная схема основных функциональных подсистем с учетом “мягких вычислений”.
Разработка информационного обеспечения автоматизированной…
Опишем более подробно входные и выходные данные автоматизированной системы.
Сойфер, В. А. Методы компьютерной обработки изображений / В. А. Сойфер, — М.: Физматлит, 2001.
Анализ методов обнаружения лиц на изображении.
Методы распознавания образов | Статья в журнале…
изображение, преобразование, класс, анализ изображений, распознавание образов, машинное обучение, машинное зрение, искусственный интеллект, вектор признаков, фильтрация контуров.
Алгоритмы распознавания объектов | Статья в сборнике…
Ключевые слова: распознавание образов, обработка изображений, компьютерное зрение, машинное обучение.
Первая задача решается путем отображения пространства входных векторов в пространство значений простых классификаторов
Математическое и программное обеспечение распознавания…
– методы контурного анализа [8]: методы нахождения контуров: детектор границ Кэнни [8]
сравнение контуров с помощью вычисления моментов [3]; cравнение контуров методом морфинга (метод активных контуров) [9].
Топ-10 программ для распознавания текста в отсканированных файлах
OCR — это технология преобразования файлов, созданных на основе изображений, в редактируемый текст. К файлам, созданным на основе изображений, относятся документы, отсканированные из учебников, журналов или рукописный текст в печатный, обычно сохраняемые в формате PDF. Технология распознавания символов (OCR) позволяет извлечь текст из этих изображений и сделать его редактируемым. В этой статье мы представим 10 лучших бесплатных программ для распознавания текста, которые помогут вам с легкостью редактировать отсканированные PDF-файлы.
К файлам, созданным на основе изображений, относятся документы, отсканированные из учебников, журналов или рукописный текст в печатный, обычно сохраняемые в формате PDF. Технология распознавания символов (OCR) позволяет извлечь текст из этих изображений и сделать его редактируемым. В этой статье мы представим 10 лучших бесплатных программ для распознавания текста, которые помогут вам с легкостью редактировать отсканированные PDF-файлы.
- # 1. PDFelement
- # 2. FreeOCR
- # 3. i2OCR
- # 4. Online OCR
- # 5. Free Online OCR
- # 6. Cvisiontech
- # 7. SuperGeek Free Document OCR
- # 8. onOCR
- # 9. Investintech
- # 10. OCRgeek
1. PDFelement
Wondershare PDFelement — Редактор PDF-файлов обеспечивает удобную работу с отсканированными PDF-документами благодаря передовой технологии оптического распознавания символов. Эта функция позволяет распознавать текст отсканированных PDF-файлов, чтобы сделать текст и файл редактируемыми. Кроме того, с его помощью вы можете конвертировать ваши отсканированные PDF-файлы в другие редактируемые форматы, включая Excel, Word, PPT, Text и другие. Качество вашего оригинального документа будет полностью сохранено.
Кроме того, с его помощью вы можете конвертировать ваши отсканированные PDF-файлы в другие редактируемые форматы, включая Excel, Word, PPT, Text и другие. Качество вашего оригинального документа будет полностью сохранено.
PDFelement оснащен мощными инструментами редактирования, которые позволяют вставлять, удалять или изменять текст, изображения и страницы. Вы также можете заполнять интерактивные и неинтерактивные формы и создавать новые формы с различными вариантами их заполнения.
Скачать Бесплатно Скачать Бесплатно
Мощная функция автоматического распознавания форм позволяет с легкостью обрабатывать формы.
Извлекайте данные легко, эффективно и точно с помощью функции извлечения данных из форм.
Преобразование стопок бумажных документов в цифровой формат с помощью функции распознавания текста для лучшего архивирования.
Редактируйте документы, не изменяя шрифты и форматирование.
Совершенно новый дизайн, позволяющий вам оценить содержащиеся в нем рабочие документы.
Руководство: Как скопировать текст из изображения
2. FreeOCR
Полностью бесплатный онлайн-инструмент для распознавания текста, который не требует регистрации или указания адреса электронной почты. Работает с различными файлами изображений, включая GIF, JPG, BMP, TIFF или PDF с многостолбцовым текстом. Распознает более 30 различных языков. Размер загрузки ограничен до 2 МБ или 5000 пикселей, можно загружать не более 10 изображений в час.
3. i2OCR
i2OCR работает со следующими типами файлов изображений: JPEG, TIF, BMP, PNG, PBM, GIF, PPM, PGM или изображения, доступные по ссылке (URL). Программа позволяет конвертировать изображения с вашего локального диска или онлайн. Без регистрации. Поддержка PDF-документов с многостолбцовым текстом и распознавание текстов на 33 языках. В отличие от FreeOCR, нет ограничений по количеству загруженных изображений.
В отличие от FreeOCR, нет ограничений по количеству загруженных изображений.
4. Online OCR
Online OCR позволяет конвертировать фотографии и цифровые изображения в текст. Распознает тексты на 32 языках и конвертирует отсканированные PDF-файлы в Word, RTF и текстовые форматы. С помощью данной программы можно также извлекать текст из изображений в форматах JPG, JPEG, BMP, TIFF и GIF и преобразовывать его в редактируемые документы Word, TXT, PDF, Excel или HTML. Конвертирование до 15 изображений в час.
5. Free Online OCR
Free Online OCR позволяет конвертировать скриншоты, отсканированные документы, факсы и фотографии в форматы текст с возможностью поиска и редактирования, например, TXT, DOC, RTF и PDF. Программа поддерживает такие форматы, как BMP, PDF, PNG, TIFF, JPG(JPEG), и GIF.
6. Cvisiontech
Cvisiontech также поддерживает одновременную загрузку нескольких файлов TIFF, PDF, BMP и JPG. Перед загрузкой необходимо убедиться, что размер любого из загруженных файлов менее 100 МБ. Программа позволяет сжимать файлы и оптимизировать их для веб-сайта.
Перед загрузкой необходимо убедиться, что размер любого из загруженных файлов менее 100 МБ. Программа позволяет сжимать файлы и оптимизировать их для веб-сайта.
7. SuperGeek Free Document OCR
SuperGeek Free Document OCR — удобная и мощная программа для конверирования изображений и распознавания текста (OCR), подходящая как для профессионального, так и для домашнего использования. Позволяет читать текст из JPG, JPEG, TIF, TIFF, PNG, BMP, PSD, GIF, EMF, WMF, J2K, DCX, PCX, JP2 и т.д. и конвертировать файлы данных типов в редактируемые документы MSWord и TXT всего за несколько кликов.
8. onOCR
Программа onOCR справляется с различными отсканированными PDF или файлами изображений независимо от их размера. Free OCR помогает преобразовывать нередактируемые документы в тексты с возможностью копирования и редактирования. Вы можете обрабатывать как крупные, так и мелкие изображения и преобразовывать их в редактируемый текст.
9. Investintech
Able2Extract от Investintech — это инструмент для работы PDF с возможностью конвертирования отсканированных PDF в один из более чем 10 различных типов редактируемых файлов. С его помощью вы можете преобразовывать файлы практически любого типа в защищенные PDF, просматривать и редактировать PDF и преобразованные файлы, а также извлекать текст из отсканированных документов.
10. OCRgeek
OCRGeek позволяет вам выполнять распознавать тексты онлайн в пакетном режиме. Вы можете без проблем загружать по несколько файлов одновременно. Процесс распознавания происходит быстро и просто. Загруженные вами документы будут организованы и одновременно преобразованы в формат TXT. Форматы ввода, которые поддерживает OCRgeek: JPG, PNG, TIFF, PDF, DJVU, GIF и BMP.
Безбумажный офис экономит время и денежные средства, но это означает, что большое количество бумажных документов необходимо оцифровывать путем сканирования. Однако вы не можете редактировать или добавлять что-либо к тексту, это вообще не сэкономит времени. Оптическое распознавание символов (OCR) преобразует текст из этих документов или изображения документов, чтобы вы могли работать с ними в цифровом виде. Существует множество программ распознавания текста. Если вы остановились здесь в поисках идеального устройства распознавания текста для сканирования ваших документов? Хорошее решение!
Однако вы не можете редактировать или добавлять что-либо к тексту, это вообще не сэкономит времени. Оптическое распознавание символов (OCR) преобразует текст из этих документов или изображения документов, чтобы вы могли работать с ними в цифровом виде. Существует множество программ распознавания текста. Если вы остановились здесь в поисках идеального устройства распознавания текста для сканирования ваших документов? Хорошее решение!
Но обратите внимание, что идеальное программное обеспечение для распознавания текста не должно ограничиваться только сканированием файлов. Вместо этого в нем должны быть другие дополнительные функции для организации документов, преобразования, редактирования, объединения и так далее. Вот почему мы провели глубокое исследование, чтобы предложить вам эти отличные программы распознавания текста для настольных компьютеров. В этом видео мы порекомендуем пять лучших программ, которые помогут конвертировать ваши документы. Давайте учиться!
Скачать Бесплатно Скачать Бесплатно КУПИТЬ СЕЙЧАС КУПИТЬ СЕЙЧАС
Приложение для определения шрифта в браузере. Как определить шрифт по картинке. Исходный код страницы
Здравствуйте, дорогие друзья. Как провели выходные, а точнее праздники? Надеюсь, что хорошо. Я лично замечательно их провел. Мы с женой с друзьями ездили в город Ярославль. Но об этом я хотел бы рассказать в следующий раз. А пока к вам у меня один вопрос: представьте, что вы увидели какой-то текст (на сайте или картинке) и он вам жутко понравился. Представили? Отлично.
И вот что тогда делать, если вам хочется использовать этот шрифт у себя, например для фотошопа, офисных документов (Word, PDF и т.д.) или же для своего сайта? Я вам покажу как определить шрифт текста на картинке или любом сайте, ну или по крайней мере найти очень похожий на него. Готовы? Тогда поехали!
Если вы увидели красивый текст на каком-либо изображении, то рекомендую вам один способ для определения.
Но самое главное — не скачивайте ничего отсюда. Лучше ищите проверенным способом, который я показывал здесь .
Но это я описал идеальный случай, когда темный шрифт находится на светлом фоне без лишних деталей. А вот если картинка более насыщенная и на ней больше деталей, то будет немного сложнее. Но все равно сервис постарается подобрать то, что считает похожим.
Текст на картинке (кириллические)
К сожалению, я пока еще не встречал сервисов, которые могут распознавать кириллические (русские) шрифты. Очень жаль. Попадалась одна программа font detect , но она ищет шрифты только в конкретных папках на вашем компьютере и на самом деле не сама по себе не очень.
Но есть общедоступный сайт, где люди выкладывают картинки с текстом, а знающие люди помогают определить, что это вообще. В итоге в большинстве случаев результат положительный.
Текст на веб-страницах
Если вы зашли на какой-либо сайт и вам понравился сам шрифт написания на сайте, то его очень легко можно определить с помощью расширения в браузере гугл хром. Посмотрим? Давайте!
Посмотрим? Давайте!
В общем, благодаря таким нехитрым приемам, вы сможете найти такой шрифт, который вам нужен, или же найти хотя бы что-то близкое и похожее. В любом случае это очень ощутимая помощь и намного лучше, чем если вы будете искать всё в ручную. Правильно я говорю?
Единственное, сервисы эти не всемогущие и могут не найти вам что-либо даже похожее. И на это могут влиять разные факторы, например слишком много лишних объектов на картинке или плохо сканируемый и круто-обработанный (растянутый или со множеством эффектов) текст. Так что старайтесь искать более подходящие изображения.
Ну а я на этом сегодняшнюю статью завершаю. И я искренне надеюсь, что она вам пришлась по нраву. Обязательно подпишитесь на обновления моего блога, а также поделитесь статьей в социальных сетях. Кроме того рекомендую вам почитать и другие статьи. Уверен, что вы найдете что-нибудь полезное для себя. Увидимся. Пока-пока!
С уважением, Дмитрий Костин!
Наверняка у многих была ситуация, когда надо было определить неизвестный шрифт.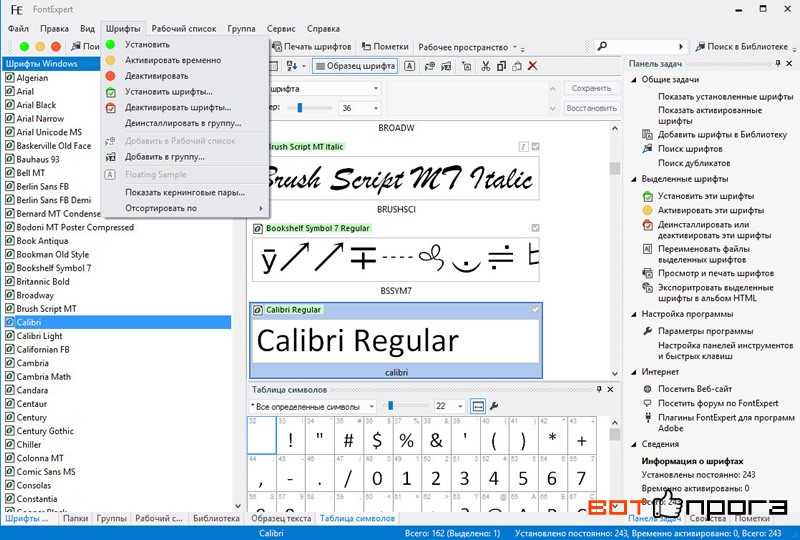
Поможет решить данную проблему достаточно простым и оригинальным способом. Вы загружаете (со своего компьютера или указав ссылку) картинку или логотип, на которых содержится текст, а сайт выдаёт список шрифтов. Для загрузки подходят файлы размером не более 360 x 275 пикселей и следующих форматов: GIF, JPEG, TIFF, BMP. Иногда может потребоваться ввести соответствующие символы, изображенные на картинке, поскольку система не всегда способна сама их точно опознать.
Для лучшего распознавания системой отдельных символов, разработчики рекомендуют придерживаться следующих рекомендаций. Следует помнить, что чем меньше шрифт, тем более велика вероятность ошибочной идентификации текста. Оптимальным для системы является размер отдельного символа в пределах 100 пикселей (больший размер увеличивает время поиска совпадений). Конечно, ссылаясь на ограничение картинки по ширине, изображение будет содержать всего 3-4 символа, но этого вполне достаточно для определения похожих шрифтов. Сервис успешно работает с цветными картинками, однако высокой точности можно добиться только на черно-белых изображениях.
После загрузки изображения анализатор распознает символы.
Если определить шрифт все таки не получилось, можно отправить изображение на форум , где вам всегда помогут.
Есть один недостаток — нет поддержки кириллических шрифтов.
Есть еще один замечательный онлайн сервис по распознанию шрифтов — (What Font is)
Загрузив на этот сайт изображение вы сможете узнать какой шрифт использовался для написания текста на на ней. В базе имеется достаточное количество латинских шрифтов, а вот с кириллицей пока не густо. Еще на сайте предлагается бесплатно скачать некоторое количество шрифтов.
На сервисе Whatfontis есть 3 пути узнать что за шрифт:
Путь 1
В первое окно загрузить графическое изображение, содержащие надпись нажать кнопку Continue. Появиться окно распознования вашей картинки и поля для ввода буквы которую сервер смог распознать. Чем больше букв вы укажете, тем выше шанс найти ваш искомый шрифт.
По окончанию в самом конце страницы, будет три варианта поиска:
- Display only free fonts or free alternative fonts
(Отобразить только бесплатные шрифты или альтернативные бесплатные) - Display only commercial fonts or commercial alternative fonts
(Отобразить только платные шрифты или альтернативные коммерческие) - Display all fonts
(Отобразить все шрифты)
Путь 2
Можно не загружать свою картинку содержащую текст с искомым шрифтом, а указать веб адрес картинки со шрифтом.
Путь 3
Поиск по имени. Можно ввести название шрифта и искать его аналоги.
Я уверен, что у любого дизайнера был такой момент, когда он видел где-то какой-то шрифт, который так мог бы пригодится в проекте, но… что за шрифт?.. Ответ на этот вопрос затаился в глубине Вашего сознания, либо в глубине Вашего «незнания» (что разумеется простительно).
В этой статье мы рассмотрим несколько ресурсов, которые могут помочь вам в идентификации понравившегося шрифта.
Конечно, нельзя рассчитывать, что эти источники дадут вам 100 процентную уверенность в том что вы найдете нужный шрифт, но что помогут, так это точно.
Graphic Design Blog полезный ресурс, но может помочь лишь в том случае, если вы знаете имя дизайнера или студию, создавшего шрифт. Список студий и дизайнеров весьма обширный и поиск шрифта в разы упрощается. Но, что делать, если вы видите шрифт в первый раз?
Шаг 2: После загрузки картинки, проверьте, что What The Font правильно определил глифы, и лишь после этого жмите «поиск».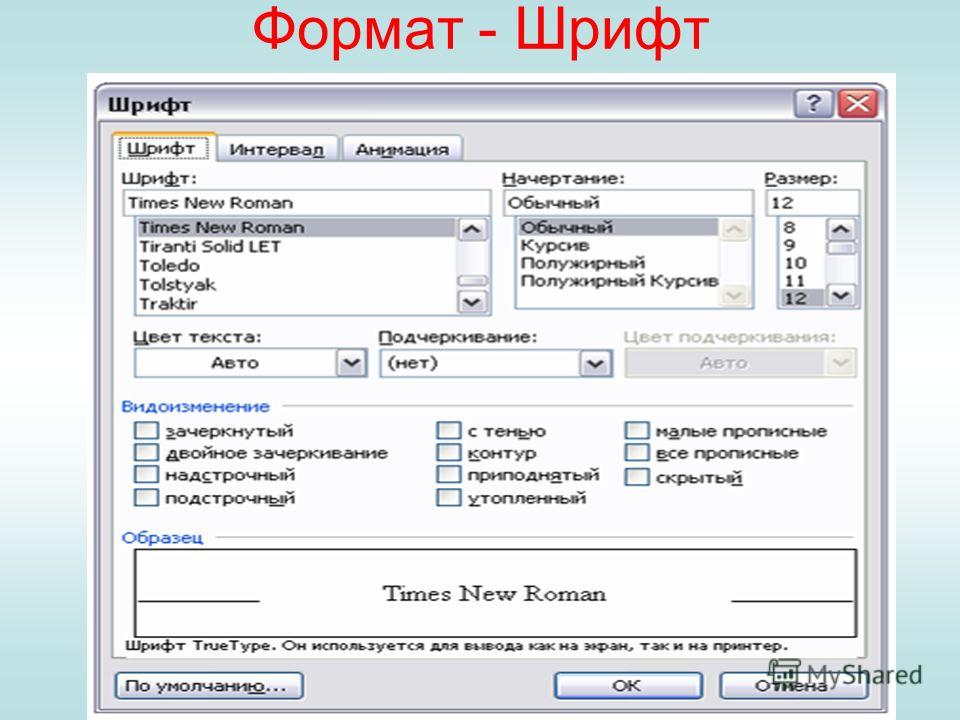
Вкратце, ГЛИФ — это графический образ знака. Один знак может соответствовать нескольким глифам; строчная «а», капительная «а» и альтернативный вариант строчной «а» с росчерком являются одним и тем же знаком, но в то же время это три разных глифа (графемы).
С другой стороны, один глиф также может соответствовать комбинации нескольких знаков, например лигатура «ffi», являясь единой графемой, соответствует последовательности трех знаков: f, f и i. Т.о. для программы проверки орфографии слово suffix будет состоять из 6 знаков, а графический процессор выдаст на экран 4 глифа.
Сначала я загрузил эту картинку:
Отличное сообщество, огромное количество ресурсов, блогов, новостей связных с типографской культурой. Есть даже typography Wiki.
В статье отвечу на вопрос как узнать шрифт на сайте. Не раз видел на блогах интересные написания, и как определить стиль и описание покажу ниже.
Верный способ как узнать шрифт на сайте
Хотел написать много методов как узнать шрифт на сайте,но вывел один и самый точный.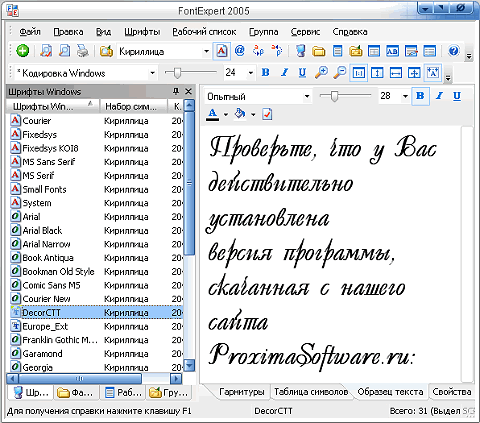 В пример взял блог своего друга Андрея mixinvestor. Советую использовать браузер гугл хром. Заходим на желаемый ресурс и смотрим инструкцию.
В пример взял блог своего друга Андрея mixinvestor. Советую использовать браузер гугл хром. Заходим на желаемый ресурс и смотрим инструкцию.
- Обводим какой текст нужен для проверки.
- Нажимаем правой кнопкой мыши и “Просмотреть код”.
- Строки html, подтверждающие правильность.
- Название и написание, так же видно какой размер, в примере 41 px.
Далее вы можете его прописать, либо найти в онлайн. Чтобы найти такой стиль написания для скачивания, введите в поисковую выдачу гугл или яндекс.
- Заходим на результат из выдачи.
- Скачиваем оригинал.
Видео определение: какой используется шрифт на ресурсе и ка его определить
В видео показан секретный способ определения и использования специального расширения для google chrome.
Случалась ли с вами такая ситуация: заприметишь красивый шрифт, и хочешь забрать к себе в коллекцию, а он оказывается на картинке, а не в печатном тексте? То есть и в исходном коде не посмотреть, что за начертание использовано для оформления, и на глаз не определить.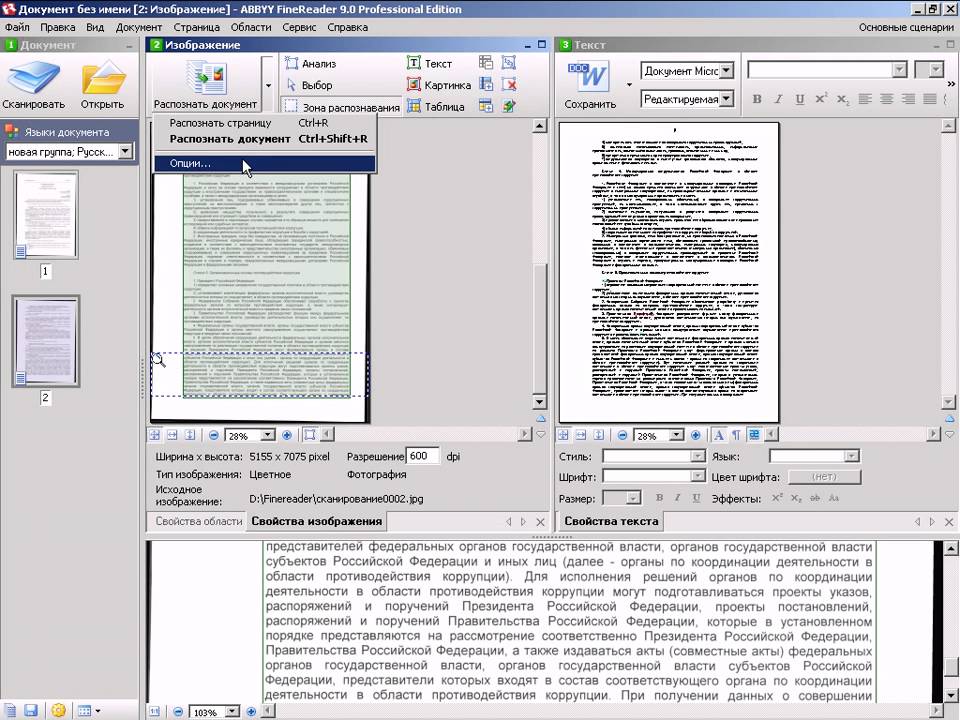 Казалось бы, выхода нет. На самом деле в интернете есть масса сервисов, способных определить шрифт по картинке онлайн. Мы расскажем вам о двух.
Казалось бы, выхода нет. На самом деле в интернете есть масса сервисов, способных определить шрифт по картинке онлайн. Мы расскажем вам о двух.
Давайте попробуем на двух самых известных площадках определить шрифт с этой картинки:
WhatFontIs
Этот бесплатный ресурс полностью на английском языке. Так что база латинских шрифтов там довольно широкая. А вот с русскими – напряжёнка. Для тех, кто не знает английского, мы подготовили небольшую инструкцию по использованию сервиса.
Итак, чтобы воспользоваться WhatFontIs с целью найти шрифт по картинке, сохраните изображение с понравившимся начертанием или сделайте скриншот страницы и вырежьте нужный фрагмент. Проследите, чтобы картинка была в формате jpg, png или gif и не превышала 1,8 мб. Теперь следуйте инструкции.
Совет: вместо того, чтобы загружать картинку, в нижнем поле можно вставить ссылку на неё.
Если сервис не смог определить шрифт, не отчаивайтесь. Разместите картинку на форуме сайта, где местные гуру обязательно помогут вам разобраться.
WhatTheFont
Ещё один англоязычный сервис для определения шрифта по картинке. Пытаться отыскать здесь кириллические начертания – трата времени. В базе WhatTheFont их попросту нет.
Мобильное приложение WhatTheFont
Мало кто знает, но у сервиса WhatTheFont есть приложение для определения шрифта по картинке на гаджетах от Apple. Это удобно, когда вам попалось на глаза, к примеру, объявление в газете, оформленное красивым шрифтом, или впечатлила вывеска на улице. Просто сфотографируйте текст, и приложение выполнит свою задачу.
В действительности способов, которые помогут определить шрифт онлайн, больше, чем два. Например, есть сервисы, которые вместо того, чтобы распознать шрифт по картинке, зададут вам тысячу и один вопрос о том, как выглядит искомое начертание (http://www.identifont.com/). Существуют и ресурсы, которые даже могут натренировать ваш глазомер так, что вы не хуже машины сможете распознавать множество шрифтов (http://ft.vremenno. net/en/). Однако WhatTheFont и WhatFontIs – пожалуй, самые удобные и популярные площадки для этой цели.
net/en/). Однако WhatTheFont и WhatFontIs – пожалуй, самые удобные и популярные площадки для этой цели.
Распознавание шрифтов с помощью глубокого обучения | Джехад Мохамед | MLearning.ai
Сканируется каллиграфия А.Это основано на DeepFont Paper, методе, созданном Adobe.Inc для обнаружения шрифта на изображениях с использованием глубокого обучения. Они опубликовали свою работу в виде документа для общественности, и реализованный код является производным от того же. В этом блоге обсуждаются необходимые шаги, а также дается обзор кода.
Ключевые точки DeepFont:
- Он обучен на наборе данных AdobeVFR, который содержит 2383 Шрифт Категории!
- Его CNN адаптирована к предметной области (Нажмите здесь, чтобы узнать больше)
- Его обучение основано на сжатии модели
Прежде чем мы начнем — давайте начнем с того, какие библиотеки нам нужны.
Из Matplotlib.pyplot Import Imshow
Импорт Matplotlib.cm AS CM
Импорт MATPLOTLIB.PYLAB AS
от KERAS.PYLAB AS
от KERS.PLABS .0006 ImageDataGenerator
import numpy as np
import PIL
from PIL import ImageFilter
import cv2
import itertools
import random
import keras
import imutils
из imutils импорт путей
импорт os
из keras импорт оптимизаторы
from keras.preprocessing.image import img_to_array
from sklearn.model_selection import train_test_split
from keras.utils import to_categorical
from keras import callbacks
from keras.models import Sequential
from keras.layers.normalization import BatchNormalization
from keras.layers Импорт Плотный, выпадающий, выбросить
из Keras.layers Import Conv2d, MaxPooling2d, Upsampling2d, Conv2dtranspose
с Ceras Import .Will Will Will Will Will Will Will in
Will Will Will Will Will Will in
.
Will Will Will Will in
.
. манипулировать изображениями, давайте возьмем PIL (библиотеку изображений Python) и создадим функцию для чтения изображения из каталога и изменения размера по мере необходимости.
 деф pil_image(img_path):
деф pil_image(img_path):
пил_им = пил . Изображение . открыть (img_path) . convert('L')
pil_im = pil_im . resize((105,105))
#imshow(np.asarray(pil_im))
return pil_imТеперь мы разобьем всю работу на 4 шага или этапа.
Шаг 1: Набор данных
Поскольку ссылка на набор данных AdobeVFR имеет огромный размер и содержит множество категорий шрифтов, простой способ обойти это — создать собственный набор данных на основе необходимых исправлений шрифтов с помощью TextRecognitionDataGenerator github.
Когда у вас есть набор образцов, вы готовы к работе!
Шаг 2: Предварительная обработка данных
Шрифты не похожи на объекты, и для классификации их функций требуется огромная пространственная информация. Чтобы определить очень незначительное изменение характеристик, DeepFont использует определенные методы предварительной обработки, а именно:
- Шум
- Размытие
- Перспективное вращение
- Затенение (градиентное освещение)
- Переменный интервал между символами
- Переменное соотношение сторон
Исходя из этого — у нас есть функции для каждого из шагов аугментации:
def Noise_image(pil_im):ASARRAY (PIL_IM)
# Добавление шума к изображению
Среднее = 0,0 # Некоторая постоянная
Std = 5 # Некоторая постоянная (стандартное отклонение)
NOISY_IMG = IMG_ARRAY + NP .случайное . нормальное (среднее, станд., img_array . форма)
noisy_img_clipped = np . клип(noisy_img, 0, 255)
шум_img = PIL . Изображение . fromarray(np . uint8(noisy_img_clipped))
шум_изображения = шум_изображения . resize((105,105))
return Noise_img
def blur_image(pil_im):
#Добавление размытия к изображению
blur_img = pil_im3 .
filter(ImageFilter . GaussianBlur(радиус = 3))
blur_img = blur_img . resize((105,105))
return blur_img
def affine_rotation(img):
строк, столбцов = img . shapepoint1 = np .
float32([[10, 10], [30, 10], [10, 30]])
point2 = np . float32([[20, 15], [40, 10], [20, 40]])A = cv2 . getAffineTransform(point1, point2)
вывод = cv2 . warpAffine(img, A, (столбцы, строки))
affine_img = PIL . Изображение . fromarray (np . uint8 (выход))
affine_img = affine_img . resize((105,105))
return affine_img
def градиент_fill(изображение):
лапласиан = cv2 . Лапласиан (изображение, cv2 . CV_64F)
лапласиан = cv2 . изменение размера (лапласиан, (105, 105))
return laplacian
Теперь, когда они готовы, мы можем подготовить набор данных.
data_path = "font_patch/" #Ссылка на все созданные образцы случайный . семян(42)
случайных . shuffle(imagePaths)#Это были 5 шрифтов, взятых за образец def conv_label(label):
IF Метка == 'LATO':
Возврат 0
ELIF Метка == 'Raleway':
return 1
ELIF Label == 'Roboto':
7 ELIF = 'Roboto'
ELIF = = ':
70003 . return 2
ELIF Метка == 'Sansation':
return 3
ELIF Метка == 'Проходная дорожка':
return 4augument = ["Blur" ","аффинный","градиент"]
a = itertools .комбинаций (дополнение, 4)
для i в list(a):
print(list(i))
Теперь, основываясь на a, мы перебираем изображения, используя только что сгенерированные комбинации, добавляя вывод данных и меток каждый раз.
counter = 0
для imagePath в imagePaths:
label = imagePath . split(os . path . sep)[ - 2]
Метка = conv_label (метка)
PIL_IMG = PIL_IMAGE (ImagePath)
#IMSHOW (PIL_IMG)#Добавление оригинального изображения
org_img = Img_to_RARAP )
данные . append(org_img)
ярлыков . добавить(метка)дополнить = ["шум","размытие","аффинный","градиент"]
для l в диапазоне (0,len(дополнение)):a = itertools .
для I в списке (A):
Комбинации = Список (I)
Печать (LEN (Комбинации))
TEMP_IMG = PIL_IMG
)
TEMP_IMG = 669 Для J в Комбинациях:, если J == 'Noise':
# Добавление шума изображения
Temp_img = rower_image (temp_img)ELIF J .0003 == 'Blur':
# Добавление изображения размытия
Temp_img = BLUR_IMAGE (TEMP_IMG)
#IMSHOW (BLUR_IMG)ELIF j == 'Affine Offine:
77 ELIF j == ' Affine '
77 elif j == 9000' affine '7 . нп . Array (PIL_IMG)
# Добавление аффинного ротационного изображения
Temp_img = Affine_Rotation (OPEN_CV_AFFINE)ELIF J == 'GRADIENT':
array(pil_img)
OPEN_CV_GRADIent = Н.
# Добавление градиентного изображения добавить (temp_img)
меток . append(label)
Наш следующий шаг очень прост — мы разделяем данные, чтобы мы могли использовать 75% для обучения и оставшиеся 25% для тестирования. Затем мы конвертируем метки из целых чисел в векторы.
данные = нп . asarray(data, dtype = "float") / 255.0
labels = np . array(метки)
print("Успех")(trainX, testX, trainY, testY) = train_test_split(данные,
меток, test_size = 0,25, random_state = 42)trainY3 =
3 trainY, num_classes = 5)
testY = to_categorical(testY, num_classes = 5)авг = ImageDataGenerator(rotation_range = 30, width_shift_range = 0.
. классификации сети CNN, они следовали новой схеме, такой как две подсети,
- Низкоуровневая подсеть : извлечены из составного набора синтетических и реальных данных.
- Подсеть высокого уровня : Изучает глубокий классификатор на низкоуровневых функциях. Для получения более подробной информации и пояснений прочитайте их документ
Мы создаем модель, как указано в документе, и компилируем ее.
K.set_image_data_format('channels_last') def create_model():
модель = Sequential() # Cu Layers
модель . добавить(Conv2D(64, размер ядра = (48, 48), активация = 'relu', input_shape = (105,105,1)))
модель . добавить(Пакетная нормализация())
модель . добавить(MaxPooling2D(pool_size = (2, 2)))
модель . добавить(Conv2D(128, размер ядра = (24, 24), активация = 'relu'))
модель . добавить(Пакетная нормализация())
модель . добавить(MaxPooling2D(pool_size = (2, 2)))
модель . add(Conv2DTranspose(128, (24,24), шаги = (2,2), активация = 'relu', заполнение = 'такой же', kernel_initializer = 'однородный'))
модель . добавить(UpSampling2D(размер = (2, 2)))
модель . add(Conv2DTranspose(64, (12,12), шаги = (2,2), активация = 'relu', заполнение = 'то же самое', kernel_initializer = 'униформа'))
модель . add(UpSampling2D(size = (2, 2)))
#Cs Layers
модель . добавить(Conv2D(256, размер ядра = (12, 12), активация = 'relu'))
модель . добавить(Conv2D(256, размер ядра = (12, 12), активация = 'relu'))
модель . добавить(Conv2D(256, размер ядра = (12, 12), активация = 'relu'))
модель . добавить(свести())
модель . add(Dense(4096, активация = 'relu'))
модель . добавить(Выпадение(0.5))
модель . добавить(Dense(4096,активация = 'relu'))
модель . добавить(Выпадение(0.5))
модель . add(Dense(2383,активация = 'relu'))
модель . add(Dense(5, активация = 'softmax'))
return model
batch_size = 128
epochs = 50
model= create_model()
sgd = tensorflow.keras.optimizers.SGD1(l. , распад = 1e-6, импульс = 0,9, нестеров = True)
model.compile (потеря = 'mean_squared_error', оптимизатор = sgd, metrics = ['точность']) Early_stopping = обратных вызовов . Раннее (Монитор = 'val_loss', min_delta = 0, терпение = 10, Verbose = 0, режим = 'мин.) контрольная точка = обратных вызовов . ModelCheckpoint(путь к файлу, монитор = 'val_loss', подробный = 1, save_best_only = True , режим = 'мин')
callbacks_list = pping]0007
Теперь мы подогнали модель и проверили на потери и точность.
модель . FIT (Trainx, Trainy, Shuffle = True ,
BATCH_SIZE = BATCH_SIZE,
EPOCHS = EPOCHS,
VERBOSE = 1,
Validation_DATA = (TESTX, TELTY),
Validation_DATA = (testx, testy), callbacks = (testx, testy), callbacks = (testx, testy), callbacks = (testx, testy), callbacks wardation_data = (testx, testy). )счет = модель . оценить(testX, testY, verbose = 0)
print('Потеря теста:', оценка[0])
print('Точность теста:', оценка[1])
Потеря теста: 0,1341324895620346
Точность теста: 0,6410256624221802
Шаг 4: рамка
в качестве прототипа, мы используем KERAS.
из keras.
модель = load_model('top_model.h5')
оценка = модель . оценить(testX, testY, verbose = 0)
print('Потеря теста:', оценка[0])
Печать («Точность теста:», оценка [1])
Потеря теста: 0,12708203494548798
Точность теста: 0,5833333134651184
Теперь We Trake A We Trak To Do Do Do Do Do Do Do Do Do Do Do Do Do Do Do Do Do Do Do Do Do Do Do Do Do Do Do результаты, достижения!img_path="sample/sample.jpg"
pil_im =PIL.Image.open(img_path).convert('L')
pil_im=blur_image(pil_im)
org_img = img_to_array(pil_im) def rev_conv_label(метка) :
если метка == 0:
Возврат 'Lato'
ELIF Метка == 1:
Возврат 'Raleway'
ELIF Лейбл == 2:
return ' ELIF Метка == 3:
Возврат 'Sansation'
ELIF Метка == 4:
Данные 'Walwway'data = []
Data .
данные = np . asarray(data, dtype = "float") / 255.0y = model.predict(data)
y = np.round(y).astype(int)label = rev_conv_label(y[0,0 ]))
рис, ax = plt . участков (1)
акселерометров . imshow(pil_im, интерполяция = 'ближайший', cmap = см . серый)
ах . text(5, 5, label , bbox = {'facecolor': 'white', 'pad': 10})
plt . show()
Вот и все, ребята! Распознавание шрифтов с помощью DeepFont.
Mlearning.ai Предложения по подаче заявок
Как стать писателем на Mlearning.ai
medium.com
7 лучших бесплатных приложений OCR для преобразования изображений в текст
Автор Сайкат Басу
Обновлено
Делиться Твитнуть Делиться Электронная почта
Хотите бесплатное программное обеспечение для распознавания текста? В этой статье собраны семь лучших программ, которые превращают изображения в текст.
Изображение предоставлено: nikolay100/DepositphotosЕсли вы хотите преобразовать печатный текст или рукописный текст в цифровую копию, вам не нужно делать это вручную. Вам даже не нужно тратить целое состояние на профессиональные инструменты. Мы покажем вам лучшие программы OCR (оптическое распознавание символов), которые бесплатно конвертируют изображения в текст.
Что такое OCR?
Программное обеспечение для оптического распознавания символов (OCR) преобразует изображения или даже рукописный текст в текст. Инструменты OCR анализируют документ и сравнивают его со шрифтами, хранящимися в их базе данных, и/или отмечая характерные черты символов. Некоторые приложения OCR также используют проверку орфографии, чтобы «угадать» нераспознанные слова. Трудно достичь 100% точности, но максимальное приближение — это то, к чему стремится большинство программ.
OCR может помочь студентам, исследователям и офисным работникам ускорить работу. Итак, давайте поиграем еще с несколькими и найдем лучшее программное обеспечение для распознавания текста для ваших нужд.
1. OCR с помощью Microsoft OneNote
Microsoft OneNote имеет расширенные функции распознавания текста, которые работают как с изображениями, так и с рукописными заметками.
- Перетащите отсканированное изображение или сохраненное изображение в OneNote. Вы также можете использовать OneNote для вырезания части экрана или изображения в OneNote.
- Щелкните правой кнопкой мыши на вставленном изображении и выберите Копировать текст с изображения .
- Скопированный оптически распознанный текст попадает в буфер обмена, и теперь вы можете вставить его обратно в OneNote или в любую программу, например Word или Блокнот.
OneNote также может извлекать текст из многостраничной распечатки одним щелчком мыши. Вставьте многостраничную распечатку в OneNote, а затем щелкните правой кнопкой мыши текущую выбранную страницу.
- Нажмите Копировать текст с этой страницы распечатки для захвата текста только с этой выбранной страницы.
- Нажмите Копировать текст со всех страниц распечатки , чтобы скопировать текст со всех страниц за один раз, как показано ниже.
Обратите внимание, что точность распознавания также зависит от качества фотографии. Вот почему оптическое распознавание рукописного текста все еще немного нечеткое для OneNote и других программ OCR на рынке. Тем не менее, это одна из ключевых функций OneNote, которую вы должны использовать при каждой возможности.
2. SimpleOCR
это скриншот интерфейса SimpleOCR Проблема, с которой я столкнулся при распознавании рукописного ввода с помощью инструментов Microsoft, могла быть решена с помощью SimpleOCR. Но программное обеспечение предлагает распознавание рукописного ввода только в качестве 14-дневной бесплатной пробной версии. При этом машинное распознавание отпечатков не имеет никаких ограничений.
Программное обеспечение неуклюжее и выглядит устаревшим, так как оно не обновлялось с версии 3.1, но вы все равно можете попробовать его из-за его простоты.
- Настройте чтение напрямую со сканера или путем добавления страницы (форматы JPG, TIFF, BMP).
- SimpleOCR предлагает некоторый контроль над преобразованием с помощью функций выделения текста, изображения и игнорирования текста.
- Преобразование в текст переводит процесс в этап проверки ; пользователь может исправить неточности в преобразованном тексте с помощью встроенной проверки орфографии.
- Преобразованный файл можно сохранить в формате DOC или TXT.
SimpleOCR хорошо работал с обычным текстом, но его обработка макетов с несколькими столбцами разочаровала. На мой взгляд, точность преобразования инструментов Microsoft была значительно лучше, чем SimpleOCR.
Скачать : SimpleOCR для Windows (доступны бесплатные и платные версии)
3. Сканирование фотографий
Photo Scan — это бесплатное приложение для оптического распознавания символов Windows, которое можно загрузить из магазина Microsoft Store. Приложение, созданное Define Studios, представляет собой OCR-сканер и считыватель QR-кода в одном лице.
Укажите приложению изображение или распечатку файла. Вы также можете использовать веб-камеру вашего ПК, чтобы передать изображение для просмотра. В отличие от нескольких других инструментов, описанных в этой статье, Photo Scan не работает с PDF-файлами. Распознанный текст отображается в соседнем окне.
Преобразование текста в речь является основным моментом . Щелкните значок динамика, и приложение прочитает вслух то, что оно только что отсканировало.
С рукописным текстом дело обстоит не очень хорошо, но с распознаванием печатного текста все в порядке. Когда все будет сделано, вы можете сохранить текст OCR в нескольких форматах, таких как текст, HTML, форматированный текст, XML, формат журнала и т. д.
Загрузка: Сканирование фотографий (бесплатная покупка в приложении)
4. (a9t9) Бесплатное приложение OCR для Windows
(a9t9) Бесплатное программное обеспечение OCR — это приложение для универсальной платформы Windows, что означает, что вы можете использовать его на любом своем устройстве Windows. Существует также онлайн-эквивалент OCR, основанный на том же API.
(a9t9) поддерживает 21 язык для анализа ваших изображений и преобразования PDF в текст. Приложение также можно использовать бесплатно, а поддержку рекламы можно отключить с помощью покупки в приложении. Как и большинство бесплатных программ OCR, это идея для печатных документов, а не для рукописного текста.
Загрузка: a9t9 Free OCR (бесплатная покупка в приложении)
5. Capture2Text
Capture2Text — это бесплатное программное обеспечение для распознавания текста для Windows, в котором есть сочетания клавиш для быстрого распознавания всего, что происходит на экране. Это также исполняемый файл, который не требует установки.
Используйте сочетание клавиш по умолчанию WinKey + Q , чтобы активировать процесс OCR. Затем вы можете использовать мышь, чтобы выбрать часть, которую вы хотите захватить. Нажмите Введите , чтобы активировать оптическое распознавание символов. Захваченный и преобразованный текст появится во всплывающем окне и по умолчанию также будет доступен в буфере обмена.
Capture2Text использует механизм распознавания текста Google и поддерживает более 100 языков. Он использует Google Translate для преобразования захваченного текста на другие языки. Проверьте меню на панели инструментов Windows, чтобы получить доступ к Настройки , включить или выключить сохранение в буфер обмена или переключить язык OCR по умолчанию.
Скачать : Capture2Text (бесплатно)
6. OCR сканирования изображения
Это приложение Microsoft Store отлично подходит для пакетной обработки файлов с помощью OCR. Он использует дизайн с тремя столбцами: папка с файлами слева, выбранный файл посередине и распознанный текст справа. Image Scan OCR поддерживает изображения и PDF-файлы. Он не дал каких-либо разборчивых результатов для образцов почерка, поэтому придерживайтесь только печатного текста.
При первом запуске вам нужно будет выбрать папку через пункт меню OpenFolder . Вы также можете установить язык для улучшения распознавания текста. Когда мы открывали папки с большим количеством файлов, приложение становилось довольно медленным, поэтому мы рекомендуем выбрать пустую папку и перетаскивать в нее файлы по ходу дела. Когда вы нажимаете BatchProcess , OCR сканирования изображений обрабатывает все файлы в текущей папке. После того как вы обработали изображение или документ, вы можете отредактировать результат в правом столбце, а затем скопировать его или сохранить в текстовый файл.
Загрузка: OCR сканирования изображений (бесплатно)
7.
OCR с Документами GoogleЕсли вы находитесь вдали от своего компьютера, попробуйте возможности OCR Google Диска. Документы Google имеют встроенную программу OCR, которая может распознавать текст в файлах JPEG, PNG, GIF и PDF. Но все файлы должны быть 2 МБ или меньше, а текст должен быть 10 пикселей или больше.
Google Диск также может автоматически определять язык в отсканированных файлах, хотя точность с нелатинскими символами может быть невысокой.
- Войдите в свою учетную запись Google Диска.
- Нажмите Создать > Загрузка файла . Кроме того, вы также можете нажать Мой диск > Загрузить файлы .
- Перейдите к файлу на вашем ПК, который вы хотите преобразовать из PDF или изображения в текст. Нажмите кнопку Открыть , чтобы загрузить файл.
- Документ теперь находится на вашем Google Диске. Щелкните документ правой кнопкой мыши и выберите Открыть с помощью > Документы Google .
- Google преобразует ваш PDF-файл или файл изображения в текст с помощью OCR и открывает его в новом документе Google. Текст доступен для редактирования, и вы можете исправить те части, где OCR не смог его правильно прочитать.
- Вы можете скачать доработанный документ в нескольких форматах, поддерживаемых Google Диском. Выберите из меню File > Download as .
Бесплатное программное обеспечение для распознавания текста, которое вы можете выбрать
В то время как бесплатные инструменты были адекватны печатному тексту, они не работали с обычным рукописным текстом. Лично я отдаю предпочтение использованию оптического распознавания символов Microsoft OneNote, потому что вы можете сделать его частью рабочего процесса создания заметок.
Photo Scan — это универсальное приложение Магазина Windows, которое поддерживает разрывы строк в различных форматах документов, в которые можно сохранять документы. Но не позволяйте вашему поиску бесплатных конвертеров OCR заканчиваться на этом. Существуют альтернативные способы распознавания изображений и текста.
9 методов распознавания шрифтов (онлайн и офлайн!)
Блог Учебники
07 июн, 2021 07 июня, 2021
- Каролина Артуффо
Некоторые типы шрифтов очень различимы, но ни один из шрифтов не содержит подписи! Вам наверняка попадался очень интересный и оригинальный шрифт, который вы хотели бы использовать для какого-нибудь проекта. Но как найти его в Интернете?
К счастью, технология достаточно продвинута и больше не нужно пытаться найти такой же шрифт или более похожий на тот, который мы ищем.
Существует
системы отслеживания шрифтов , которые могут начать с простого изображения (типа jpg) и сравнить его со своей внутренней базой данных, показав наиболее близкий шрифт или наилучшее соответствие.Поэтому в этой статье я раскрою все самые полезные инструменты для распознавания шрифтов по изображению!
Эта программа является настоятельно рекомендуемым инструментом. Для его работы требуется загрузить четкое изображение шрифта (его можно получить с помощью такого инструмента, как Greenshot или просто обрезав его со скриншота).
Программа строгая и требует точного кадрирования изображения, на котором есть шрифт. Запущенный поиск Fontidentifier покажет все родственные шрифты и похожие на тот, который мы искали, подсказав, где найти и скачать искомые шрифты как бесплатно, так и платно.
Если вы заинтересованы в распознавании шрифта, начинающегося с jpg, WhatThefFont.com — это сайт для вас. Нужно заранее знать, что есть правила, которым нужно следовать, нужно убедиться, что:
- Высота букв должна быть 100 пикселей
- Изображение должно быть как можно более горизонтальным
- Буквы нельзя трогать, а символы должны быть на большом расстоянии друг от друга
- Избегайте слишком размытых изображений из-за увеличения
Затем программа загрузит на экран несколько похожих шрифтов, чтобы выбрать наиболее подходящий. Если результат неудовлетворителен, вы все равно можете перейти на форум сайта, где специалисты по типографике вручную найдут шрифт, который вы хотели использовать!
Likefont работает. Как и на других сайтах, Likefont позволяет загружать изображение и искать все шрифты, которые на него похожи. Как только поиск активируется, вам будет представлена серия поисковых запросов по связанным шрифтам, которые напоминают шрифт вашего образца изображения, с процентами, указывающими степень совпадения. Эта система также позволяет распознавать символы азиатских языков.
Whatfontis — выдающийся инструмент для онлайн-распознавания шрифтов. Просто подпишитесь, чтобы вас отправили на страницу, где вы можете загрузить изображение, на котором есть надпись определенным шрифтом, который вас интересует.
Интересно то, что Whatfontis позволяет вам загрузить его как расширение Chrome, а также позволит вам распознавать шрифты, представленные на веб-сайте, по URL-адресу, а также с помощью изображения.
Reddit , для тех, кто с ним не знаком, это один из крупнейших форумов и новостных сайтов в мире; вы можете найти все, и по этой причине я хочу представить это в этом руководстве по поиску шрифтов по изображению, так как существуют различные группы и страницы, посвященные поиску шрифтов и типографике.
Для этого просто подпишитесь на одну из соответствующих групп на Reddit, внимательно прочитайте их правила, а затем опубликуйте изображение, шрифт которого вы хотите экстраполировать. Множество специалистов по шрифтам и экспертов наберется терпения, чтобы помочь вам бесплатно!
Одним из самых интересных каналов на Reddit для этой цели является https://www.reddit.com/r/identifythisfont/, который имеет почти 100 000 подписчиков и может похвастаться хорошим репертуаром экспертов по шрифтам, интересующихся миром типографики!
Quora чем-то похож на Reddit, Quora также является забитым сайтом. Когда загрузка изображения для распознавания шрифта на одном из автоматизированных сайтов не работает, Quora одним из первых размещает свое изображение и ждет ответа или совета от эксперта по шрифтам.
Font Matcherator позволяет загружать различные типы изображений, логотипов и скриншотов, позволяя сайту искать шрифты, похожие на то, что вы ищете.
Разве вы не получили большое удовольствие от использования онлайн-систем поиска шрифтов? Если вам нужно профессиональное решение, давайте поговорим о том, как распознать шрифт с помощью Фотошоп . Эта функция является базовой и интегрирована в последние версии программы.
Импортируйте изображение, содержащее искомый шрифт, в Photoshop. В этот момент откройте текстовое меню и найдите пункт «Найти похожий шрифт» . На этом этапе, если необходимо, постарайтесь точно определить слово, чтобы программа могла выполнить более полный поиск.
На этом этапе вам будет показан список шрифтов, похожих на отсканированный, среди которых вы можете выбрать для загрузки, если они доступны в библиотеке Adobe.
Fontedge — еще одна система автоматического распознавания шрифтов по изображению, очень рекомендуемая. Также в этом случае просто вооружитесь jpg или скриншотом, загрузите его и программа сама найдет для нас наиболее похожие шрифты.
Многие из этих онлайн-методов распознавания шрифтов требуют, чтобы вы делали точные изображения или скриншоты некоторых слов, содержащих рассматриваемый шрифт. Лично я часто использую Greenshot , бесплатную программу для Windows для создания макроса, который с помощью простой кнопки позволяет выбрать точную область экрана (даже с помощью лупы). Затем изображение можно перенести и скопировать в любую графическую программу!
Вы ищете полностью индивидуальный шрифт для своего специального проекта? На протяжении многих лет мы имели удовольствие сотрудничать с графическими дизайнерами шрифтов со всего мира, целью которых является создание персонализированных шрифтов! Напишите нам для получения дополнительной информации.
Использование диспетчера шрифтов
Учебное пособие
Бесплатная пробная версия
Загрузить ресурсы
См. дополнительные руководства
Узнайте о диспетчере шрифтов, отдельном приложении, входящем в состав CorelDRAW Graphics Suite. Ознакомьтесь с интерфейсом приложения и узнайте, как с помощью библиотек и коллекций легко управлять библиотекой шрифтов и поддерживать порядок шрифтов.
Спасибо за просмотр! Мы надеемся, что вы нашли это руководство полезным, и мы хотели бы услышать ваши отзывы в разделе «Комментарии» внизу страницы. Вы найдете письменную версию этого руководства ниже, а копию в формате PDF для печати можно загрузить на вкладке «Загрузить ресурсы» выше.
Узнайте, что нового в CorelDRAW Graphics Suite!
Загрузите БЕСПЛАТНУЮ 15-дневную пробную версию для Windows или Mac и разожгите свой творческий огонь новыми инструментами перспективы, гибким пространством для дизайна, прогрессивными инструментами редактирования фотографий и многим другим.
Загрузите бесплатную пробную версию
Загрузите следующие бесплатные ресурсы:
Письменное руководство (PDF, 576 КБ)
Ресурсы CorelDRAW Technical Suite 9
Руководство пользователя PHOTO-PAINT (PDF, 26 МБ)
Инструменты, которые вам нужны
CorelDRAW Graphics Suite
Креативность сочетается с производительностью в CorelDRAW Graphics Suite: профессиональном наборе инструментов для векторной иллюстрации, компоновки, редактирования фотографий и типографики.
Осенний клипарт
Украсьте свои фотографии, изображения, коллажи и многое другое с помощью этой коллекции из более чем 240 осенних клипартов в PNG и векторном формате.
Стандарт CorelDRAW 2021
Мечтайте, а затем проектируйте с помощью CorelDRAW Standard 2021 — универсального пакета графического дизайна для любителей и домашнего бизнеса.
Электронная книга «50 советов и рекомендаций»
Этот набор кратких советов и практических примеров поможет вам максимально эффективно использовать CorelDRAW и вывести свои дизайнерские работы на новый уровень.
Corel Font Manager — это отдельное приложение, входящее в состав CorelDRAW Graphics Suite (Windows и Mac). Он работает с CorelDRAW и Corel PHOTO-PAINT для поиска, фильтрации, организации и управления шрифтами. В этом уроке мы будем использовать версию для Windows, однако приложение работает одинаково на обеих платформах.
Щелкните любое из изображений ниже, чтобы просмотреть его в полном размере.
Интерфейс диспетчера шрифтов
Диспетчер шрифтов можно запустить с помощью собственного значка или для пользователей Windows непосредственно из CorelDRAW или PHOTO-PAINT через средство запуска приложений. Интерфейс имеет панель инструментов и 3 основных раздела: панель Библиотеки , панель Предварительный просмотр и панель Свойства .
Панель предварительного просмотра
В области предварительного просмотра , шрифты организованы в семейства шрифтов и имеют цветную полосу, указывающую на состояние шрифта :
- Зеленый — установленный шрифт или семейство шрифтов
- Зеленый со значком замка — защищенный системный шрифт или семейство шрифтов
- Желтый — шрифт или семейство шрифтов не установлено, доступно только в CorelDRAW и Corel PHOTO-PAINT
- Серый — семейство шрифтов, содержащее как установленные, так и неустановленные шрифты
Каждый шрифт также имеет символ технологии шрифта:
- O для шрифтов OpenType
- T для шрифтов TrueType
- A для шрифтов Type 1
По умолчанию каждый шрифт отображается под своим именем. В верхней части панели Preview вы можете ввести образец текста в окне Preview Font , чтобы увидеть, как каждый шрифт выглядит с определенными символами. Названия шрифтов снова появляются, когда вы очищаете окно Preview Font .
Также есть окно Поиск в верхней части окна Предварительный просмотр , которую можно использовать для поиска определенного шрифта.
Количество шрифтов в вашей системе отображается в левом нижнем углу панели Предварительный просмотр , а в правом нижнем углу вы можете использовать ползунок Изменить размер для изменения размера экрана.
Установка, удаление и удаление шрифтов
Диспетчер шрифтов позволяет устанавливать и удалять один или несколько шрифтов, а также целые семейства шрифтов. Вы можете удалить шрифты, которые вам больше не нужны, чтобы предотвратить беспорядок.
Выберите шрифт на панели Предварительный просмотр , а затем используйте значки на панели инструментов для установки, удаления или удаления шрифта. Вы также можете получить доступ к этим командам, щелкнув правой кнопкой мыши шрифт или в меню Font .
ПРИМЕЧАНИЕ : Шрифты, используемые операционной системой, защищены и не могут быть удалены или удалены.
Управление повторяющимися шрифтами
Ваши папки или коллекции могут содержать дубликаты одного и того же шрифта. На это указывает значок в правом верхнем углу рядом с символом технологии шрифта.
Вы можете показать все повторяющиеся шрифты, а затем удалить ненужные.
- Используйте кнопку Duplicate Fonts на верхней панели инструментов, чтобы переключаться между отображением и скрытием повторяющихся шрифтов в
- Вы также можете получить доступ к команде Show/Hide Duplicate Fonts , щелкнув правой кнопкой мыши любой шрифт в на панели Preview или в разделе Font
- Используйте фильтр Duplicates в Состояние шрифта категория фильтра на панели Библиотека для отображения только повторяющихся шрифтов на панели Preview
Панель свойств
справа на панели Свойства .
ПРИМЕЧАНИЕ : если Свойства0004 не отображается, нажмите кнопку Показать свойства шрифта на верхней панели инструментов.
В верхней части панели Свойства щелкните значок, чтобы просмотреть:
- Набор глифов для предварительного просмотра и фильтрации доступных глифов для выбранного шрифта; или
- Подробности , чтобы просмотреть подробную информацию о шрифте, такую как версия, технология, кодовая страница, дизайнер и т. д.
В области Glyph Filters вы можете использовать флажки, чтобы отфильтровать список Glyph Preview , чтобы отображались только числа, валюта или символы и т. д. Шрифты OpenType также будут иметь определенные функции OpenType, такие как различные стилистические наборы, доступные в качестве параметров фильтрации.
В списке Glyph Preview нажмите маленькую стрелку, чтобы развернуть раздел Подробности глифа , который включает такую информацию, как имя, идентификатор глифа, нажатие клавиши и т. д.
Количество глифов для выбранного шрифта отображается в нижнем левом углу панели Свойства, а рядом с ним находится ползунок Изменить размер для настройки размера отображаемого глифа.
Панель библиотек
Панель Библиотеки состоит из 3 разделов: Папки, Коллекции и Фильтры.
Папки
Папки позволяют легко получать доступ и отслеживать шрифты, находящиеся в одной папке. Папка по умолчанию в Менеджере шрифтов называется Мои шрифты . Он включает в себя все установленные шрифты Windows и все шрифты в ваших добавленных папках.
Чтобы добавить папку:
- Файл > Добавить папку ; или
- Нажмите значок Добавить папку на панели инструментов.
- Перейдите к папке со шрифтами и нажмите Выбрать папку .
- Теперь эта папка появится в диспетчере шрифтов.
Чтобы удалить папку, выберите папку в библиотеках , а затем:
- Перейти к Файл > Удалить папку или коллекцию ; или
- Нажмите значок Удалить на панели инструментов; или
- Щелкните папку правой кнопкой мыши и выберите Удалить папку или коллекцию .
Коллекции
Коллекции идеально подходят для быстрого доступа к шрифтам, которые находятся в разных папках. Например, вы можете создать коллекцию, включающую все шрифты, используемые в проекте, или коллекцию шрифтов определенного стиля, таких как скрипты.
Чтобы создать коллекцию:
- Перейдите к Файл > Добавить коллекцию или щелкните значок Добавить коллекцию на панели инструментов.
- Введите имя коллекции.
- Щелкните папку или другую коллекцию, чтобы отобразить список шрифтов и выбрать шрифт, который вы хотите добавить.
- Чтобы добавить шрифт в коллекцию:
- Перетащите его из панели предварительного просмотра в коллекцию; или
- Щелкните правой кнопкой мыши шрифт в Панель предварительного просмотра и выберите Добавить в коллекцию ; или
- Перейти к Шрифт > Добавить в коллекцию .
Чтобы удалить шрифт из коллекции, щелкните правой кнопкой мыши шрифт на панели предварительного просмотра и выберите Удалить из [название коллекции] . Вы также можете перейти к Шрифт > Удалить из [название коллекции] .
ПРИМЕЧАНИЕ : удаление шрифта из коллекции не приводит к удалению или удалению шрифта.
Фильтры
В разделе Фильтры можно выбрать определенные параметры для фильтрации того, что отображается на панели Предварительный просмотр , например состояние шрифта, стиль, функции OpenType и т. д.
Нажмите на стрелки рядом с категорией фильтра, чтобы открыть ее, затем выберите фильтры, которые вы хотите использовать. Вы можете использовать несколько фильтров одновременно.
Чтобы удалить отдельные фильтры, просто снимите с них флажки. Чтобы удалить все фильтров, нажмите кнопку Удалить фильтры шрифтов в правом верхнем углу раздела Фильтры .
Получение дополнительных шрифтов
Дополнительные шрифты можно загрузить из диспетчера шрифтов с помощью значка Получить больше на панели инструментов. В окне Получить больше вы можете найти множество новых пакетов шрифтов, некоторые из которых можно приобрести бесплатно, а некоторые - приобрести. Загруженные пакеты появятся в разделе Мои коллекции .
Узнайте, что нового в CorelDRAW Graphics Suite!
Загрузите БЕСПЛАТНУЮ 15-дневную пробную версию для Windows или Mac и зажгите свой творческий огонь новыми инструментами перспективы, гибким пространством для дизайна, прогрессивными инструментами редактирования фотографий и многим другим.
Загрузите бесплатную пробную версию
Как определить шрифт на изображении — Picozu
