Распознавание татарского текста — Convertio
Преобразование отсканированных документов и изображений на татарском языке в редактируемые форматы вывода Word, Pdf, Excel и Txt (простой текст)
Доступно страниц: 10 (Вы уже использовали 0 страниц)
Если вам нужно распознать больше страниц, пожалуйста, зарегистрируйтесь
Загрузите файлы для распознавания или перетащите их на эту страницу
Выберите файлы
Поддерживаемые форматы файлов:
pdf, jpg, bmp, gif, jp2, jpeg, pbm, pcx, pgm, png, ppm, tga, tiff, wbmp
Выберите все языки, используемые в документе
Выберите основной язык…ТатарскийАнглийский—————-АфрикаансАлбанскийАрабский (Саудовская Аравия)Армянский (восточный)Армянский (западный)Азербайджанский (Кириллица)Азербайджанский (Латиница)БаскскийБелорусскийБолгарскийКаталанскийСебуанскийКитайский упрощенныйКитайский традиционныйХорватскийЧешскийДатскийНидерландскийНидерландский (Бельгия)ЭсперантоЭстонскийФиджиФинскийФранцузскийГалисийскийНемецкийГреческийГавайскийИвритВенгерскийИсландскийИндонезийскийИрландскийИтальянскийЯпонскийКазахскийКиргизскийКонгоКорейскийКурдскийЛатинскийЛатышскийЛитовскийМакедонскийМалайский (Малайзия)МальтийскийНорвежский (Букмол)ПольскийПортугальскийПортугальский (Бразилия)РумынскийРусскийШотландскийСербский (Кириллица)Сербский (Латиница)СловацкийСловенскийСомалиИспанскийСуахилиШведскийТагальскийТаитиТаджикскийТайскийТурецкийТуркменскийУйгурский (Кириллица)Уйгурский (Латиница)УкраинскийУзбекский (Кириллица)Узбекский (Латиница)ВьетнамскийВаллийский
Выберите дополнительные языки. ..ТатарскийАнглийский—————-АфрикаансАлбанскийАрабский (Саудовская Аравия)Армянский (восточный)Армянский (западный)Азербайджанский (Кириллица)Азербайджанский (Латиница)БаскскийБелорусскийБолгарскийКаталанскийСебуанскийКитайский упрощенныйКитайский традиционныйХорватскийЧешскийДатскийНидерландскийНидерландский (Бельгия)ЭсперантоЭстонскийФиджиФинскийФранцузскийГалисийскийНемецкийГреческийГавайскийИвритВенгерскийИсландскийИндонезийскийИрландскийИтальянскийЯпонскийКазахскийКиргизскийКонгоКорейскийКурдскийЛатинскийЛатышскийЛитовскийМакедонскийМалайский (Малайзия)МальтийскийНорвежский (Букмол)ПольскийПортугальскийПортугальский (Бразилия)РумынскийРусскийШотландскийСербский (Кириллица)Сербский (Латиница)СловацкийСловенскийСомалиИспанскийСуахилиШведскийТагальскийТаитиТаджикскийТайскийТурецкийТуркменскийУйгурский (Кириллица)Уйгурский (Латиница)УкраинскийУзбекский (Кириллица)Узбекский (Латиница)ВьетнамскийВаллийский
..ТатарскийАнглийский—————-АфрикаансАлбанскийАрабский (Саудовская Аравия)Армянский (восточный)Армянский (западный)Азербайджанский (Кириллица)Азербайджанский (Латиница)БаскскийБелорусскийБолгарскийКаталанскийСебуанскийКитайский упрощенныйКитайский традиционныйХорватскийЧешскийДатскийНидерландскийНидерландский (Бельгия)ЭсперантоЭстонскийФиджиФинскийФранцузскийГалисийскийНемецкийГреческийГавайскийИвритВенгерскийИсландскийИндонезийскийИрландскийИтальянскийЯпонскийКазахскийКиргизскийКонгоКорейскийКурдскийЛатинскийЛатышскийЛитовскийМакедонскийМалайский (Малайзия)МальтийскийНорвежский (Букмол)ПольскийПортугальскийПортугальский (Бразилия)РумынскийРусскийШотландскийСербский (Кириллица)Сербский (Латиница)СловацкийСловенскийСомалиИспанскийСуахилиШведскийТагальскийТаитиТаджикскийТайскийТурецкийТуркменскийУйгурский (Кириллица)Уйгурский (Латиница)УкраинскийУзбекский (Кириллица)Узбекский (Латиница)ВьетнамскийВаллийский
Формат и настройки выбора
Документ Microsoft Word (.docx)Microsoft Excel Workbook (. xlsx)Microsoft Excel 97-2003 Workbook (.xls)Microsoft PowerPoint Presentation (.pptx)Searchable PDF Document (.pdf)Text Document (.txt)RTF Document (.rtf)CSV Document (.csv)Electornic Publication (.epub)Xml формат хранения книг (.fb2)DjVu Document (.djvu)
xlsx)Microsoft Excel 97-2003 Workbook (.xls)Microsoft PowerPoint Presentation (.pptx)Searchable PDF Document (.pdf)Text Document (.txt)RTF Document (.rtf)CSV Document (.csv)Electornic Publication (.epub)Xml формат хранения книг (.fb2)DjVu Document (.djvu)
Все страницы
Номера страниц
Как распознать текст на татарском языке?
Шаг 1
Загрузите изображения или PDF-файлы
Выберите файлы с компьютера, Google Диска, Dropbox, по ссылке или перетащив их на страницу
Шаг 2
Выберите выходной формат
Выберите .doc или любой другой формат, который вам нужен в результате (поддерживается больше 10 текстовых форматов)
Шаг 3
Конвертируйте и скачивайте
Нажмите «Распознать», и вы можете сразу загрузить распознанный текстовый файл на татарском языке
Сведения о таблице перевода на татарский язык
Сведения о таблице перевода на татарский языкТАТАРСКИЙ
Обозначение таблицы
тат
Это техническое описание таблицы перевода DBT. Если вам нужна более общая информация о языках и выборе шаблонов, см. список шаблонов.
Если вам нужна более общая информация о языках и выборе шаблонов, см. список шаблонов.
Изначально языковая таблица для перевода по Брайлю определяется выбранным шаблоном и может быть изменена с помощью меню Документ/Таблицы перевода. Использование этих меню не требует использования указателя таблицы. Однако, чтобы переключиться на другую таблицу перевода на полпути через файл, необходимо ввести код DBT и обозначение таблицы, на которую следует переключиться. Для переключения дополнительных языков в таблице базовых языков см. команду [lng~X]. Для переключения с одного базового языка на другой используйте команду [lnb~…].
Обзор функций
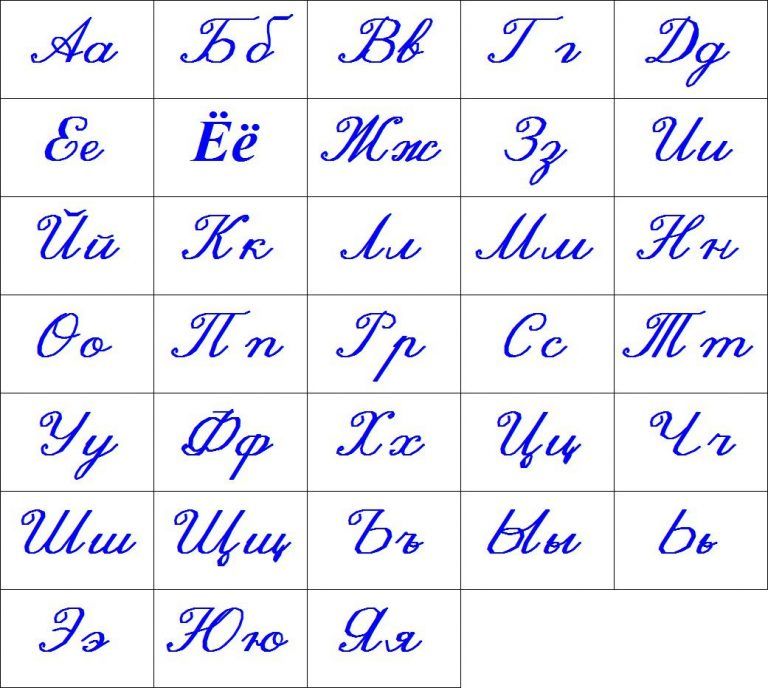
Таблицы на татарском языке поддерживают перевод с печати на шрифт Брайля литературных текстов на татарском языке, написанных кириллицей. Хотя они аналогичны русским, на самом деле существует 6 различных символов Брайля.
Они предназначены в первую очередь для использования в сочетании с Microsoft Word или эквивалентными внешними средствами для составления и редактирования печатного текста, который затем можно импортировать в переводчик Брайля Даксбери (DBT) для преобразования в шрифт Брайля.
Автоматический перенос шрифта Брайля (то есть автоматическое введение кодов вспомогательных переносов во время перевода на шрифт Брайля) поддерживается по умолчанию, хотя его можно включать и выключать с помощью кодов перевода.
Брайля для печати (обратный перевод)
Для этого языка поддерживается перевод шрифтом Брайля в печать. Однако перевод шрифта Брайля в печатный текст может быть неидеальным, поэтому помните о возможных ошибках. Если вы обнаружите ошибки или у вас есть предложения, отправьте файлы *.dxb и *.dxp вместе с объяснением по адресу: [email protected]. Пожалуйста, не забудьте включить образцы файлов!
Особые требования и ограничения
Несмотря на то, что DBT, начиная с версии 10. 5, может отображать кириллические и арабские символы, обычно удобнее использовать внешний текстовый процессор для составления и редактирования печатного текста, который необходимо перевести. При этом необходимо использовать средство, которое кодирует текст в Unicode, чтобы его можно было правильно импортировать в DBT. (Некоторые методы ввода кириллицы полагаются на вариант «шрифта» для отображения стандартных символов ASCII как кириллицы. Эти методы не могут использоваться, так как эти символы ASCII будут импортированы в соответствии с их стандартной интерпретацией, а не как символы кириллицы.)
5, может отображать кириллические и арабские символы, обычно удобнее использовать внешний текстовый процессор для составления и редактирования печатного текста, который необходимо перевести. При этом необходимо использовать средство, которое кодирует текст в Unicode, чтобы его можно было правильно импортировать в DBT. (Некоторые методы ввода кириллицы полагаются на вариант «шрифта» для отображения стандартных символов ASCII как кириллицы. Эти методы не могут использоваться, так как эти символы ASCII будут импортированы в соответствии с их стандартной интерпретацией, а не как символы кириллицы.)
Microsoft Word при правильном использовании соответствует указанным выше требованиям. Используйте шрифт Lucida Sans Unicode или эквивалентный шрифт Unicode и татарскую (или кириллицу, или арабскую) клавиатуру при вводе татарского текста.
Поддерживаемые дополнительные языки
Английский текст может быть введен как дополнительный язык и преобразован в несокращенный английский шрифт Брайля.
Можно ввести текст на французском языке; он набран как неконтрактный французский шрифт Брайля, включая заглавный индикатор из 46 точек.
Можно также ввести болгарский, казахский и украинский языки; они набраны так же, как и татарские.
Обратите внимание, что в дополнение к перечисленным выше «вторичным языкам», поддерживаемым в самой татарской таблице, также можно переключиться на любую из доступных таблиц перевода, перечисленных в DBT. (См. код [lnb~…] ниже.)
Поддерживаемые технические коды Брайля
Технические коды не поддерживаются.
Однако можно переключиться на любую из доступных таблиц перевода, перечисленных в DBT (см. код [lnb~…] ниже), многие из которых поддерживают различные технические коды, такие как математические или компьютерные обозначения, или которые поддерживают унифицированную обработку технических обозначений, а также художественного текста на базовом языке, связанном с таблицей.
Поддерживаемые коды трансляции DBT
Следующие коды перевода DBT доступны при использовании татарской таблицы. Любые другие используемые коды перевода будут игнорироваться или даже могут привести к неожиданным результатам. При использовании альтернативной таблицы перевода, т.е. при переключении на другую таблицу базового языка с помощью кнопки [ lnb~…], пожалуйста, обратитесь к соответствующему разделу и доступным кодам для этой таблицы.
[/] может быть встроен в группы букв, которые обычно сокращаются, чтобы предотвратить сокращение.
[ab] эквивалентно [g2]
[ahy] или [ahy1] включает автоматический перенос шрифта Брайля (что является начальным условием по умолчанию)
[ah0] отключает автоматический перенос шрифта Брайля.
[fte~b]
[fte~i]
[fte~u]
[фут~б]
[футов~i]
[fts~u]
[чт]
[g1] переключается на шрифт Брайля «класс 1» (несокращенный).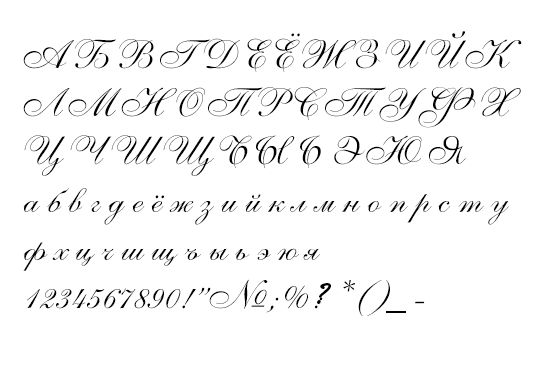 Это не имеет никакого эффекта в этой таблице, так как все шрифты Брайля в любом случае не сокращены.
Это не имеет никакого эффекта в этой таблице, так как все шрифты Брайля в любом случае не сокращены.
[g2] переключается на шрифт Брайля «класс 2» (сокращенный). Это обычный режим, но на самом деле он не имеет никакого эффекта, поскольку татарский и все второстепенные языки всегда транскрибируются без контракта.
[дюйм] эквивалентно [г1]
[руб]
[lnb~…] (для переключения на другую базовую [основную] языковую таблицу)
[lng~bg] переключает на болгарский язык.
[lng~en] переключает на английский язык.
[lng~fr] переключает на французский язык.
[lng~kk] или [lng] переключает на казахский язык.
[lng~ru] переключает на русский язык.
[lng~uk] переключает на украинский язык.
[tx] возобновляет нормальный перевод, заканчивая «прямой шрифт Брайля».
[vrn] отменяет [vrn~spc], восстанавливая нормальное подавление пробелов после запятых и точек с запятой.
[vrn~spc] сохраняет пробелы после запятых и точек с запятой, которые по умолчанию удалены в татарском шрифте Брайля.
Поддерживаемые символы
Таблица предназначена для работы со следующими группами символов:
Все печатные символы ASCII
Символы с диакритическими знаками и знаки препинания, характерные для французского, немецкого, итальянского и испанского языков
Знак британского фунта стерлингов ()
Несмотря на то, что DBT, начиная с версии 10.5, может отображать кириллические и арабские символы, обычно удобнее использовать внешний текстовый процессор для составления и редактирования печатного текста, который необходимо перевести. При этом необходимо использовать средство, которое кодирует текст в Unicode, чтобы его можно было правильно импортировать в DBT. (Некоторые методы ввода кириллицы полагаются на вариант «шрифта» для отображения стандартных символов ASCII как кириллицы. Эти методы не могут использоваться, так как эти символы ASCII будут импортированы в соответствии с их стандартной интерпретацией, а не как символы кириллицы.)
Эти методы не могут использоваться, так как эти символы ASCII будут импортированы в соответствии с их стандартной интерпретацией, а не как символы кириллицы.)
Вышеприведенное является только общим руководством (см. раздел «Общие примечания» в начале этого документа).
Ссылки, история и кредиты
Эти таблицы были первоначально основаны на информации, приведенной для казахского, русского и других поддерживаемых языков в «Использовании шрифта Брайля в мире», совместной публикации ЮНЕСКО и Национальной библиотечной службы для слепых и инвалидов, Вашингтон, округ Колумбия (1990). Согласно этой публикации, сокращения не используются в русском шрифте Брайля, поэтому в этих таблицах должен быть шрифт Брайля, нормальный для этой страны.
(Документация проверена: январь 2014 г.)
Транслитерация для малоресурсных текстов с переключением кода: создание автоматического преобразователя кириллицы в латиницу для татарского языка
Тихиро Тагучи, Юсуке Сакаи, Taro Watanabe
Abstract
Мы вводим транслитерацию кириллицы в латиницу для татарского языка, основанную на языковой идентификации на уровне подслов. Транслитерация является сложной задачей по следующим двум причинам. Во-первых, поскольку современные татарские тексты часто содержат внутрисловное переключение кода на русский язык, к каждой морфеме необходимо применять различный набор правил транслитерации в зависимости от языка, что требует языковой идентификации на уровне морфем. Во-вторых, тот факт, что татарский язык является малоресурсным, поскольку большая часть текстов написана на кириллице, затрудняет подготовку достаточного набора данных. Учитывая эту ситуацию, мы предложили метод транслитерации, основанный на идентификации языка на уровне подслов. Мы обучили языковой классификатор одноязычным татарскому и русскому текстам и применили различные правила транслитерации в соответствии с идентифицированным языком. Результаты показывают, что предложенный нами метод превосходит другие инструменты транслитерации татарского языка и подразумевает, что он в некоторой степени правильно транскрибирует русские заимствования.
Транслитерация является сложной задачей по следующим двум причинам. Во-первых, поскольку современные татарские тексты часто содержат внутрисловное переключение кода на русский язык, к каждой морфеме необходимо применять различный набор правил транслитерации в зависимости от языка, что требует языковой идентификации на уровне морфем. Во-вторых, тот факт, что татарский язык является малоресурсным, поскольку большая часть текстов написана на кириллице, затрудняет подготовку достаточного набора данных. Учитывая эту ситуацию, мы предложили метод транслитерации, основанный на идентификации языка на уровне подслов. Мы обучили языковой классификатор одноязычным татарскому и русскому текстам и применили различные правила транслитерации в соответствии с идентифицированным языком. Результаты показывают, что предложенный нами метод превосходит другие инструменты транслитерации татарского языка и подразумевает, что он в некоторой степени правильно транскрибирует русские заимствования.- Идентификатор антологии:
- 2021.
 CALCS-1.18
CALCS-1.18 - Том:
- ДУХОВ ПИТАЛЕТНОЙ СМЕРИИ ПО КОМПУНЦИОННУЮ ПЕРЕЧАТЬСЯ В ЛИНГИСТИЧЕСКОЙ КОДЕР
- МЕСЯЦ:
- июня
- MONOMS:
- июня
- :
- июня
- :
- июня
- :
- июня
- :
- .
- Online
- Место проведения:
- CALCS
- SIG:
- Издатель:
- Ассоциация компьютерной лингвистики
- Примечание: 909906 060132 133–140
- . Процитируйте (ACL):
- Тихиро Тагучи, Юсуке Сакаи и Таро Ватанабэ. 2021. Транслитерация для малоресурсных текстов с переключением кода: создание автоматического преобразователя кириллицы в латиницу для татарского языка. In Труды пятого семинара по вычислительным подходам к лингвистическому переключению кода , стр. 133–140, Интернет. Ассоциация компьютерной лингвистики.
- Процитируйте (неофициально):
- Транслитерация для малоресурсных текстов с переключением кода: Создание автоматического преобразователя кириллицы в латиницу для татарского языка (Тагучи и др.
 , CALCS 2021)
, CALCS 2021) - Копия цитирования:
- PDF:
- https://aclanthology.org/2021.calcs-1.18.pdf
PDF Процитировать Поиск
- BibTeX
- MODS XML
- Сноска
- Предварительно отформатированный
@inproceedings{taguchi-etal-2021-транслитерация,
title = "Транслитерация для малоресурсных текстов с переключением кода: создание автоматического конвертера {C}yrillic-to-{L}atin для {T}atar",
автор = "Тагучи, Тихиро и
Сакаи, Юсуке и
Ватанабэ, Таро».
booktitle = "Материалы пятого семинара по вычислительным подходам к лингвистическому переключению кода",
месяц = июнь,
год = "2021",
адрес = "Онлайн",
издатель = "Ассоциация вычислительной лингвистики",
url = "https://aclanthology.org/2021.calcs-1.18",
doi = "10.18653/v1/2021.calcs-1.18",
страницы = "133--140",
abstract = "Мы вводим кириллически-латинский транслитератор для татарского языка, основанный на идентификации языка на уровне подслов. Транслитерация является сложной задачей по следующим двум причинам. Во-первых, потому что современные татарские тексты часто содержат внутрисловный код- при переходе на русский язык к каждой морфеме необходимо применять различный набор правил транслитерации в зависимости от языка, что требует идентификации языка на уровне морфем Во-вторых, тот факт, что татарский является малоресурсным языком, большая часть текстов которого написана кириллицей. , затрудняет подготовку достаточного набора данных.В этой ситуации мы предложили метод транслитерации, основанный на идентификации языка на уровне подслов.Мы обучили языковой классификатор с одноязычными татарскими и русскими текстами и применили различные правила транслитерации в соответствии с идентифицированным языком , Результаты показывают, что предложенный нами метод превосходит другие инструменты татарской транслитерации, и подразумевают, что он правильно транскрибирует В некоторой степени русские заимствования.",
}
Транслитерация является сложной задачей по следующим двум причинам. Во-первых, потому что современные татарские тексты часто содержат внутрисловный код- при переходе на русский язык к каждой морфеме необходимо применять различный набор правил транслитерации в зависимости от языка, что требует идентификации языка на уровне морфем Во-вторых, тот факт, что татарский является малоресурсным языком, большая часть текстов которого написана кириллицей. , затрудняет подготовку достаточного набора данных.В этой ситуации мы предложили метод транслитерации, основанный на идентификации языка на уровне подслов.Мы обучили языковой классификатор с одноязычными татарскими и русскими текстами и применили различные правила транслитерации в соответствии с идентифицированным языком , Результаты показывают, что предложенный нами метод превосходит другие инструменты татарской транслитерации, и подразумевают, что он правильно транскрибирует В некоторой степени русские заимствования.",
}
0" encoding="UTF-8"?>
<моды> <информация о заголовке> Транслитерация для малоресурсных текстов с переключением кода: создание автоматического преобразователя кириллицы в латиницу для татарского языка <название типа="личное">Тихиро Тагучи <роль>автор <название типа="личное">Юске Сакаи <роль>автор <название типа="личное">Таро Ватанабэ <роль>автор <информация о происхождении>2021-06 текст <информация о заголовке> <аннотация>Мы вводим транслитерацию кириллицы в латиницу для татарского языка, основанную на языковой идентификации на уровне подслов.Материалы пятого семинара по вычислительным подходам к лингвистическому переключению кода <информация о происхождении>Ассоциация компьютерной лингвистики <место>Онлайн публикация конференции Транслитерация является сложной задачей по следующим двум причинам. Во-первых, поскольку современные татарские тексты часто содержат внутрисловное переключение кода на русский язык, к каждой морфеме необходимо применять различный набор правил транслитерации в зависимости от языка, что требует языковой идентификации на уровне морфем. Во-вторых, тот факт, что татарский язык является малоресурсным, поскольку большая часть текстов написана на кириллице, затрудняет подготовку достаточного набора данных. Учитывая эту ситуацию, мы предложили метод транслитерации, основанный на идентификации языка на уровне подслов. Мы обучили языковой классификатор одноязычным татарскому и русскому текстам и применили различные правила транслитерации в соответствии с идентифицированным языком. Результаты показывают, что предложенный нами метод превосходит другие инструменты транслитерации татарского языка и подразумевает, что он в некоторой степени правильно транскрибирует русские заимствования.
taguchi-etal-2021-transliteration 10. <местоположение>18653/v1/2021.calcs-1.18
https://aclanthology.org/2021.calcs-1.18 <часть> <дата>2021-06 <единица экстента="страница">133 140
%0 Материалы конференции Транслитерация %T для малоресурсных текстов с переключением кода: создание автоматического преобразователя кириллицы в латиницу для татарского языка %A Тагучи, Тихиро %А Сакаи, Юсукэ %A Ватанабэ, Таро %S Материалы пятого семинара по вычислительным подходам к лингвистическому переключению кода %D 2021 %8 июня %I Ассоциация компьютерной лингвистики %С онлайн %F taguchi-etal-2021-транслитерация %X Мы вводим транслитератор кириллицы в латиницу для татарского языка, основанный на идентификации языка на уровне подслов. Транслитерация является сложной задачей по следующим двум причинам. Во-первых, поскольку современные татарские тексты часто содержат внутрисловное переключение кода на русский язык, к каждой морфеме необходимо применять различный набор правил транслитерации в зависимости от языка, что требует языковой идентификации на уровне морфем.Во-вторых, тот факт, что татарский язык является малоресурсным, поскольку большая часть текстов написана на кириллице, затрудняет подготовку достаточного набора данных. Учитывая эту ситуацию, мы предложили метод транслитерации, основанный на идентификации языка на уровне подслов. Мы обучили языковой классификатор одноязычным татарскому и русскому текстам и применили различные правила транслитерации в соответствии с идентифицированным языком. Результаты показывают, что предложенный нами метод превосходит другие инструменты транслитерации татарского языка и подразумевает, что он в некоторой степени правильно транскрибирует русские заимствования. %R 10.18653/v1/2021.вычисления-1.18 %U https://aclanthology.org/2021.calcs-1.18 %U https://doi.org/10.18653/v1/2021.calcs-1.18 %Р 133-140
Markdown (неофициальный)
[Транслитерация для малоресурсных текстов с переключением кода: создание автоматического преобразователя кириллицы в латиницу для татарского] (https://aclanthology.