Шрифты под старину русский. Церковно-славянские шрифты
В своём знаменитом очерке «Украшение и преступление» 1908-го года модный тогда архитектор Адольф Лоос писал: «Развитие культуры влечёт за собой вытеснение орнаментальности из оформления повседневных вещей». Этим утверждением он исключал множество вычурных декоративных шрифтов, разработанных на протяжении прошлых столетий, из применения в дизайне высокого класса. А теперь быстренько вернёмся в наши дни: в Web 3.0 полно почти ровных шрифтов без засечек и классических прямых шрифтов, поэтому дизайнерам так не хватает излишеств книгопечатников былых времён.
Возьмите на вооружение мощную выразительность антикварных шрифтов и придайте вашей графике очарование старины, очень модное сейчас и в печатных, и в онлайн-проектах. От ковбойского и викторианского стилей до авангарда и каллиграфии — выбор весьма широк. Шрифты сгруппированы произвольно, современные интерпретации могут соседствовать с (почти) подлинными прототипами. Все они доступны бесплатно для применения в частных проектах, только, пожалуйста, не забывайте внимательно читать лицензионные соглашения.
Имитации оттисков с деревянных досок и плакатные шрифты
Этот напоминающий дешёвые оттиски с деревянных досок шрифт не лишён своего шарма: от него веет блёклыми афишами захудалого театрика. Вид в равной степени мрачный и вызывающий, подходит для графики на сюжеты от неформальных до пугающих.
Circus Ornate Дитера Штеффманна (Dieter Steffmann) создаёт то же настроение, что и классическая графика на цирковые сюжеты, но сохраняет своеобразие в качестве орнаментального, броского плакатного шрифта.
— (похож на шрифт Rosewood)
Разработанный в подражание таким шрифтам как Rosewood и Ponderosa, которые, в свою очередь, напоминают плакатные шрифты конца 18 века, Coffee Tin оживляет старинную рекламную графику, осовременивая её чёткостью линий.
—
Ещё один прекрасный псевдо-антикварный шрифт, созданный на основе плакатных литер19 века. Typeology foundry позаимствовали и само начертание, и название у шрифта, разработанного в 1884 году Д. Т. Эймсом (D.T. Ames).
Т. Эймсом (D.T. Ames).
—
Ещё один псевдо-антикварный шедевр Дитера Штеффманна (Dieter Steffmann), Egyptienne Zierinitialen, превращает двухмерные буквы в роскошную объёмную резьбу.
—
Прелестный винтажный шедевр от Jester Font Studio.
—
Nasty — состаренный «ремикс», созданный Эдуардо Ресифи (Eduardo Recife) из шрифта Extra Ornamental, разработки House of Lime. Выпущен в двух вариантах, которые Ресифи также советует применять в сочетании друг с другом.
—
Разработчик ПО со свободной лицензией Дэвид Раковский (David Rakowski) создал этот шрифт в 1991 г. Спустя 17 лет, гармония монументальности и изящества в его очертаниях выглядит сенсацией из прошлого, которая сегодня производит неизгладимое впечатление.
—
Tuscan Рика Мюллера (Rick Mueller) — один из его многих винтажных шрифтов, который, однако, выделяется из общей массы затейливостью контуров в сочетании с весомой простотой. Этот шрифт напоминает антикварные плакатные литеры без лишних завитушек.
Этот шрифт напоминает антикварные плакатные литеры без лишних завитушек.
—
Явное подобие Sideshow, разработки Harold’s Fonts, Fusty Saddle — вручную нарисованный, а затем оцифрованный шрифт ковбойского стиля. Bittbox предлагает вам не только гарнитуру своего шрифта, но и пояснение к нему: «fusty», как сказано на сайте автора, означает «старомодный и по сути, и с виду».
—
Цифровая версия оттиска с деревянной доски с явным стилистическим привкусом Дикого Запада, разработанная Мэтью Остином Пэтти (Matthew Austin Petty) из Disturbed Type. Словно заросшие ковбойской щетиной, грубо стёсанные края и неряшливые поверхности блочных элементов придают этому шрифту особый старинный налёт мужественности.
—
Продукт независимой студии цифровой полиграфии Fountain, Azteak сочетает в себе отголоски прошлого с мечтами о будущем. На механистическую основу этого шрифта наложены разные украшения, что навевает ассоциации с научно-фантастическими фильмами об альтернативном будущем в эпоху паровых машин.
—
Название этого шрифта — производное от фразы «ангел-хранитель» на французском языке, и его прописные буквы, действительно, венчаются фигурами крылатых стражей. Сочетание изящества и прочности контуров AngeGardien, общее у него с другими качественными винтажными шрифтами, возможно, и есть то самое, что стоит сохранить.
Антические и ренессансные шрифты
Подлинный шрифт 18 века кеслон (Caslon) мог бы сейчас выглядеть как Caslon Antique: слегка потёртым по краям, но не утратившим твёрдости. Данная интерпретация классического Caslon с засечками добавляет тексту взрослость и авторитетность без потери отчётливости.
—
Dominican — ещё один искусственно состаренный антикварный шрифт, причём, очень своеобразный, очертания которого навеяны особой прелестью старинных книг.
—
Необычный, состоящий из одних заглавных, шрифт Old Dog New Tricks вызывает интерес тем, что нижние элементы его, в принципе, классических букв с засечками опущены под линию строки.
—
Разработанный Дэвидом Дж. Пэрри (David J. Perry) в 2003 году, Cardo предназначался для учебных пособий по классическим языкам и средневековой письменности. Остроконечные буквы этого шрифта напоминают как почерк летописцев, так и надписи, выбитые на камнях.
Старопечатные и каллиграфические шрифты
Прерывистая линия строки и выцветшие буквы могли бы придать ему неопрятный вид, но этот шрифт достаточно устойчив, чтобы вписаться в любую разметку, не поддающуюся выравниванию, ему под стать.
—
Подобие шрифта названия фильма П. Т. Эндерсона (P.T. Anderson) 2007-го года, данный пример наглядно демонстрирует примесь ковбойского стиля к традиционному готическому начертанию.
—
Olde English — интересный образец шрифта, который, несмотря на его принадлежность одному времени и месту, сумели легко связать с другим. Хотя его начертание напоминает средневековые немецкие готические шрифты, Olde English, вообще-то, назван термином, обозначающим древнеанглийский язык, на котором писали островным минускулом.
—
Шрифт Schwabacher получил название от немецкой деревни Schwabach, а начертание — от каллиграфического почерка летописцев. Хотя с 17 века им лишь изредка пользовались в Германии, он оказал огромное влияние на историю книгопечатания.
—
Fraktur широко применялся в печатном деле в Германии даже на протяжении 20-го века, и встречается во множестве вариаций. Fette Fraktur — степенная, разрежённая версия, разборчивая для привычного к шрифту «антиква» читателя, не теряющая при этом отчётливости очертаний.
—
Шрифт, разработанный, чтобы вызвать ностальгию по времени зарождения бейсбола, когда стадионы ещё называли в честь соседних населённых пунктов и людей. Он — как винтажные бейсбольные майки, такой же броский и жёсткий в равной мере.
Он — как винтажные бейсбольные майки, такой же броский и жёсткий в равной мере.
—
Wrexham Script — более плотный и угловатый шрифт, выработанный надписями на спортинвентаре, с примесью винтажности.
—
В изобилии имитаций рукописного почерка, представленных в сети, легко теряется связь между обычным безымянным образцом начертания и его предками из прошлых столетий, посредством применения которых, а часто и их профессионального совершенствования, он сформировался. ALS Script, пропорциональный и изящный, является достойным продолжением своей династии: его очертания напоминают почерк писарей в официальных инстанциях 18 и 19 веков.
—
Вопреки неприятию орнаментальности господином Лоосем, вычурная декоративность Adine Kirnberg не мешает ни его разборчивости, ни его применимости. Этот грамотно разработанный курсив с лёгким намёком на антикварность годится не только для приглашений на свадьбу.
—
Прямой курсив, в равной мере геометрически правильный и орнаментальный. В контурах Ecolier заметны отголоски стиля ар-деко, но в их основу, видимо, легли тонкие изгибы каллиграфии вместе с устремлёнными ввысь формами творений современной инженерной мысли.
—
По словам дизайнера Билли Арджела (Billy Argel), идею шрифта Olho de Boi подсказала первая почтовая марка, выпущенная в Бразилии 1 августа 1843 года. Характерные штрихи и завитки придают символам этого шрифта вид букв, скопированных прямо из старых писем.
— («Каракули скелета на карте кладоискателя»)
Может быть всего один Международный день устного пиратского сленга, но почему бы не писать по-пиратски хоть четырежды в неделю? Этот шрифт назван очень точно: закорючки в стиле пиратских историй напоминают размытые водой рукописные пометки с карты затерянного острова сокровищ.
Шрифты стилей модерн и ар-деко
Fletcher Gothic от Casady & Greene — шрифт стиля модерн с чёткими контурами и поразительной тонкостью отделки: привнесите особое ощущение рубежа 19-20 столетий в свою графику нового века.
—
Изгибы очертаний этого шрифта напоминают растительные мотивы контуров модерна. Hadley оживляет текст, придавая ему налёт старины без потери современной актуальности.
—
Если бы Альфонс Муха (Alphonse Mucha) разрабатывал шрифты, он бы придумал Secesja. Затейливо изогнутые засечки и растительный узор придают буквам настроение радости жизни.
—
В начале 20-го века Чарльз Дана Гибсон (Charles Dana Gibson) прославился перьевыми набросками женщин в корсетах и с высокими причёсками, известными с тех пор как «Девушки Гибсона». Trinigan, с его волнистыми поперечными элементами и силуэтами в форме песочных часов, оживляет те классические образы в виде печатных символов.
Русский гражданский шрифт. 1708–1958 62
выпуску книг светского характера сосредоточивалась во вновь органи¬
зованной императорской типографии Академии наук, указы печатались
в типографии Сената, а издание церковных книг, ранее печатавшихся
в московском Печатном Дворе и петербургской типографии Александро-
Невской лавры, было сосредоточено в Москве в синодальной типо¬
графии.
Таким образом, привилегия печатания гражданских книг была за¬
креплена за организованной в 1727 году типографией Академии наук.
При Петре до организации типографии Академии наук было выпу¬
щено около 400 названий гражданских книг. В послепетровский период
до 1740 года вышло около 175 названий. Издательская деятельность осо¬
бенно развилась в царствование Елизаветы: с 1741 по 1761 год было вы¬
пущено 612 изданий, не считая выпуска календарей, «Ведомостей» и
других периодических изданий.
Приведенные данные позволяют судить о размахе типографско-
издательской деятельности ведущей русской типографии XVIII века —
типографии Академии наук.
По разносторонности и интенсивности издательской деятельности
типография Академии наук соперничала с ведущими типографиями
Запада. Не случайно поэтому, что до конца XVIII века под влиянием
типографии Академии наук находились все другие русские типографии,
как столичные, так и провинциальные (правительственные и частные).
Они заимствовали у нее не только шрифты и типографское оборудова¬
ние, но и квалифицированные типографские кадры.
Освещая развитие типографского дела в России первой половины
XVIII века, необходимо выделить вопрос о развитии словолитного
дела, в частности, в типографии Академии наук.
Известно, что со времени возникновения книгопечатания в России
шрифты резались и отливались в Москве. Известны, в частности, имена
таких граверов XVII века, как Осип Кириллов, Кондратий Иванов,
Никита Фофанов, Федор Иванов, иеродиакон Арсений. Все они были
талантливыми мастерами и умели отливать шрифты. Шрифты даже
получали названия по именам граверов, которые их делали. Так по¬
явились азбуки осиповская, никитская, арсеньевская и др. х.
При Петре I шрифты нарезали и отливали в Москве Михаил Ефремов,
Григорий Александров и Василий Петров. Во вновь организованной
типографии в Петербурге гражданские шрифты отливались бывшими
учениками московской типографии Петром Григорьевым и Иваном Оси¬
повым. В петербургской типографии с 1714 по 1722 год было отлито
В петербургской типографии с 1714 по 1722 год было отлито
8 азбук, кроме немецкой и латинской 2.
1 А. А. Сидоров, указ. соч., стр. 84.
2 А. В. Гаврилов, указ. соч., стр. 4, прим. 1;стр. 181, прим. 2. Здесь, по
всей вероятности, имеется в виду отливка литер с готовых матриц.
118
При устройстве типографии Академии наук латинские шрифты вы¬
писывались из Гамбурга. Первые русские шрифты были в основном оте¬
чественного производства. С 1726 года, как об этом свидетельствуют
источники, русские люди пунсоны делать и литеры отливать научились
не хуже иноземцев V С 40-х годов в русском граверном искусстве сфор¬
мировались такие крупные мастера, как Иван Соколов, Григорий Ка¬
чалов и другие, которые создали замечательную школу по гравирова¬
нию литер. Эта школа сосредоточивалась при Академии наук. Согласно
штатному списку служащих Академии, в словолитной типографии в
середине XVIII века с учениками значилось около 50 граверов 2 (правда,
не все граверы словолитни гравировали литеры). Не удивительно по¬
Не удивительно по¬
этому, что типография Академии наук, начиная с 1740 года, создавала
оригинальные образцы шрифтов, отличавшиеся чистотой отделки. По¬
сылая в 1776 году образец академических литер в Москву для отливки,
синод предписал сделать их «такие точно чистотой и исправностью, как
образцы значатся» 3. Не только правительственные типографии, как
Петербургская синодальная типография, Московского университета
и др., но и частные, как, например, типография Гартунга, отливали в
1771 году шрифты по образцу академических. Однако шрифты эти по
рисунку и отливке, в особенности у Гартунга, были явно хуже акаде¬
мических.
Мы провели графический анализ шрифтов по книгам петровского и
послепетровского периодов. В рисунке гражданского шрифта сущест¬
венных изменений не произошло до конца 30-х годов. В этот период
можно установить три вида гражданского шрифта 4.
К первому виду относится шрифт, которым была напечатана «Гео-
метриа» в 1708 году. Этот шрифт был рассмотрен нами в третьей главе.
Этот шрифт был рассмотрен нами в третьей главе.
Он существовал до 1710 года, т. е. до того времени, когда Петр I утвер¬
дил гражданскую азбуку.
В соответствии с утвержденным образцом азбуки появился второй
вид гражданского шрифта. Основное отличие его от первого заключа¬
лось в начертаниях букв р, ц, щ, п, ъ, ы, ь, ѣ. Кроме того, были вне¬
сены следующие изменения: вместо буквы «зело», которая имела на¬
чертания латинского s, стали применять букву з «земля»; кроме буквы
ѳ стали применять букву ф; вместо круглого строчного начертания
буквы д применяли прописное ее начертание; строчные буквы ь, ы
часто не были выступающими. Впоследствии в отдельных шрифтах
1 П. Пекарский, Академическая типография в старину и ныне (Предис¬
ловие к образцам шрифтов типографии Академии наук, Спб., 1870).
2 Д. А. Р о в и н с к и й, Подробный словарь русских граверов, стр. 197—206.
3 А. В. Гаврилов, указ. соч., стр. 226.
4 При анализе не затрагивался буквенный состав азбуки, который часто ме¬
нялся.
119
Библиотека
В разделе представлены книги о шрифтах, каталоги и альбомы
Альбом картографических шрифтов, Труды ЦНИИГАиК, 1956 г.
Альбом писаных и печатных шрифтов, М.А.Нетыкса, 1906 г.
Альбом шрифтов Земской типографии, Симферополь, 1904-1910 гг.
Библиография русских типографских шрифтов, В.Я.Адарюков, 1924 г.
Библиография русских типографских шрифтов, В.Я.Адарюков, 1924 г. (e-book) Rab-book
Искусство книги, А.А.Сидоров, 1922 г.
История русского орнамента. Музей Строгановского училища, 1868 г.
Картотека шрифтов по ГОСТ-1947, ВНИТО Полиграфии и Издательств.
Книжная корректура, Н.Н.Филиппов, 1929 г.
Книжный шрифт, М.В.Большаков, 1964 г.
Краткие сведения по типографскому делу, П.Коломнин, 1899 г.
Начертание шрифтов,Т.И.Куцын, 1950 г.
Новый русскiй шрифтъ В.Машiнъ, 1906 г.
Образцовые шрифты Военной типографии, 1821 г.
Образцы писмен Императорской Академии наук, 1862 г.
Образцы славяно-русского книгопечатания с 1491 года, 1891 г.
Образцы словолитни И. Щербакова в С.-Петербурге, 1881 г.
Образцы текстовых машинных шрифтов линотипа, Ленинград, 1938 г.
Образцы художественных шрифтов и рамок, А.А.Котляров, 1929 г.
Образцы шрифта словолитни и стереотипии Пиуса Бауер в Варшаве, 1888 г.
Образцы шрифтов (Типография и Переплетная) Ю.А.Мансфельдъ, 1904 г.
Образцы шрифтов 4-й типографии им.Е.Соколовой, 1956 г.
Образцы шрифтов, Генеральный штаб РККА, 1937 г.
Образцы шрифтов, Графические мастерские Академического издательства, 1923 г.
Образцы шрифтов и рамок для чертежей и планов, А.Д.Демкин, 1924 г.
Образцы шрифтов и украшений типографии А. И. Вильборга, б.г.
Образцы шрифтов ИАН — «Отче наш» и другие тексты на 325 языках и наречиях, 1870 г.
Образцы шрифтов С.-Петербургской Синодальной типографии, 1902 г.
Образцы шрифтов типо-литографии Сибирского Т-ва Печатного Дела, б.г.
Образцы шрифтов типографии А.Траншеля, 1876 г.
Образцы шрифтов типографии Астраханского губернского правления, 1886 г.
Образцы шрифтов типографии МХ Можайского УИКа, 1926 г.
Образцы шрифтов Типографии Центросоюза, б.г.
Оформление книги — Руководство по подготовке рукописи к печати, Л.И.Гессен, 1935 г
Оформление советской книги, Г.Г.Гильо, Д.В.Константинов, 1939 г.
Полиграфический орнамент В.1, Глаголь, 1991 г.
Полиграфический орнамент В.2, Глаголь, 1991 г.
Построение шрифтов, Я.Г.Чернихов Н.А.Соболев, 2005 г.
Руководство к изучению ленточного(Рондо) шрифта, А.И.Печинский, 1917 г.
Русский типографский шрифт. Вопросы истории и практика применения, А.Г.Шицгал, 1974 г.
Самоучитель каллиграфии и скорописи, С.Вольченка, 1902 г.
Сборник старинно русских и славянских букв, К.Д.Далматов, 1895 г.
Словолитни О. И. Лемана в С.-Петербурге и Москве, Каталог шрифтов, 1915(?) г.
Словолитня О. О. Гербек. Шрифты и орнаменты, 19?? г.
Собрание шрифтов. Составил и издал Михаил Маймистов, 1912
Современный шрифт, В.Тоотс, 1966 г.
Художественные шрифты, А. М.Иерусалимский, 1930 г.
М.Иерусалимский, 1930 г.
Шрифт, Б.В.Воронецкий Э.Д.Кузнецов, 1967 г.
Шрифт в наглядной агитации, С.И.Смирнов, Издание третье,1990 г.
Шрифты и Алфавиты, О.В.Снарский, 1979 г.
Шрифты для надписей на чертежах, М.Д.Микеладзе, 1961 г.
Шрифты для проектов, планов и карт, А.С.Шулейкин, 1987 г.
Шрифты и их построение, Д.А.Писаревский, 1927 г.
Шрифты и шрифтовые работы, В.В.Грачев, б.г.
Шрифты типографские, ОНШ, ред. А.Н.Стрелкова, 1974 г.
Шрифты. Разработка и использование, Г.М.Барышников, 1997 г.
Шрифты. Учебно-методическое пособие для курсантов ЛВВТКУ, Н.А.Шашурин, 1981 г.
Эстетика искусства шрифта, А.Капр, 1979 г.
Filmed at the Joh.Enschede foundryCarl Dair at Enschede the last days of metal type
Carl Dair’s 1957 Film — Gravers & Files (без перевода)Printing & Typesetting: Linotype — 1960
Видео YouTube: Tomorrow Always Comes
Устройство и работа линотипной машины (без перевода)«Типография XIX века»
Репортаж о работе старейшей типографии
Таджикистана«Придворная московская типография»
Репортаж о типографии издательства ИЗВЕСТИЯ выполняющей спецзаказы для руководства страныЭкскурсия в типографию
Процесс изготовления книги
УСТАВ, ПОЛУУСТАВ, ВЯЗЬ или ИЖИЦА, ЕВАНГЕЛИЕ, ФИТА, РУССКИЙ СУВЕНИР
«. ..Советские ученые, руководствуясь указанием классиков марксизма-ленинизма о том, что письменность возникает на последнем этапе существования первобытнообщинного строя, когда начинается процесс его разложения, связывают причины и потребности в появлении письменности с внутренними процессами исторического развития: разложением первобытнообщинного строя, складыванием антагонистических классов, развитием производительных сил и образованием государственности…»
..Советские ученые, руководствуясь указанием классиков марксизма-ленинизма о том, что письменность возникает на последнем этапе существования первобытнообщинного строя, когда начинается процесс его разложения, связывают причины и потребности в появлении письменности с внутренними процессами исторического развития: разложением первобытнообщинного строя, складыванием антагонистических классов, развитием производительных сил и образованием государственности…»
отрывок из вступительной статьи к любой книги по типографике, изданной в лучшие времена
Если последовать указаниям классиков из эпиграфа к этой статье и связать текущую ситуацию на рынке шрифтовых продуктов и технологий с социально-политической ситуацией в стране, то хорошим определением сегодняшнего дня будет «смутное время». Мы живем в кругу сложившихся стереотипов, и один из ярких тому примеров — восприятие национальной культуры. Страницы многих современных изданий пестрят материалами, оформленными «под старину». Авторы статьи провели, как это сегодня модно говорить, независимое журналистское расследование и пришли к выводу, что все издания, оформленные «в национальном русском стиле», становятся странно похожими друг на друга. Между строк нам видится один и тот же знакомый образ… Это иностранный турист, что бродит по Арбату с матрешкой в руках и военной ушанкой на голове. Слово «русский» в сознании заморского гостя прочно ассоциируется с матрешками, медведями, балалайкой и водкой, его вид вызывает, в зависимости от остроты патриотических чувств, смех или раздражение.
Авторы статьи провели, как это сегодня модно говорить, независимое журналистское расследование и пришли к выводу, что все издания, оформленные «в национальном русском стиле», становятся странно похожими друг на друга. Между строк нам видится один и тот же знакомый образ… Это иностранный турист, что бродит по Арбату с матрешкой в руках и военной ушанкой на голове. Слово «русский» в сознании заморского гостя прочно ассоциируется с матрешками, медведями, балалайкой и водкой, его вид вызывает, в зависимости от остроты патриотических чувств, смех или раздражение.
Мы обсуждали эту проблему с художественными редакторами издательств и программистскими фирмами, работающими на рынке издательских систем. Мнения, полученные в результате, оказались полярны. Бойкая компьютерная молодежь, играющая готовыми «кубиками» из clip-art, строго указала на бедность отечественного рынка шрифтов и орнаментов. Собирательный образ можно описать несколькими фразами (разговор ведется на фоне книжной полки с китайскими CD-ROM, забитыми пиратскими копиями программ): «С софтом у меня порядок: редакторы и версталки — какие хочешь, одних шрифтов 20 мегабайт. ., с латиницей проблем не было никогда: Траянова колонна, готика, современных шрифтов — устанешь перечислять; с современной кириллицей за последние пару лет тоже стало более или менее, а вот старославянских нет совсем, с «Ижицы» начинаются и на ней же заканчиваются, поэтому все «русские» материалы выглядят как родные братья».
., с латиницей проблем не было никогда: Траянова колонна, готика, современных шрифтов — устанешь перечислять; с современной кириллицей за последние пару лет тоже стало более или менее, а вот старославянских нет совсем, с «Ижицы» начинаются и на ней же заканчиваются, поэтому все «русские» материалы выглядят как родные братья».
Оппонентом компьютерных гениев выступил пожилой художник, переживший не один худсовет: «Во-первых, все не так плохо: существуют современные издания, «русский» дизайн которых соответствует стилю и содержанию. В хорошем книжном магазине можно найти народные сказки, книги по истории искусства, церковную литературу, оформленную с художественной точки зрения безукоризненно, но интересующие вас иллюстрации созданы «руками» без использования компьютерной техники.
Во-вторых — не так сложно найти литературу по истории книги, грамматике церковнославянского языка, статьи о древних шрифтах, а также отыскать конкретных людей, посвятивших себя этим вопросам. ..»
..»
Необходимо отметить, что у «древних шрифтов на новый лад» есть еще и такой серьезный и требовательный потребитель, как Православная Церковь. Ведется активная работа по переизданию духовной литературы, часто настолько ветхой и пожелтевшей, что обычные репринтные методы не дают желаемого результата. Серьезной проблемой является то, что одновременно учесть пожелания служителей церкви, издателей исторической литературы и составителей рекламных проспектов практически невозможно. Православная Церковь использует набор символов церковной грамоты конца XIX века, внешний вид которых продиктован канонами и печатной технологией тех времен. Современные светские заказчики ценят в шрифте не столько историческую точность, сколько стиль, своего рода «концентрацию русского духа». Хорошей иллюстрацией противоречия между историей и современными нуждами является пожелание иметь соответствующее начертание латинского алфавита. Строго говоря, они хотят получить в компьютерном формате некую графическую форму, которая, в соответствии с историей славянской и мировой культуры, никогда не существовала как шрифт.
Особенно сложен вопрос о стандарте на таблицы кодировки старославянских символов, нерешенный до настоящего времени.
В качестве иллюстрации рекомендуем рассмотреть при помощи Таблицы символов Windows (character map) набор символов шрифта «Ижица», доступного большинству читателей.
В этом шрифте нет латинских букв, но есть буква ижица и многие ныне вымершие ее сотоварищи: фита, Е йотированное, юс большой, юс малый, от (омега), зело, ять и другие. Вместе с тем «Ижица» содержит все символы стандартного русского алфавита и может применяться в современных изданиях. «Ижица» не претендует на историческую точность, при всей своей оригинальности это не более, чем декоративный шрифт в русском стиле. Для переиздания старинных книг он не пригоден.
Общеизвестным является факт создания славянской азбуки византийскими миссионерами Кириллом и Мефодием для перевода церковной литературы с греческого на славянские языки. Большая часть букв кириллицы заимствована из византийского устава. Графические формы букв определялись инструментом письма и материалом, на котором «издавалась» старинная книга.
Графические формы букв определялись инструментом письма и материалом, на котором «издавалась» старинная книга.
Но мало кто задумывался, что попытки по-настоящему точно воссоздать старинный шрифт потребуют пересмотра современной кодировки, так как в древнерусских шрифтах набор символов отличался не только от современного гражданского, но и от того, чем сегодня пользуется Православная Церковь, да к тому же со временем он еще и менялся. Вместо привычных сегодня арабских цифр в таблице придется разместить обозначения древнерусских числительных в виде букв, снабженных специальным знаком — титлом. Символы этого шрифта не требуют деления на прописные и строчные, в нем не будет запятой, пришедшей только в XVI веке из болгарской книжной традиции. Даже пробел, без которого невозможно представить современный набор, не использовался в текстах, написанных уставом. Зато нужны слова и буквы под титлом, то есть сокращенные слова-значки, похожие на элементы современной стенографии.
Аналогия со стенографией неслучайна, шрифт старых книг — всегда шрифт рукописный. Наборные кассы первых печатных изданий, стоивших едва ли не дороже рукописей, делались по образу и подобию рукописей. Кстати, Иван Федоров, вопреки распространенному мнению, был не первым, кто применил на Руси печатный станок. Сейчас доказано, что, как минимум, одна типография заработала несколько раньше. Но ни на одной из дошедших до нас более ранних печатных книг нет ни даты, ни имени издателя. Так что Иван Федоров, по-видимому, ввел в книжное дело нечто другое, не менее важное — выходные данные. Первые типографские стандарты появились при Петре Первом, до петровской реформы их практически не было: у каждого писца свой почерк, у каждой типографии — свой шрифт. Поэтому исторически корректным можно считать только тот компьютерный шрифт, который точно воспроизводит почерк автора конкретной рукописи или шрифт типографии.
Наборные кассы первых печатных изданий, стоивших едва ли не дороже рукописей, делались по образу и подобию рукописей. Кстати, Иван Федоров, вопреки распространенному мнению, был не первым, кто применил на Руси печатный станок. Сейчас доказано, что, как минимум, одна типография заработала несколько раньше. Но ни на одной из дошедших до нас более ранних печатных книг нет ни даты, ни имени издателя. Так что Иван Федоров, по-видимому, ввел в книжное дело нечто другое, не менее важное — выходные данные. Первые типографские стандарты появились при Петре Первом, до петровской реформы их практически не было: у каждого писца свой почерк, у каждой типографии — свой шрифт. Поэтому исторически корректным можно считать только тот компьютерный шрифт, который точно воспроизводит почерк автора конкретной рукописи или шрифт типографии.
Компьютерный набор древнерусского текста требует специальной раскладки клавиатуры. Будет ли существовать стандарт? Видимо, таковым де-факто станет расположение символов наиболее распространенного шрифта.
Поиски компромисса между светскими, историческими и церковными нуждами привели к тому, что все шрифты, показанные в обзоре, имеют разные наборы символов. Чтобы не отдавать предпочтение ни одной фирме и не вносить дополнительной путаницы, в качестве примера распечатывался современный набор русских букв, имеющийся в каждом шрифте.
Отметим лишь, что вопреки исторической правде, но в точном соответствии с компьютерными стандартами фирмы SPSL и «ТайпМаркет» предлагают как «древнерусский», так и коммерческие варианты шрифтов, в которые входит латинский алфавит. Есть в них даже знак доллара, хотя в XII веке не то что доллара, но и самих Соединенных Штатов еще в помине не было.
Митя Кузнецов. «Старинные» вывески для Рыбинска: sazikov — LiveJournal
Недавно в ФБ ко мне обратился музыкант и дизайнер Митя Кузнецов. Его интересовала любая информация о старинных русских вывесках: литература, фотографии, выставки, кто-где этим профессионально занимается в наши дни. Дело в том, что Митя уже не первый год работает над воссозданием исторического облика центральной части города Рыбинска. Здесь переплелось сразу несколько административных начинаний и частных инициатив: работы по архитектурной реставрации и реконструкции центральной части города, разработка колористического кода для фасадов зданий, решение городской администрации о регулировании наружной рекламы в историческом центре.
Дело в том, что Митя уже не первый год работает над воссозданием исторического облика центральной части города Рыбинска. Здесь переплелось сразу несколько административных начинаний и частных инициатив: работы по архитектурной реставрации и реконструкции центральной части города, разработка колористического кода для фасадов зданий, решение городской администрации о регулировании наружной рекламы в историческом центре.
Когда готовил этот материал, с удивлением открыл для себя, что с Митей Кузнецовым, оказывается, в некотором смысле, я знаком уже очень давно — в 90-е годы он был вокалистом и музыкантом фолк-группы «Седьмая вода», творчество которой я тогда хорошо знал и любил. И вот спустя более двух десятков лет довелось познакомиться с ним лично. Да еще при таких необычных обстоятельствах.
Вот здесь он слева от Марины Соколовой — солистки группы:
Facebook post
Как рассказал мне Митя, первый опыт с вывесками был экспериментальным, попытка сотрудничества с рекламными агентствами над созданием вывесочных образцов для исторического центра, используя современные материалы и технологии, оказалась неудачной.
С прошлого года он полностью перешел в своей работе на аутентичные технологии производства русской вывески — вернул ручной труд художников и ремесленников. Мите было важно воссоздать не только вид, но и способ производства старинной вывески.
С этой целью был отработан конструктив по Коваленко: металл, дерево, краски и т.д. Именно в этой технологии сделаны вывески на улице Стоялой. Удалось добиться запрета искусственных материалов на законодательном уровне. Сейчас каждая вывеска проходит строгую комиссию, а шрифты используются только из дореволюционных сборников шрифтолитейного «заведения Бертгольда» и словолитни «О.И. Лемана».
Я порекомендовал Мите помимо совершенно замечательной книги Коваленко «Вывеска. Её история, развитие и производство», присмотреться и к работе Анисима Семенюка «Живописец вывесок: Практическое руководство по написанию вывесок на стенах, полотне, деревянных щитах, железе и других материалах», изданной в 1917 году. Это фактически учебное пособие мастера-вывесочника.
Это фактически учебное пособие мастера-вывесочника.
Изучив его можно не только получить исчерпывающие сведения о свойствах красок, применяемых при написании вывесок, но и узнать как выбрать основу для вывески, как сварить олифу, нанести позолоту, подобрать инструменты и приспособления для работы, узнать какие бывают типы вывесок и как их писать, наконец. Короче, все что надо для скорейшего овладения профессией.
Далее говорит Митя Кузнецов:
«Музей Живой Старинной Вывески под открытым небом» — так называется проект, который родился в Этно-Кузне. В 2017 году мы начали возрождение старинной вывески 19 века в историческом центре Рыбинска. За полтора года в городе появилось более 30 вывесок в старинном стиле. Большая часть — 2/3 всех этих вывесок родились в Этно-Кузне. Для этого мне потребовалось несколько лет изучения старинной орфографии, шрифтов и технологий, которые использовались до революции 1917 года. Это совпало с реконструкцией старинной Красной Площади города, на которой мы и запустили пилотный проект.
В 2018 году в Рыбинске продолжилась реставрация исторического центра города, особенно улицы Стоялой. Это одна из важнейших улиц нашего города. Здесь проходила самая бурная жизнь в дореволюционные времена, были магазины, трактиры, стояли бурлаки и крючники. Я предложил придать фасадам зданий цвет, соответствующий цветовому коду русских городов 19 века.
Опять начал копать, полгода занимался исследованием по сохранившимся цветным фотографиям, старинным книгам, сопоставляя материалы того времени. Изучив нормативы периода 1860–1900 годов, я пришел к определенной «цветовой формуле» России и понял, в какие цвета чаще всего красили дома в то время и почему.
Следствием моих изысканий стало то, что администрация города доверила мне, музыканту, курировать восстановление Стоялой улицы и определить цветовой стиль фасадов и технологию их покраски. Полученных знаний уже было достаточно для работы. Далее нужно было вычислить правильные оттенки для покраски зданий. Их могли дать только подлинные образцы. Я раздобыл сохранившиеся с прошлого века натуральные пигменты сурика, охры, оксидов хрома, железа и других. Затем стал искать, где их взять сегодня.
Их могли дать только подлинные образцы. Я раздобыл сохранившиеся с прошлого века натуральные пигменты сурика, охры, оксидов хрома, железа и других. Затем стал искать, где их взять сегодня.
С природными пигментами оказалось проблематично. Но я нашел аналоги, созданные синтезированным путем на старейшем заводе области. Поехал к ним в лабораторию, набрал пробники и стал экспериментировать. Через несколько недель мне удалось добиться 100% попадания в старинные оттенки.
Вывел формулу, пропорции и сочетаемость с разными базовыми современными красками. Я приходил к подрядчикам и замешивал краски. Можно сказать, каждое здание «прошло через мои руки». Также убедил маляров красить фасады кисточками, а не валиком, чтобы все выглядело более приближенным к старине. Оказалось, что все эти технологии более качественны и экономически в разы более выгодны.
После того, как на Красной площади старинные вывески прижились, мы решили продолжить эксперимент и на Стоялой.![]() Инициатива совпала с решением администрации навести порядок в области рекламы в историческом центре города. Концепция была поддержана администрацией города вплоть до того, что на законодательном уровне было решено привести весь центр Рыбинска к единому стилю исторической рекламы.
Инициатива совпала с решением администрации навести порядок в области рекламы в историческом центре города. Концепция была поддержана администрацией города вплоть до того, что на законодательном уровне было решено привести весь центр Рыбинска к единому стилю исторической рекламы.
На Стоялой улице я решил создать вывески полностью по технологии столетней давности, отказавшись от современных материалов. Вывеска 19 века была отражением культуры той эпохи, поэтому находится в гармонии с фасадами домов, построенных в то же время. Для изготовления вывесок в дореволюционном стиле я собрал артель из нескольких талантливых мастеров и художников.
Так как это арт-проект, было решено, что цена будет приближена к себестоимости изготовления и не будет дороже современной вывески, несмотря на ручной труд. Владельцы торговых точек, для которых мы изготовили их, проявили себя как меценаты проекта, за что им низкий поклон. И «Музей Живой Старинной Вывески» стал жить на реконструированной улице Рыбинска.
Открытый урок по ИЗО, МХК и истории в 5-м классе «Русский шрифт. Буквица»
Цели и задачи:
- Сообщение новых знаний и обобщение пройденного на уроках истории, МХК и ИЗО о возникновении письменности, о долгом пути к букве;
- о рукописных книгах, об истории книгопечатания, о каллиграфии и палеографии;
- воспитание уважения и любви к истории и культуре своего Отечества, к русскому искусству;
- обогащение духовного мира учащихся, развитие у них понимания искусства, способности быть зрителем, читателем, слушателем, исследователем; развитие эрудиции и кругозора, расширение словарного запаса; межпредметные связи.
Ход урока
1. Приветствие.
| 2. Когда-то рубили Слова топором, Потом выводили Гусиным пером. Менялись эпохи, Менялись чернила, И “вечная” ручка Весь мир полонила.  Но можно ли вечной Назваться без риска? И “шарику” вскоре Сдалась “самописка”. |
Чтоб те же слова Не строчить многократно, Стучит человек На машинке печатной. Вот чудо – машина Уже создается! Сама твою мысль На бумаге представит. Но думать – придется ! Но думать – придется ! От этого техника нас Не избавит. В. Викторов. |
– Ребята! Как вы думаете, о чем пойдет речь сегодня на уроке?
– Предполагаемый ответ: о написании букв, о шрифтах…
– Верно. А сейчас составьте цепочку из названий орудий письма, используя свои знания, материал таблиц и стихотворения В.Викторова.
Приложение 1.1 и Приложение 1.2: Таблица “Долгий путь к букве”.
Приложение 2.1 и Приложение 2.2: Таблица “Рождение книги на Руси”.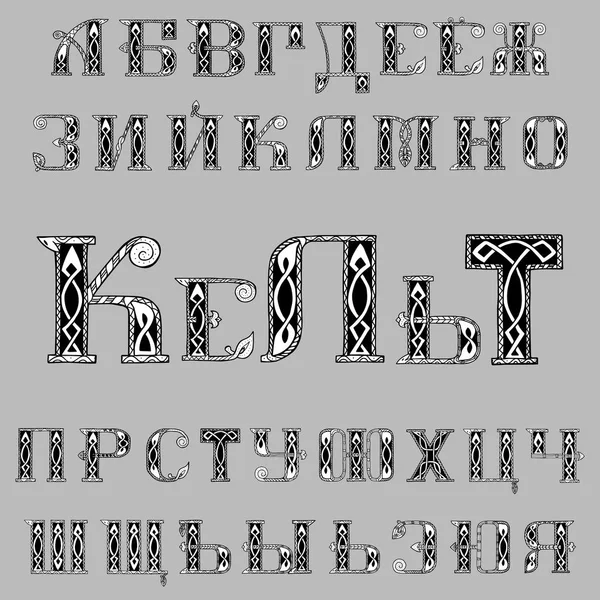
– Предполагаемый ответ: топор, палочки, кисть, перья, шпатель для клинописи, узлы в языковом письме инков-кипу…
– А на чем писали?
– Предполагаемый ответ…
Изобретение письменности – одно из величайших достижений человечества. Письменность дала возможность сохранять знания, сделала их доступными большому количеству людей. Написанное слово ценилось. Недаром на Руси говорили: “Что написано пером, не вырубишь и топором”. Появилась возможность передавать знания не только “из уст в уста”, в устном пересказе, но и в записях. Письменность является частью общей культуры данного народа и частью мировой художественной культуры.
– Ребята! Давайте вспомним основные виды письма:
– Пиктография – древнейшее письмо с помощью рисунков.
– Клинопись – сложное сочетание знаков-клиньев, выдавленных на влажной глине. У шумеров клинопись переняли другие народы, жившие в Месопотамии.
– Иероглифическое письмо ( иероглиф по-гречески означает “священное письмо”,
“священный знак” ) Древнего Египта и Китая. Язык древних египтян не был
полностью забыт. На нем до сих пор говорят копты – потомки древнего населения
Египта.
Язык древних египтян не был
полностью забыт. На нем до сих пор говорят копты – потомки древнего населения
Египта.
В китайской письменности существовало около 50 тысяч иероглифов. В Китае высоко ценилось искусство КАЛЛИГРАФИИ – красивого написания иероглифов. Во 2 веке китайцы изобрели бумагу.
– Слоговое письмо (слог – один письменный знак ) некоторых народов Индии; в Японии оно применялось наряду с китайскими иероглифами.
– Буквенно-звуковое.
– Кипу – узелковое письмо инков.
Первый буквенный алфавит появился ок.16 века до н.э. на Синайском полуострове у древне – симитских племен.
Запомни!
ПАЛЕОГРАФИЯ – наука, изучающая историю письменности.
КАЛЛИГРАФИЯ – искусство написания изящного шрифта.
– Ребята, какие пословицы, поговорки, высказывания вы знаете о словах, о языке?
– Язык языку весть подает, ответ держит, а голова смекает.
– Не бросай слов на ветер.
– Пустые слова что орех без ядра.
– Говорить – это одновременно мыслить и общаться. Б.Серебренников.
Древнерусскими назывались все рукописные первопечатные шрифты со времени их возникновения до образования новой графики гражданского письма (конец 16 – начало 17 века): кириллица, глаголица, устав, полуустав, скоропись, вязь.
Запомни!
РУССКАЯ ВЯЗЬ – особое декоративное письмо, употреблявшееся в 15 веке главным образом для выделения заглавий (показ на доске).
БУКВИЦА , или “ИНИЦИАЛ” – укрупненная заглавная буква, с которой начинается книга, глава, абзац. Это самая красивая буква, ее облик сразу создает настроение читателя (показ на доске).
– А кто мог писать книги?
– Священники, монахи.
– Верно.
Грамотных людей в те далекие времена на Руси больше всего было среди священников. Поэтому они и детей в монастырях грамоте учили, и книги переписывали от руки. Труд этот был нелегким и долгим. Вот что писали в конце книги о своей работе:
“Пусть правая рука писавшего скорей
От боли тягостной избавится своей”.
Порой книгу писец переписывал годы. Рецептов изготовления чернил было много: туда входили и старые ржавые гвозди, и квас, и мед, и даже иногда кислые щи. Когда чернила высыхали, то становились темно – коричневого цвета. Перья были чаще всего гусиные. Буквы выводили медленно, с одинаковым нажимом, отчего и само письмо, называемое УСТАВОМ, имело торжественный вид. В книге встречались и красные буквы. Красная краска – киноварь. Ею писали заголовки и начальные буквы. Отсюда и пошло выражение – “КРАСНАЯ СТРОКА”.
Книги ценили. Послушайте, как надлежало обращаться с книгой: “О, счастливейший читатель! Вымой свои руки и только после того возьмись за книгу, перевертывай листы медленно, держи пальцы подальше от букв”.
Да и сами книги не бегло читали, а “почитали”: “Велика ведь бывает польза от учения книжного”.
Переписанные листы украшали рисунками, одевали в переплеты из деревянных
досок, обтянутых кожей, делали изображения – тиснения. На обложках помещали
драгоценные камни, золотые или серебряные застежки. Поэтому в старину любили
говорить: “Книжное слово в жемчугах ходит”.
На обложках помещали
драгоценные камни, золотые или серебряные застежки. Поэтому в старину любили
говорить: “Книжное слово в жемчугах ходит”.
3. Память России.
– Ребята! А кому мы благодарны за возможность писать на родном языке?
– Немного истории…(Приложение 3 ), затем – Приложение 4.1, Приложение 4.2
Смотрим: Кирилл и Мефодий. Древнее изображение (Рисунок 1), икона 19 века (Рисунок 2).
Смотрим : Памятник Кириллу и Мефодию в Мурманске (Рисунок 3) и
в Москве (скульптор В.М.Клыков, архитектор Ю.П.Григорьев) – Рисунок 4.
Это фотография памятника отцам славянсой письменности– просветителям братьям Кириллу и Мефодию. В пьедестал встроена неугасимая лампада. Памятник был открыт в Москве на Славянской площадки 24 мая 1992 года. Этот день отмечается в нашей стране как День славянской письменности и культуры.
4. Искусствоведческая викторина – кроссворд (Приложение
5).
5.Практическая работа по ИЗО: написать на листе А4 заглавную букву – буквицу. Для работы используем простой карандаш, цветные карандаши и фломастеры. Показ учащимся готового изображения буквицы (Рисунок 5 и Рисунок 6).
6.Подведение итогов урока. Показ учащимися собственных работ (Рисунок 7 и Рисунок 8).
Вывод.
Алфавит Старорусский Шрифт Векторный Кириллический Шрифт Русский Неорусский Стоковое Изображение от ©[email protected] #288891558
Изображения
ВидеоРедакцииМузыка и звуковые эффекты
Инструменты
Предприятие
Цены
Все изображения
ВойтиРегистрация
Чтобы загрузить это изображение,
7 создайте учетную запись0018Уже есть учетная запись? Войти
Я согласен с Пользовательским соглашениемПолучать рассылку новостей и спецпредложений
Азбука древнерусского шрифта. Вектор. Кириллический шрифт на русском языке. Неорусский стиль 17-19 века. Все буквы вписаны от руки, произвольно. Стилизован под греческий или византийский устав.
Вектор. Кириллический шрифт на русском языке. Неорусский стиль 17-19 века. Все буквы вписаны от руки, произвольно. Стилизован под греческий или византийский устав.
— Вектор от [email protected]
Получите это изображение всего за 1,44 € с нашим новым Гибким планом
Попроб.Та же серия:
Шрифт Русский Устав. Вектор. Древнерусский средневековый алфавит. Набор средневековых букв 17-19 веков. Русская готика. Алое золото. Все символы, буквы и цифры хранятся отдельно. Стилизация под старину. Азбука древнерусского шрифта. Вектор. Надписи на русском языке. Неорусская постмодернистская готика, стиль 10-15 веков. Буквы написаны от руки, хаотично. Стилизован под греческий, византийский устав. Набор гранжевых, грязных шрифтов. Вектор. Заглавные буквы. Неровный шрифт. Буквы — это символы для оформления плаката, флаера или презентации. Знаки для логотипа. Все буквы отдельно. Текстурный фон. Русский алфавит. Вектор. Набор кириллических букв на белом фоне. Веселый, неформальный шрифт. Все символы выделены отдельно. Мультяшный хипстерский стиль. Русский алфавит. Вектор. Набор кириллических букв на розовом фоне. Веселый, неформальный шрифт. Все символы выделены отдельно. Мультяшный хипстерский стиль. Алфавит старого русского шрифта. Вектор. Надписи на русском языке. Неорусская постмодернистская готика, стиль 10-15 века. Буквы написаны от руки, хаотично. Стилизован под греческий, византийский устав. Азбука древнерусского шрифта. Вектор. Надпись на русском. Неорусский стиль 17-19век. Все буквы вписаны от руки, произвольно. Стилизован под греческий или византийский устав. Готическое граффити. Русский, оригинальный акцидентный шрифт. Вектор. Авторский алфавит. Полный набор знаков, цифр, прописных и строчных букв кириллицы. Его можно использовать в дизайне и логотипах. Потрясающий шрифт. Английский алфавит с цветами и растениями. Вектор. Сила девушки шрифта. Девушка в венке, образ лета и весны. Декоративные элементы для магазина, косметики и женских товаров.
Веселый, неформальный шрифт. Все символы выделены отдельно. Мультяшный хипстерский стиль. Русский алфавит. Вектор. Набор кириллических букв на розовом фоне. Веселый, неформальный шрифт. Все символы выделены отдельно. Мультяшный хипстерский стиль. Алфавит старого русского шрифта. Вектор. Надписи на русском языке. Неорусская постмодернистская готика, стиль 10-15 века. Буквы написаны от руки, хаотично. Стилизован под греческий, византийский устав. Азбука древнерусского шрифта. Вектор. Надпись на русском. Неорусский стиль 17-19век. Все буквы вписаны от руки, произвольно. Стилизован под греческий или византийский устав. Готическое граффити. Русский, оригинальный акцидентный шрифт. Вектор. Авторский алфавит. Полный набор знаков, цифр, прописных и строчных букв кириллицы. Его можно использовать в дизайне и логотипах. Потрясающий шрифт. Английский алфавит с цветами и растениями. Вектор. Сила девушки шрифта. Девушка в венке, образ лета и весны. Декоративные элементы для магазина, косметики и женских товаров. Здоровье и красота. 8 марта. Подпись: Король и Шут. Вектор. Древнерусский средневековый стиль. Русская готика. Все персонажи сохраняются отдельно. Стилизация под старину. Мотивационная надпись. Набор различных модных шрифтов. Вектор. Все буквы и сомволы отдельно. Готика. Плоский и изометрический шрифт. Логотип мультяшного динозавра. Векторная иллюстрация. Детский образ Дракона. Изображение изолировано на белом фоне. Символ, эмблема для детского магазина. Компания талисман. Икона рептилии.
Здоровье и красота. 8 марта. Подпись: Король и Шут. Вектор. Древнерусский средневековый стиль. Русская готика. Все персонажи сохраняются отдельно. Стилизация под старину. Мотивационная надпись. Набор различных модных шрифтов. Вектор. Все буквы и сомволы отдельно. Готика. Плоский и изометрический шрифт. Логотип мультяшного динозавра. Векторная иллюстрация. Детский образ Дракона. Изображение изолировано на белом фоне. Символ, эмблема для детского магазина. Компания талисман. Икона рептилии.Просмотреть еще
Похожие видеоролики:
Рост национального департамента. Анимация счетчика предупреждений о кризисе в евроНациональный департамент растет. Анимация счетчика предупреждений о кризисе фунта. Национальный департамент растет. Анимация счетчика оповещения о кризисе в долларах. Шрифт алфавита Abc с выделенной фразой «Я люблю тебя». Японский текст. С Новым годом. черный силуэт протестующего держит над головой плакат, знамя с лозунгом — услышь наши крики, почувствуй наш гнев. Зеленый фон. Протест в поддержку прав и свобод чернокожих в Анимация текста рождественских поздравлений с украшениями на белом фоне. рождество, традиции и концепция празднования, созданные в цифровом виде, видео. Ключевые слова успешного бизнеса. Цифровая анимация 4 июля, текст Дня независимости, окруженный различными значками, уменьшающими масштаб на экране на черном фоне. Цветочная рамка, праздники в движении и фон в стиле промо. Анимированный фон высокого разрешения, написанный от руки строчными буквами латинского алфавита. Черно-белый для индивидуального использования. Анимация слов «Узнай больше», «Узнай подробности» и «Подпишись», мерцающих на сером фоне. Концепция связи и связи, созданная в цифровом виде. Счастливого Рождества и счастливого Нового года.0014 Подробнее
Протест в поддержку прав и свобод чернокожих в Анимация текста рождественских поздравлений с украшениями на белом фоне. рождество, традиции и концепция празднования, созданные в цифровом виде, видео. Ключевые слова успешного бизнеса. Цифровая анимация 4 июля, текст Дня независимости, окруженный различными значками, уменьшающими масштаб на экране на черном фоне. Цветочная рамка, праздники в движении и фон в стиле промо. Анимированный фон высокого разрешения, написанный от руки строчными буквами латинского алфавита. Черно-белый для индивидуального использования. Анимация слов «Узнай больше», «Узнай подробности» и «Подпишись», мерцающих на сером фоне. Концепция связи и связи, созданная в цифровом виде. Счастливого Рождества и счастливого Нового года.0014 ПодробнееИнформация об использовании
Вы можете использовать это бесплатное векторное изображение «Алфавит древнерусского шрифта. Вектор. Кириллический шрифт на русском языке. Неорусский стиль 17-19 века. Все буквы вписаны от руки, произвольно. Стилизованный под греческий или византийский устав». для личных и коммерческих целей в соответствии со Стандартной или Расширенной лицензией. Стандартная лицензия распространяется на большинство вариантов использования, включая рекламу, дизайн пользовательского интерфейса и упаковку продуктов, и позволяет издавать до 500 000 печатных копий. Расширенная лицензия разрешает все варианты использования стандартной лицензии с неограниченными правами печати и позволяет вам использовать загруженные векторные файлы для продажи, перепродажи продукта или бесплатного распространения.
Стилизованный под греческий или византийский устав». для личных и коммерческих целей в соответствии со Стандартной или Расширенной лицензией. Стандартная лицензия распространяется на большинство вариантов использования, включая рекламу, дизайн пользовательского интерфейса и упаковку продуктов, и позволяет издавать до 500 000 печатных копий. Расширенная лицензия разрешает все варианты использования стандартной лицензии с неограниченными правами печати и позволяет вам использовать загруженные векторные файлы для продажи, перепродажи продукта или бесплатного распространения.
Это стоковое векторное изображение можно масштабировать до любого размера. Вы можете купить и скачать его в высоком разрешении до 3746×5000. Upload Date: Jul 27, 2019
Depositphotos
Language
Information
- Frequently Asked Questions
- All Documents
- Available on the
- Available on the
- Bird In Flight — The Photo Журнал
Контакты и поддержка
- +49-800-000-42-21
- Контакты
- Depositphotos Отзывы
© 2009-2022. Depositphotos, Inc. США. Все права защищены.
Depositphotos, Inc. США. Все права защищены.
Вы используете устаревший браузер. Чтобы работать в Интернете быстрее и безопаснее, бесплатно обновитесь сегодня.
Алфавит старый русский шрифт Роялти бесплатно векторное изображение
Алфавит старый русский шрифт Роялти бесплатно векторное изображение- лицензионные векторы
- Векторы шрифтов
ЛицензияПодробнее
Стандарт Вы можете использовать вектор в личных и коммерческих целях. Расширенный Вы можете использовать вектор на предметах для перепродажи и печати по требованию.Тип лицензии определяет, как вы можете использовать этот образ.
Станд. | Расшир. | |
|---|---|---|
| Печатный/редакционный | ||
| Графический дизайн | ||
| Веб-дизайн | ||
| Социальные сети | ||
| Редактировать и модифицировать | ||
| Многопользовательский | ||
| Предметы перепродажи | ||
| Печать по запросу |
Способы покупкиСравнить
Плата за изображение $ 14,99 Кредиты $ 1,00 Подписка $ 0,69 Оплатить стандартные лицензии можно тремя способами. Цены $ $.
Цены $ $.
| Оплата с | Цена изображения |
|---|---|
| Плата за изображение $ 14,99 Одноразовый платеж | |
| Предоплаченные кредиты $ 1 Загружайте изображения по запросу (1 кредит = 1 доллар США). Минимальная покупка 30р. | |
| План подписки От 69 центов Выберите месячный план. Неиспользованные загрузки автоматически переносятся на следующий месяц. | |
Способы покупкиСравнить
Плата за изображение $ 39,99 Кредиты $ 30,00Существует два способа оплаты расширенных лицензий. Цены $ $.
| Оплата с | Стоимость изображения |
|---|---|
Плата за изображение $ 39,99 Оплата разовая, регистрация не требуется. | |
| Предоплаченные кредиты $ 30 Загружайте изображения по запросу (1 кредит = 1 доллар США). | |
Дополнительные услугиПодробнее
Настроить изображение Доступно только с оплатой за изображение $ 85,00Нравится изображение, но нужны лишь некоторые изменения? Пусть наши талантливые художники сделают всю работу за вас!
Мы свяжем вас с дизайнером, который сможет внести изменения и отправить вам изображение в выбранном вами формате.
Примеры
- Изменить текст
- Изменить цвета
- Изменить размер до новых размеров
- Включить логотип или символ
- Добавьте название своей компании или компании
файла включены
Подробности загрузки…
- Идентификатор изображения
- 31086736
- Цветовой режим
- RGB
- Художник
- GeekClick
наборов данных машинного обучения | Документы с кодом
🔔 Поделитесь своим набором данных с сообществом машинного обучения!
СИФАР-10
Набор данных CIFAR-10 (Канадский институт перспективных исследований, 10 классов) является подмножеством набора данных Tiny Images и состоит из 60000 цветных изображений 32×32. Изображения помечены одним из 10 взаимоисключающих классов: самолет, автомобиль (но не грузовик или пикап), птица, кошка, олень, собака, лягушка, лошадь, корабль и грузовик (но не пикап). На класс приходится 6000 изображений, 5000 обучающих и 1000 тестовых изображений на класс.
Изображения помечены одним из 10 взаимоисключающих классов: самолет, автомобиль (но не грузовик или пикап), птица, кошка, олень, собака, лягушка, лошадь, корабль и грузовик (но не пикап). На класс приходится 6000 изображений, 5000 обучающих и 1000 тестовых изображений на класс.
9 551 ДОКУМЕНТ • 59 ПОКАЗАТЕЛЕЙ
Имиджнет
Набор данных ImageNet содержит 14 197 122 аннотированных изображения в соответствии с иерархией WordNet. С 2010 года набор данных используется в программе ImageNet Large Scale Visual Recognition Challenge (ILSVRC), эталоне классификации изображений и обнаружения объектов.
Публично выпущенный набор данных содержит набор аннотированных вручную обучающих изображений. Также выпущен набор тестовых изображений без ручных аннотаций.
Аннотации ILSVRC попадают в одну из двух категорий: (1) аннотация на уровне изображения двоичной метки для присутствия или отсутствия класса объектов на изображении, например, «на этом изображении есть автомобили», но «нет тигров, » и (2) аннотация на уровне объекта в виде узкой ограничивающей рамки и метки класса вокруг экземпляра объекта на изображении, например, «есть отвертка с центром в позиции (20, 25) с шириной 50 пикселей и высотой 30 пикселей ».
Проект ImageNet не владеет авторскими правами на изображения, поэтому предоставляются только эскизы и URL-адреса изображений.
Также выпущен набор тестовых изображений без ручных аннотаций.
Аннотации ILSVRC попадают в одну из двух категорий: (1) аннотация на уровне изображения двоичной метки для присутствия или отсутствия класса объектов на изображении, например, «на этом изображении есть автомобили», но «нет тигров, » и (2) аннотация на уровне объекта в виде узкой ограничивающей рамки и метки класса вокруг экземпляра объекта на изображении, например, «есть отвертка с центром в позиции (20, 25) с шириной 50 пикселей и высотой 30 пикселей ».
Проект ImageNet не владеет авторскими правами на изображения, поэтому предоставляются только эскизы и URL-адреса изображений.
9 100 ДОКУМЕНТОВ • 89 ПОКАЗАТЕЛЕЙ
КОКО (Общие объекты Microsoft в контексте)
Набор данных MS COCO (Microsoft Common Objects in Context) представляет собой крупномасштабный набор данных для обнаружения объектов, сегментации, обнаружения ключевых точек и подписей. Набор данных состоит из 328 тыс. изображений.
Набор данных состоит из 328 тыс. изображений.
6 448 ДОКУМЕНТОВ • 78 ПОКАЗАТЕЛЕЙ
МНИСТ
База данных MNIST (модифицированная база данных Национального института стандартов и технологий) представляет собой большой набор рукописных цифр. Он имеет обучающий набор из 60 000 примеров и тестовый набор из 10 000 примеров. Это подмножество более крупной специальной базы данных 3 NIST (цифры, написанные сотрудниками Бюро переписи населения США) и специальной базы данных 1 (цифры, написанные старшеклассниками), которые содержат монохромные изображения рукописных цифр. Цифры были нормализованы по размеру и центрированы на изображении фиксированного размера. Исходные черно-белые (двухуровневые) изображения из NIST были нормализованы по размеру, чтобы поместиться в поле 20×20 пикселей с сохранением соотношения сторон. Результирующие изображения содержат уровни серого из-за метода сглаживания, используемого алгоритмом нормализации. изображения были центрированы в изображении 28×28 путем вычисления центра масс пикселей и перемещения изображения таким образом, чтобы расположить эту точку в центре поля 28×28.
Исходные черно-белые (двухуровневые) изображения из NIST были нормализованы по размеру, чтобы поместиться в поле 20×20 пикселей с сохранением соотношения сторон. Результирующие изображения содержат уровни серого из-за метода сглаживания, используемого алгоритмом нормализации. изображения были центрированы в изображении 28×28 путем вычисления центра масс пикселей и перемещения изображения таким образом, чтобы расположить эту точку в центре поля 28×28.
5 575 ДОКУМЕНТОВ • 42 ПОКАЗАТЕЛЯ
СИФАР-100
Набор данных CIFAR-100 (Канадский институт перспективных исследований, 100 классов) является подмножеством набора данных Tiny Images и состоит из 60000 цветных изображений 32×32. 100 классов в CIFAR-100 сгруппированы в 20 суперклассов. В каждом классе 600 изображений. Каждое изображение имеет метку «точно» (класс, к которому оно принадлежит) и метку «грубо» (надкласс, к которому оно принадлежит). В каждом классе есть 500 обучающих изображений и 100 тестовых изображений.
100 классов в CIFAR-100 сгруппированы в 20 суперклассов. В каждом классе 600 изображений. Каждое изображение имеет метку «точно» (класс, к которому оно принадлежит) и метку «грубо» (надкласс, к которому оно принадлежит). В каждом классе есть 500 обучающих изображений и 100 тестовых изображений.
4712 ДОКУМЕНТОВ • 35 ПОКАЗАТЕЛЕЙ
Городские пейзажи
Cityscapes — это крупномасштабная база данных, ориентированная на семантическое понимание городских уличных сцен. Он предоставляет семантические аннотации по экземплярам и плотным пикселям для 30 классов, сгруппированных в 8 категорий (плоские поверхности, люди, транспортные средства, конструкции, объекты, природа, небо и пустота). Набор данных состоит из примерно 5000 изображений с точной аннотацией и 20000 изображений с грубой аннотацией. Данные снимались в 50 городах в течение нескольких месяцев, в дневное время и при хороших погодных условиях. Первоначально он был записан как видео, поэтому кадры были выбраны вручную, чтобы иметь следующие особенности: большое количество динамических объектов, различное расположение сцен и меняющийся фон.
Набор данных состоит из примерно 5000 изображений с точной аннотацией и 20000 изображений с грубой аннотацией. Данные снимались в 50 городах в течение нескольких месяцев, в дневное время и при хороших погодных условиях. Первоначально он был записан как видео, поэтому кадры были выбраны вручную, чтобы иметь следующие особенности: большое количество динамических объектов, различное расположение сцен и меняющийся фон.
2353 ДОКУМЕНТА • 37 ПОКАЗАТЕЛЕЙ
СВХН (номера домов с просмотра улиц)
Street View House Numbers (SVHN) — это эталонный набор данных для классификации цифр, который содержит 600 000 32 × 32 RGB-изображений печатных цифр (от 0 до 9). ) вырезано из фотографий номерных знаков домов. Обрезанные изображения располагаются по центру интересующей цифры, но близлежащие цифры и другие отвлекающие факторы остаются на изображении. SVHN имеет три набора: обучающий, тестовый и дополнительный набор из 530 000 изображений, которые менее сложны и могут быть использованы для помощи в процессе обучения.
) вырезано из фотографий номерных знаков домов. Обрезанные изображения располагаются по центру интересующей цифры, но близлежащие цифры и другие отвлекающие факторы остаются на изображении. SVHN имеет три набора: обучающий, тестовый и дополнительный набор из 530 000 изображений, которые менее сложны и могут быть использованы для помощи в процессе обучения.
2291 ДОКУМЕНТ • 11 ПОКАЗАТЕЛЕЙ
КИТТИ
KITTI (Технологический институт Карлсруэ и Технологический институт Toyota) — один из самых популярных наборов данных для использования в мобильной робототехнике и автономном вождении. Он состоит из часов сценариев дорожного движения, записанных с помощью различных датчиков, включая RGB с высоким разрешением, стереокамеры в оттенках серого и лазерный 3D-сканер. Несмотря на свою популярность, сам набор данных не содержит достоверных данных для семантической сегментации. Однако различные исследователи вручную аннотировали части набора данных, чтобы они соответствовали их потребностям. Альварес и др. сгенерировал наземную правду для 323 изображений из задачи обнаружения дорог с тремя классами: дорога, вертикаль и небо. Чжан и др. аннотировано 252 (140 для обучения и 112 для тестирования) снимков — сканов RGB и Velodyne — из задачи отслеживания для десяти категорий объектов: здание, небо, дорога, растительность, тротуар, автомобиль, пешеход, велосипедист, знак/столб и забор. Рос и др. помечены 170 тренировочных изображений и 46 тестовых изображений (из визуального одома
Несмотря на свою популярность, сам набор данных не содержит достоверных данных для семантической сегментации. Однако различные исследователи вручную аннотировали части набора данных, чтобы они соответствовали их потребностям. Альварес и др. сгенерировал наземную правду для 323 изображений из задачи обнаружения дорог с тремя классами: дорога, вертикаль и небо. Чжан и др. аннотировано 252 (140 для обучения и 112 для тестирования) снимков — сканов RGB и Velodyne — из задачи отслеживания для десяти категорий объектов: здание, небо, дорога, растительность, тротуар, автомобиль, пешеход, велосипедист, знак/столб и забор. Рос и др. помечены 170 тренировочных изображений и 46 тестовых изображений (из визуального одома
2282 ДОКУМЕНТА • 119 ПОКАЗАТЕЛЕЙ
CelebA (Набор данных атрибутов CelebFaces)
Набор данных CelebFaces Attributes содержит 202,599 изображений лиц размером 178×218 от 10 177 знаменитостей, каждое из которых снабжено 40 бинарными метками, указывающими такие атрибуты лица, как цвет волос, пол и возраст.
2230 ДОКУМЕНТОВ • 15 ПОКАЗАТЕЛЕЙ
Fashion-MNIST
Fashion-MNIST — это набор данных, состоящий из изображений в оттенках серого 28×28 70 000 модных товаров из 10 категорий, по 7 000 изображений в каждой категории. Учебный набор содержит 60 000 изображений, а тестовый — 10 000 изображений. Fashion-MNIST использует тот же размер изображения, формат данных и структуру тренировочных и тестовых разделов, что и исходный MNIST.
1960 ДОКУМЕНТОВ • 12 ПОКАЗАТЕЛЕЙ
КЛЕЙ (Эталон оценки общего понимания языка)
Тест General Language Understanding Evaluation (GLUE) представляет собой набор из девяти задач на понимание естественного языка, включая задачи на одно предложение CoLA и SST-2, задачи на сходство и перефразирование MRPC, STS-B и QQP, а также задачи на определение естественного языка MNLI, QNLI, РТЭ и ВНЛИ.
1556 ДОКУМЕНТОВ • 40 ПОКАЗАТЕЛЕЙ
Отряд (Стэнфордский набор данных ответов на вопросы)
Стэнфордский набор данных для ответов на вопросы (SQuAD) представляет собой набор пар вопросов и ответов, полученных из статей Википедии. В SQuAD правильными ответами на вопросы может быть любая последовательность жетонов в заданном тексте. Поскольку вопросы и ответы создаются людьми с помощью краудсорсинга, они более разнообразны, чем некоторые другие наборы данных для ответов на вопросы. SQuAD 1.1 содержит 107 785 пар вопросов и ответов по 536 статьям. SQuAD2.0 (SQuAD с открытым доменом, SQuAD-Open), последняя версия, сочетает в себе 100 000 вопросов в SQuAD1.1 с более чем 50 000 вопросов, на которые нет ответов, написанных состязательно краудворкерами в формах, аналогичных тем, на которые можно ответить.
SQuAD2.0 (SQuAD с открытым доменом, SQuAD-Open), последняя версия, сочетает в себе 100 000 вопросов в SQuAD1.1 с более чем 50 000 вопросов, на которые нет ответов, написанных состязательно краудворкерами в формах, аналогичных тем, на которые можно ответить.
1441 ДОКУМЕНТ • 13 ПОКАЗАТЕЛЕЙ
КУБ-200-2011 (Калтех-UCSD Birds-200-2011)
Набор данных Caltech-UCSD Birds-200-2011 (CUB-200-2011) является наиболее широко используемым набором данных для задач детальной визуальной категоризации. Он содержит 11 788 изображений 200 подкатегорий, принадлежащих птицам, 5,994 для обучения и 5794 для тестирования. Каждое изображение имеет подробные аннотации: 1 метка подкатегории, 15 местоположений деталей, 312 бинарных атрибутов и 1 ограничительная рамка. Текстовая информация поступает от Reed et al. Они расширяют набор данных CUB-200-2011, собирая подробные описания на естественном языке. Для каждого изображения собираются десять описаний, состоящих из одного предложения. Описания на естественном языке собираются через платформу Amazon Mechanical Turk (AMT) и должны содержать не менее 10 слов без какой-либо информации о подкатегориях и действиях.
Каждое изображение имеет подробные аннотации: 1 метка подкатегории, 15 местоположений деталей, 312 бинарных атрибутов и 1 ограничительная рамка. Текстовая информация поступает от Reed et al. Они расширяют набор данных CUB-200-2011, собирая подробные описания на естественном языке. Для каждого изображения собираются десять описаний, состоящих из одного предложения. Описания на естественном языке собираются через платформу Amazon Mechanical Turk (AMT) и должны содержать не менее 10 слов без какой-либо информации о подкатегориях и действиях.
1363 ДОКУМЕНТА • 33 ПОКАЗАТЕЛЯ
SST (Стэнфордское дерево настроений)
Stanford Sentiment Treebank — это корпус с полностью размеченными деревьями синтаксического анализа, который позволяет
полный анализ композиционных эффектов
чувства в языке. Корпус основан на
набор данных, представленный Пангом и Ли (2005) и
состоит из 11 855 отдельных предложений, извлеченных из
обзоры фильмов. Он был проанализирован с помощью Стэнфордского
парсер и содержит в общей сложности 215 154 уникальных фразы
из этих деревьев синтаксического анализа, каждое из которых аннотировано тремя судьями-людьми.
Корпус основан на
набор данных, представленный Пангом и Ли (2005) и
состоит из 11 855 отдельных предложений, извлеченных из
обзоры фильмов. Он был проанализирован с помощью Стэнфордского
парсер и содержит в общей сложности 215 154 уникальных фразы
из этих деревьев синтаксического анализа, каждое из которых аннотировано тремя судьями-людьми.
1297 ДОКУМЕНТОВ • 6 ПОКАЗАТЕЛЕЙ
Пенн Трибэнк
Английский корпус Penn Treebank (PTB) и, в частности, раздел корпуса, соответствующий статьям Wall Street Journal (WSJ), является одним из наиболее известных и используемых корпусов для оценки моделей маркировки последовательностей. Задача состоит в том, чтобы аннотировать каждое слово его тегом Part-of-Speech. В наиболее распространенной разбивке этого корпуса для обучения используются секции с 0 по 18 (38 219предложения, 912 344 токена), разделы с 19 по 21 используются для проверки (5 527 предложений, 131 768 токенов), а разделы с 22 по 24 используются для тестирования (5 462 предложения, 129 654 токена).
Корпус также обычно используется для языкового моделирования на уровне символов и слов.
Задача состоит в том, чтобы аннотировать каждое слово его тегом Part-of-Speech. В наиболее распространенной разбивке этого корпуса для обучения используются секции с 0 по 18 (38 219предложения, 912 344 токена), разделы с 19 по 21 используются для проверки (5 527 предложений, 131 768 токенов), а разделы с 22 по 24 используются для тестирования (5 462 предложения, 129 654 токена).
Корпус также обычно используется для языкового моделирования на уровне символов и слов.
1241 ДОКУМЕНТ • 14 ПОКАЗАТЕЛЕЙ
ЛибриРечь
Корпус LibriSpeech представляет собой коллекцию примерно 1000 часов аудиокниг, являющихся частью проекта LibriVox. Большинство аудиокниг исходит от Project Gutenberg. Учебные данные разделены на 3 части по 100 часов, 360 часов и 500 часов, в то время как данные разработки и тестирования разделены на «чистые» и «другие» категории, соответственно, в зависимости от того, насколько хорошо или сложно будут работать системы автоматического распознавания речи. . Каждый из наборов для разработки и тестирования длится около 5 часов. Этот корпус также содержит языковые модели n-грамм и соответствующие тексты, взятые из книг Project Gutenberg, которые содержат 803 миллиона токенов и 977 тысяч уникальных слов.
Большинство аудиокниг исходит от Project Gutenberg. Учебные данные разделены на 3 части по 100 часов, 360 часов и 500 часов, в то время как данные разработки и тестирования разделены на «чистые» и «другие» категории, соответственно, в зависимости от того, насколько хорошо или сложно будут работать системы автоматического распознавания речи. . Каждый из наборов для разработки и тестирования длится около 5 часов. Этот корпус также содержит языковые модели n-грамм и соответствующие тексты, взятые из книг Project Gutenberg, которые содержат 803 миллиона токенов и 977 тысяч уникальных слов.
1201 ДОКУМЕНТ • 8 ПОКАЗАТЕЛЕЙ
UCF101 (Набор данных UCF101 Human Actions)
Набор данных UCF101 является расширением UCF50 и состоит из 13 320 видеоклипов, которые разбиты на 101 категорию. Эти 101 категорию можно разделить на 5 типов (движение тела, взаимодействие человека с человеком, взаимодействие человека с объектом, игра на музыкальных инструментах и спорт). Общая продолжительность этих видеороликов составляет более 27 часов. Все видео собраны с YouTube и имеют фиксированную частоту кадров 25 FPS при разрешении 320×240.
Эти 101 категорию можно разделить на 5 типов (движение тела, взаимодействие человека с человеком, взаимодействие человека с объектом, игра на музыкальных инструментах и спорт). Общая продолжительность этих видеороликов составляет более 27 часов. Все видео собраны с YouTube и имеют фиксированную частоту кадров 25 FPS при разрешении 320×240.
1174 ДОКУМЕНТА • 16 ПОКАЗАТЕЛЕЙ
МультиNLI (Многожанровый вывод на естественном языке)
Набор данных Multi-Genre Natural Language Inference (MultiNLI) содержит 433 000 пар предложений. Его размер и способ сбора моделируются точно так же, как SNLI. MultiNLI предлагает десять различных жанров (лицом к лицу, по телефону, 9/11, Travel, Letters, Oxford University Press, Slate, Verbatim, Goverment and Fiction) письменных и устных данных на английском языке. Существуют совпадающие наборы для разработки/тестирования, полученные из тех же источников, что и в обучающем наборе, и несовпадающие наборы, которые не очень похожи на те, что были видны во время обучения.
MultiNLI предлагает десять различных жанров (лицом к лицу, по телефону, 9/11, Travel, Letters, Oxford University Press, Slate, Verbatim, Goverment and Fiction) письменных и устных данных на английском языке. Существуют совпадающие наборы для разработки/тестирования, полученные из тех же источников, что и в обучающем наборе, и несовпадающие наборы, которые не очень похожи на те, что были видны во время обучения.
1110 ДОКУМЕНТОВ • 6 ПОКАЗАТЕЛЕЙ
Шейпнет
ShapeNet — это крупномасштабное хранилище 3D-моделей CAD, разработанное исследователями из Стэнфордского университета, Принстонского университета и Технологического института Toyota в Чикаго, США. Репозиторий содержит более 300 миллионов моделей, 220 000 из которых разделены на 3 135 классов, организованных с использованием отношений гипероним-гипоним WordNet. Подмножество частей ShapeNet содержит 31,693 сетки, разделенные на 16 общих классов объектов (например, стол, стул, самолет и т. д.). Наземная правда каждой формы содержит 2-5 частей (всего 50 классов деталей).
Репозиторий содержит более 300 миллионов моделей, 220 000 из которых разделены на 3 135 классов, организованных с использованием отношений гипероним-гипоним WordNet. Подмножество частей ShapeNet содержит 31,693 сетки, разделенные на 16 общих классов объектов (например, стол, стул, самолет и т. д.). Наземная правда каждой формы содержит 2-5 частей (всего 50 классов деталей).
1091 ДОКУМЕНТ • 10 ПОКАЗАТЕЛЕЙ
IMDb Обзоры фильмов
Набор данных IMDb Movie Reviews представляет собой двоичный набор данных анализа настроений, состоящий из 50 000 обзоров из базы данных Internet Movie Database (IMDb), помеченных как положительные или отрицательные. Набор данных содержит четное количество положительных и отрицательных отзывов. Учитываются только сильно поляризующие отзывы. Отрицательная рецензия имеет оценку ≤ 4 из 10, а положительная рецензия имеет оценку ≥ 7 из 10. На фильм включено не более 30 рецензий. Набор данных содержит дополнительные немаркированные данные.
Набор данных содержит четное количество положительных и отрицательных отзывов. Учитываются только сильно поляризующие отзывы. Отрицательная рецензия имеет оценку ≤ 4 из 10, а положительная рецензия имеет оценку ≥ 7 из 10. На фильм включено не более 30 рецензий. Набор данных содержит дополнительные немаркированные данные.
1090 ДОКУМЕНТОВ • 7 ПОКАЗАТЕЛЕЙ
Визуальный ответ на вопрос (ВКА)
Visual Question Answering (VQA) — это набор данных, содержащий открытые вопросы об изображениях. Эти вопросы требуют понимания видения, языка и знания здравого смысла, чтобы ответить. Первая версия набора данных была выпущена в октябре 2015 года. VQA v2.0 был выпущен в апреле 2017 года.
Первая версия набора данных была выпущена в октябре 2015 года. VQA v2.0 был выпущен в апреле 2017 года.
1077 ДОКУМЕНТОВ • 2 ПОКАЗАТЕЛЯ
СНЛИ (Стэнфордский вывод на естественном языке)
Набор данных SNLI (Stanford Natural Language Inference) состоит из 570 тысяч пар предложений, вручную помеченных как следствия, противоречия и нейтральные. Предпосылки — это подписи к изображениям из Flickr30k, а гипотезы были созданы аннотаторами из краудсорсинга, которым показывали предпосылку и просили составить подразумевающие, противоречащие и нейтральные предложения. Аннотаторам было поручено судить об отношении между предложениями, учитывая, что они описывают одно и то же событие. Каждая пара помечена как «последствия», «нейтральные», «противоречия» или «-», где «-» означает, что соглашение не может быть достигнуто.
Аннотаторам было поручено судить об отношении между предложениями, учитывая, что они описывают одно и то же событие. Каждая пара помечена как «последствия», «нейтральные», «противоречия» или «-», где «-» означает, что соглашение не может быть достигнуто.
949 ДОКУМЕНТОВ • 3 ПОКАЗАТЕЛЯ
мини-Imagenet
мини-имиджнет
mini-Imagenet предлагается Matching Networks для One Shot Learning . В NeurIPS, 2016. Этот набор данных состоит из 50 000 обучающих изображений и 10 000 тестовых изображений, равномерно распределяется по 100 классам.
946 ДОКУМЕНТОВ • 18 ПОКАЗАТЕЛЕЙ
МуДжоКо
MuJoCo (многосуставная динамика с контактом) — это физический движок, используемый для реализации сред для оценки методов обучения с подкреплением.
934 ДОКУМЕНТА • 2 ПОКАЗАТЕЛЯ
Тренажерный зал OpenAI
OpenAI Gym — это набор инструментов для разработки и сравнения алгоритмов обучения с подкреплением. Он включает в себя такие среды, как Algorithmic, Atari, Box2D, Classic Control, MuJoCo, Robotics и Toy Text.
932 ДОКУМЕНТА • 3 ПОКАЗАТЕЛЯ
Модельнет
Набор данных ModelNet40 содержит облака точек синтетических объектов. ModelNet40, как наиболее широко используемый эталонный тест для анализа облаков точек, популярен благодаря своим различным категориям, четким формам, хорошо структурированному набору данных и т. д. Первоначальный ModelNet40 состоит из 12 311 сгенерированных САПР сеток в 40 категориях (таких как самолет, автомобиль, растение, светильник), из них 9843 используются для обучения, а остальные 2468 зарезервированы для тестирования. Соответствующие точки данных облака точек равномерно выбираются из поверхностей сетки, а затем дополнительно обрабатываются путем перемещения к исходной точке и масштабирования в единичную сферу.
ModelNet40, как наиболее широко используемый эталонный тест для анализа облаков точек, популярен благодаря своим различным категориям, четким формам, хорошо структурированному набору данных и т. д. Первоначальный ModelNet40 состоит из 12 311 сгенерированных САПР сеток в 40 категориях (таких как самолет, автомобиль, растение, светильник), из них 9843 используются для обучения, а остальные 2468 зарезервированы для тестирования. Соответствующие точки данных облака точек равномерно выбираются из поверхностей сетки, а затем дополнительно обрабатываются путем перемещения к исходной точке и масштабирования в единичную сферу.
878 ДОКУМЕНТОВ • 7 ПОКАЗАТЕЛЕЙ
Кинетика (Набор видеоданных Kinetics Human Action)
Набор данных Kinetics — это крупномасштабный высококачественный набор данных для распознавания действий человека в видео. Набор данных состоит из около 500 000 видеоклипов, охватывающих 600 классов действий человека, по крайней мере, 600 видеоклипов для каждого класса действий. Каждый видеоклип длится около 10 секунд и помечен одним классом действия. Видео собраны с YouTube.
Набор данных состоит из около 500 000 видеоклипов, охватывающих 600 классов действий человека, по крайней мере, 600 видеоклипов для каждого класса действий. Каждый видеоклип длится около 10 секунд и помечен одним классом действия. Видео собраны с YouTube.
797 ДОКУМЕНТОВ • 19 ПОКАЗАТЕЛЕЙ
Визуальный геном
Visual Genome содержит данные визуальных ответов на вопросы в настройках с множественным выбором. Он состоит из 101 174 изображений от MSCOCO с 1,7 миллионами пар QA, в среднем 17 вопросов на изображение. По сравнению с набором данных Visual Question Answering, Visual Genome представляет собой более сбалансированное распределение по 6 типам вопросов: что, где, когда, кто, почему и как. Набор данных Visual Genome также представляет 108 000 изображений с густо аннотированными объектами, атрибутами и отношениями.
Набор данных Visual Genome также представляет 108 000 изображений с густо аннотированными объектами, атрибутами и отношениями.
793 ДОКУМЕНТА • 17 ПОКАЗАТЕЛЕЙ
ФильмОбъектив
Наборы данных MovieLens, впервые выпущенные в 1998 году, описывают выраженные предпочтения людей в отношении фильмов. Эти предпочтения имеют форму кортежей, каждый из которых является результатом выражения человеком предпочтения (рейтинг от 0 до 5 звезд) для фильма в определенное время. Эти настройки были введены через веб-сайт MovieLens1 — рекомендательную систему, которая просит своих пользователей давать оценки фильмам, чтобы получать персонализированные рекомендации фильмов.
756 ДОКУМЕНТОВ • 12 ПОКАЗАТЕЛЕЙ
Опубликовано
Опубликовано
Набор данных Pubmed состоит из 19717 научных публикаций из базы данных PubMed, касающихся диабета, отнесенного к одному из трех классов. Сеть цитирования состоит из 44338 ссылок. Каждая публикация в наборе данных описывается взвешенным вектором слов TF/IDF из словаря, состоящего из 500 уникальных слов.
714 ДОКУМЕНТОВ • 16 ПОКАЗАТЕЛЕЙ
Места
Набор данных Places предлагается для распознавания сцен и содержит более 2,5 миллионов изображений, охватывающих более 205 категорий сцен с более чем 5000 изображений в каждой категории.
696 ДОКУМЕНТОВ • 4 ПОКАЗАТЕЛЯ
LFW (с надписью «Лица в дикой природе»)
Набор данных LFW содержит 13 233 изображения лиц, собранных из Интернета. Этот набор данных состоит из 5749удостоверения личности с 1680 людьми с двумя и более изображениями. В стандартном протоколе оценки LFW сообщается о точности проверки для 6000 пар лиц.
681 ДОКУМЕНТЫ • 6 ПОКАЗАТЕЛЕЙ
Рынок-1501
Market-1501 — это крупномасштабный общедоступный эталонный набор данных для повторной идентификации личности. Он содержит 1501 личность, захваченную шестью разными камерами, и 32 668 ограничивающих рамок изображений пешеходов, полученных с помощью детектора пешеходов моделей деформируемых частей. У каждого человека в среднем 3,6 изображения с каждой точки обзора. Набор данных разделен на две части: 750 идентификаторов используются для обучения, а оставшиеся 751 идентификатор используются для тестирования. В официальном протоколе тестирования 3368 изображений-запросов выбираются в качестве тестового набора, чтобы найти правильное совпадение среди 19 изображений.732 изображения галереи ссылок.
Он содержит 1501 личность, захваченную шестью разными камерами, и 32 668 ограничивающих рамок изображений пешеходов, полученных с помощью детектора пешеходов моделей деформируемых частей. У каждого человека в среднем 3,6 изображения с каждой точки обзора. Набор данных разделен на две части: 750 идентификаторов используются для обучения, а оставшиеся 751 идентификатор используются для тестирования. В официальном протоколе тестирования 3368 изображений-запросов выбираются в качестве тестового набора, чтобы найти правильное совпадение среди 19 изображений.732 изображения галереи ссылок.
678 ДОКУМЕНТОВ • 8 ПОКАЗАТЕЛЕЙ
СТЛ-10 (Самообучение 10)
STL-10 — это набор данных изображений, полученный из ImageNet и широко используемый для оценки алгоритмов неконтролируемого изучения признаков или самообучения. Помимо 100 000 немаркированных изображений, он содержит 13 000 помеченных изображений из 10 классов объектов (таких как птицы, кошки, грузовики), среди которых 5 000 изображений разделены для обучения, а остальные 8 000 изображений — для тестирования. Все изображения цветные с 9Размер 6×96 пикселей.
Помимо 100 000 немаркированных изображений, он содержит 13 000 помеченных изображений из 10 классов объектов (таких как птицы, кошки, грузовики), среди которых 5 000 изображений разделены для обучения, а остальные 8 000 изображений — для тестирования. Все изображения цветные с 9Размер 6×96 пикселей.
640 ДОКУМЕНТОВ • 13 ПОКАЗАТЕЛЕЙ
nuScenes
Набор данных nuScenes представляет собой крупномасштабный набор данных для автономного вождения. Набор данных содержит трехмерные ограничивающие рамки для 1000 сцен, собранных в Бостоне и Сингапуре. Каждая сцена длится 20 секунд и аннотируется с частотой 2 Гц. В итоге получается 28130 образцов для обучения, 6019образцы для проверки и 6008 образцов для тестирования. Набор данных содержит полный набор данных об автономных транспортных средствах: 32-лучевой лидар, 6 камер и радаров с полным охватом 360°. Задача обнаружения 3D-объектов оценивает производительность по 10 классам: автомобили, грузовики, автобусы, прицепы, строительные машины, пешеходы, мотоциклы, велосипеды, дорожные конусы и барьеры.
В итоге получается 28130 образцов для обучения, 6019образцы для проверки и 6008 образцов для тестирования. Набор данных содержит полный набор данных об автономных транспортных средствах: 32-лучевой лидар, 6 камер и радаров с полным охватом 360°. Задача обнаружения 3D-объектов оценивает производительность по 10 классам: автомобили, грузовики, автобусы, прицепы, строительные машины, пешеходы, мотоциклы, велосипеды, дорожные конусы и барьеры.
620 ДОКУМЕНТОВ • 12 ПОКАЗАТЕЛЕЙ
QNLI (вопросно-ответный НЛИ)
Набор данных QNLI (вопросно-ответный NLI) представляет собой набор данных для вывода на естественном языке, автоматически полученный из Стэнфордского набора данных для ответов на вопросы v1. 1 (SQuAD). SQuAD v1.1 состоит из пар вопрос-абзац, где одно из предложений в абзаце (взято из Википедии) содержит ответ на соответствующий вопрос (написанный комментатором). Набор данных был преобразован в классификацию пар предложений путем формирования пары между каждым вопросом и каждым предложением в соответствующем контексте и фильтрации пар с низким лексическим перекрытием между вопросом и контекстным предложением. Задача состоит в том, чтобы определить, содержит ли контекстное предложение ответ на вопрос. Эта модифицированная версия исходной задачи удаляет требование, чтобы модель выбирала точный ответ, но также удаляет упрощающие предположения о том, что ответ всегда присутствует во входных данных и что лексическое перекрытие является надежным сигналом. Набор данных QNLI является частью теста GLEU.
1 (SQuAD). SQuAD v1.1 состоит из пар вопрос-абзац, где одно из предложений в абзаце (взято из Википедии) содержит ответ на соответствующий вопрос (написанный комментатором). Набор данных был преобразован в классификацию пар предложений путем формирования пары между каждым вопросом и каждым предложением в соответствующем контексте и фильтрации пар с низким лексическим перекрытием между вопросом и контекстным предложением. Задача состоит в том, чтобы определить, содержит ли контекстное предложение ответ на вопрос. Эта модифицированная версия исходной задачи удаляет требование, чтобы модель выбирала точный ответ, но также удаляет упрощающие предположения о том, что ответ всегда присутствует во входных данных и что лексическое перекрытие является надежным сигналом. Набор данных QNLI является частью теста GLEU.
615 ДОКУМЕНТОВ • 3 ПОКАЗАТЕЛЯ
КАРЛА (Машина учится действовать)
CARLA (CAR Learning to Act) — это открытый симулятор вождения в городе, разработанный как слой с открытым исходным кодом поверх Unreal Engine 4. Технически он работает аналогично слою с открытым исходным кодом поверх Unreal Engine 4, который предоставляет датчики в виде Камеры RGB (с настраиваемыми позициями), карты глубины наземных правд, карты семантической сегментации наземных правд с 12 семантическими классами, предназначенными для вождения (дорога, разметка полосы движения, дорожный знак, тротуар и т. д.), ограничивающие рамки для динамических объектов в окружающей среде и измерения самого агента (местоположение и ориентация транспортного средства).
Технически он работает аналогично слою с открытым исходным кодом поверх Unreal Engine 4, который предоставляет датчики в виде Камеры RGB (с настраиваемыми позициями), карты глубины наземных правд, карты семантической сегментации наземных правд с 12 семантическими классами, предназначенными для вождения (дорога, разметка полосы движения, дорожный знак, тротуар и т. д.), ограничивающие рамки для динамических объектов в окружающей среде и измерения самого агента (местоположение и ориентация транспортного средства).
613 ДОКУМЕНТОВ • 2 ПОКАЗАТЕЛЯ
FFHQ (Flickr-Faces-HQ)
Flickr-Faces-HQ (FFHQ) состоит из 70 000 высококачественных изображений в формате PNG с разрешением 1024×1024 и содержит значительные различия с точки зрения возраста, этнической принадлежности и фона изображения. Он также хорошо охватывает такие аксессуары, как очки, солнцезащитные очки, головные уборы и т. д. Изображения были просканированы с Flickr, таким образом унаследовав все предубеждения этого веб-сайта, и автоматически выровнены и обрезаны с помощью dlib. Были собраны только изображения под разрешающими лицензиями. Для обрезки набора использовались различные автоматические фильтры, и, наконец, Amazon Mechanical Turk был использован для удаления случайных статуй, картин или фотографий с фотографий.
Он также хорошо охватывает такие аксессуары, как очки, солнцезащитные очки, головные уборы и т. д. Изображения были просканированы с Flickr, таким образом унаследовав все предубеждения этого веб-сайта, и автоматически выровнены и обрезаны с помощью dlib. Были собраны только изображения под разрешающими лицензиями. Для обрезки набора использовались различные автоматические фильтры, и, наконец, Amazon Mechanical Turk был использован для удаления случайных статуй, картин или фотографий с фотографий.
601 ДОКУМЕНТЫ • 12 ПОКАЗАТЕЛЕЙ
Сканнет
ScanNet — это набор данных RGB-D для помещений на уровне экземпляра, который включает в себя как 2D-, так и 3D-данные. Это набор помеченных вокселей, а не точек или объектов. К настоящему времени ScanNet v2, новейшая версия ScanNet, собрала 1513 аннотированных сканов с примерно 90% покрытия поверхности. В задаче семантической сегментации этот набор данных размечается в 20 классах аннотированных трехмерных вокселизированных объектов.
Это набор помеченных вокселей, а не точек или объектов. К настоящему времени ScanNet v2, новейшая версия ScanNet, собрала 1513 аннотированных сканов с примерно 90% покрытия поверхности. В задаче семантической сегментации этот набор данных размечается в 20 классах аннотированных трехмерных вокселизированных объектов.
590 ДОКУМЕНТОВ • 14 ПОКАЗАТЕЛЕЙ
HMDB51
Набор данных HMDB51 представляет собой большую коллекцию реалистичных видеороликов из различных источников, включая фильмы и веб-видео. Набор данных состоит из 6849видеоклипы из 51 категории действий (например, «прыгать», «поцелуй» и «смех»), причем каждая категория содержит не менее 101 клипа. Первоначальная схема оценки использует три различных сплита обучения/тестирования. В каждом сплите у каждого класса действия есть 70 клипов для обучения и 30 клипов для тестирования. Средняя точность по этим трем разделениям используется для измерения окончательной производительности.
Первоначальная схема оценки использует три различных сплита обучения/тестирования. В каждом сплите у каждого класса действия есть 70 клипов для обучения и 30 клипов для тестирования. Средняя точность по этим трем разделениям используется для измерения окончательной производительности.
587 ДОКУМЕНТОВ • 13 ПОКАЗАТЕЛЕЙ
МИМИК-III (Магазин медицинской информации для интенсивной терапии III)
Набор данных Medical Information Mart for Intensive Care III (MIMIC-III) представляет собой большую, обезличенную и общедоступную коллекцию медицинских записей. Каждая запись в наборе данных включает МКБ-9.коды, которые идентифицируют диагнозы и выполненные процедуры. Каждый код разделен на подкоды, которые часто включают конкретные косвенные детали. Набор данных состоит из 112 000 записей клинических отчетов (средняя длина 709,3 токена) и 1159 кодов МКБ-9 верхнего уровня. Каждому отчету присваивается в среднем 7,6 кодов. Данные включают основные показатели жизнедеятельности, лекарства, лабораторные измерения, наблюдения и заметки медицинских работников, баланс жидкости, коды процедур, диагностические коды, отчеты о визуализации, продолжительность пребывания в больнице, данные о выживаемости и многое другое.
Каждая запись в наборе данных включает МКБ-9.коды, которые идентифицируют диагнозы и выполненные процедуры. Каждый код разделен на подкоды, которые часто включают конкретные косвенные детали. Набор данных состоит из 112 000 записей клинических отчетов (средняя длина 709,3 токена) и 1159 кодов МКБ-9 верхнего уровня. Каждому отчету присваивается в среднем 7,6 кодов. Данные включают основные показатели жизнедеятельности, лекарства, лабораторные измерения, наблюдения и заметки медицинских работников, баланс жидкости, коды процедур, диагностические коды, отчеты о визуализации, продолжительность пребывания в больнице, данные о выживаемости и многое другое.
585 ДОКУМЕНТОВ • 7 ПОКАЗАТЕЛЕЙ
НеРФ (Поля нейронного излучения)
Neural Radiance Fields (NeRF) — это метод синтеза новых представлений сложных сцен путем оптимизации лежащей в основе функции непрерывной объемной сцены с использованием разреженного набора входных представлений. Набор данных состоит из трех частей, первые две из которых представляют собой синтетические визуализации объектов, называемые Diffuse Synthetic 360◦ и Realistic Synthetic 360◦, а третья — реальные изображения сложных сцен. Diffuse Synthetic 360◦ состоит из четырех ламбертовских объектов с простой геометрией. Каждый объект визуализируется с разрешением 512×512 пикселей с точек обзора, выбранных в верхней полусфере. Realistic Synthetic 360◦ состоит из восьми объектов сложной геометрии и реалистичных неламбертовских материалов. Шесть из них визуализируются из точек обзора, выбранных в верхней полусфере, а два левых — из точек обзора, выбранных в полной сфере, причем все они имеют разрешение 800×800 пикселей. Реальные изображения сложных сцен состоят из 8 сцен, обращенных вперед, снятых мобильным телефоном, размером 1008×756 пикселей.
Набор данных состоит из трех частей, первые две из которых представляют собой синтетические визуализации объектов, называемые Diffuse Synthetic 360◦ и Realistic Synthetic 360◦, а третья — реальные изображения сложных сцен. Diffuse Synthetic 360◦ состоит из четырех ламбертовских объектов с простой геометрией. Каждый объект визуализируется с разрешением 512×512 пикселей с точек обзора, выбранных в верхней полусфере. Realistic Synthetic 360◦ состоит из восьми объектов сложной геометрии и реалистичных неламбертовских материалов. Шесть из них визуализируются из точек обзора, выбранных в верхней полусфере, а два левых — из точек обзора, выбранных в полной сфере, причем все они имеют разрешение 800×800 пикселей. Реальные изображения сложных сцен состоят из 8 сцен, обращенных вперед, снятых мобильным телефоном, размером 1008×756 пикселей.
568 ДОКУМЕНТОВ • 1 ЭТАЛОН
NYUv2 (NYU-Глубина V2)
Набор данных NYU-Depth V2 состоит из видеопоследовательностей различных внутренних сцен, записанных камерами RGB и Depth от Microsoft Kinect. Особенности:
Особенности:
563 ДОКУМЕНТА • 17 ПОКАЗАТЕЛЕЙ
Концептнет
ConceptNet — это граф знаний, который соединяет слова и фразы естественного языка с помеченными ребрами. Его знания собираются из многих источников, включая ресурсы, созданные экспертами, краудсорсинг и целенаправленные игры. Он предназначен для представления общих знаний, связанных с пониманием языка, улучшения приложений на естественном языке, позволяя приложению лучше понимать значения слов, которые люди используют.
559 ДОКУМЕНТОВ • ПОКА НЕТ ЭТАЛОННЫХ
Оксфорд 102 цветок (Набор данных цветов 102 категорий)
Oxford 102 Flower — это набор данных для классификации изображений, состоящий из 102 категорий цветов. В качестве цветов выбраны цветы, обычно произрастающие в Соединенном Королевстве. Каждый класс состоит из от 40 до 258 изображений.
В качестве цветов выбраны цветы, обычно произрастающие в Соединенном Королевстве. Каждый класс состоит из от 40 до 258 изображений.
552 ДОКУМЕНТА • 12 ПОКАЗАТЕЛЕЙ
Офис-Дом
Office-Home — это эталонный набор данных для адаптации домена, который содержит 4 домена, каждый из которых состоит из 65 категорий. Четыре домена: Искусство – художественные образы в виде эскизов, картин, орнаментов и т. д.; Клипарт – коллекция клипартов; Продукт — изображения объектов без фона и Real-World — изображения объектов, снятые обычной камерой. Он содержит 15 500 изображений, в среднем около 70 изображений на класс и максимум 9 изображений. 9 изображений в классе.
9 изображений в классе.
541 ДОКУМЕНТЫ • 9 ПОКАЗАТЕЛЕЙ
LSUN (Масштабная задача понимания сцены)
Целью задачи «Понимание крупномасштабных сцен» (LSUN) является предоставление другого эталона для классификации и понимания крупномасштабных сцен. Набор данных классификации LSUN содержит 10 категорий сцен, таких как столовая, спальня, курица, церковь под открытым небом и так далее. Для обучающих данных каждая категория содержит огромное количество изображений, от 120 000 до 3 000 000. Данные проверки включают 300 изображений, а данные тестирования содержат 1000 изображений для каждой категории.
