Russian — Overleaf, Онлайн редактор LaTeX
Contents
- 1 Introduction
- 2 Russian example using pdfLaTeX
- 3 Background topics: characters and encodings
- 3.1 Text files: integers and characters
- 3.2 Input encoding: inputenc, UTF-8 and a change to LaTeX in 2018
- 3.3 Output encoding: the fontenc package (for use with pdfLaTeX)
- 4 Language-specific packages and commands
- 5 Hyphenation
- 6 A final example
- 7 Further reading
This article explores typesetting Russian text: enabling correct use of Cyrillic characters, such аs ц, ч, ш, щ, ъ etc., and providing support for language-specific features such as hyphenation. If you are looking for instructions on how to use more than one language in a single document, for instance English and Russian, see the International language support article.
We’ll start with the following pdfLaTeX example which you can open in Overleaf using the link below the code.
\documentclass{article}
\usepackage[T2A]{fontenc}
%Hyphenation rules
%--------------------------------------
\usepackage{hyphenat}
\hyphenation{ма-те-ма-ти-ка вос-ста-нав-ли-вать}
%--------------------------------------
\usepackage[english, russian]{babel}
\begin{document}
\tableofcontents
\begin{abstract}
Это вводный абзац в начале документа.
\end{abstract}
\section{Предисловие}
Этот текст будет на русском языке. Это демонстрация того, что символы кириллицы
в сгенерированном документе (Compile to PDF) отображаются правильно. Для этого Вы должны установить нужный язык (russian) и необходимую кодировку шрифта (T2A).
\vskip12pt
\textbf{Этот текст будет на русском языке. Это демонстрация того, что символы кириллицы в сгенерированном документе (Compile to PDF) отображаются правильно. }
\vskip12pt
\textit{Этот текст будет на русском языке. Это демонстрация того, что символы кириллицы в сгенерированном документе (Compile to PDF) отображаются правильно.}
\section{Математические формулы}
Кириллические символы также могут быть использованы в математическом режиме.
\begin{equation}
S_\textup{ис} = S_{123}
\end{equation}
\end{document}
}
\vskip12pt
\textit{Этот текст будет на русском языке. Это демонстрация того, что символы кириллицы в сгенерированном документе (Compile to PDF) отображаются правильно.}
\section{Математические формулы}
Кириллические символы также могут быть использованы в математическом режиме.
\begin{equation}
S_\textup{ис} = S_{123}
\end{equation}
\end{document}
Open this pdfLaTeX example in Overleaf
This example produces the following output:
The following sections provide background material on topics related to typesetting different languages using LaTeX (mostly related to pdfLaTeX).
Text files: integers and characters
Any text file, such as a LaTeX input .tex file, is nothing more than a stream of numeric (integer) values which are being used as a mechanism to represent characters of text; consequently, processing a text file involves scanning (reading/processing) a series of integer values. However, an important question arises:
Text files can be generated within innumerable computing environments: across different countries/continents, using a multitude of different devices, operating systems and editing tools.
Clearly, the producer (originator) and consumer (user) of textual data must, somehow, agree on the encoding (mapping) being used, otherwise 
Input encoding:
inputenc, UTF-8 and a change to LaTeX in 2018Historically, a variety of 8-bit encodings were used to generate/process text files, including LaTeX inputs. To cut short a very long story, the developers of LaTeX created the
However, over time, users/software developers moved away from multiple 8-bit encodings to using Unicode and its UTF-8 encoding scheme, which became the de facto option for encoding text files. Prior to 2018, to process UTF-8 encoded files LaTeX document preambles included the line
\usepackage[utf8]{inputenc}
Readers might observe that the example above does not include the line \usepackage[utf8]{inputenc} in the document preamble: why is that? This is due to an important change to LaTeX introduced in 2018: a switch to UTF-8 as the default  Documents typeset with pdfLaTeX, and using UTF-8 encoded text, including those created and typeset on Overleaf, no longer need to include
Documents typeset with pdfLaTeX, and using UTF-8 encoded text, including those created and typeset on Overleaf, no longer need to include \usepackage[utf8]{inputenc} but is does no harm to do so. For further information see the April 2018 issue of LaTeX News and the Overleaf blog post TeX Live upgrade—September 2019. All text files created on Overleaf are encoded using UTF-8.
Output encoding: the
fontenc package (for use with pdfLaTeX)To correctly typeset characters contained within input files, those characters need to be mapped to the appropriate fontenc.
To use fontenc include the following line in your document preamble, using an encoding, such as the T2A encoding, which supports the Cyrillic script:
\usepackage[T2A]{fontenc}
The following chart lists the T2A font encoding for Cyrillic text.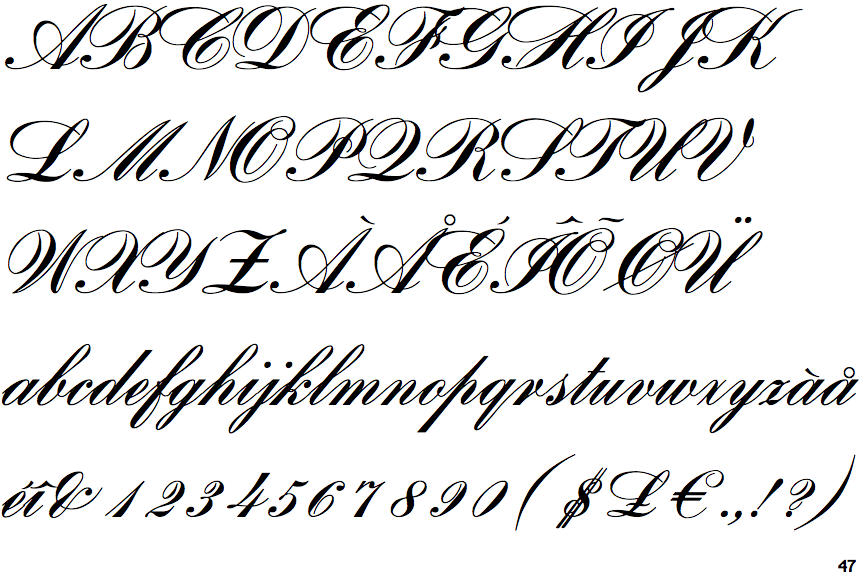 It is reproduced from page 23 of the document LaTeX font encodings which is available on CTAN.
It is reproduced from page 23 of the document LaTeX font encodings which is available on CTAN.
To extended the default LaTeX capabilities, for proper hyphenation and translating the names of the document elements, import the babel package and use the russian language option:
\usepackage[russian]{babel}
As you may see in the example in the introduction, instead of «Abstract» and «Contents» the Russian words «Аннотация» and «Содержание» are used. Cyrillic characters can also be used in mathematical mode.
If you need to include more than one language, for instance, Russian and English, see the International language support article to learn how to achieve this. A great deal of useful background information can be found in the document Russian language module for Babel.
To achieve linebreaks, some words have to be hyphenated: broken up into syllables separated by a - (hyphen), allowing the word to continue on the next line. For example, математика could become мате-мати-ка. The
For example, математика could become мате-мати-ка. The babel package usually does a good job of hyphenation but, occasionally, you may need to define hyphenation points manually, which you can do using these commands in the preamble:
\usepackage{hyphenat}
\hyphenation{мате-мати-ка восста-навливать}
\usepackage{hyphenat} imports the hyphenat package and the second line is a list of space-separated words with defined hyphenation points. If you want to prevent automatic hyphenation of a particular {\nobreak word} within your document.
This final example configures LaTeX so that the Russian text can be typeset using pdfLaTeX, XeLaTeX and LuaLuaTeX—to switch compilers on Overleaf, see the article Changing compiler.
This example uses the \iftutex command from the iftex package to detect whether a Unicode-aware engine (LuaTeX or XeTeX) is being used to compile the LaTeX code (document).
fontspec package and used to typeset the document. If a non-Unicode-aware engine, such as pdfTeX, is detected then the LaTeX code (document) is typeset using old 8-bit font technologies (based on Adobe Type 1).The following code opens on Overleaf and defaults to compiling with XeLaTeX. To use a different compiler, see the article Changing compiler.
\documentclass{article}
\usepackage{iftex}
\iftutex
% For LuaTeX or XeTeX Use Google's
% OpenType Noto fonts for typesetting
% Russian text
\usepackage{fontspec}
\defaultfontfeatures{Ligatures={TeX}}
\setmainfont{Noto Serif}
\setsansfont{Noto Sans}
\setmonofont{Noto Sans Mono}
\else
% For pdfTeX we must use old
% 8-bit font technologies
\usepackage[T2A]{fontenc}
\fi
%Hyphenation rules
\usepackage{hyphenat}
\hyphenation{ма-те-ма-ти-ка вос-ста-нав-ли-вать}
\usepackage[english, russian]{babel}
\begin{document}
Этот текст будет на русском языке. Это демонстрация того, что символы кириллицы в сгенерированном документе отображаются правильно. \vskip12pt
\textbf{Этот текст будет на русском языке. Это демонстрация того, что символы кириллицы в сгенерированном документе отображаются правильно.}
\vskip12pt
\textit{Этот текст будет на русском языке. Это демонстрация того, что символы кириллицы в сгенерированном документе отображаются правильно.}
\vskip12pt
\texttt{Этот текст будет на русском языке.}
\end{document}
\vskip12pt
\textbf{Этот текст будет на русском языке. Это демонстрация того, что символы кириллицы в сгенерированном документе отображаются правильно.}
\vskip12pt
\textit{Этот текст будет на русском языке. Это демонстрация того, что символы кириллицы в сгенерированном документе отображаются правильно.}
\vskip12pt
\texttt{Этот текст будет на русском языке.}
\end{document}
Open this example on Overleaf
Using XeLaTeX, this example produces the following output:
For more information see
- Supporting modern fonts with XƎLaTeX
- Typesetting quotations and quotation marks
- International language support
- Chinese
- French
- German
- Greek
- Italian
- Japanese
- Korean
- Portuguese
- Arabic
- Spanish
- Russian language module for Babel
- History of the T2A, T2B and T2C Cyrillic encodings
- The not so short introduction to LaTeX2ε
- LaTeX/Internationalization on WikiBooks
- LaTeX/Special_Characters on WikiBooks
Метод наипростейшей стенографии.
 Алфавит и шрифт для неё / Хабр
Алфавит и шрифт для неё / ХабрМногих отпугивает слово «стенография» и есть от чего, так как под этим подразумевается сложная система, которую не только длительно надо изучать, но и постоянно применять, чтобы был от этого толк. Я же предлагаю вам ознакомиться с наипростейшим методом записи русской устной речи с помощью упрощенных значков, что конечно не повысит в 2-4 раза скорость записи как в стенографии, но точно облегчит эту запись.
Для изучения алфавита требуется 30 минут (да, это точно и проверено на ученике 2 класса обычной школы), еще около часа желательно почитать что-то на этом алфавите, ну и само письмо придется нарабатывать на скорость в течение дня.
В отличие от стенографии, у которой упор сделан на скорость письма и значки могут отличаться размерами и занимать две клетки по высоте, в данном методе мы можем писать на каждой клетке тетради краткими символами, что не только экономит в 2 раза конспект, но экономит чернила и наши силы на выведение сложных знаков или соединений между ними.
Думаю, что многие уже догадались и разобрались, что написано на картинке выше. Криптографическая стойкость этой записи почти нулевая, хотя и позволит вам писать в метро что-то, что не сможет прочитать рядом сидящий (можно и печатать, если выставить временно определенный шрифт в документе). Зато обучится этому методу просто, быстро, а читать такой текст не сложно.
Значки можно изменить под себя, если вам что-то кажется не так и не то. Я же подобрал их с учетом похожести на уже известные русские или английские и чем чаще встречается буква в русских словах (оеаитнсрвлкм…), тем пытался её проще, а значит и быстрее, нарисовать. Обратите внимание на написание цифр, так как они должны рисоваться особо, чтобы не путать их с буквами.
Шрифт тут сделан не идеально хорошо, а больше для примера, чтобы вы могли понять метод, да и почитать что-то можно было с этим шрифтом. Скачать его можно тут:
шрифт «Arial Unicode MS_ST»
Запомнить алфавит в таком виде не сложно, так как есть похожесть по частичному рисованию (а), ж – половина от символа, как и о, т. Где-то это знакомо вам от английского языка (б, д, и), транскрипции (ш). Для символа н выбран крючок L, так как н очень часто встречаемый символ, а вот для символа м крючок смотрит назад, с него обычно мы начинаем написание рукописной м. Буква п как бы упавшая вперед и это тоже легко запомнить.
Где-то это знакомо вам от английского языка (б, д, и), транскрипции (ш). Для символа н выбран крючок L, так как н очень часто встречаемый символ, а вот для символа м крючок смотрит назад, с него обычно мы начинаем написание рукописной м. Буква п как бы упавшая вперед и это тоже легко запомнить.
Заглавные символы можно пробовать писать чуть крупнее или подчеркивать такие символы, как это принято в стенографии. Символы могут чуть отличаться на письме, если вам там проще. Допустим м и н можно писать с закруглением, а р наоборот ровно, как печатную русскую г (хотя допускаю и р не изменять, если вам так удобней и быстрей. Это же касается и буквы э). Чтобы отличать г и ч, надо бы редко употребляемую ч писать с закруглением в верхней части (хотя всю жизнь писали похоже и разбирали такой почерк). Букву л пишите как очень длинную единицу, чтобы отличить ее и от i и от цифры и от буквы т (для этого у т и есть прямой верх, а не под наклоном). Буквы б и д можете писать и как английские b и d с четкой окружностью внизу.
Старайтесь четкие прямые линии рисовать прямо, а полуокружность как у о, отличимо от прямой как у и. Чтобы проверить искажение почерка от скорости можно провести тест: пишите на каждой строчке одну букву из алфавита как можно быстрее наращивая скорость к концу строки. Потом сравните похожесть букв между собой. Если похожесть есть, то продумайте, что надо сделать, чтобы рисовать такие символы отличимо и быстро.
Критикам из общества поклонников стенографии сразу сообщаю, что метод разрабатывался исходя из поставленных задач и показатель скорости далеко не важный. Важно было получить метод сокращенного обозначения букв позволяющий писать в одну клеточку (в стенографии это не так), так как чем проще и мельче написанное, тем меньше сил тратят студенты при письме. При этом важно было писать буквы примерно одинаковые по высоте, чтобы легче это можно было прочитать, а то записи и так не крупные. Еще важная проблема – это влияние почерка на понимание написанного, а для этого отличимость букв от наклона и искажений в написании должна быть достаточной для понимания.
