Что такое обработка и анализ данных? – Как стать специалистом по обработке и анализу данных
Узнайте, чем занимается специалист по обработке и анализу данных и как стать успешным специалистом по обработке и анализу данных
Что такое специалист по обработке и анализу данных?
Специалист по обработке и анализу данных руководит исследовательскими проектами по извлечению ценной информации из больших данных и имеет опыт в области технологий, математики, бизнеса и коммуникаций. Организации используют эту информацию для принятия лучших решений, решения сложных проблем и улучшения своей деятельности. Выявляя полезную информацию, скрытую в больших наборах данных, специалист по данным может значительно улучшить способность своей компании достигать поставленных целей. Вот почему специалисты по данным пользуются большим спросом и даже считаются «рок-звездами» в деловом мире.
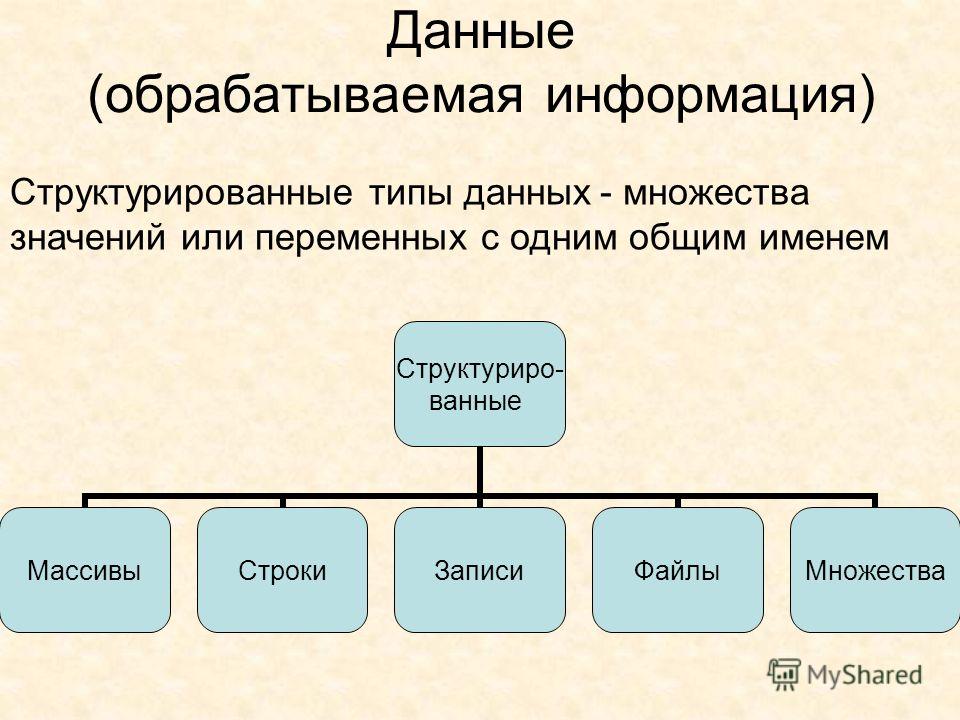
Общие сведения об обработке и анализе данных
Что такое обработка и анализ данных?
Обработка и анализ данных представляет собой научное изучение данных для получения знаний. Эта область объединяет несколько дисциплин для извлечения знаний из массивных наборов данных с целью принятия обоснованных решений и прогнозов. Специалисты по обработке и анализу данных, аналитики данных, архитекторы данных, инженеры данных, статистики, администраторы баз данных и бизнес-аналитики — все они работают в области обработки и анализа данных.
Спрос на обработку и анализ данных быстро возрастает, поскольку объем данных увеличивается в геометрической прогрессии, а компании все больше зависят от аналитики для увеличения доходов и инноваций. Например, по мере того, как бизнес-взаимодействия становятся все более цифровыми, создается больше данных, предоставляя новые возможности для получения информации о том, как лучше персонализировать опыт, улучшить обслуживание и удовлетворенность клиентов, разработать новые и улучшенные продукты и увеличить продажи.
Чем занимается специалист по обработке и анализу данных?
Специалист по обработке и анализу данных собирает, анализирует и интерпретирует большие данные, чтобы выявить закономерности и идеи, сделать прогнозы и создать действенные планы. Большие данные можно определить как наборы данных, которые имеют большее разнообразие, объем и скорость, чем были приспособлены для обработки более ранние методы управления данными. Специалисты по обработке и анализу данных работают со многими типами больших данных, включая:
- Структурированные данные, которые обычно организованы в строки и столбцы и включают слова и числа, такие как имена, даты и данные кредитной карты. Например, специалист по обработке и анализу данных в коммунальной отрасли может анализировать таблицы данных о выработке и использовании электроэнергии, чтобы снизить затраты и выявить закономерности, которые могут привести к отказу оборудования.

- Неструктурированные данные, которые неорганизованы и включают текст в файлах документов, социальные сети и мобильные данные, контент веб-сайтов и видео. Например, специалист по обработке и анализу данных в сфере розничной торговли может ответить на вопрос об улучшении качества обслуживания клиентов, проанализировав неструктурированные заметки колл-центра, электронные письма, опросы и сообщения в социальных сетях.
Кроме того, характеристики набора данных могут быть описаны как
Чтобы получить знания обо всех этих типах данных, специалисты по обработке данных используют свои навыки в следующих областях:
- Компьютерное программирование.

- Математика, статистика и вероятность. Специалисты по обработке данных используют эти навыки для анализа данных, проверки гипотез и создания моделей машинного обучения — файлов, которые специалисты по данным обучают распознавать определенные типы шаблонов. Специалисты по обработке данных используют обученные модели машинного обучения, чтобы обнаруживать взаимосвязи в данных, делать прогнозы относительно данных и находить решения проблем. Вместо того, чтобы создавать и обучать модели с нуля, специалисты по обработке и анализу данных также могут воспользоваться преимуществами автоматизированного машинного обучения для доступа к готовым к производству моделям машинного обучения.

- Знание предметной области. Чтобы преобразовывать данные в релевантные и значимые идеи, которые влияют на результаты бизнеса, специалистам по обработке данных также необходимы знания в предметной области — понимание отрасли и компании, в которой они работают. Вот несколько примеров того, как специалисты по обработке данных могут применять свои знания в предметной области для решения отраслевых проблем.
| Отрасль | Типы проектов обработки и анализа данных |
|---|---|
| Бизнес |
Разработка новых продуктов и усовершенствование продуктов
Цепочка поставок и управление запасами Рекомендации по продуктам для клиентов электронной коммерции |
| Развлечения |
Общие сведения о шаблонах использования содержимого мультимедиа
Разработка содержимого на основе данных целевого рынка Настроенные рекомендации на основе предпочтений пользователя |
| Финансы и банковские услуги |
Предотвращение мошенничества и других нарушений безопасности
Управление рисками инвестиционных портфелей Виртуальные помощники, которые помогут клиентам с вопросами |
| Государственная организация |
Решения политики
Мониторинг удовлетворенности клиентов Обнаружение мошенничества, например заявления о социальной нетрудоспособности |
| Здравоохранение |
Лекарственная терапия, основанная на доказательствах, и экономическая эффективность новых препаратов
Переносные средства отслеживания для улучшения ухода за пациентами |
| Телекоммуникации |
Улучшения обслуживания на основе пользовательских предпочтений и расположений
Минимизация пропущенных вызовов и других проблем с обслуживанием |
| Служебные программы |
Анализ интеллектуальных счетчиков для улучшения использования служебных программ и удовлетворенности клиентов
Улучшенное управление ресурсами и рабочими ресурсами |
Есть еще один навык, который имеет решающее значение для ответа на вопрос «Чем занимается специалист по обработке и анализу данных?» Эффективное доведение результатов их анализа до менеджеров, руководителей и других заинтересованных сторон является одной из наиболее важных частей работы. Специалисты по данным должны сделать свои выводы понятными для нетехнической аудитории, чтобы они могли использовать эти идеи для принятия обоснованных решений. Таким образом, специалисты по обработке данных должны уметь:
Специалисты по данным должны сделать свои выводы понятными для нетехнической аудитории, чтобы они могли использовать эти идеи для принятия обоснованных решений. Таким образом, специалисты по обработке данных должны уметь:
- Общение, публичные выступления и визуализация данных. Большие специалисты по обработке и анализу данных обладают сильными навыками вербального общения, включая рассказывание историй и публичные выступления. В области науки о данных картинка действительно стоит тысячи слов. Представление результатов науки о данных с использованием графиков и диаграмм позволяет аудитории быстро понять данные всего за пять секунд или меньше. По этой причине успешные специалисты по обработке и анализу данных относятся к визуализации данных так же серьезно, как и к их анализу.
Процессы и результаты обработки и анализа данных
Процессы обработки и анализа данных
Специалисты по обработке и анализу данных следуют аналогичному процессу для завершения своих проектов:
-
Специалист по обработке и анализу данных работает с заинтересованными сторонами, чтобы четко определить проблему, которую они хотят решить, или вопрос, на который им нужно ответить, а также цели проекта и требования к решению.

-
На основе бизнес-задачи, специалист по обработке и анализу данных решает, какой аналитический подход использовать: 1) описательный для получения дополнительной информации о текущем состоянии, 2) диагностический, чтобы понять, что происходит и почему, 3) прогнозирующий, чтобы спрогнозировать, что произойдет, или 4) предписывающий, чтобы понять, как решить проблему.
-
Специалист по данным идентифицирует и получает данные, необходимые для достижения желаемого результата. Это может включать запросы к базам данных, извлечение информации с веб-сайтов (веб-извлечение) или получение данных из файлов. Данные могут быть доступны внутри компании, или команде может потребоваться приобрести данные. В некоторых случаях организациям может потребоваться собрать новые данные, чтобы иметь возможность успешно запустить проект.
-
Как правило, этот этап занимает больше всего времени.
 Чтобы создать набор данных для моделирования, специалист по обработке и анализу данных преобразует все данные в один и тот же формат, упорядочивает данные, удаляет ненужные данные и заменяет недостающие данные.
Чтобы создать набор данных для моделирования, специалист по обработке и анализу данных преобразует все данные в один и тот же формат, упорядочивает данные, удаляет ненужные данные и заменяет недостающие данные. -
После очистки данных специалист по обработке и анализу данных изучает данные и применяет методы статистического анализа для выявления взаимосвязей между особенностями данных, а также статистических взаимосвязей между ними и предсказываемыми ими значениями (известными как метки). Предсказанная метка может быть количественным значением, например финансовой стоимостью чего-либо в будущем или продолжительностью задержки рейса в минутах.
Исследование и подготовка обычно включают в себя большой объем интерактивного анализа и визуализации данных, — обычно с использованием таких языков, как Python и R, в интерактивных инструментах и средах, специально предназначенных для этой задачи. Сценарии, используемые для изучения данных, обычно размещаются в специализированных средах, таких как Jupyter Notebooks.
 Эти инструменты позволяют специалистам по обработке и анализу данных программно исследовать данные, а также документировать полученные результаты и делиться ими.
Эти инструменты позволяют специалистам по обработке и анализу данных программно исследовать данные, а также документировать полученные результаты и делиться ими. -
Специалист по обработке и анализу данных создает и обучает предписывающие или описательные модели, затем тестирует и оценивает модель, чтобы убедиться, что она отвечает на вопрос или решает бизнес-проблему. Проще говоря, модель — это фрагмент кода, который принимает входные данные и производит выходные данные. Создание модели машинного обучения включает в себя выбор алгоритма, предоставление ему данных и настройку гиперпараметров. Гиперпараметры — это настраиваемые параметры, которые позволяют специалистам по данным контролировать процесс обучения модели. Например, в нейронных сетях специалист по данным определяет количество скрытых слоев и количество узлов в каждом слое. Настройка гиперпараметров, также называемая оптимизацией гиперпараметров, — это процесс поиска конфигурации гиперпараметров, обеспечивающей наилучшую производительность.

Распространенный вопрос: «Какой алгоритм машинного обучения мне следует использовать?» Алгоритм машинного обучения превращает набор данных в модель. Алгоритм, который выбирает специалист по данным, зависит в первую очередь от двух различных аспектов сценария обработки данных:
- На какой бизнес-вопрос специалист по обработке и анализу данных хочет ответить, изучая прошлые данные?
- Каковы требования сценария обработки данных, включая точность, время обучения, линейность, количество параметров и количество функций?
Чтобы помочь ответить на эти вопросы, Машинное обучение Azure предоставляет полный набор алгоритмов, таких как Лес принятия решений по нескольким классам, Системы рекомендаций, Регрессия нейронной сети, Нейронная сеть по нескольким классам и Кластеризация методом k-средних. Каждый алгоритм предназначен для решения определенного типа задач машинного обучения. Кроме того, Памятка по алгоритму машинного обучения Azure помогает специалистам по данным выбрать правильный алгоритм для ответа на бизнес-вопрос.

-
Специалист по обработке и анализу данных предоставляет окончательную модель с документацией и развертывает новый набор данных в рабочей среде после тестирования, чтобы он мог играть активную роль в бизнесе. Прогнозы развернутой модели можно использовать для принятия бизнес-решений.
-
Средства визуализации, такие как Microsoft Power BI, Tableau, Apache wSuperset и Metabase, упрощают исследователю данных изучение данных и создание красивых визуализаций, которые показывают результаты таким образом, чтобы их было легко понять нетехнической аудитории.
Специалисты по данным могут также использовать веб-записные книжки для обработки данных, такие как Zeppelin Notebooks, на протяжении большей части процесса приема данных, их обнаружения, аналитики, визуализации и совместной работы.
Методы обработки и анализа данных
Специалисты по обработке данных используют статистические методы, такие как проверка гипотез, анализ факторов, регрессионный анализ и кластеризация, чтобы получить статистически обоснованные выводы.
Документация по обработке и анализу данных
Хотя документация по обработке и анализу данных различается в зависимости от проекта и отрасли, обычно она включает документацию, показывающую, откуда берутся данные и как они были изменены. Это помогает другим членам группы данных эффективно использовать данные в будущем. Например, документация помогает бизнес-аналитикам использовать инструменты визуализации для интерпретации набора данных.
Типы документации по обработке и анализу данных включают:
- Проект для определения бизнес-целей проекта, метрик оценки, ресурсов, временной шкалы и бюджета.
- Пользовательские истории обработки и анализа данных для создания идей для проектов по обработке и анализу данных.
 Специалист по обработке и анализу данных записывает историю с точки зрения заинтересованного лица, описывая, чего заинтересованное лицо хотело бы достичь, и причину, по которой заинтересованное лицо запрашивает проект.
Специалист по обработке и анализу данных записывает историю с точки зрения заинтересованного лица, описывая, чего заинтересованное лицо хотело бы достичь, и причину, по которой заинтересованное лицо запрашивает проект. - Документация модели обработки и анализа данных для документирования набора данных, плана эксперимента и алгоритмов.
- Вспомогательная системная документация, включая руководства пользователя, документацию по инфраструктуре для обслуживания системы и документацию по коду.
Как стать специалистом по обработке и анализу данных
Существует несколько способов стать специалистом по данным. Требования обычно включают степень в области информационных технологий или информатики. Однако некоторые ИТ-специалисты изучают обработку и анализ данных, посещая учебные курсы и онлайн-курсы, а другие получают степень магистра или сертификат по обработке и анализу данных.
Чтобы узнать, как стать специалистом по обработке данных, воспользуйтесь этими учебными ресурсами Майкрософт, которые помогут вам:
- быстро приступить к. Ознакомьтесь с бесплатной электронной книгой Packt Принципы обработки и анализа данных, руководство для начинающих по статистическим методам и теории. Вы изучите основы статистического анализа и машинного обучения, ключевые термины и процессы обработки и анализа данных.
- Развивайте навыки машинного обучения с помощью Azure, облачной платформы Майкрософт. Изучите ресурсы Azure по машинному обучению для специалистов по обработке и анализу данных, в том числе бесплатные обучающие видео, примеры архитектур решений и истории клиентов.
- Получите опыт машинного обучения в Azure бесплатно всего за 4 недели. Выделите час в день, чтобы научиться создавать инновационные решения для сложных проблем. Вы изучите основы масштабирования проектов машинного обучения с использованием новейших инструментов и платформ.
 Самостоятельный путь машинного обучения от нуля до героя также подготовит вас к получению сертификата Azure Data Scientist Associate.
Самостоятельный путь машинного обучения от нуля до героя также подготовит вас к получению сертификата Azure Data Scientist Associate. - Пройдите комплексное обучение. Воспользуйтесь схемой обучения специалистов по обработке и анализу данных Майкрософт и выберите один из курсов для самостоятельного обучения или курсов под руководством инструктора. Узнайте, как создавать модели машинного обучения, использовать визуальные инструменты, запускать рабочие нагрузки по обработке и анализу данных в облаке и создавать приложения, поддерживающие обработку естественного языка.
Получите сертификат специалиста по обработке и анализу данных
Сертификаты — отличный способ продемонстрировать свою квалификацию в области обработки и анализа данных и начать карьеру. Сертифицированные специалисты Майкрософт пользуются большим спросом, и прямо сейчас есть вакансии для специалистов по обработке и анализу данных Azure. Ознакомьтесь с сертификатами обработки и анализа данных, наиболее часто используемых работодателями:
Ознакомьтесь с сертификатами обработки и анализа данных, наиболее часто используемых работодателями:
- Сертифицировано Майкрософт: специалист по обработке и анализу данных Azure. Примените свои знания в области обработки и анализа данных и машинного обучения для реализации и запуска рабочих нагрузок машинного обучения в Azure с помощью службы машинного обучения Azure.
- Сертификация Майкрософт: специальность платформы клиентских данных. Внедряйте решения, которые предоставляют информацию о профилях клиентов и отслеживают действия по взаимодействию, чтобы улучшить качество обслуживания клиентов и повысить их удержание.
Разница между аналитиками данных и специалистами по обработке и анализу данных
Как и специалисты по обработке и анализу данных, аналитики данных работают с большими наборами данных, чтобы выявить тенденции в данных. Однако специалисты по обработке и анализу данных, как правило, являются более техническими членами команды с большим опытом и ответственностью, такими как инициирование и руководство проектами по науке о данных, создание и обучение моделей машинного обучения, а также представление своих результатов руководителям и на конференциях. Некоторые специалисты по обработке и анализу данных выполняют все эти задачи, а другие сосредотачиваются на конкретных, таких как алгоритмы обучения или построение моделей. Многие специалисты по данным начали свою карьеру в качестве аналитиков данных, а аналитики данных могут быть повышены до должностей специалистов по обработке и анализу данных в течение нескольких лет.
Некоторые специалисты по обработке и анализу данных выполняют все эти задачи, а другие сосредотачиваются на конкретных, таких как алгоритмы обучения или построение моделей. Многие специалисты по данным начали свою карьеру в качестве аналитиков данных, а аналитики данных могут быть повышены до должностей специалистов по обработке и анализу данных в течение нескольких лет.
| Недоступно | Аналитик данных | Специалист по обработке и анализу данных |
|---|---|---|
| Роль | Статистический анализ данных | Разработка решений для сложных бизнес-потребностей с использованием больших данных |
| Стандартные инструменты | Microsoft Excel, SQL, Tableau, Power BI | SQL, Python, R, Julia, Hadoop, Apache Spark, SAS, Tableau, машинное обучение, Apache Superset, Power BI, записные книжки по обработке и анализу данных |
| Анализ типов данных | Структурированные данные | Структурированные и неструктурированные данные |
| Задачи и обязанности |
|
|


-
Специалист по обработке и анализу данных руководит исследовательскими проектами по извлечению ценной информации из больших данных и имеет опыт в области технологий, математики, бизнеса и коммуникаций. Организации используют эту информацию для принятия лучших решений, решения сложных проблем и улучшения своей деятельности. Выявляя полезную информацию, скрытую в больших наборах данных, такие специалисты могут значительно улучшить способность своей компании достигать поставленных целей. Вот почему специалисты по обработке и анализу данных пользуются большим спросом и даже считаются «рок-звездами» в деловом мире.
Подробнее о роли специалиста по обработке и анализу данных
-
Обработка и анализ данных представляет научное изучение данных для получения знаний.
 Эта область объединяет несколько дисциплин для извлечения знаний из массивных наборов данных с целью принятия обоснованных решений и прогнозов.
Эта область объединяет несколько дисциплин для извлечения знаний из массивных наборов данных с целью принятия обоснованных решений и прогнозов.Знакомство с обработкой и анализом данных
-
Специалисты по обработке данных возглавляют исследовательские проекты для извлечения ценной информации и практических идей из больших данных. Эта деятельность включает в себя определение проблемы, которую необходимо решить, написание запросов для извлечения нужных данных из баз данных, очистку и сортировку данных, создание и обучение моделей машинного обучения, а также использование методов визуализации данных для эффективной передачи результатов заинтересованным сторонам.
Узнайте, как специалисты по обработке данных извлекают знания из данных
-
Документация по обработке и анализу данных различается в зависимости от проекта и отрасли, но обычно содержит планы проектов, пользовательские истории, документацию по моделям и вспомогательную документацию по системам, например, руководства пользователя.
Подробнее о документации по обработке и анализу данных
-
Некоторые ИТ-специалисты изучают обработку и анализ данных с помощью семинаров и онлайн-курсов, другие получают степень магистра или сертификат. Сертификаты — отличный способ продемонстрировать свою квалификацию в области обработки и анализа данных и начать карьеру. Сертифицированные специалисты Майкрософт весьма востребованы: прямо сейчас есть вакансии для специалистов по обработке и анализу данных Azure.
Изучите учебные ресурсы и сертификаты по обработке и анализу данных
-
Как и специалисты по обработке и анализу данных, аналитики данных работают с большими наборами данных, чтобы выявить тенденции в данных. Тем не менее, специалисты по обработке и анализу данных — это больше технические члены команды с большим опытом и ответственностью, такие как инициирование и руководство проектами по науке о данных, создание и обучение моделей машинного обучения, а также представление результатов своих проектов руководителям и на конференциях.
 Некоторые специалисты по обработке и анализу данных выполняют все эти задачи, а другие сосредотачиваются на конкретных, таких как алгоритмы обучения или построение моделей.
Некоторые специалисты по обработке и анализу данных выполняют все эти задачи, а другие сосредотачиваются на конкретных, таких как алгоритмы обучения или построение моделей.См. сравнение обязанностей специалиста по обработке и анализу данных и аналитика данных
Дополнительные ресурсы
Ознакомление
Вебинары
Руководства
Начало работы с бесплатной учетной записью Azure
Получите доступ к популярным службам Azure бесплатно в течение 12 месяцев, более 25 постоянно доступных служб, бесплатных всегда, и кредит в сумме $200 на ваш счет для использования в течение первых 30 дней.
Начните бесплатно
Связаться со специалистом по продажам ИИ Azure
Получите рекомендации о том, как приступить к работе с ИИ Azure. Задавайте вопросы, узнавайте о ценах и рекомендациях, а также получайте помощь с разработкой решения, соответствующего вашим потребностям.
Связаться с нами
Определение потоковой передачи данных | Amazon Web Services (AWS)
Потоковые данные – это данные, непрерывно генерируемые тысячами источников данных, которые обычно отправляют записи данных одновременно и небольшими объемами (по несколько килобайтов). В состав потоковых данных входят различные виды данных, например файлы журналов, сформированных клиентами при использовании мобильных или интернет-приложений, покупки в интернет-магазинах, действия игроков в играх, информация из социальных сетей, финансовые торговые площадки и геопространственные сервисы, а также телеметрические данные, полученные от подключенных устройств или оборудования в ЦОД.
Эти данные должны быть обработаны последовательно и инкрементно либо по каждой из записей, либо с использованием скользящего временного окна, после чего их можно использовать в различных аналитических задачах, включая корреляцию, агрегацию, фильтрацию и шаблонизацию. Информация, полученная в результате подобного анализа, позволяет компаниям разобраться во многих аспектах своей деятельности, например в использовании сервисов (для задач учета/выставления счетов), активности серверов, навигации по веб-сайтам, геолокации устройств, людей или товаров, и в результате быстро реагировать на изменяющиеся условия. К примеру, компании могут отслеживать изменения общественного настроя в отношении своих торговых марок и продуктов за счет постоянного анализа потоков данных из социальных сетей, а в случае необходимости принимать своевременные меры.
Информация, полученная в результате подобного анализа, позволяет компаниям разобраться во многих аспектах своей деятельности, например в использовании сервисов (для задач учета/выставления счетов), активности серверов, навигации по веб-сайтам, геолокации устройств, людей или товаров, и в результате быстро реагировать на изменяющиеся условия. К примеру, компании могут отслеживать изменения общественного настроя в отношении своих торговых марок и продуктов за счет постоянного анализа потоков данных из социальных сетей, а в случае необходимости принимать своевременные меры.
Преимущества потоковой передачи данных
Обработка потоковых данных является предпочтительной для большинства сценариев использования, подразумевающих непрерывное формирование новых динамических данных. Обработка потоковых данных применима в большинстве отраслевых сегментов и случаев использования, подразумевающих обработку больших данных. Обычно компании начинают с простых задач, например со сбора данных системных журналов, или с элементарных вычислений, например с обновления минимумов и максимумов. Затем эти задачи трансформируются в более сложную обработку, происходящую в режиме, близком к реальному времени. Изначально приложения могут обрабатывать потоки данных с целью формирования простых отчетов и выполнения простых ответных действий, например активации сигнализации, когда значения ключевых параметров выйдут за указанные границы. В итоге этим приложениям приходится выполнять более сложные формы анализа данных, например применять алгоритмы машинного обучения и достигать более глубокого понимания ситуации на основании данных. С течением времени в этот процесс также добавляются комплексные алгоритмы обработки потоков и событий, например анализ временных окон для определения самых свежих популярных кинофильмов, что позволяет получать еще более полезную аналитическую информацию.
Затем эти задачи трансформируются в более сложную обработку, происходящую в режиме, близком к реальному времени. Изначально приложения могут обрабатывать потоки данных с целью формирования простых отчетов и выполнения простых ответных действий, например активации сигнализации, когда значения ключевых параметров выйдут за указанные границы. В итоге этим приложениям приходится выполнять более сложные формы анализа данных, например применять алгоритмы машинного обучения и достигать более глубокого понимания ситуации на основании данных. С течением времени в этот процесс также добавляются комплексные алгоритмы обработки потоков и событий, например анализ временных окон для определения самых свежих популярных кинофильмов, что позволяет получать еще более полезную аналитическую информацию.
Примеры потоковой передачи данных
- Датчики, используемые в транспортных средствах, промышленном оборудовании и сельскохозяйственной технике, отправляют данные в потоковое приложение.
 Приложение осуществляет мониторинг производительности, предупреждает возникновение возможных дефектов и автоматически заказывает необходимые запасные части для предотвращения простоя оборудования.
Приложение осуществляет мониторинг производительности, предупреждает возникновение возможных дефектов и автоматически заказывает необходимые запасные части для предотвращения простоя оборудования. - Финансовое учреждение отслеживает изменения на фондовых биржах в режиме реального времени, вычисляет рисковую стоимость и автоматически выполняет ребалансировку портфеля ценных бумаг на основании изменений биржевого курса.
- Веб-сайт агентства недвижимости отслеживает набор данных, полученный с мобильных устройств клиентов, и предоставляет рекомендации по объектам недвижимости в режиме реального времени на основании данных геолокации.
- Гелиоэнергетическая компания должна предоставлять своим клиентам определенную проходную мощность, в противном случае ей придется платить штрафы. Она развернула приложение для обработки потоковых данных, которое осуществляет мониторинг всех используемых солнечных батарей и планирует необходимое обслуживание в режиме реального времени, что позволяет минимизировать периоды генерации низкой проходной мощности для каждой из батарей и избежать уплаты штрафов.

- Мультимедийный издатель осуществляет потоковую передачу миллиардов записей со своих онлайновых ресурсов, выполняет агрегацию и дополнение данных с учетом демографической информации о пользователях и оптимизирует размещение контента на веб-сайте, благодаря чему обеспечивается релевантность контента и повышается качество обслуживания посетителей.
- Компания-разработчик интернет-игр выполняет сбор потоковых данных о взаимодействиях игроков с играми и передает эти данные на игровую платформу. Затем выполняется анализ этих данных в режиме реального времени, в результате чего формируются стимулы и динамические эффекты для повышения вовлеченности игроков.
Сравнение пакетной и потоковой обработки
Перед началом работы с потоковой передачей данных стоит сравнить потоковую обработку с пакетной обработкой и выявить различия. Пакетная обработка может использоваться для вычислений по любым запросам к данным из разных наборов. Обычно при расчете результатов подобной обработки используются все входящие в пакет данные, благодаря чему обеспечивается глубокий анализ наборов больших данных. В качестве примера платформ, поддерживающих пакетные задания, можно привести системы, использующие MapReduce, например Amazon EMR. В то же время потоковая обработка требует подачи последовательностей данных и инкрементного обновления метрик, отчетов и итоговой статистики в ответ на каждую поступающую запись данных. Этот тип обработки лучше всего подходит для мониторинга в режиме реального времени и функций ответа.
Обычно при расчете результатов подобной обработки используются все входящие в пакет данные, благодаря чему обеспечивается глубокий анализ наборов больших данных. В качестве примера платформ, поддерживающих пакетные задания, можно привести системы, использующие MapReduce, например Amazon EMR. В то же время потоковая обработка требует подачи последовательностей данных и инкрементного обновления метрик, отчетов и итоговой статистики в ответ на каждую поступающую запись данных. Этот тип обработки лучше всего подходит для мониторинга в режиме реального времени и функций ответа.
Многие организации выстраивают гибридные модели за счет комбинации двух подходов и поддерживают операции как на уровне реального времени, так и на пакетном уровне. Сначала данные обрабатываются с помощью платформы потоковых данных, например Amazon Kinesis, с целью извлечения важной информации в режиме реального времени, а затем размещаются в хранилище, например Amazon S3, где преобразуются и загружаются для решения различных задач пакетной обработки.
Возможные проблемы при работе с потоковыми данными
Обработка потоковых данных требует использования двух уровней: уровня хранилища и уровня обработки. Уровень хранилища должен поддерживать очередность записей и строгую непротиворечивость для обеспечения быстрых, экономичных и воспроизводимых операций записи и чтения больших потоков данных. Уровень обработки отвечает за потребление данных, расположенных на уровне хранилища, выполнение вычислений с использованием этих данных и уведомление уровня хранилища о том, какие данные можно удалить за ненадобностью. Кроме того, необходимо предусмотреть масштабируемость, надежность данных и отказоустойчивость как на уровне хранилища, так и на уровне обработки. В результате появилось множество платформ, предоставляющих необходимую инфраструктуру для создания приложений обработки потоковых данных, включая
Amazon Kinesis Data Streams,
Amazon Kinesis Data Firehose,
Amazon Managed Streaming for Apache Kafka (Amazon MSK), Apache Flume, Apache Spark Streaming и Apache Storm.
Работа с потоковыми данными в AWS
Amazon Web Services (AWS) предлагает различные варианты работы с потоковыми данными. Вы можете воспользоваться управляемыми сервисами потоковых данных, предлагаемых Amazon Kinesis, или развернуть в Amazon EC2 собственное решение и использовать его для работы с потоковыми данными в облаке.
Amazon Kinesis – это платформа для работы с потоковыми данными в AWS. Она предлагает мощные сервисы, которые упрощают загрузку и анализ потоковых данных, а также позволяет создавать свои собственные настраиваемые приложения для решения специфических задач, возникающих при обработке потоковых данных. Она предлагает три сервиса: Amazon Kinesis Data Firehose, Amazon Kinesis Data Streams и Amazon Managed Streaming for Apache Kafka (Amazon MSK).
Кроме того, вы можете использовать другие платформы потоковых данных, например Apache Flume, Apache Spark Streaming и Apache Storm, в Amazon EC2 и Amazon EMR.
Amazon Kinesis Data Streams
Сервис Amazon Kinesis Data Streams позволяет создавать настраиваемые приложения для обработки или анализа данных в режиме реального времени для решения узкоспециальных задач. Он может непрерывно захватывать и сохранять данные из сотен тысяч источников со скоростью несколько терабайтов в час. У вас есть возможность создавать приложения, потребляющие данные из Amazon Kinesis Data Streams, для работы панелей управления в режиме реального времени, выдачи оповещений, реализации динамического ценообразования, проведения рекламных кампаний и т. д. Amazon Kinesis Data Streams поддерживает платформы потоковой обработки, выбранные пользователем, включая Kinesis Client Library (KCL), Apache Storm и Apache Spark Streaming.
Подробнее об Amazon Kinesis Data Streams »
Amazon Kinesis Data Firehose
Amazon Kinesis Data Firehose – самый простой способ загрузки потоковых данных в AWS. Этот инструмент позволяет захватывать и автоматически загружать потоковые данные в Amazon S3 и Amazon Redshift, а затем выполнять анализ с помощью имеющихся средств бизнес-аналитики и информационных панелей практически в режиме реального времени. Он позволяет быстро реализовать подход ELT и воспользоваться преимуществами от использования потоковых данных.
Подробнее об Amazon Kinesis Data Firehose »
Amazon Managed Streaming for Apache Kafka (Amazon MSK)
Amazon MSK – это полностью управляемый сервис, который упрощает создание и запуск приложений, использующих Apache Kafka для обработки потоковых данных. Apache Kafka – это платформа с открытым исходным кодом для создания потоковых конвейеров данных и приложений в реальном времени. С помощью Amazon MSK вы можете использовать собственные API-интерфейсы Apache Kafka для заполнения озер данных, потоковой передачи измененных данных в базы данных и обратно, а также для мощных приложений машинного обучения и аналитики.
Подробнее об Amazon MSK »
Прочие потоковые решения в Amazon EC2
Пользователи могут установить платформы потоковых данных в Amazon EC2 и Amazon EMR по собственному усмотрению, а также создать собственные уровни хранилища и обработки. Создавая собственное решение для обработки потоковых данных в Amazon EC2 и Amazon EMR, можно избежать сложностей при выделении инфраструктуры и получить доступ к разнообразным вариантам хранения и обработки потоковых данных. Для уровня хранилища потоковых данных доступны варианты Amazon MSK и Apache Flume. Для уровня обработки потоковых данных доступны варианты Apache Spark Streaming и Apache Storm.
Для уровня хранилища потоковых данных доступны варианты Amazon MSK и Apache Flume. Для уровня обработки потоковых данных доступны варианты Apache Spark Streaming и Apache Storm.
Дальнейшие шаги
- Узнайте больше об Amazon MSK
- Узнайте больше об Amazon Kinesis
- Узнайте о сервисах для работы с большими данными на платформе AWS
- См. страницу Apache Spark в Amazon EMR
- Преобразуйте потоковые данные в аналитические результаты за несколько щелчков мышью с помощью Amazon Kinesis Data Firehose и Amazon Redshift
Зарегистрируйте бесплатный аккаунт
Получите мгновенный доступ к уровню бесплатного пользования AWS.
Регистрация
Начать разработку в консоли
Начните разработку для сервиса Amazon Kinesis в Консоли управления AWS.
Вход
Вход в Консоль
Подробнее об AWS
- Что такое AWS?
- Что такое облачные вычисления?
- Инклюзивность, многообразие и равенство AWS
- Что такое DevOps?
- Что такое контейнер?
- Что такое озеро данных?
- Безопасность облака AWS
- Новые возможности
- Блоги
- Пресс‑релизы
Ресурсы для работы с AWS
- Начало работы
- Обучение и сертификация
- Портфолио решений AWS
- Центр архитектурных решений
- Вопросы и ответы по продуктам и техническим темам
- Отчеты аналитиков
- Партнерская сеть AWS
Разработчики на AWS
- Центр разработчика
- Пакеты SDK и инструментарий
- .
 NET на AWS
NET на AWS - Python на AWS
- Java на AWS
- PHP на AWS
- JavaScript на AWS
Поддержка
- Связаться с нами
- Работа в AWS
- Обратиться в службу поддержки
- Центр знаний
- AWS re:Post
- Обзор AWS Support
- Юридическая информация
Amazon.com – работодатель равных возможностей. Мы предоставляем равные права представителям меньшинств, женщинам, лицам с ограниченными возможностями, ветеранам боевых действий и представителям любых гендерных групп любой сексуальной ориентации независимо от их возраста.
Поддержка AWS для Internet Explorer заканчивается 07/31/2022. Поддерживаемые браузеры: Chrome, Firefox, Edge и Safari. Подробнее »
Что такое большие данные? | Oracle СНГ
Определение больших данных
Большие данные: что именно обозначает этот термин?
Большие данные — это разнообразные данные, поступающие с более высокой скоростью, объем которых постоянно растет. Таким образом, три основных свойства больших данных — это разнообразие, высокая скорость поступления и большой объем.
Таким образом, три основных свойства больших данных — это разнообразие, высокая скорость поступления и большой объем.
Если говорить простыми словами, большие данные — более крупные и сложные наборы данных, особенно из новых источников. Размер этих наборов данных настолько велик, что традиционные программы для обработки не могут с ними справиться. Однако эти большие данные можно использовать для решения бизнес-задач, которые раньше не могли быть решены.
Решения для больших данных
Основные свойства больших данных
| Объем | Количество данных — важный фактор. Располагая ими в больших количествах, Вам потребуется обрабатывать большие объемы неструктурированных данных низкой плотности. Ценность таких данных не всегда известна. Это могут быть данные каналов Twitter, данные посещаемости веб-страниц, а также данные мобильных приложений, сетевой трафик, данные датчиков. В некоторые организации могут поступать десятки терабайт данных, в другие — сотни петабайт. |
| Скорость | Скорость в данном контексте — это быстрота приема данных и, возможно, действий на их основе. Обычно высокоскоростные потоки данных поступают прямо в оперативную память, а не записываются на диск. Некоторые «умные» продукты с поддержкой Интернета работают в режиме реального или практически реального времени. Соответственно, такие данные требуют оценки и действий в реальном времени. |
| Разнообразие | Разнообразие означает, что доступные данные принадлежат к разным типам. Традиционные типы данных структурированы и могут быть сразу сохранены в реляционной базе данных. С появлением Big Data, данные стали поступать в неструктурированном виде. Такие неструктурированные и полуструктурированные типы данных как текст, аудио и видео, требуют дополнительной обработки для определения их значения и поддержки метаданных. |
Ценность больших данных и их достоверность
Еще два свойства сформировались за последние несколько лет: ценность и достоверность. Данные имеют внутренне присущую им ценность. Однако чтобы они приносили пользу, эту ценность необходимо раскрыть. Не менее важно и то, насколько достоверны Ваши большие данные и насколько Вы можете на них полагаться.
Данные имеют внутренне присущую им ценность. Однако чтобы они приносили пользу, эту ценность необходимо раскрыть. Не менее важно и то, насколько достоверны Ваши большие данные и насколько Вы можете на них полагаться.
Сегодня большие данные стали разновидностью капитала. Подумайте о крупнейших технологических компаниях. Ценность их предложений в значительной степени зависит от их данных, которые они постоянно анализируют, чтобы повышать эффективность и разрабатывать новые продукты.
Новейшие достижения в сфере технологий позволили значительно снизить стоимость хранилищ и вычислений, что дает возможность хранить и обрабатывать постоянно растущие объемы данных. Современные технологии позволяют хранить и обрабатывать больше данных за меньшую стоимость, что позволяет Вам принимать более точные и взвешенные бизнес-решения.
Извлечение ценности из больших данных не сводится только к их анализу (это их отдельное преимущество). Речь о комплексном исследовательском процессе с участием специалистов по глубокому анализу, корпоративных пользователей и руководителей, которые будут задавать правильные вопросы, выявлять шаблоны, делать обоснованные предположения и предсказывать поведение.
Но как мы к этому пришли?
История больших данных
Хотя сама по себе концепция больших данных не нова, первые большие наборы данных начали использовать в 1960-70 гг., когда появились первые в мире ЦОД и реляционные базы данных.
К 2005 году бизнес начал осознавать, насколько велик объем данных, которые пользователи создают при использовании Facebook, YouTube и других интернет-сервисов. В том же году появилась платформа Hadoop на основе открытого кода, которая была создана специально для хранения и анализа наборов больших данных. В то же время начала набирать популярность методология NoSQL.
Появление платформ на основе открытого кода, таких как Hadoop и позднее Spark, сыграло значительную роль в распространении больших данных, так как эти инструменты упрощают обработку больших данных и снижают стоимость хранения. За прошедшие годы объемы больших данных возросли на порядки. Огромные объемы данных появляются в результате деятельности пользователей — но теперь не только их.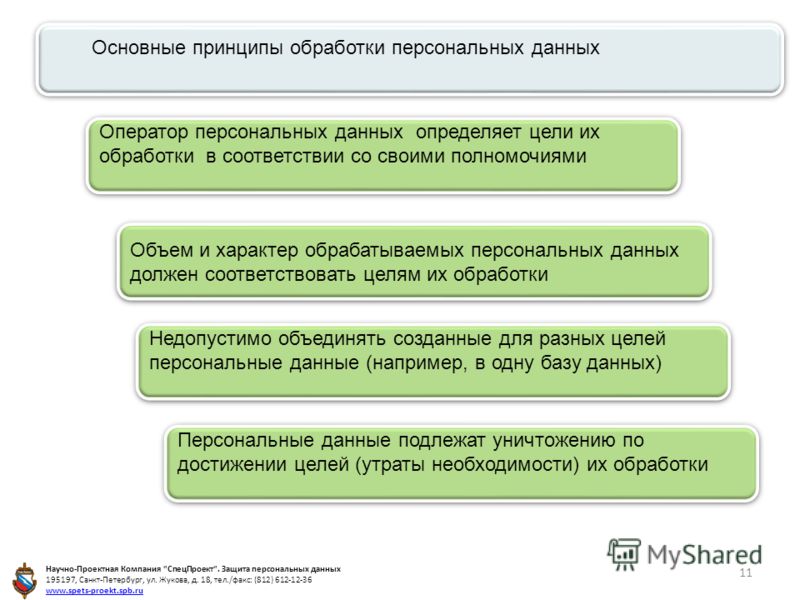
С появлением Интернета вещей (IoT) все большее число устройств получает подключение к Интернету, что позволяет собирать данные о моделях действий пользователей и работе продуктов. А когда появились технологии машинного обучения, объем данных вырос еще больше.
Большие данные имеют долгую историю развития, однако их потенциал еще далеко не раскрыт. Облачные вычисления раздвинули границы применения больших данных еще шире. Облачные технологии обеспечивают по-настоящему гибкие возможности масштабирования, что позволяет разработчикам развертывать кластеры для тестирования выборочных данных по требованию. Кроме того, также все более значимыми становятся графовые базы данных, позволяющие отображать громадные объемы данных так, чтобы анализировать их можно было быстро и всеобъемлюще.
Загрузить электронную книгу с примерами использования графов
Преимущества больших данных
- Большие данные дают возможность получать более полные ответы, потому они предоставляют больше информации.
- Более подробные ответы означают, что Вы можете быть более уверены в достоверности данных — что обеспечивает абсолютно новый подход к решению задач.
Примеры использования больших данных
Большие данные можно применять в самых различных сферах деятельности — от взаимодействия с заказчиками до аналитики. Вот лишь несколько сценариев практического использования.
| Разработка продуктов | Такие компании, как Netflix и Procter & Gamble, используют большие данные для прогнозирования потребительского спроса. Они классифицируют ключевые атрибуты существующих и снятых с использования продуктов и услуг и моделируют связи между этими атрибутами и коммерческим успехом предложений, чтобы создавать предиктивные модели для новых продуктов и услуг. Кроме того, P&G использует данные и статистику, получаемые от фокусных групп, а также из социальных сетей, по результатам рыночных тестов и пробных продаж, после чего выпускает новые продукты. |
| Предиктивное управление обслуживанием | Факторы, которые позволяют прогнозировать сбои механики, могут скрываться в недрах структурированных данных, таких как год, марка и модель оборудования, или в неструктурированных данных, таких как записи журналов, данные датчиков, сообщения об ошибках и сведения о температуре двигателя. Проанализировав индикаторы вероятных проблем до их возникновения, организации могут повысить экономическую эффективность техобслуживания и максимально продлить срок службы запчастей и оборудования. |
| Взаимодействие с заказчиками | Борьба за заказчиков в самом разгаре. Сегодня получить точные данные о качестве обслуживания клиентов проще, чем когда-либо. Большие данные позволят Вам извлечь полезные сведения из соцсетей, информации о посещении веб-сайтов и других источников, таким образом повысив качество взаимодействия с клиентами и сделав свои предложения максимально полезными. Обеспечьте индивидуальный подход, сократите отток клиентской базы и предотвращайте возникновение проблем. |
| Обнаружение несанкционированного доступа и выполнение нормативных требований | Когда дело касается безопасности, речь идет не просто о паре хакеров: против Вас выступают целые команды опытных специалистов. Нормативные требования и стандарты безопасности постоянно меняются. Большие данные позволяют определять шаблоны, характерные для мошенников, и собирать значительные объемы данных, чтобы ускорить предоставление нормативной отчетности. |
| Машинное обучение | Сегодня машинное обучение — одна из самых популярных тем для обсуждения. И данные — в особенности большие данные — являются одной из причин этой популярности. Сегодня мы можем обучать машины вместо того, чтобы программировать их. Именно доступность больших данных сделала это возможным. |
| Операционная эффективность | Операционная эффективность редко становится обсуждаемой темой, однако именно в этой области большие данные играют самую значительную роль. Большие данные позволяют получать доступ к сведениям о производстве, мнении заказчиков и доходах, а также анализировать эти и другие факторы, чтобы сократить число простоев и прогнозировать будущий спрос. Большие данные также позволяют принимать более взвешенные решения в соответствии с рыночным спросом. Большие данные также позволяют принимать более взвешенные решения в соответствии с рыночным спросом. |
| Внедрение инноваций | Большие данные позволяют выявлять взаимозависимости между пользователями, учреждениями и компаниями, внедрять их и определять новые способы применения полученных сведений. Используйте результаты исследований данных, чтобы повысить эффективность финансовых решений и планирования. Изучайте тенденции и желания покупателей, чтобы выпускать новые продукты и услуги. Внедрите динамическое ценообразование. Возможности поистине безграничны. |
Сложности при использовании больших данных
Большие данные — это большие возможности, но и немалые трудности.
Прежде всего, большие данные предсказуемо занимают много места. Хотя новые технологии хранения постоянно развиваются, объемы данных возрастают вдвое почти каждые два года. Организации до сих пор сталкиваются с проблемами роста объемов данных и их эффективного хранения.
Но недостаточно просто найти большое хранилище. Данные необходимо использовать, чтобы они приносили выгоду, и размер этой выгоды зависит от обработки данных. Чистые данные, то есть данные, актуальные для клиента и организованные для эффективного анализа, требуют тщательной обработки. Специалисты по изучению данных тратят от 50 до 80% рабочего времени на обработку и подготовку данных для использования.
И, наконец, технологии больших данных развиваются семимильными шагами. Несколько лет назад Apache Hadoop была самой популярной технологией для работы с большими данными. Платформа Apache Spark появилась в 2014 году. Сегодня оптимальным подходом является совместное использование этих двух платформ. Чтобы успевать за развитием больших данных, требуется прилагать большие усилия.
Ознакомьтесь с дополнительными ресурсами о больших данных:
Подробнее о больших данных в Oracle
Как работают большие данные
Большие данные позволяют извлекать новые ценные сведения, которые открывают новые возможности и бизнес-модели. Чтобы начать работу с большими данными, необходимо выполнить три действия.
Чтобы начать работу с большими данными, необходимо выполнить три действия.
1. Интеграция
Технология больших данных позволяет объединять данные из разрозненных источников и приложений. Традиционные механизмы интеграции, такие как средства для извлечения, преобразования и загрузки данных (ETL), не справляются с подобными задачами. Для анализа наборов данных размером в терабайт, а то и петабайт, нужны новые стратегии и технологии.
Во время этапа интеграции происходит добавление, обработка и форматирование данных, чтобы корпоративным аналитикам было удобно с ними работать.
2. Управление
Большим данным требуется объемное хранилище. Решение для хранения может быть размещено в локальной или облачной среде или и там и там. Вы можете хранить данные в предпочтительном формате и применять желаемые требования к обработке (и необходимые механизмы обработки) к наборам данным по мере необходимости. Большинство организаций выбирают решение для хранения данных в зависимости от того, где они хранятся в настоящее время. Облачные хранилища пользуются растущей популярностью, так как поддерживают актуальные требования к вычислениям и позволяют задействовать ресурсы по мере надобности.
Облачные хранилища пользуются растущей популярностью, так как поддерживают актуальные требования к вычислениям и позволяют задействовать ресурсы по мере надобности.
3. Анализ
Вложения в большие данные окупятся сполна, когда Вы приступите к анализу данных и начнете предпринимать действия исходя из полученных сведений. Обеспечьте новый уровень прозрачности благодаря визуальному анализу разнообразных наборов данных. Используйте глубокий анализ данных, чтобы совершать новые открытия. Делитесь своими открытиями с другими. Создавайте модели данных с помощью машинного обучения и искусственного интеллекта. Примените свои данные на деле.
Лучшие практики при работе с большими данными
Чтобы помочь Вам в освоении новой технологии, мы подготовили список лучших практик, которых рекомендуем придерживаться. Ниже приведены наши рекомендации по созданию надежного фундамента для работы с большими данными.
| Согласуйте изучение больших данных с бизнес-задачами | Более обширные наборы данных позволяют совершать новые открытия. Поэтому важно планировать вложения в специалистов, организацию и инфраструктуру исходя из четко поставленных бизнес-задач, чтобы гарантировать постоянное привлечение инвестиций и финансирование. Чтобы понять, на верном ли Вы пути, спросите себя, каким образом большие данные поддерживают приоритеты бизнеса и ИТ и способствуют достижению важнейших целей. Например, речь может идти о фильтрации веб-журналов для понимания тенденций в интернет-торговле, анализе отзывов заказчиков в социальных сетях и взаимодействия со службой поддержки, а также изучении методов статистической корреляции и их сопоставлении с данными о заказчиках, продукции, производстве и проектировании. Поэтому важно планировать вложения в специалистов, организацию и инфраструктуру исходя из четко поставленных бизнес-задач, чтобы гарантировать постоянное привлечение инвестиций и финансирование. Чтобы понять, на верном ли Вы пути, спросите себя, каким образом большие данные поддерживают приоритеты бизнеса и ИТ и способствуют достижению важнейших целей. Например, речь может идти о фильтрации веб-журналов для понимания тенденций в интернет-торговле, анализе отзывов заказчиков в социальных сетях и взаимодействия со службой поддержки, а также изучении методов статистической корреляции и их сопоставлении с данными о заказчиках, продукции, производстве и проектировании. |
| Используйте стандарты и руководства, чтобы компенсировать недостаток квалификации | Нехватка навыков является одним из наиболее существенных препятствий на пути к извлечению выгоды из больших данных. Этот риск можно снизить, если внести технологии, планы и решения, связанные с большими данными, в программу управления ИТ. Стандартизация подхода позволит эффективнее управлять расходами и ресурсами. При внедрении решений и стратегий, имеющих отношение к большим данным, необходимо заранее оценить необходимый уровень компетенции и принять меры по устранению недостатков в навыках. Речь может идти об обучении или переобучении существующего персонала, найме новых специалистов или обращении в консалтинговые фирмы. Стандартизация подхода позволит эффективнее управлять расходами и ресурсами. При внедрении решений и стратегий, имеющих отношение к большим данным, необходимо заранее оценить необходимый уровень компетенции и принять меры по устранению недостатков в навыках. Речь может идти об обучении или переобучении существующего персонала, найме новых специалистов или обращении в консалтинговые фирмы. |
| Оптимизируйте передачу знаний с помощью центров повышения квалификации | Используйте центры повышения квалификации для обмена знаниями, наблюдения и управления проектной коммуникацией. Независимо от того, начинаете ли Вы работу с большими данными или продолжаете, расходы на оборудование и ПО следует распределить по всем подразделениям организации. Такой структурированный и систематизированный подход помогает расширить возможности больших данных и повысить уровень зрелости информационной архитектуры в целом. |
| Согласование структурированных и неструктурированных данных приносит наибольшие преимущества | Анализ больших данных сам по себе ценен. Неважно, какие данные Вы собираете — данные о заказчиках, продукции, оборудовании или окружающей среде — цель состоит в том, чтобы добавить больше релевантных единиц информации в эталонные и аналитические сводки и обеспечить более точные выводы. Например, важно различать отношение всех заказчиков от отношения наиболее ценных заказчиков. Именно поэтому многие организации рассматривают большие данные как неотъемлемую часть существующего набора средств бизнес-анализа, платформ хранения данных и информационной архитектуры. Не забывайте, что процессы и модели больших данных могут выполняться и разрабатываться как человеком, так и машинами. Аналитические возможности больших данных включают статистику, пространственный анализ, семантику, интерактивное изучение и визуализацию. Использование аналитических моделей позволяет соотносить различные типы и источники данных, чтобы устанавливать связи и извлекать полезные сведения. |
| Обеспечьте производительность лабораторий по изучению данных | Обнаружение полезных сведений в данных не всегда обходится без сложностей. Иногда мы даже не знаем, что именно ищем. Это нормально. Руководство и специалисты по ИТ должны с пониманием относиться к отсутствию четкой цели или требований. В то же время специалисты по анализу и изучению данных должны тесно сотрудничать с коммерческими подразделениями, чтобы ясно представлять, в каких областях имеются пробелы и каковы требования бизнеса. Чтобы обеспечить интерактивное исследование данных и возможность экспериментов со статистическими алгоритмами, необходимы высокопроизводительные рабочие среды. Убедитесь, что в тестовых средах есть доступ ко всем необходимым ресурсам и что они надлежащим образом контролируются. |
| Согласуйте с облачной операционной моделью | Технологии больших данных требуют доступа к широкому набору ресурсов для итеративных экспериментов и текущих производственных задач. Решения для больших данных охватывают все области деятельности, включая транзакции, основные, эталонные и сводные данные. Тестовые среды для анализа должны создаваться по требованию. Управление распределением ресурсов играет критически важную роль в обеспечении контроля за всем потоком данных, включая предварительную и последующую обработку, интеграцию, обобщение в базе данных и аналитическое моделирование. Правильно спланированная стратегия предоставления ресурсов для частных и общедоступных облаков и обеспечения безопасности имеет ключевое значение при поддержке этих меняющихся требований. Решения для больших данных охватывают все области деятельности, включая транзакции, основные, эталонные и сводные данные. Тестовые среды для анализа должны создаваться по требованию. Управление распределением ресурсов играет критически важную роль в обеспечении контроля за всем потоком данных, включая предварительную и последующую обработку, интеграцию, обобщение в базе данных и аналитическое моделирование. Правильно спланированная стратегия предоставления ресурсов для частных и общедоступных облаков и обеспечения безопасности имеет ключевое значение при поддержке этих меняющихся требований. |
 Однако Вы сможете извлечь еще большее количество полезных сведений за счет сопоставления и интеграции больших данных низкой плотности с уже используемыми структурированными данными.
Однако Вы сможете извлечь еще большее количество полезных сведений за счет сопоставления и интеграции больших данных низкой плотности с уже используемыми структурированными данными.
Что такое обработка данных? Определение и этапы — Интеграция Talend Cloud
Статьи по теме
- Что такое MySQL? Все, что вам нужно знать
- Что такое промежуточное ПО? Технологический посредник
- Что такое Shadow IT? Определение, риски и примеры
- Что такое бессерверная архитектура?
- Что такое SAP?
Без обработки данных компании ограничивают свой доступ к тем самым данным, которые могут повысить их конкурентоспособность и предоставить важную информацию для бизнеса. Вот почему для всех компаний крайне важно понимать необходимость обработки всех своих данных и то, как это делать.
Вот почему для всех компаний крайне важно понимать необходимость обработки всех своих данных и то, как это делать.
Что такое обработка данных?
Обработка данных происходит, когда данные собираются и преобразуются в пригодную для использования информацию. Обычно выполняется специалистом по данным или группой специалистов по данным. Важно, чтобы обработка данных выполнялась правильно, чтобы не оказать негативного влияния на конечный продукт или вывод данных.
Обработка данных начинается с данных в необработанном виде и преобразуется в более удобочитаемый формат (графики, документы и т. д.), придавая им форму и контекст, необходимые для интерпретации компьютерами и использования сотрудниками всей организации.
Шесть этапов обработки данных
1. Сбор данных
Сбор данных является первым этапом обработки данных. Данные извлекаются из доступных источников, включая озера данных и хранилища данных. Важно, чтобы доступные источники данных были надежными и хорошо построенными, чтобы собранные данные (и позже используемые в качестве информации) были максимально высокого качества.
2. Подготовка данных
После сбора данных начинается этап подготовки данных. Подготовка данных, часто называемая «предварительной обработкой», представляет собой этап, на котором необработанные данные очищаются и организуются для следующего этапа обработки данных. Во время подготовки исходные данные тщательно проверяются на наличие ошибок. Цель этого шага — устранить неверные данные (избыточные, неполные или неверные данные) и приступить к созданию высококачественных данных для лучшей бизнес-аналитики.
3. Ввод данных
Чистые данные затем вводятся в место назначения (возможно, в CRM, например Salesforce, или в хранилище данных, например Redshift) и переводятся на понятный язык. Ввод данных — это первый этап, на котором необработанные данные начинают принимать форму полезной информации.
4. Обработка
На этом этапе данные, введенные в компьютер на предыдущем этапе, фактически обрабатываются для интерпретации. Обработка выполняется с использованием алгоритмов машинного обучения, хотя сам процесс может незначительно отличаться в зависимости от источника обрабатываемых данных (озера данных, социальные сети, подключенные устройства и т. д.) и их предполагаемого использования (проверка рекламных шаблонов, медицинская диагностика с подключенных устройств, определение потребностей клиентов и др.).
д.) и их предполагаемого использования (проверка рекламных шаблонов, медицинская диагностика с подключенных устройств, определение потребностей клиентов и др.).
5. Вывод/интерпретация данных
Этап вывода/интерпретации — это этап, на котором данные наконец могут быть использованы учеными, не занимающимися данными. Она переведена, удобочитаема и часто представлена в виде графиков, видео, изображений, обычного текста и т. д.). Члены компании или учреждения теперь могут начать самостоятельно обслуживать данные для своих собственных проектов по анализу данных.
6. Хранение данных
Завершающим этапом обработки данных является их хранение. После обработки всех данных они сохраняются для дальнейшего использования. Хотя некоторая информация может быть использована сразу же, большая ее часть послужит цели позже. Кроме того, правильно хранящиеся данные необходимы для соблюдения законодательства о защите данных, такого как GDPR. Когда данные хранятся надлежащим образом, члены организации могут быстро и легко получить к ним доступ в случае необходимости.
Будущее обработки данных
Будущее обработки данных — в облаке. Облачные технологии основаны на удобстве современных электронных методов обработки данных и ускоряют их скорость и эффективность. Более быстрые и качественные данные означают, что каждая организация может использовать больше данных и получать больше ценной информации.
По мере переноса больших данных в облако компании получают огромные преимущества. Облачные технологии больших данных позволяют компаниям объединять все свои платформы в одну легко адаптируемую систему. По мере изменения и обновления программного обеспечения (как это часто происходит в мире больших данных) облачные технологии органично интегрируют новое со старым.
Преимущества облачной обработки данных никоим образом не ограничиваются крупными корпорациями. На самом деле, небольшие компании могут сами пожинать большие выгоды. Облачные платформы могут быть недорогими и предлагать гибкость для роста и расширения возможностей по мере роста компании. Это дает компаниям возможность масштабироваться без высокой цены.
Это дает компаниям возможность масштабироваться без высокой цены.
От обработки данных к аналитике
Большие данные меняют способ ведения бизнеса всеми нами. Сегодня сохранение гибкости и конкурентоспособности зависит от наличия четкой и эффективной стратегии обработки данных. Хотя шесть этапов обработки данных не изменятся, облако привело к огромному прогрессу в технологиях, которые на сегодняшний день обеспечивают самые передовые, экономичные и быстрые методы обработки данных.
Станьте мастером обработки данных.
Скачать бесплатную пробную версию Talend Cloud
Готовы начать работу с Talend?
Связаться с отделом продаж
Другие статьи по теме
- Что такое MySQL? Все, что вам нужно знать
- Что такое промежуточное ПО? Технологический посредник
- Что такое Shadow IT? Определение, риски и примеры
- Что такое бессерверная архитектура?
- Что такое SAP?
- Что такое ERP и зачем это нужно?
- Что такое «Хранилище данных» и зачем оно нам?
- Что такое лаборатория данных?
- Общие сведения об облачном хранилище
- Что такое устаревшая система?
- Что такое данные как услуга?
- Что такое киоск данных?
- Что такое интеллектуальный анализ данных?
- Что такое Apache Hive?
- Управление данными: обзор процесса в Python
- Что такое источник данных?
- Определение преобразования данных
- SQL и NoSQL: различия, базы данных и решения
- Моделирование данных: обеспечение данных, которым можно доверять
- Как современная архитектура данных обеспечивает реальные бизнес-результаты
- Гравитация данных: что это означает для ваших данных
- База данных CRM: что это такое и как максимально эффективно использовать ваши данные
- Данные Преобразование 101: Повышение точности базы данных
Озеро данных и хранилище данных: ключевые отличия
Статьи по теме
- Тестирование хранилища данных (по сравнению с тестированием ETL)
- Архитектура современного хранилища данных: традиционное хранилище данных против облачного хранилища
- Вся правда о корпоративном хранилище данных (EDW)
- Что такое хранилище данных и почему оно важно для вашего бизнеса?
- 8 Преимущества облачного хранилища данных
Озера данных и хранилища данных широко используются для хранения больших данных, но они не являются взаимозаменяемыми терминами. Озеро данных — это обширный пул необработанных данных, назначение которых еще не определено. Хранилище данных — это хранилище структурированных отфильтрованных данных, которые уже были обработаны для определенной цели. Существует даже новая тенденция в архитектуре управления данными — хранилище данных, которое сочетает в себе гибкость озера данных с возможностями управления данными хранилища данных.
Озеро данных — это обширный пул необработанных данных, назначение которых еще не определено. Хранилище данных — это хранилище структурированных отфильтрованных данных, которые уже были обработаны для определенной цели. Существует даже новая тенденция в архитектуре управления данными — хранилище данных, которое сочетает в себе гибкость озера данных с возможностями управления данными хранилища данных.
Эти два типа хранения данных часто путают, но между ними гораздо больше различий, чем сходства. На самом деле, единственное реальное сходство между ними заключается в их высокоуровневой цели хранения данных.
Различие важно, потому что они служат разным целям и требуют разных наборов глаз для правильной оптимизации. В то время как озеро данных подходит для одной компании, хранилище данных лучше подойдет для другой.
Четыре основных различия между озером данных и хранилищем данных
Существует несколько различий между озером данных и хранилищем данных. Структура данных, идеальные пользователи, методы обработки и общая цель данных являются ключевыми отличиями.
Структура данных: необработанные и обработанные
Необработанные данные — это данные, которые еще не были обработаны для определенной цели. Возможно, самое большое различие между озерами данных и хранилищами данных заключается в разной структуре необработанных и обработанных данных. Озера данных в основном хранят необработанные данные, тогда как хранилища данных хранят обработанные и уточненные данные.
Из-за этого для озер данных обычно требуется гораздо большая емкость хранилища, чем для хранилищ данных. Кроме того, необработанные необработанные данные гибки, их можно быстро проанализировать для любых целей и они идеально подходят для машинного обучения. Однако риск всех этих необработанных данных заключается в том, что озера данных иногда превращаются в болота данных без надлежащих мер по обеспечению качества данных и управлению данными.
Хранилища данных, сохраняя только обработанные данные, экономят дорогостоящее место для хранения, не храня данные, которые могут никогда не использоваться. Кроме того, обработанные данные могут быть легко поняты более широкой аудиторией.
Кроме того, обработанные данные могут быть легко поняты более широкой аудиторией.
Назначение: не определено по сравнению с используемым
Назначение отдельных фрагментов данных в озере данных не определено. Необработанные данные поступают в озеро данных, иногда с учетом конкретного будущего использования, а иногда просто для того, чтобы иметь их под рукой. Это означает, что озера данных имеют меньшую организацию и меньшую фильтрацию данных, чем их аналог.
Обработанные данные — это необработанные данные, предназначенные для определенного использования. Поскольку в хранилищах данных хранятся только обработанные данные, все данные в хранилище данных используются для определенной цели внутри организации. Это означает, что место для хранения не тратится впустую на данные, которые могут никогда не использоваться.
Пользователи: специалисты по данным и бизнес-профессионалы
Озера данных часто трудно ориентировать тем, кто не знаком с необработанными данными. Необработанные, неструктурированные данные обычно требуют специалиста по данным и специализированных инструментов для их понимания и преобразования для любого конкретного использования в бизнесе.
Необработанные, неструктурированные данные обычно требуют специалиста по данным и специализированных инструментов для их понимания и преобразования для любого конкретного использования в бизнесе.
В качестве альтернативы растет популярность инструментов подготовки данных, которые обеспечивают самостоятельный доступ к информации, хранящейся в озерах данных.
Подробнее см. в разделе «Что такое подготовка данных?» →
Обработанные данные используются в диаграммах, электронных таблицах, таблицах и т. д., чтобы их могли прочитать большинство, если не все, сотрудников компании. Обработанные данные, подобные тем, которые хранятся в хранилищах данных, требуют только того, чтобы пользователь был знаком с представляемой темой.
Доступность: гибкость или безопасность
Доступность и простота использования относятся к использованию репозитория данных в целом, а не данных в нем. Архитектура озера данных не имеет структуры, поэтому к ней легко получить доступ и ее легко изменить. Кроме того, любые изменения, вносимые в данные, можно вносить быстро, поскольку у озер данных очень мало ограничений.
Кроме того, любые изменения, вносимые в данные, можно вносить быстро, поскольку у озер данных очень мало ограничений.
Хранилища данных по своей природе более структурированы. Одним из основных преимуществ архитектуры хранилища данных является то, что обработка и структура данных упрощают расшифровку самих данных, а ограничения структуры делают хранилища данных сложными и дорогостоящими в управлении.
Озеро данных или хранилище данных: что мне подходит?
Организации часто нуждаются в обоих. Озера данных возникли из-за необходимости использовать большие данные и использовать необработанные, детализированные структурированные и неструктурированные данные для машинного обучения, но по-прежнему существует потребность в создании хранилищ данных для аналитики, которую используют бизнес-пользователи.
Здравоохранение: озера данных хранят неструктурированную информацию
Хранилища данных уже много лет используются в сфере здравоохранения, но они никогда не пользовались большим успехом. Из-за неструктурированного характера большей части данных в здравоохранении (заметки врачей, клинические данные и т. д.) и необходимости анализа в режиме реального времени хранилища данных, как правило, не являются идеальной моделью.
Из-за неструктурированного характера большей части данных в здравоохранении (заметки врачей, клинические данные и т. д.) и необходимости анализа в режиме реального времени хранилища данных, как правило, не являются идеальной моделью.
Озера данных позволяют сочетать структурированные и неструктурированные данные, что, как правило, больше подходит для медицинских компаний.
Узнайте больше о том, как компания Talend помогла AstraZeneca создать глобальное озеро данных. →
Образование: озера данных предлагают гибкие решения
В последние годы значение больших данных для реформы образования стало чрезвычайно очевидным. Данные об оценках учащихся, посещаемости и многом другом могут не только помочь неуспевающим учащимся вернуться на правильный путь, но и фактически помочь предсказать потенциальные проблемы до их возникновения. Гибкие решения для работы с большими данными также помогли образовательным учреждениям оптимизировать выставление счетов, повысить эффективность сбора средств и многое другое.
Гибкие решения для работы с большими данными также помогли образовательным учреждениям оптимизировать выставление счетов, повысить эффективность сбора средств и многое другое.
Большая часть этих данных обширна и очень необработана, поэтому во многих случаях образовательные учреждения получают наибольшую выгоду от гибкости озер данных.
Финансы: хранилища данных привлекают массы
В финансах, а также в других сферах бизнеса хранилище данных часто является лучшей моделью хранения, поскольку оно может быть структурировано для доступа всей компании, а не специалисту по данным.
Большие данные помогли индустрии финансовых услуг добиться больших успехов, и хранилища данных сыграли важную роль в этих успехах. Единственная причина, по которой компания, предоставляющая финансовые услуги, может отказаться от такой модели, заключается в том, что она более рентабельна, но не так эффективна для других целей.
Транспорт: озера данных помогают делать прогнозы
Большая часть преимуществ анализа озер данных заключается в возможности делать прогнозы.
В транспортной отрасли, особенно в управлении цепочками поставок, возможность прогнозирования, которая обеспечивается гибкими данными в озере данных, может иметь огромные преимущества, а именно преимущества сокращения затрат, реализуемые за счет изучения данных из форм в транспортном конвейере.
Важность выбора озера данных или хранилища данных
Разговор об озере данных и хранилище данных, вероятно, только начался, но ключевые различия в структуре, процессах, пользователях и общей гибкости делают каждую модель уникальной. В зависимости от потребностей вашей компании разработка правильного озера данных или хранилища данных будет способствовать росту.
Узнайте больше об облачных озерах данных или попробуйте Talend Data Fabric, чтобы начать использовать возможности больших данных уже сегодня.
Что такое киоск данных? (по сравнению с хранилищем данных)
Статьи по теме
- Что такое MySQL? Все, что вам нужно знать
- Что такое промежуточное ПО? Технологический посредник
- Что такое Shadow IT? Определение, риски и примеры
- Что такое бессерверная архитектура?
- Что такое SAP?
На рынке, где доминируют большие данные и аналитика, витрины данных являются одним из ключей к эффективному преобразованию информации в идеи. Хранилища данных обычно имеют дело с большими наборами данных, но для анализа данных требуются легкодоступные и легкодоступные данные. Должен ли деловой человек выполнять сложные запросы только для того, чтобы получить доступ к данным, которые ему нужны для его отчетов? Нет, и именно поэтому умные компании используют витрины данных.
Хранилища данных обычно имеют дело с большими наборами данных, но для анализа данных требуются легкодоступные и легкодоступные данные. Должен ли деловой человек выполнять сложные запросы только для того, чтобы получить доступ к данным, которые ему нужны для его отчетов? Нет, и именно поэтому умные компании используют витрины данных.
Витрина данных — это тематическая база данных, которая часто является секционированным сегментом корпоративного хранилища данных. Подмножество данных, хранящихся в киоске данных, обычно соответствует определенному бизнес-подразделению, например, продажам, финансам или маркетингу. Витрины данных ускоряют бизнес-процессы, предоставляя доступ к соответствующей информации в хранилище данных или хранилище оперативных данных в течение нескольких дней, а не месяцев или дольше. Поскольку киоск данных содержит только данные, применимые к определенной области бизнеса, это экономичный способ быстро получить полезную информацию.
Витрины данных и хранилища данных
Витрины данных и хранилища данных — это хорошо структурированные репозитории, в которых данные хранятся и управляются до тех пор, пока они не потребуются. Однако они различаются по объему хранимых данных: хранилища данных предназначены для использования в качестве центрального хранилища данных для всего бизнеса, тогда как витрина данных выполняет запрос определенного подразделения или бизнес-функции. Поскольку хранилище данных содержит данные для всей компании, рекомендуется строго контролировать доступ к ним. Кроме того, запрос данных, которые вам нужны в хранилище данных, является невероятно сложной задачей для бизнеса. Таким образом, основная цель витрины данных состоит в том, чтобы изолировать или разделить меньший набор данных от целого, чтобы обеспечить более легкий доступ к данным для конечных потребителей.
Однако они различаются по объему хранимых данных: хранилища данных предназначены для использования в качестве центрального хранилища данных для всего бизнеса, тогда как витрина данных выполняет запрос определенного подразделения или бизнес-функции. Поскольку хранилище данных содержит данные для всей компании, рекомендуется строго контролировать доступ к ним. Кроме того, запрос данных, которые вам нужны в хранилище данных, является невероятно сложной задачей для бизнеса. Таким образом, основная цель витрины данных состоит в том, чтобы изолировать или разделить меньший набор данных от целого, чтобы обеспечить более легкий доступ к данным для конечных потребителей.
Витрина данных может быть создана из существующего хранилища данных — подход «сверху вниз» — или из других источников, таких как внутренние операционные системы или внешние данные. Подобно хранилищу данных, это реляционная база данных, в которой хранятся транзакционные данные (значение времени, числовой порядок, ссылка на один или несколько объектов) в столбцах и строках, что упрощает организацию и доступ.
С другой стороны, отдельные бизнес-подразделения могут создавать свои собственные витрины данных на основе собственных требований к данным. Если того требуют бизнес-потребности, несколько витрин данных можно объединить для создания единого хранилища данных. Это подход к разработке снизу вверх.
3 типа киосков данных
Существует три типа киосков данных: зависимые, независимые и гибридные. Они классифицируются на основе их отношения к хранилищу данных и источникам данных, которые используются для создания системы.
1. Зависимые витрины данных
Зависимая витрина данных создается из существующего корпоративного хранилища данных. Это нисходящий подход, который начинается с хранения всех бизнес-данных в одном центральном месте, а затем извлекает четко определенную часть данных, когда это необходимо для анализа.
Для формирования хранилища данных определенный набор данных агрегируется (формируется в кластер) из хранилища, реструктурируется, а затем загружается в киоск данных, где его можно запрашивать. Это может быть логическое представление или физическое подмножество хранилища данных:
Это может быть логическое представление или физическое подмножество хранилища данных:
- Логическое представление. представляет собой физически отдельную базу данных от хранилища данных
Детализированные данные — самый низкий уровень данных в целевом наборе — в хранилище данных служат единой точкой отсчета для всех создаваемых зависимых витрин данных.
2. Независимые витрины данных
Независимая витрина данных — это автономная система, созданная без использования хранилища данных, которая фокусируется на одной предметной области или бизнес-функции. Данные извлекаются из внутренних или внешних источников данных (или из обоих), обрабатываются, а затем загружаются в репозиторий витрин данных, где они хранятся до тех пор, пока они не потребуются для бизнес-аналитики.
Независимые витрины данных несложно спроектировать и разработать. Они полезны для достижения краткосрочных целей, но могут стать громоздкими в управлении (каждый со своим собственным инструментом ETL и логикой) по мере расширения и усложнения потребностей бизнеса.
3. Гибридные витрины данных
Гибридные витрины данных объединяют данные из существующего хранилища данных и других операционных исходных систем. Он сочетает в себе скорость и ориентированность на конечного пользователя нисходящего подхода с преимуществами интеграции восходящего метода на уровне предприятия.
Структура витрины данных
Подобно хранилищу данных, витрина данных может быть организована с использованием схемы в виде звезды, снежинки, хранилища или другой схемы. ИТ-команды обычно используют схему «звезда», состоящую из одной или нескольких таблиц фактов (набор показателей, относящихся к конкретному бизнес-процессу или событию), ссылающихся на таблицы измерений (первичный ключ, присоединенный к таблице фактов) в реляционной базе данных.
Преимущество звездообразной схемы заключается в том, что при написании запросов требуется меньше объединений, поскольку нет зависимости между измерениями. Это упрощает процесс запроса ETL, облегчая доступ и навигацию для аналитиков.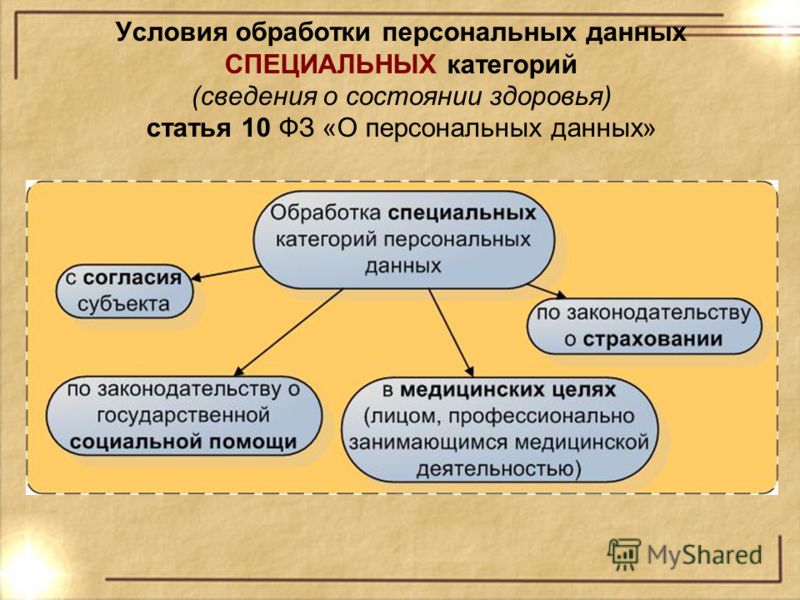
В схеме снежинки размеры четко не определены. Они нормализованы, чтобы уменьшить избыточность данных и защитить их целостность. Для хранения таблиц измерений требуется меньше места, но это более сложная структура (несколько таблиц для заполнения и синхронизации), которую может быть сложно поддерживать.
Преимущества витрины данных
Управление большими данными и получение ценной информации для бизнеса — это задача, с которой сталкиваются все компании, и большинство из них решает ее с помощью стратегических киосков данных.
- Эффективный доступ — Витрина данных — это экономящее время решение для доступа к определенному набору данных для бизнес-аналитики.
- Недорогая альтернатива хранилищу данных — Витрины данных могут быть недорогой альтернативой созданию корпоративного хранилища данных, где требуемые наборы данных меньше. Независимая витрина данных может быть запущена и запущена в течение недели или меньше.
- Повышение производительности хранилища данных — Зависимые и гибридные витрины данных могут повысить производительность хранилища данных, взяв на себя бремя обработки для удовлетворения потребностей аналитика.
 Когда зависимые витрины данных размещаются в отдельном центре обработки, они также значительно сокращают затраты на обработку аналитики.
Когда зависимые витрины данных размещаются в отдельном центре обработки, они также значительно сокращают затраты на обработку аналитики.
Другие преимущества киоска данных включают:
- Обслуживание данных — Разные отделы могут владеть своими данными и контролировать их.
- Простая настройка — Простая конструкция требует меньше технических навыков для настройки.
- Аналитика — можно легко отслеживать ключевые показатели эффективности (KPI).
- Легкий ввод — Витрины данных могут стать строительными блоками будущего проекта корпоративного хранилища данных.
Будущее киосков данных — в облаке
Даже с учетом повышенной гибкости и эффективности, которые предлагают витрины данных, большие данные и крупный бизнес по-прежнему становятся слишком большими для многих локальных решений. По мере того, как хранилища данных и озера данных перемещаются в облако, то же самое происходит и с витринами данных.
Благодаря общей облачной платформе для создания и хранения данных доступ и аналитика становятся намного более эффективными. Кластеры временных данных могут быть созданы для краткосрочного анализа, а долгоживущие кластеры могут объединяться для более устойчивой работы. Современные технологии также отделяют хранение данных от вычислений, обеспечивая максимальную масштабируемость для запросов данных.
Другие преимущества облачных зависимых и гибридных киосков данных включают:
- Гибкая архитектура с облачными приложениями.
- Единое хранилище, содержащее все витрины данных.
- Ресурсы потребляются по требованию.
- Немедленный доступ к информации в режиме реального времени.
- Повышенная эффективность.
- Консолидация ресурсов для снижения затрат.
- Интерактивная аналитика в режиме реального времени.
Начало работы с витринами данных
Компании сталкиваются с бесконечным объемом информации и постоянно меняющейся потребностью разбивать эту информацию на управляемые фрагменты для анализа и анализа. Витрины данных в облаке — это долгосрочное масштабируемое решение. Чтобы создать киоск данных, обязательно найдите инструмент ETL, который позволит вам подключиться к существующему хранилищу данных или другим важным источникам данных, из которых ваши бизнес-пользователи должны получать информацию. Кроме того, убедитесь, что ваш инструмент интеграции данных может регулярно обновлять витрину данных, чтобы ваши данные и итоговая аналитика были актуальными.
Витрины данных в облаке — это долгосрочное масштабируемое решение. Чтобы создать киоск данных, обязательно найдите инструмент ETL, который позволит вам подключиться к существующему хранилищу данных или другим важным источникам данных, из которых ваши бизнес-пользователи должны получать информацию. Кроме того, убедитесь, что ваш инструмент интеграции данных может регулярно обновлять витрину данных, чтобы ваши данные и итоговая аналитика были актуальными.
Платформа управления данными Talend помогает командам работать эффективнее благодаря открытой, масштабируемой архитектуре и простым графическим инструментам, помогающим преобразовывать и загружать применимые источники данных для создания новой витрины данных. Кроме того, Talend Data Management Platform упрощает обслуживание существующих киосков данных за счет автоматизации и планирования заданий интеграции, необходимых для обновления витрин данных.
С помощью Talend Open Studio for Data Integration вы можете подключаться к таким технологиям, как Amazon Web Services Redshift, Snowflake и Azure Data Warehouse, чтобы создавать собственные витрины данных, используя гибкость и масштабируемость облака.
